Different view-points exist when it comes to looking at the the emerging landscape of interpretability methods, such as the type of data these methods deal with or whether they refer to global or local properties. The classification of machine learning interpretability techniques should not be one-sided. There are exist different points of view, which distinguish and could further divide these methods. Hence, in order for a practitioner to identify the ideal method for the specific criteria of each problem encountered, all aspects of each method should be taken into consideration.
This taxonomy focuses on the purpose that these methods were created to serve and the ways through which they accomplish this purpose. As a result, according to the presented taxonomy, four major categories for interpretability methods are identified: methods for explaining complex black-box models, methods for creating white-box models, methods that promote fairness and restrict the existence of discrimination, and, lastly, methods for analysing the sensitivity of model predictions.
3.2. Interpretability Methods to Create White-Box Models
This category encompasses methods that create interpretable and easily understandable from humans models. The models in this category are often called intrinsic, transparent, or white-box models. Such models include the linear, decision tree, and rule-based models and some other more complex and sophisticated models that are equally transparent and, therefore, promising for the interpretability field. This work will focus on more complex models, as the linear, decision tree and elementary rule-based models have been extensively discussed in many other scientific studies. A summary of the discussed interpretability methods to create white-box models can be found in
Table 3.
Ustun and Rudin [
64] proposed Supersparse Linear Integer Models (SLIM), a type of predictive system that only allows for additions, subtraction, and multiplications of input features to generate predictions, thus being highly interpretable.
In [
65], Microsoft presented two case studies on real medical data, where naturally interpretable generalized additive models with pairwise interactions (GA
2Ms), as originally proposed in [
66], achieved state-of-the-art accuracy, showing that GA
2Ms are the first step towards deploying interpretable high-accuracy models in applications like healthcare, where interpretability is of utmost importance. GA
2Ms are generalized additive models (GAM) [
67], but with a few tweaks that set them apart, in terms of predictive power, from traditional GAMs. More specifically, GA
2Ms are trained while using modern machine learning techniques such as bagging and boosting, while their boosting procedure uses a round-robin approach through features in order to reduce the undesirable effects of co-linearity. Furthermore, any pairwise interaction terms are automatically identified and, therefore, included, which further increases their predictive power. In terms of interpretability, as additive models, GA
2Ms are naturally interpretable, being able to calculate the contributions of each feature towards the final prediction in a modular way, thus making it easy for humans to understand the degree of impact of each feature and gain useful insight into the model’s predictions.
Boolean Rule Column Generation [
68] is a technique that utilises Boolean rules, either in their disjunctive normal form (DNF) or in their conjunctive normal form (CNF), in order to create predictive models. In this case, interpretability is achieved through rule simplicity: a low number Boolean rules with few clauses and conditions in each clause can more easily be understood and interpreted by humans. The authors highlighted that most column generation algorithms, although efficient, can lead to computational issues when it comes to learning rules for large datasets, due to the exponential size of the rule-space, which corresponds to all possible conjunctions or disjunctions of the input features. As a solution, they introduced an approximate column-generation algorithm that employs randomization in order to efficiently search the rule-space and learn interpretable DNF or CNF classification rules while optimally balancing the tradeoff between classification accuracy and rule simplicity.
Generalized Linear Rule Models [
69], which are often referred to as rule ensembles, are Generalized Linear Models (GLMs) [
70] that are linear combinations of rule-based features. The benefit of such models is that they are naturally interpretable, while also being relatively complex and flexible, since rules are able to capture nonlinear relationships and dependencies. Under the proposed approach, a GLM is re-fit as rules are created, thus allowing for existing rules to be re-weighted, ultimately producing a weighted combination of rules.
Hind et al. [
71] introduced TED, a framework for producing local explanations that satisfy the complexity mental model of a domain. The goal of TED is not to dig into the reasoning process of a model, but, instead, to mirror the reasoning process of a human expert in a specific domain, who effectively creates an domain-specific explanation system.
In summary, not a lot of progress has been made in recent years towards develo** white-box models. This is most likely the result of the immense complexity modern applications require, in combination with the inherent limitations of such models in terms of predictive power—especially in computer vision and natural language processing, where the difference in performance when compared to deep learning models is unbridgeable. Furthermore, because models are increasingly expected to perform well on more than one tasks and transfer of knowledge from one domain to another is becoming a common theme, white-box models, currently being able to perform well only in a single task, are losing traction within the literature and they are drop** further behind in terms of interest.
3.3. Interpretability Methods to Restrict Discrimination and Enhance Fairness in Machine Learning Models
Because machine learning systems are increasingly adopted in real life applications, any inequities or discrimination that are promoted by those systems have the potential to directly affect human lives. Machine Learning Fairness is a sub-domain of machine learning interpretability that focuses solely on the social and ethical impact of machine learning algorithms by evaluating them in terms impartiality and discrimination. The study of fairness in machine learning is becoming more broad and diverse, and it is progressing rapidly. Traditionally, the fairness of a machine learning system has been evaluated by checking the models’ predictions and errors across certain demographic segments, for example, groups of a specific ethnicity or gender. In terms of dealing with a lack of fairness, a number of techniques have been developed both to remove bias from training data and from model predictions and to train models that learn to make fair predictions in the first place. In this section, the most widely-used machine learning fairness methods are presented, discussed and finally summarised in
Table 4.
Disparate impact testing [
72] is a model agnostic method that is able to assess the fairness of a model, but is not able to provide any insight or detail regarding the causes of any discovered bias. The method conducts a series of simple experiments that highlight any differences in terms of model predictions and errors across different demographic groups. More specifically, it can detect biases regarding ethnicity, gender, disability status, marital status, or any other demographic. While straightforward and efficient when it comes to selecting the most fair model, the method, due to the simplicity of its tests, might fail to pick up on local occurrences of discrimination, especially in complex models.
A way to ensure fairness in machine learning models is to alter the model construction process. In [
73], three different data preprocessing techniques to ensure fairness in classification tasks are analysed. The first presented technique, which is called suppression, detects the features that correlate the most, according to some threshold with any sensitive features, such as gender or age. In order to diminish the impact of the sensitive features in the model’s decisions, the sensitive features along with their most correlated features are removed before training. This forces the model to learn from and, therefore, base its decisions on other attributes, thus not being biased against certain demographic segments. The second technique is called “massaging the dataset” and it was originally proposed in [
74]. In order to remove the discrimination from the input data, according to this technique, some relabelling is applied to of some instances in the dataset. First, using a ranker, the instances most likely to be victims (discriminated ones) or most likely to be profiters (favoured ones) are detected, according to their probability of belonging to the corresponding class without taking the sensitives attributes into account. Subsequently, their labels are changed and a classifier is trained on this modified data that is free of bias. Finally the idea behind the third preprocessing technique, as initially presented in [
75], is to apply different weights to the instances of the dataset based on frequency counts with respect to the sensitive column. The weight of an instance is calculated as the expected probability that its sensitive feature value and class appear together, while assuming that they are independent, divided by the respective observed probability. Reweighing has a similar effect to the “massaging” approach, but its major advantage is that it does alter the labels of the dataset. Similarly to disparate impact testing, the described data preproecessing methods might fail to pick up on local occurrences of discrimination, especially in complex models.
Another data preprocessing technique for removing the bias from machine learning models was proposed in [
76]. More specifically, having the following three goals in mind: controlling discrimination, limiting distortion in individual instances, and preserving utility, the authors derived a convex optimization for learning a data representation that captures these goals.
Adversarial debiasing [
77] is a framework for mitigating biases concerning demographic segments in machine learning systems by selecting a feature regarding the segment of interest and, subsequently, training a main model and an adversarial model simultaneously. The main model is trained in order to predict the label, whereas the adversarial model based on the main model’s prediction for each instance tries to predict the demographic segment of the instance; the objective is to maximize the main model’s ability to correctly predict the label, while, at the same time, minimizing the adversarial model’s ability to predict the demographic segment in question. Adversarial debiasing can be applied to both regression and classification tasks, regardless of the complexity of the chosen model. With regards to the sensitive features of interest, both continuous and discrete values can be handled and any imposed constraints can enforced across multiple definitions of fairness.
Kamiran et al. [
78] pointed out that many of the methods that make classifiers aware of discriminatory biases require data modifications or algorithm tweaks and they are not very flexible with respect to multiple sensitive feature handling and control over the performance vs. discrimination trade-off. As a solution to these problems, two new methods methods that utilise decision theory in order to create discrimination-aware classifiers were proposed, namely Reject Option based Classification (ROC) and Discrimination-Aware Ensemble (DAE), neither of which require any data preprocessing or classifier adjustments. ROC can be viewed as a cost-based classification method, in which misclassifying an instance of a non-favoured group as negative results is much higher punishment than wrongly predicting a member of a favored group as negative. DAE employs an ensemble of classifiers. Ensembles, by nature, can be very useful in reducing bias. According to the authors, this is because the greater the number of classifiers and the more diverse these classifiers are, the higher the probability that some of them will be fair. Under this assumption, the discrimination awareness of such an ensemble can be controlled by adjusting the diversity of its voting classifiers, while the trade-off between accuracy and discrimination in DAEs depends on the disagreements between the voting classifiers and number of instances that are incorrectly classified.
Liu et al. [
79] highlighted that most work in machine learning fairness had mostly studied the notion of fairness within static environments, and it had not been concerned with how decisions change the underlying population over time. They argued that seemingly fair decision rules have the potential to cause harm to disadvantaged groups and presented the case of loan decisions as an example where the introduction of seemingly fair rules can all decrease the credit score of the affected population over time. After emphasising the importance of temporal modelling and continuous measurement in evaluating what is considered fair, they concluded that in order for fairness rules to be set, rather than just considering what seems to be fair at a stationary point, an approach that takes the long term effects of such rules on the population in dynamic fashion into consideration is needed.
The problem of algorithmically allocating resources when in shortage was studied in [
80] and, more specifically, the notion of fairness within this procedure in terms of groups and the potential consequences. An efficient learning algorithm is proposed that converges to an optimal fair allocation, even without any prior knowledge of the frequency of instances in each group; only the number of instances that received the resource in a given allocation is known, rather than the total number of instances. This can be translated to the fact that the creditworthiness of individuals not given loans is not known in the case of loan decisions or to the fact that some crimes committed in areas of low policing presence are not known either. As an application their framework, the authors considered the predictive policing problem, and experimentally evaluated their proposed algorithm on the Philadelphia Crime Incidents dataset. The effectiveness of the proposed method was proven, as, although trained on arrest data that were produced by its own predictions for the previous days, potentially resulting in feedback loops, the algorithm managed to overcome them.
Feedback loops in the context of predictive policing and the allocation of policing resources were also studied in [
81]. More specifically, the authors first highlighted that feedback loops are a known issue in predictive policing systems, where a common scenario includes police resources being spent repeatedly on the same areas, regardless of the true crime rate. Subsequently, they developed a mathematical model of predictive policing which revealed the reasons behind the occurrence of feedback loops and showed that a relationship exists between the severity of problems that are caused by a runaway feedback loop and the variance in crime rates among area. Finally, upon acknowledging that incidents reported by citizens can alleviate the impact of runaway feedback, the authors demonstrated ways of altering the model inputs, though which predictive policing systems, which are able to overcoming the runaway feedback loop and, therefore, capable of learning the true crime rate, can be produced.
Models of strategic manipulation is a category of models that attempt to capture the dynamics between a classifier and agents in an environment, where all of the agents are capable, to the same degree, of manipulating their features in order to deceit the classifier into making a decision in their favour. In real world social environments, however, an individual’s ability to adapt to an algorithm does not merely relate to their personal benefit of getting a favourable decision, instead it heavily depends on a number of complex social interactions and factors within the environment. In [
82] strategic manipulation models were studied and adapted in an environment of social inequality, in which different social groups have to pay different costs of manipulation. It was proven that, in such a setting, a decision making model exhibited a behaviour where some members of the advantaged group incorrectly received a favourable decision, while some members of the disadvantaged group incorrectly received a non-favourable one. The results also demonstrated that any tools attempting to evaluate an individual’s fitness or eligibility can potentially have harmful social consequences when the individuals’ capacities to adaptively respond differ. Finally, the authors conclude that the increasing use of decision-making machine learning tools in our imperfect social world will require the design of suitable models and the development of a sound theoretical background that would explicitly address critical issues, such as social stratification and unequal access, in order for true fairness to be achieved.
Milli et al. [
83] also studied how individuals adjust their behaviour strategically to manipulate decision rules in order to gain favourable treatment from decision-making models. They reiterated that the design of more conservative decision boundaries in an effort to enhance robustness of decision making systems against such forms of distributional shift is significantly needed in order for fairness to be achieved. However, the authors showed, through experimentation, that although stricter decision boundaries add benefit to the decision maker, this is done at the expense of the individuals being classified. There is, therefore, some trade-off between the accuracy of the decision maker and the impact to the individuals in question. More specifically, a notion of “social burden” was introducedin order to quantify the cost of strategic decision making as the expected cost that a positive individual needs to meet to be correctly classified as positive, and it was proven that any increase in terms of the accuracy of the decision maker necessarily corresponds to an increase in the social burden for the individuals. Lastly, they empirically demonstrated that any extra costs occurring for individuals have the potential to be disproportionately harmful towards the already disadvantaged groups of individuals, highlighting that any strategy towards more accurate decision making must also weigh in social welfare and fairness factors.
Counterfactual fairness, which is defined strictly in [
84], attempts to capture the intuition that a decision affecting an individual is fair if it would affect the same individual in the same way both the actual world and in a counterfactual world, where the individual would be a member of a different demographic group. In the same study, it was argued that it was crucial for causality in fairness to be addressed and subsequently a framework for modeling fairness using tools from causal inference was proposed. According to the authors, any measures of causality in fairness measures should not only consist of quantities free of counterfactuals, but is also essential that counterfactual causal guarantees are pursued. The proposed framework, which is based on the idea of counterfactual fairness, allows for the users to produce models that, instead of merely ignoring sensitive attributes that potentially reflect social biases towards individuals, are able to take such features into consideration and compensate for them accordingly.
The fairness of word embeddings, a vectorised representation of text data, used in many real world machine learning application, was studied in [
85] and it was revealed that word embeddings, even those that were trained on Google News articles, carry strong gender bias. More specifically, two very useful, in terms of embedding debiasing, properties were shown. Firstly, it was shown that there exists a direction in the embedding space towards which gender stereotypes can be captured. Secondly, it was shown that gender neutral words can be linearly separated from gender definition words in the embedding space. Subsequently, metrics for quantifying both the direct and indirect gender stereotypes present in the word embeddings were created and an algorithm that utilises the previous two properties and tweaks the embedding vectors in order for gender bias to be removed was proposed by the authors.
According to [
86], fairness should be realised not only segment-wise, but also at an individual level. In order to achieve this, fairness was formulated into a data representation problem, where any representations learnt would need to be optimised towards two competing objectives: similar individuals should have similar encodings; however, such encodings should be ignorant of any sensitive information regarding the individual.
In [
87], three approaches for making the naive Bayes classifier discrimination-free were proposed. The first approach was to regulate the conditional probability distribution of the sensitive feature values given that the label is positive, by simply boosting the probability of the disadvantaged sensitive feature values given the positive label, while, at the same time, decreasing the probability of the favoured sensitive feature values given the positive label. While easy to follow and implement, this approach brings the downside of either reducing or boosting the number of positive labels that are produced by the model, depending on the difference between the frequency of the favoured sensitive values and frequency of the discriminated sensitive values in the input data. The second approach involves training a different model for every sensitive attribute value. The case where a sensitive feature has two values, and, therefore, two models were trained, was illustrated: one model was developed using only the rows that had a favoured sensitive value, while another model only utilised the rows that had a discriminated sensitive value. The different models are part of a meta-model, where discrimination is mitigated by adjusting the conditional probability, as described in the first approach. In the third approach, a latent variable is introduced to the modelling procedure, which corresponds to the non-biased label and the model parameters were optimized towards likelihood-maximisation while using the expectation-maximization (EM) algorithm.
In [
88], a framework for fair classification, which consisted of two parts, was presented. More specifically, the first part involves the development of a task-specific metric in order to evaluate the degree of similarity among individuals with respect to the classification task, whereas the second part consists of an algorithmic procedure that is capable of maximizing the objective function, subject to the fairness constraint, according to which, similar decisions should be made for similar individuals. Furthermore, the framework was adjusted towards the much related goal of guaranteeing statistical parity, while, as previously, ensuring that similar individuals are provided with analogous decisions. Finally, the close relationship between privacy and fairness was discussed and, more specifically, how fairness can be further promoted using tools and approaches developed within the framework of differential privacy.
The difference between the fairness of the decision making process, also known as procedural fairness, and the fairness of the decision outcomes, also known as distributive fairness, was brought up by the authors of [
89], who also emphasised that the majority of the scientific work on machine learning fairness revolved around the latter. For this gap to be bridged, procedural fairness metrics were introduced in order for the impact of input features used in the decision to be taken into consideration and for the moral judgments of humans regarding the use of these features to be quantified.
Building on from [
90], where the concept of meritocratic fairness was introduced, Kearns et al. [
91] performed a more comprehensive analysis on the broader issue of realising superior guarantees in terms of performance, while relaxing the model assumptions. Furthermore, the issue of fairness in infinite linear bandit problems was studied and a scheme for meritocratic fairness regarding online linear problems was produced, which was significantly more generic and robust than the existing methods. Under this scheme, fairness is satisfied by ensuring optimality in terms of reward: no actions that lead to preferential treatments are taken, unless the algorithm is certain that the reward of such an action would be higher reward. In practice, this is achieved by calculating confidence intervals around the expected rewards for the different individuals and, based on this process, two individuals are said to be linked if their corresponding confidence intervals are overlap**, and chained if they can reach each other through a chain of intermediate linked individuals.
The fact that the majority of notions or definitions of machine learning fairness merely focus on predefined social segments was criticised in [
96]. More specifically, it was highlighted that such simplistic constraints, while forcing classifiers to achieve fairness at segment-level, can potentially bring discrimination upon sub-segments that consist of certain combinations of the sensitive feature values. As a first step towards addressing this, the authors proposed defining fairness across an exponential or infinite number of sub-segments, which were determined over the space of sensitive feature values. To this end, an algorithm that produces the most fair, in terms of sub-segments, distribution over classifiers was proposed. This is achieved by the algorithm through viewing the sub-segment fairness as a zero-sum game between a Learner and an Auditor, as well as through a series of heuristics.
Following up from other studies demonstrating that the exclusion of sensitive features cannot fully eradicate discrimination from model decisions, Kamishima et al. [
99] presented and analysed three major causes of unfairness in machine learning: prejudice, underestimation, and negative legacy. In order to address the issue of indirect prejudice, a regulariser that was capable of restricting the dependence of any probabilistic discriminative model on sensitive input features was developed. By incorporating the proposed regulariser to logistic regression classifiers, the authors demonstrated its effectiveness in purging prejudice.
In [
92], a framework for quantifying and reducing discrimination in any supervised learning model was proposed. First, an interpretable criterion for identifying discrimination against any specified sensitive feature was defined and a formula for develo** classifiers that fulfil that criterion was introduced. Using a case study, the authors demonstrated that, according to the defined criterion, the proposed method produced the Bayes optimal non-discriminating classifier and justified the use of postprocessing over the altering of the training process alternative by measuring the loss that results from the enforcement of the non-discrimination criterion. Finally, the potential limitations of the proposed method were identified and pinpointed by the authors, as it was shown that not all dependency structures and not all other proposed definitions or intuitive notions of fairness can be captured while using the proposed criterion.
Pleiss et al. [
97], building on from [
92], studied the problem of producing calibrated probability scores, the end goal of many machine learning applications, while, at the same time, ensuring fair decisions across different demographic segments. They demonstrated, through experimentation on a diverse pool of datasets, that probability calibration is only compatible with cases where fairness is pursued with respect to a single error constraint and concluded that maintaining both fairness and calibrated probabilities, although desirable, is often nearly impossible to achieve in practice. For the former cases, a simple postprocessing technique was proposed that calibrates the output scores, while, at the same time, maintaining fairness by suppressing the information of randomly chosen input features.
Celis et al. [
98] highlighted that, although efforts have been made in recent studies to achieve fairness with respect to some particular metric, some important metrics have been ignored, while some of the proposed algorithms are not supported by a solid theoretical background. To address these concerns, they developed a meta-classifier with strong theoretical guarantees that can handle multiple fairness constraints with respect to multiple non-disjoint sensitive features, thus enabling the adoption and employment of fairness metrics that were previously unavailable.
In [
94], a new metric for evaluating decision boundary fairness both in terms of disparate treatment and disparate impact at the same time, with respect to one or more sensitive features was introduced. Furthermore, utilising this metric, the authors designed a framework comprising of two contrasting formulations: the first one optimises for accuracy subject to fairness constraints, while the second one optimises towards fairness subject to accuracy constraints. The proposed formulations were implemented for logistic regression and support vector machines and evaluated on real-world data, showing that they offer fine-grained control over the tradeoff between the degree of fairness and predictive accuracy.
Following up from their previous work [
94], Zafar et al. [
93] introduced a novel notion of unfairness, which was defined through the rates of misclassification, called disparate mistreatment. Subsequently, they proposed intuitive ways for measuring disparate mistreatment in classifiers that rely on decision boundaries to make decisions. By experimenting on both synthetic and real world data, they demonstrated how easily the proposed measures can be converted into optimisation constraints, thus incorporated in the training process, and how well they work in terms of reducing disparate mistreatment, while maintaining high accuracy standards. However, they warned of the potential limitations of their method due to the absence of any theoretical guarantees on the global optimality of the solution as well as due to the the approximation methods used, which might prove to be inaccurate when applied to small datasets.
In another work by Zafar et al. [
100], it was pointed out that many of the existing notions of fairness, regarding treatment or impact, are too rigorous and restrictive and, as a result, tend to hinder the overall model performance. In order to address this, the authors proposed notions of fairness that are based on the collective preference of the different demographic groups. More specifically, their notion of fairness tries to encapsulate which treatment or outcome would the different demographic groups prefer when given a list of choices to pick from. For these preferences to be taken into consideration, proxies that capture and quantify them were formulated by the authors and boundary-based classifiers were optimised with respect to these proxies. Through empirical evaluation, while using a variety of both real-world and synthetic datasets, it was illustrated that classifiers pursuing fairness based on group preferences achieved higher predictive accuracy than those seeking fairness through strictly defined parity.
Agarwal et al. [
95] introduced a systematic framework that incorporates many other previously outlined definitions of fairness, treating them as special cases. The core concept behind the method is to reduce the problem of fair classification to a sequence of fair classification sub-problems, subject to the given constraints. In order to demonstrate the effectiveness of the framework, two specific reductions that optimally balance the tradeoff between predictive accuracy and any notion of single-criterion definition of fairness were proposed by the authors.
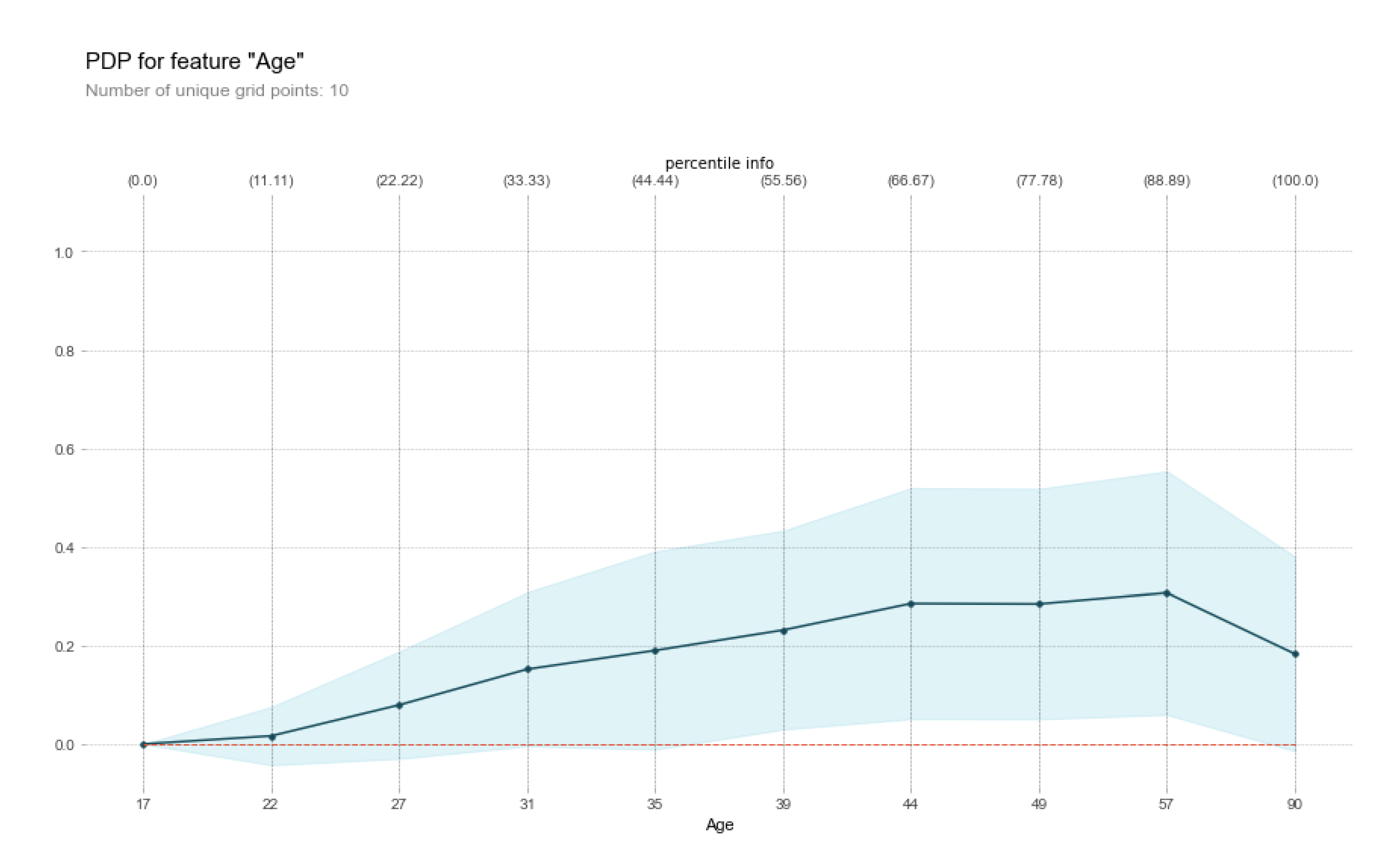
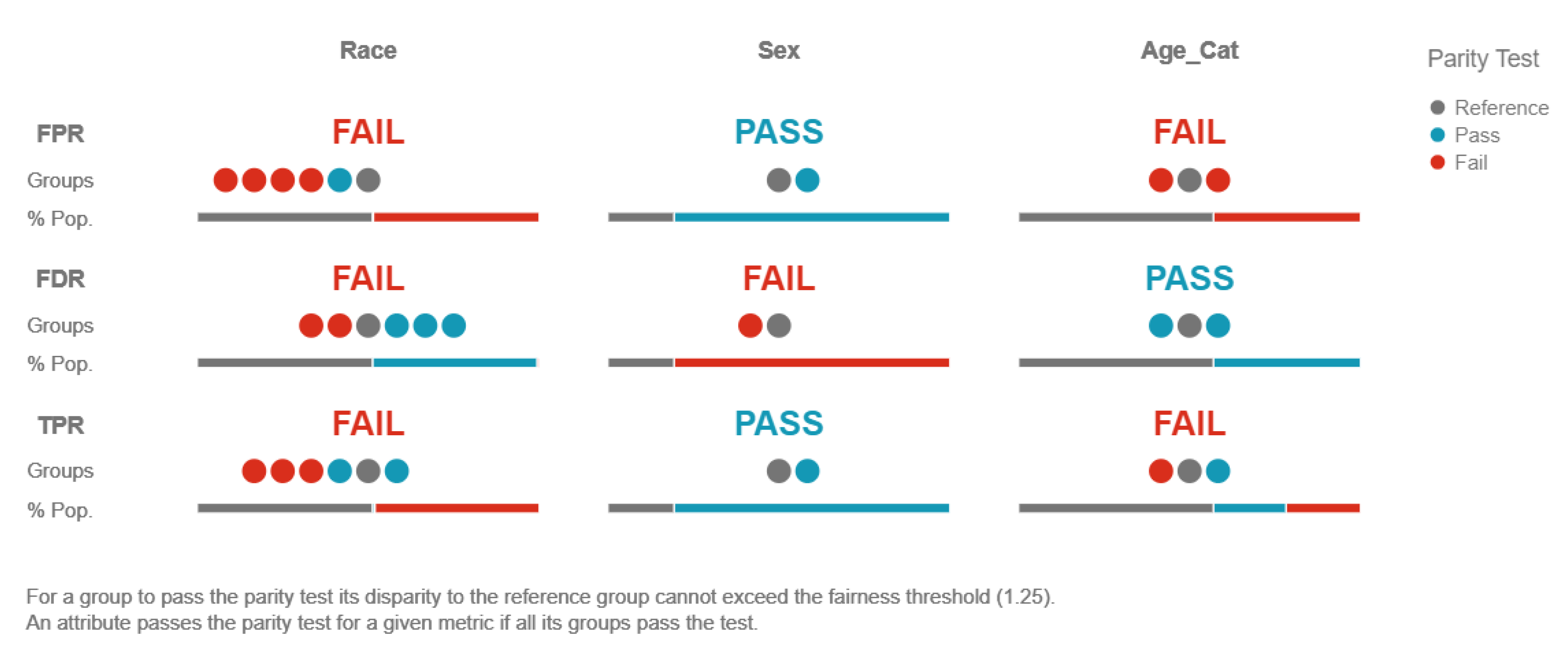
In
Figure 6 and
Figure 7, the use of machine learning interpretability methods to reduce discrimination and promote fairness is presented. More specifically, in
Figure 6 parity testing is applied using the aequitas library on the ProPublica COMPAS Recidivism Risk Assessment dataset, whereas in
Figure 7, a comparison of the level of race bias (bias disparity) among different groups in the sample population is shown.
In conclusion, fairness is a relatively new domain of machine learning interpretability, yet the progress made in the last few years has been tremendous. Various methods have been created in order to protect disadvantaged demographic segments against social bias and ensure fair allocation of resources. These different methods concern data manipulations prior to model training, algorithmic modifications within the training process as well as post-hoc adjustments. However, most of these methods, regardless of which step of the process they are applied, focus too much on group-level fairness and often ignore individual-level factors both within the groups and at a global scale, potentially mistreating individuals in favour of groups. Furthermore, only a tiny portion of the scientific literature is concerned with fairness in non-tabular data, such as images and text; therefore, a large gap exists in these unexplored areas that are to be filled in the coming years.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







