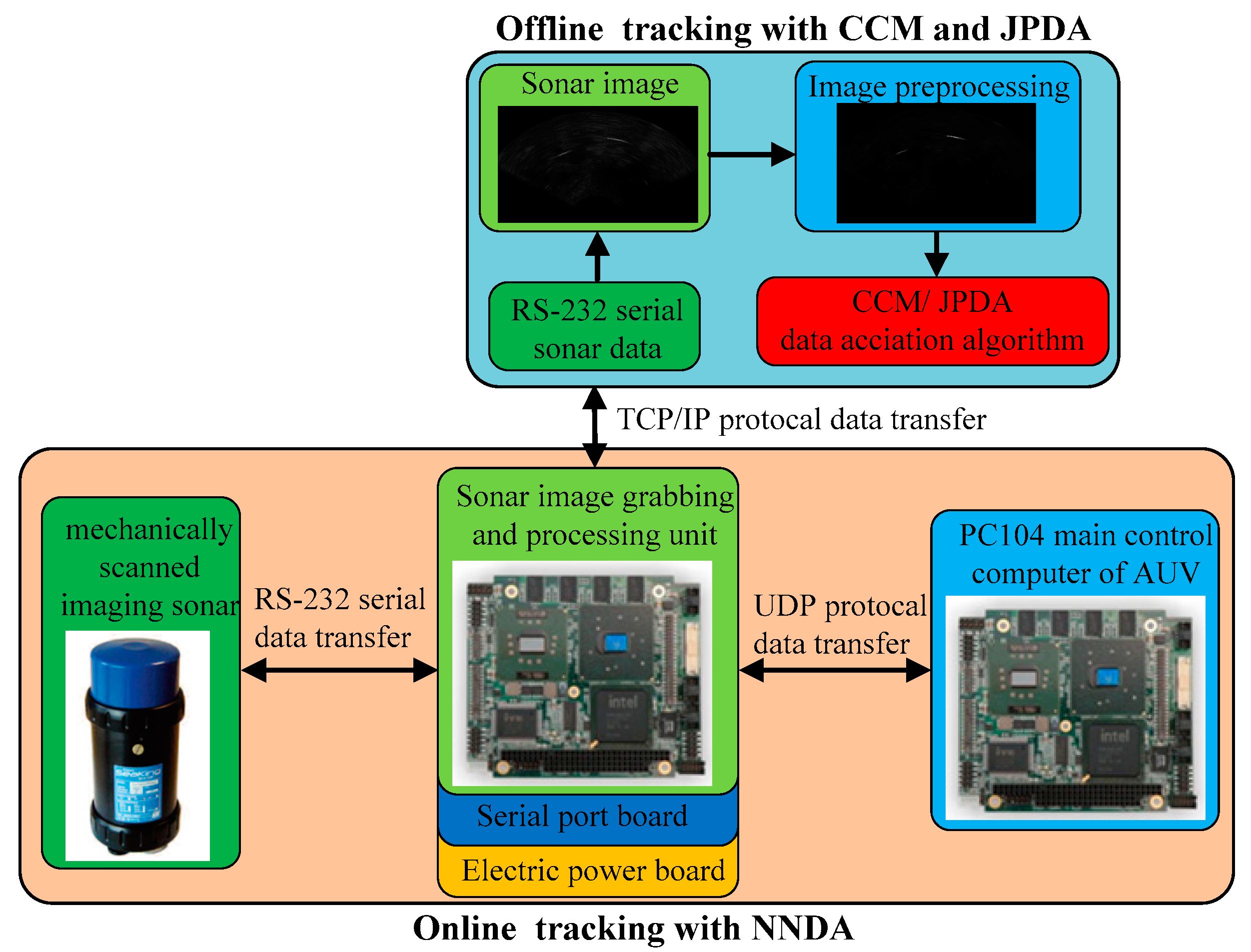
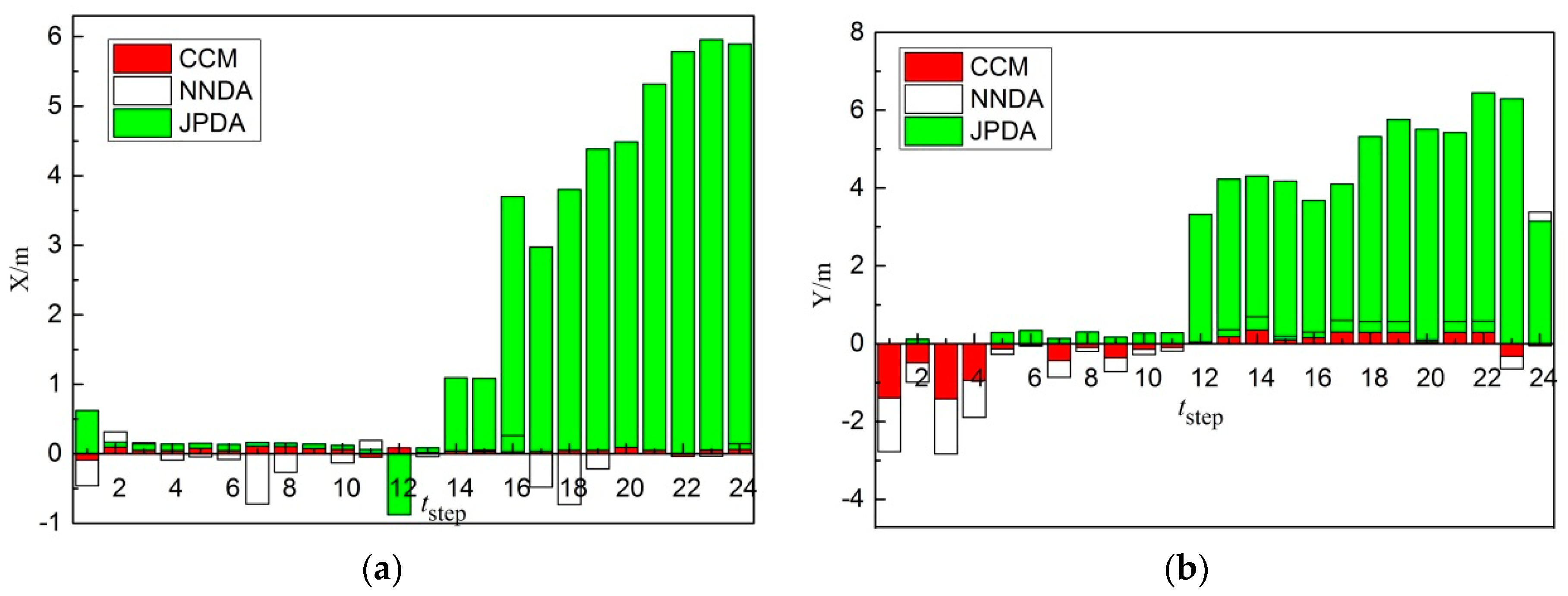
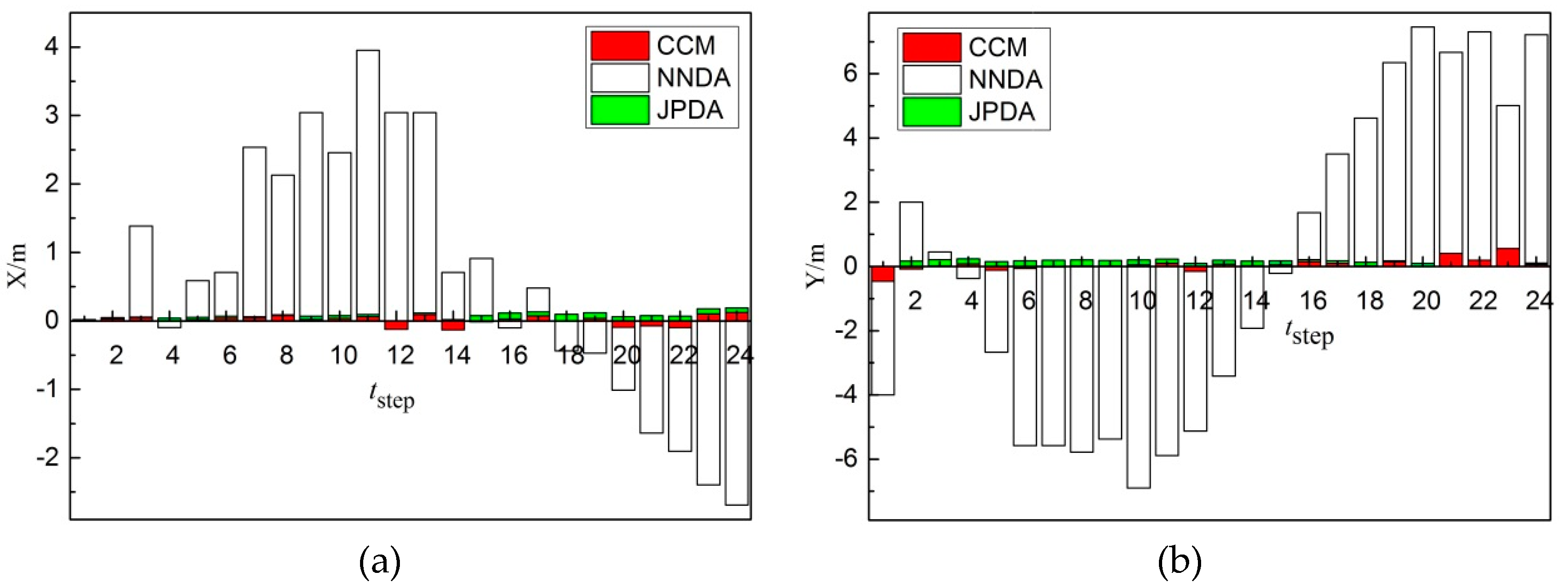
Data association is a significant process for underwater multiple targets tracking. To settle the issue of data association in the multi-target tracking, a data association algorithm in line with the clustering cloud-like model is proposed.
3.1. The Clustering Algorithm Based on the Cloud-Like Model
The cloud-like model combines the fuzziness and randomness of the qualitative concept, which can achieve the conversion of the qualitative linguistic values and quantitative values. Moreover, the model can change the qualitative language value into the quantitative value, which is the cloud-like droplet of the model. During the transformation, the cloud-like droplet generation is a random event, and thus it can be described by the probability distribution.
The traditional C-means clustering issue can be described as follows:
P-dimension samples {
x1,
x2, …,
xn} can be divide into
c classes, and each class is represented by a clustering center
vi (
i = 1, 2, …,
c). The degree of membership of the sample in each category can be represented by a classification matrix
U = [
uik]
cn (where
uik represents the degree of membership of the
k-th sample for class
I and
). The clustering aims to find the optimal
U and
for minimizing the objectives function
. In the fuzzy C-means clustering method (FCM), we computed the membership function as follows:
where
is the suitable norm and
m is the fuzzy weighted index.
In the C-means clustering method based on the model, each class is represented by a cloud-like model. The cloud-like expectation is regarded as its clustering center. The classification matrix is calculated by the mean of the certainty degree of the samples in the cloud-like model. During the transformation, the cloud-like droplet generation is a random event. Therefore, it can be described by the probability distribution. The cloud-like model principally contains the following three digital features: expected value (Ex), entropy (En), and hyper entropy (He). The expected value (Ex) refers to the expected value of a cloud-like droplet on the spatial distribution of the domain, which remains the most representative value of the qualitative concept. Generally, the greater the entropy (En) is, the more macroscopic the concept will be in the cloud-like model. Additionally, it is determined by the randomness and fuzziness of the concept. En is the measurement of the qualitative concepts of randomness, reflecting the dispersion degree of the cloud-like droplets that represent this qualitative concept. Furthermore, it is the measure of the qualitative concepts of fuzziness, which signifies the value range of the cloud-like droplets accepted in the domain. The measurement of the hyper entropy’s (He) uncertainty, which is the entropy of the entropy, is jointly decided by the randomness and fuzziness of the entropy, reflecting the condensation degree of the cloud-like droplets.
Supposing (
Ex,
En, and
He) is the
i-th class
P-dimension cloud-like model, and
Ex,
En, and
He is a
P-dimension vector, respectively. The clustering center is
and the elements of the classification matrix are Equation (2).
where
,
, and
are the
l-dimension elements of
,
, and
, respectively.
The clustering objective function of CCM is similar to FCM, and the clustering objective function is as follows:
Under a constraint condition (the normalization condition ), FCM gets the iterative formula adopting the iterative solution through the Lagrange multiplier method. Without the above constraints, the objective function of CCM is computed using the iteration of the forward and reverse cloud-like transformation. Considering that the sample set for clustering here is the underwater target sonar image data, there is the random uncertainty (each sample is subject to some unknown probability distribution) and fuzzy uncertainty (each sample is a small sample set). The cloud-like model can depict fuzziness and randomness simultaneously, and thus the C-means clustering on the basis of the cloud-like model is involved in the data association so as to avoid the dependence of the clustering algorithm on the normalization conditions.
3.2. Multi-Target Data Association Algorithm Based on the C-Means Clustering Cloud-Like Model
Based on the above section, this section will cluster all of the valid echoes (targets in the sonar image) by the clustering algorithm using the cloud-like model. Then, the nearest neighbor method is involved to associate the targets. The cluster centers of the multiple targets are regarded as the final measurement for the given target for the state estimation. Supposing there are m echoes and t targets, the procedure is as follows:
(1) At the beginning of the track update cycle, the basic information concerning the prediction state vector
, the prediction measurement vector
, the innovation covariance
, and the gain
of the target
can be computed by Equations (4) to (8).
where
is the state transition matrix,
is the measurement matrix,
is the prediction covariance,
is the process noise covariance matrix, and
is the measurement noise covariance matrix.
(2) Before performing the multiple targets data association calculation, we should check if all of the measurements fall into the tracking wave gate. If
, it is regarded as a valid target, where
is the threshold value of tracking the wave gate.
is the measuring information about measurement
i to target
j, as given in Equation (9), as follows:
where
is the measurement acquired from the sonar.
(3) The CCM algorithm is presented to cluster the effective targets, which fall into the tracking wave gate in order to obtain the center of the cluster . The calculation process is as follows:
① We initialize
U(0) and
, where
② According to the rule of maximum degree of membership, U(b) is utilized to classify the target effective targets {Z1(k + 1), Z2(k + 1),…, Zmq(k + 1)} into t classes. For each class of measurement targets, the cloud-like model in the b-th dimension is calculated by a non-deterministic inverse cloud-like generator, where j = 1, 2, …, t and l = 1, 2, …, p.
③ A new classification matrix
is calculated in accordance with each cluster of the cloud-like model, as shown in Equation (11), as follows:
where
Zil(
k + 1)
(l = 1, 2, …,
p) is the
l-th dimension of the
i-th measurement information;
is the
l-th dimension of the mean of the
j-th cloud-like model, and it is a random number generated from the
l-th dimension’s the entropy
and the super-entropy
of the
j-th cloud-like model.
④ We have the clustering objective function as follows:
where
is a matrix composed of each of the cloud-like model’s mean vectors.
⑤ If ( is a predetermined threshold), then the clustering is achieved and . Otherwise, suppose b = b + 1 and return to step ①.
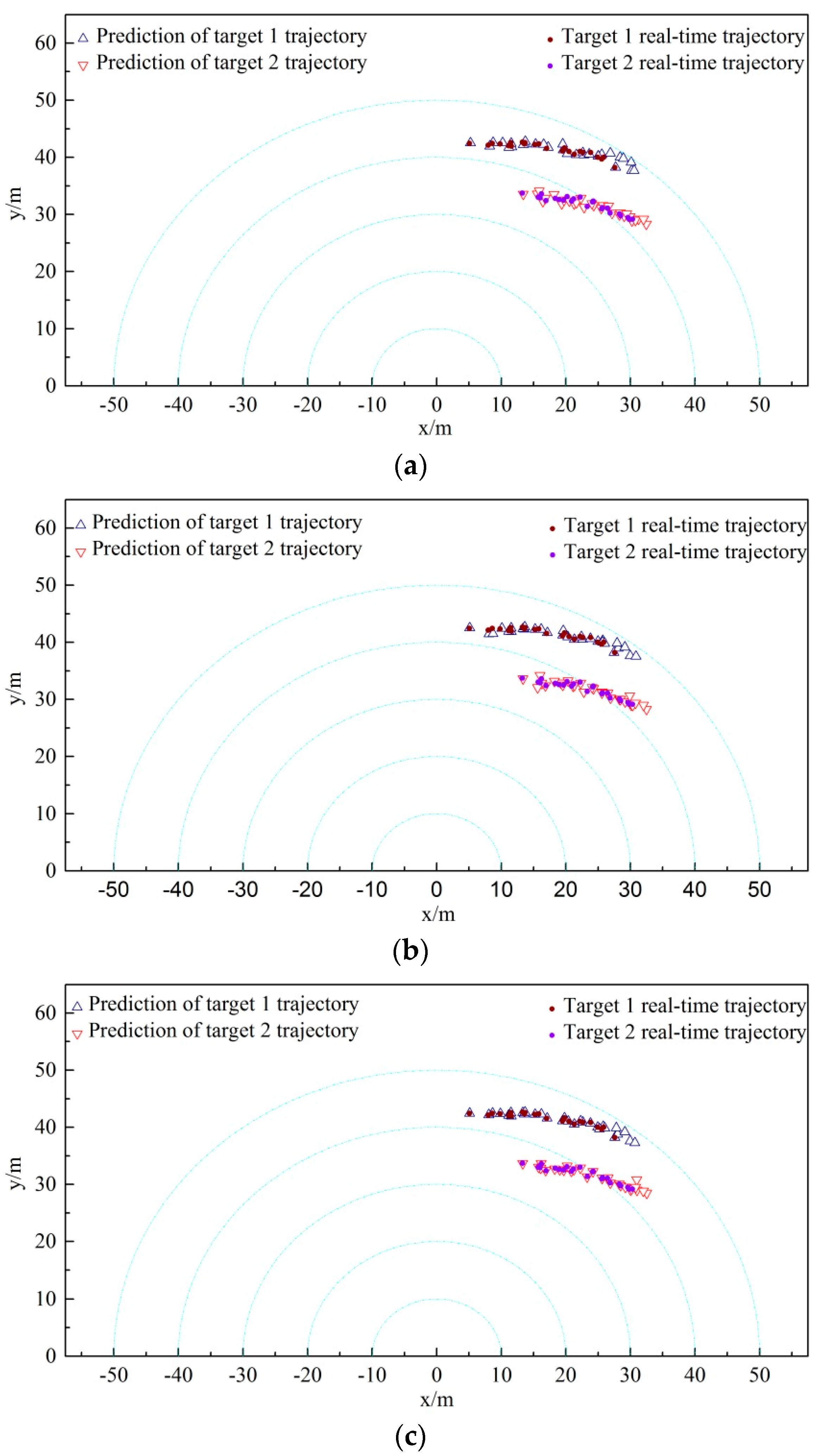
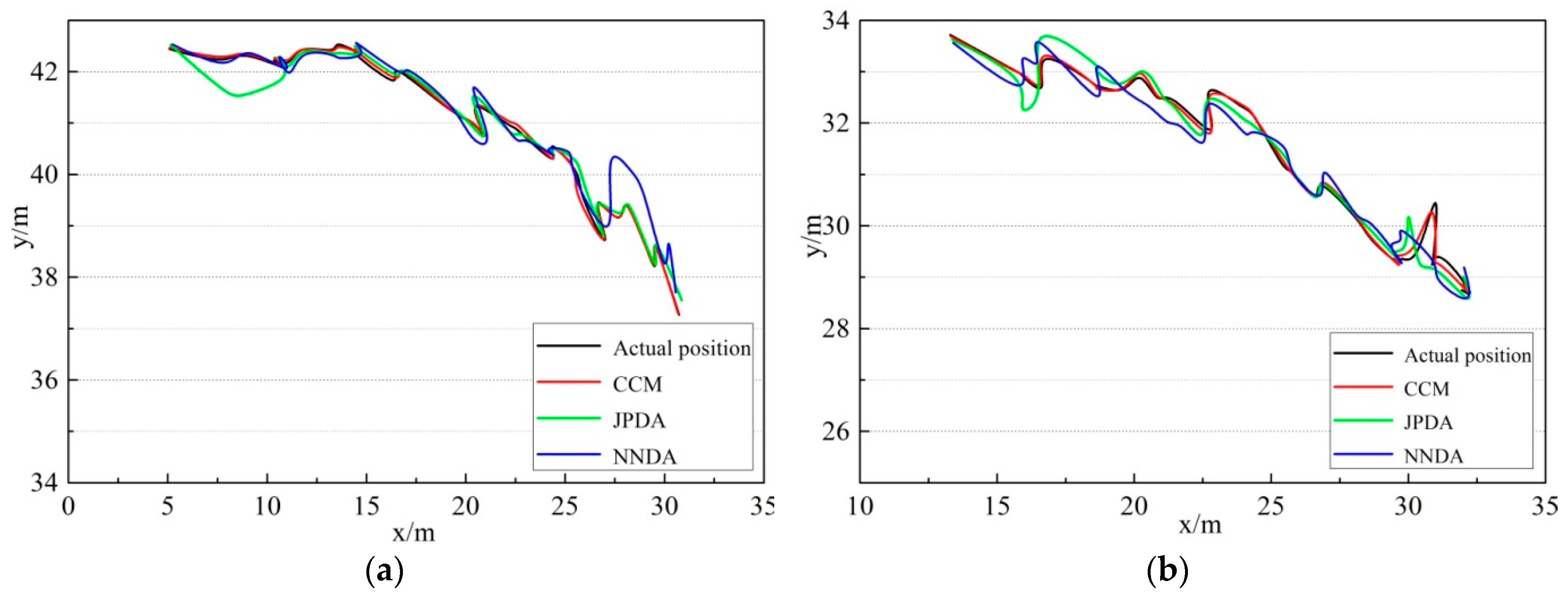
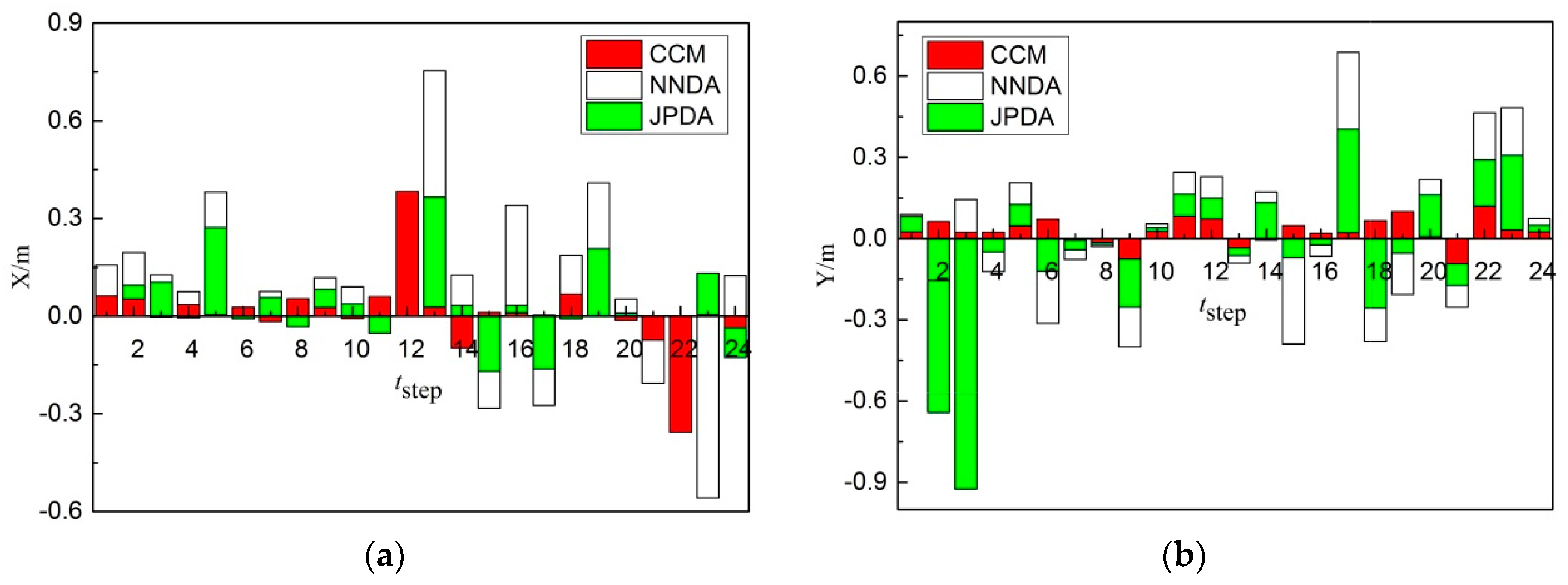
(4) The nearest neighbor algorithm is involved to find the cluster center paired to each target trajectory, and the cluster center is regarded as the final measurement of the corresponding target at time k + 1 (final stage of the track up-date cycle).
(5) The state and covariance of each target can be filtered and updated as follows:



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}