1. Introduction
In recent years, Surface Electromyography(sEMG) signals have been widely used in artificial limb control, medical devices, human-computer interaction, and other fields. With the development of artificial intelligence and robotics technology, the intention of human hand movements can be obtained by using an artificial intelligence algorithm to analyze the sEMG signals collected from the residual limb. Robotics and artificial intelligence can be leveraged to better help the disabled people to independently complete some basic interactions in their daily life. The sEMG signals, which are non-stationary, represent the sum of subcutaneous athletic action potentials generated through muscular contraction [
1]. Also, it is one of the main physical signals of an intelligent algorithm to identify motion intention.
Distinguishing sEMG signals collected from different gestures is the core part of the related applications using sEMG signals as intermediate media. At present, the literature on gesture recognition or artificial limb control by sEMG signals primarily focuses on the time and frequency domain feature extraction of sEMG signals, which aims to distinguish sEMG signals by feature recognition [
1,
2,
3]. After years of exploration by researchers, some effective feature combinations have been proposed in both the time domain and frequency domain [
4,
5,
6], and some fruitful results have been achieved with their respective datasets. Choosing feature extraction is particularly important in that different gestures can be distinguished by traditional methods. However, it is difficult to improve the performance of gesture recognition based on sEMG by traditional methods. Nevertheless, the process of designing and selecting features can be complicated and the combinations of features are diverse, leading to increasing of workload and dissatisfied results [
7].
Using deep neural networks to distinguish sEMG signals has been proposed by researchers. Wu et al. [
7] proposed LCNN and CNN_LSTM models (These models can be thought of as autoencoders for automatic feature extraction.), which do not require the process of traditional feature extraction. In recent years, deep learning has achieved great success in the field of image recognition. An important idea was put forward in [
8,
9] that the signals of a channel can form a graph, after the short- time Fourier transform or wavelet transform of sEMG signals. It was a good idea to convert the sEMG signal into an image and inspired us with the transform of the sEMG signal. Researchers such as Côté-Allard et al. [
8], who regarded the original sEMG signals as an image, constructed the ConvNet model to further improve the classification accuracy of sEMG signals. However, the LCNN and CNN_LSTM models proposed by Wu et al. [
7], and the ConvNet model used by Côté-Allard et al. [
8], contain a large number of parameters.
For deep learning algorithms, the final test accuracy is directly affected by the size of the training data, but one participant cannot be expected to generate tens of thousands of examples in one experiment during the data collection process. However, a large amount of data can be obtained by aggregating the records of multiple participants, so that the model can be pre-trained to reduce the amount of data required by new participants. On the other hand, designing a compact network structure to reduce the number of parameters can also reduce the demand for data size.
In order to reduce the number of model parameters and improve the accuracy of model classification, we present a new compact deep convolutional neural network model for gesture recognition, called as EMGNet. It was validated on the Myo Dataset that the average recognition accuracy of EMGNet can achieve 98.81%. The NinaPro DB5 dataset has often been used to test classical machine learning methods. The accuracy of the EMGNet on these datasets was higher than that of the traditional machine learning methods.
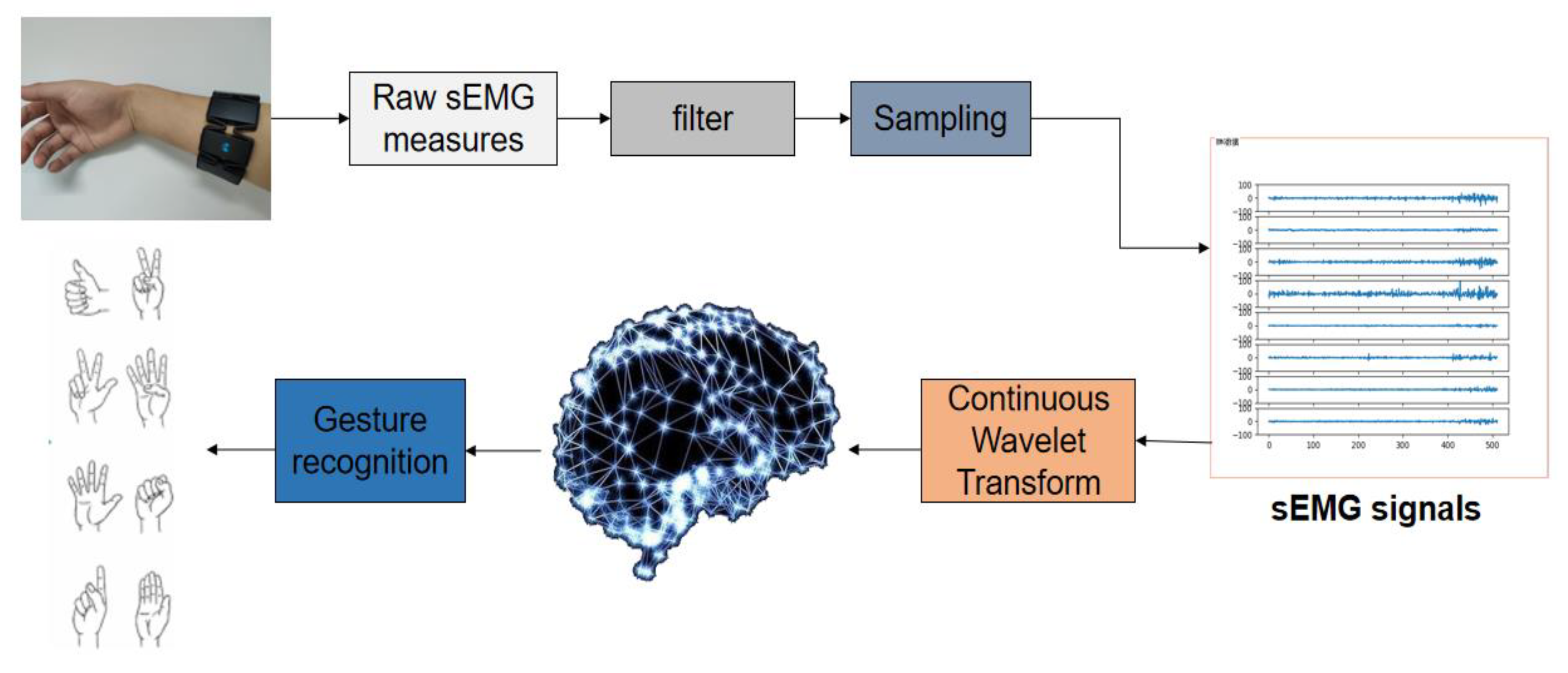
Figure 1 shows the overall flow chart of sEMG signal acquisition and identification.
The rest of this paper is organized as follows. The related work of gesture recognition through deep learning is outlined in
Section 2. The data processing and network architecture are described in detail in
Section 3. The proposed network model is compared with the current excellent deep network framework and the classical machine learning classification method in
Section 4. Finally, we present the conclusion in
Section 5.
2. Related Work
People will produce different signals when completing the same action even lots of precise control electrodes are used to sense them [
10]. Therefore, it is difficult to recognize sEMG signals. Since the AlexNet network proposed by Krizhevksy et al. [
11] won the ImageNet challenge in 2012, deep learning has achieved great success in image classification, speech recognition, and other fields. Images can be accurately classified by training the neural network model to learn the characteristics of images. Nowadays, exploring network architecture has become part of deep learning research.
Currently, some researchers have successfully applied deep learning to sEMG signal classification and explored several effective network frameworks [
8,
12,
13,
14,
15,
16]. Using CNN to classify sEMG signals, literature [
12,
17,
18] took the raw signals as input space. The spectrograms of raw sEMG signals were obtained by Short-Time Fourier Transform (STFT) and fed into the convolutional network (ConvNets) [
13,
19]. Literature [
8] used the ConvNets to classify the characterizations of the sEMG signals extracted by short-time Fourier transform-based spectrogram and Continuous Wavelet Transform (CWT). Since sEMG signals correspond to the timing signal, we proposed to classify the sEMG signal by combining Long Short-Term Memory (LSTM) and CNN from our previous work [
7]. The temporal information in the signal is retained and the ability of CNN to extract features is utilized. We take advantage of the complementarity of CNNs and LSTMs by combing them into one unified architecture. Meanwhile, we analyze the effect of adding CNN before the LSTM. We propose LCNN and CNN-LSTM models, which can directly input pre- processed EMG signals into the network [
7]. In practical work, we verified that the performance of the LCNN model is better than CNN-LSTM.
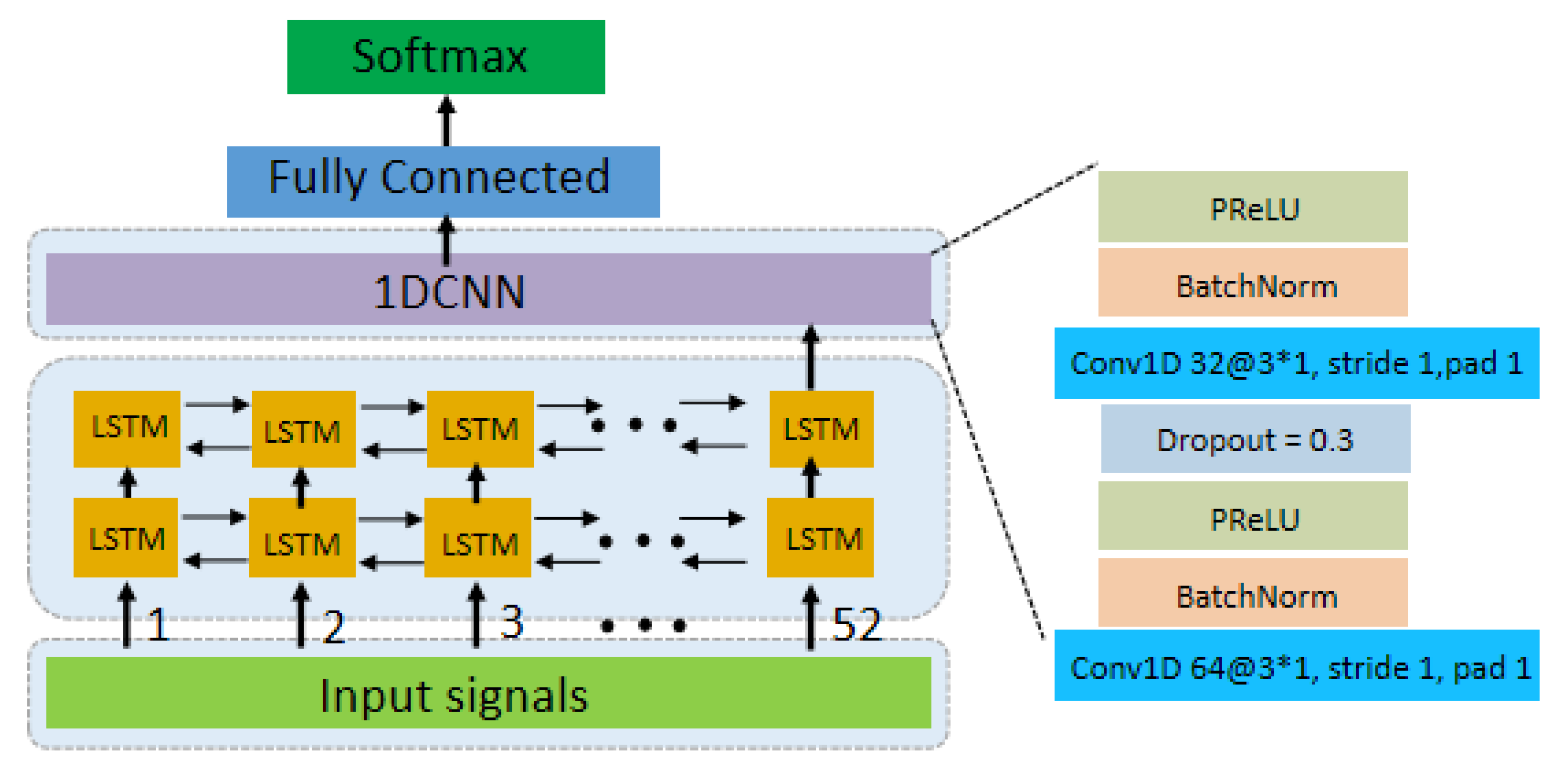
Figure 2 simply depicts the architecture of the LCNN model. We use PReLU [
20] as the non-linear activation function. ADAM [
21] is utilized for the optimization of the model.
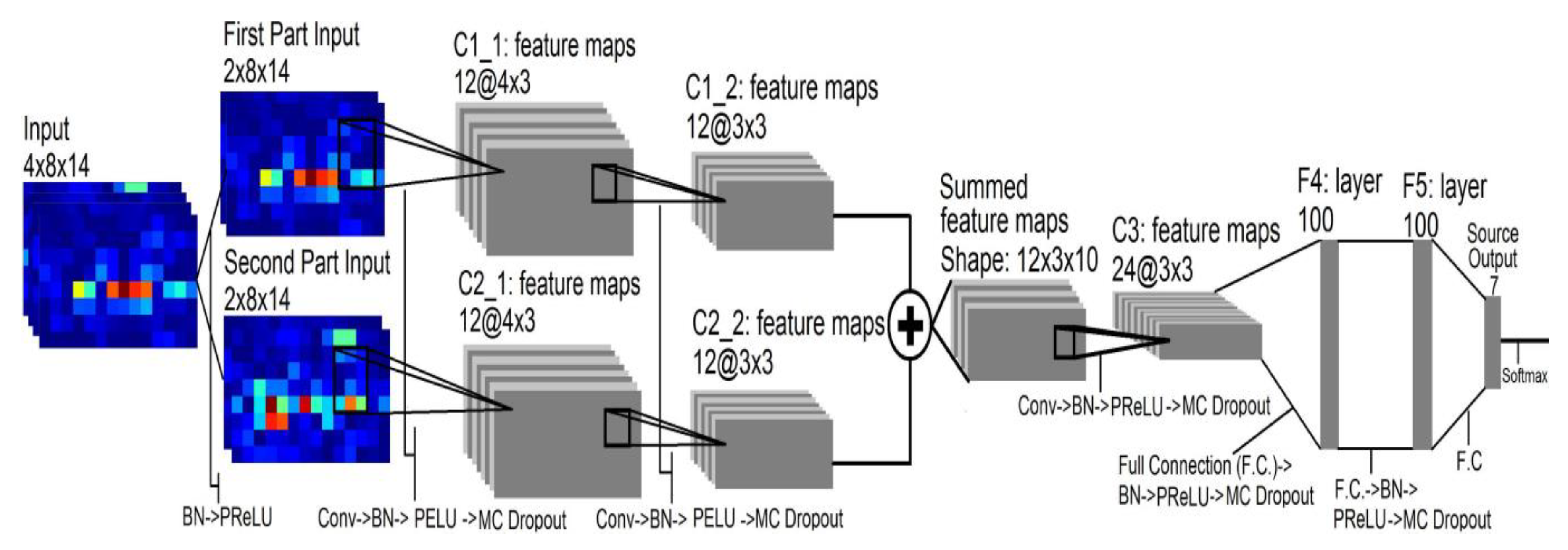
However, the ConvNets model (Shown in
Figure 3) in [
8] was too complicated, and the LSTM model was introduced in [
7], which led to expensive computation in gesture recognition. Therefore, a new network model was proposed in this paper, and it was proved by experiment that this model not only improves the accuracy of recognition, but also reduces the complexity of the network model.
4. Experiment and Results
We evaluated our mode on two publicly available hand gesture recognition datasets composed of Myo Dataset [
8,
9] and NinaPro DB5 Dataset [
6]. First, we compared the method proposed with the methods of classical machine learning and three other methods (CNN-LSTM, LCNN, CWT+TL) on the Myo Dataset [
8,
9]. Then, it was compared with the methods of classical machine learning and the methods (CNN-LSTM, LCNN) proposed earlier on the NinaPro DB5 Dataset [
6].
4.1. Evaluation Dataset
Containing two different sub-datasets, this gesture dataset (Myo Dataset [
8,
9]) was collected using the Myo armband. The first Dataset was used as the pre-training dataset in [
8] and the second includes the part of training and testing. The former is mainly used to establish, verify, and optimize the classification model, which consists of 19 subjects. The latter, used only for final training and validation, consists of 17 participants. The second Dataset contains a training section and two test sections in the literature [
8,
9], which is an unreasonable arrangement and leads to a decrease in the amount of training data. In order to facilitate the comparative experiment, this article uses the same settings. The Myo Dataset contains 7 types of gestures, and there are significant differences between gestures. It provides sufficient amount of data, and its gestures are shown in
Figure 7.
This dataset (NinaPro DB5 [
6]) is based on benchmark sEMG-based gesture recognition algorithms [
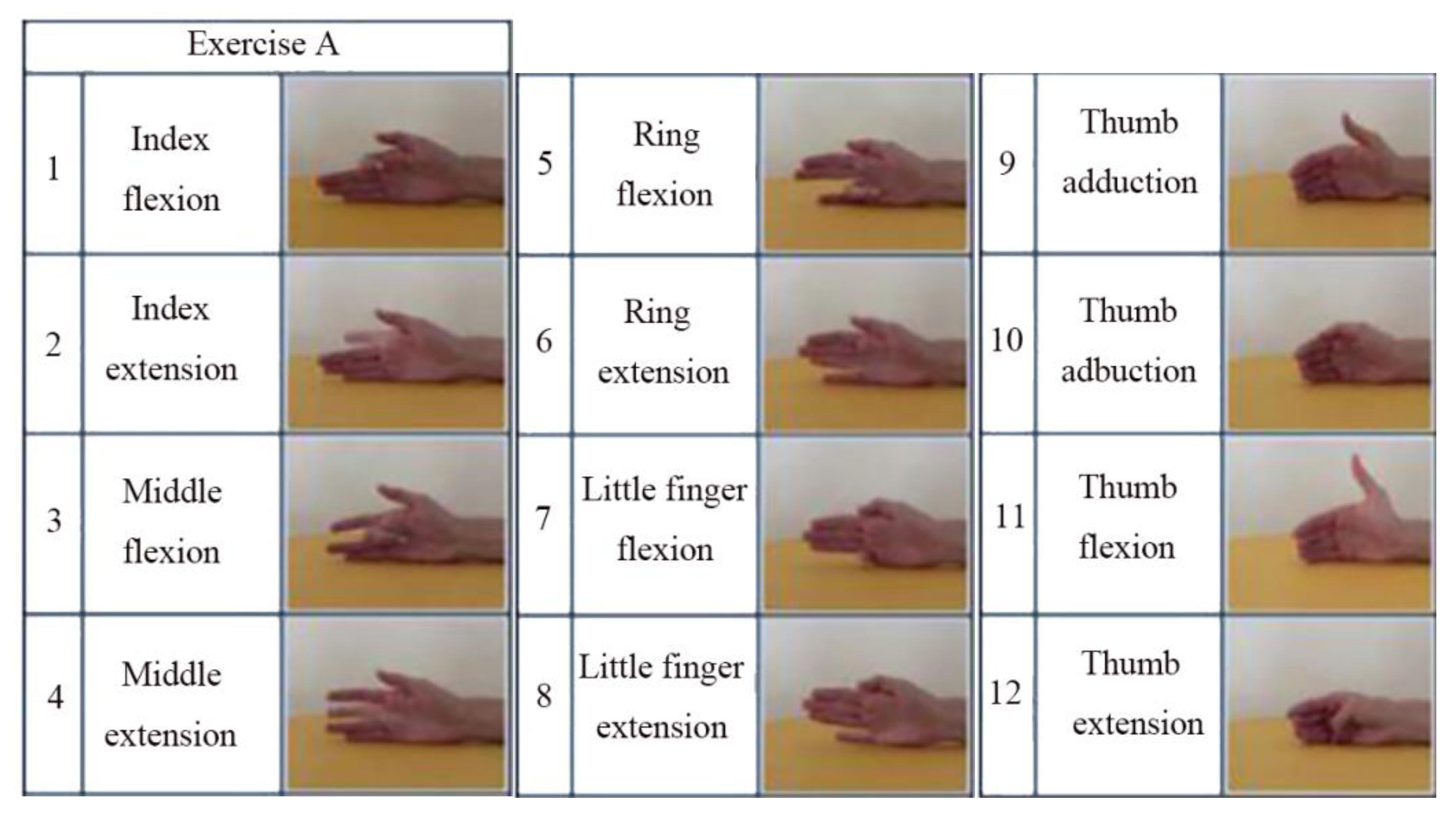
6] containing data from 10 able-bodied participants divided into three exercise sets—Exercise A, B, and C contain 12, 17, and 23 different movements (including neutral) respectively. It is recorded by two Myo armbands, and only one of them is used in this work. One of the characteristics is that there are some similar gestures and the training data is not enough. Therefore, the model is prone to overfitting in the training process.
Figure 8 shows the gesture categories in the dataset of Exercise A.
4.2. Method of Training
Adam [
11] is used as the optimization method of network model training in this work. The length of data collected by each gesture in the two datasets was the same. After the same segmentation method, the data amount of each gesture was the same, and the samples are balanced. In the Myo dataset, each person has 2280 samples for each gesture, with a total of 19 participants, while in the Nina Pro dataset, each person has 1140 samples for each gesture, with a total of 10 participants.
At the same time, after the samples are segmented, we used the shuffle algorithm to shuffle the samples of each gesture, and then took 60% as a training sample set, 10% as the verification sample set, and the last 30% of each gesture as the test sample set.
The amount of data fed into the network by each training batch was 128 samples, and a total of 50 rounds of iterative training were conducted. We initially set the learning rate at 0.01 and shrank the learning rate by 10 times at epoch 20 and 40. In order to prevent over-fitting of the network, L2 regularization is used in this paper. The parameter settings in the training process are shown in
Table 2.
4.3. Myo Dataset Classification Results
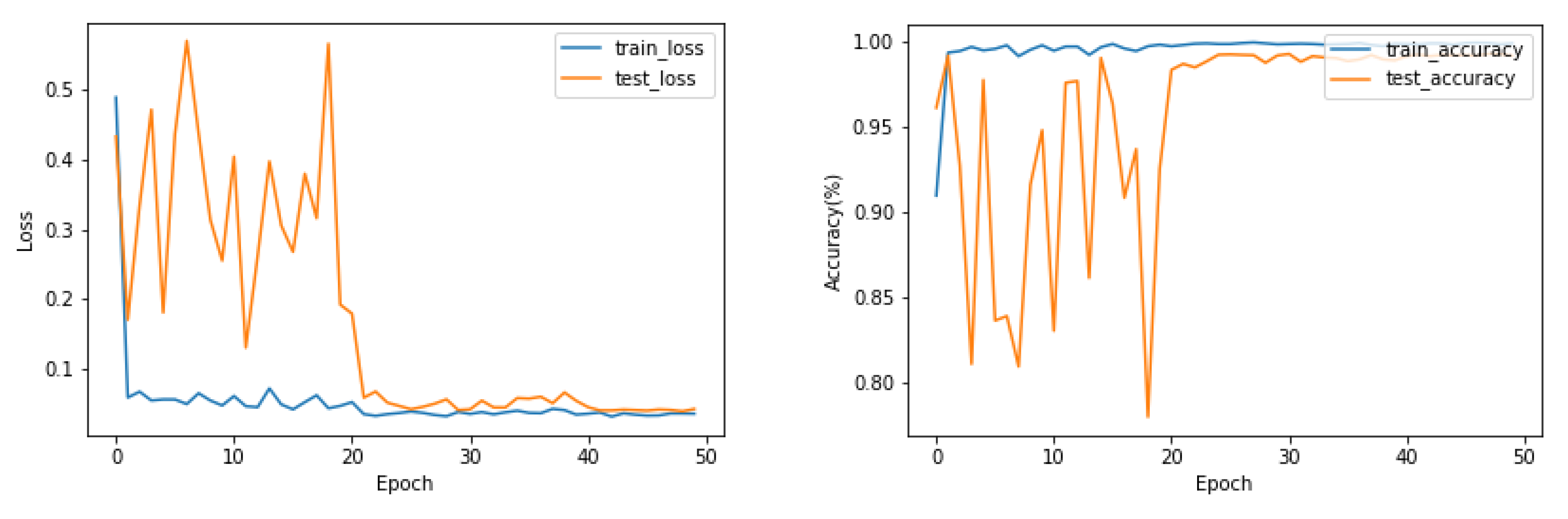
The loss and accuracy curves during training and testing on the Myo Dataset using the EMGNet model are shown in
Figure 9.
As shown in
Figure 9, the EMGNet network successfully completed the classification task in the Myo Dataset, and the over-fitting phenomenon did not appear in the training and testing. We tested the accuracy of our model and compared it with the current three most advanced methods.
Table 3 shows the accuracy of each method. According to the results shown in
Table 3, the accuracy of our proposed model is better than the current advanced methods.
4.4. NinaPro DB5 Dataset Classification Results
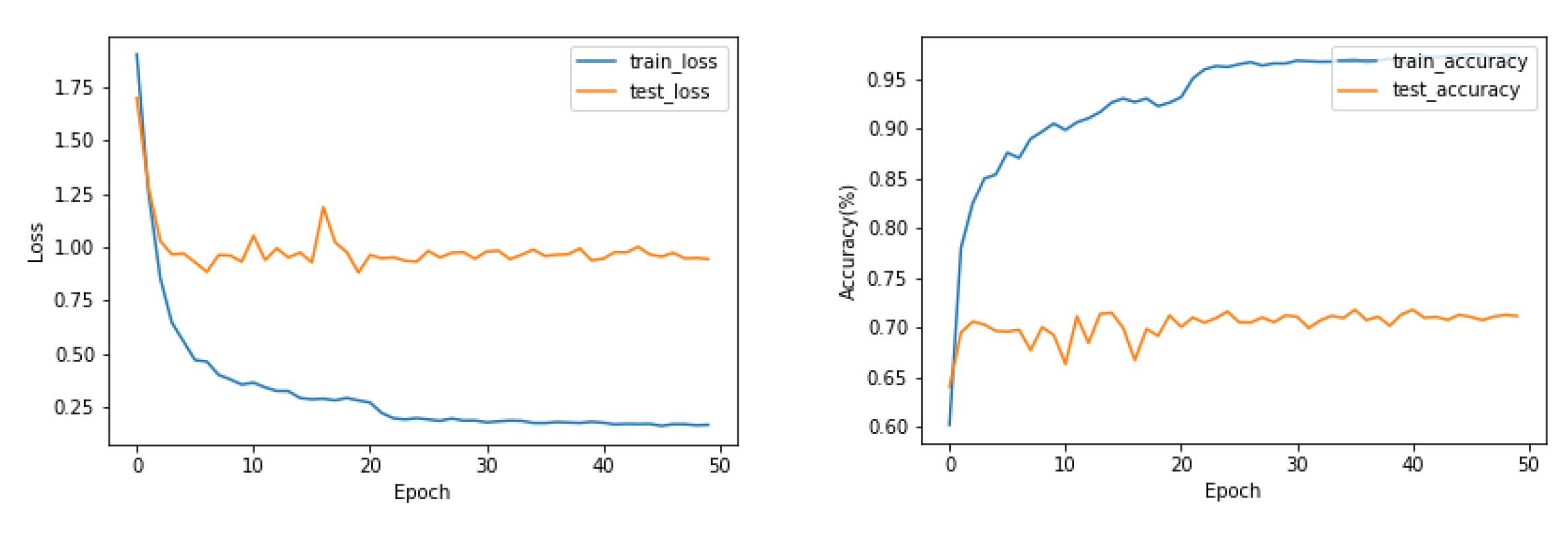
Figure 10 shows that the loss and accuracy curves during training and testing on exercise A of the NinaPro DB5 Dataset. During training of the EMGNet model, the phenomenon of overfitting appears. Reducing the number of layers in the EMGNet does not solve this problem.
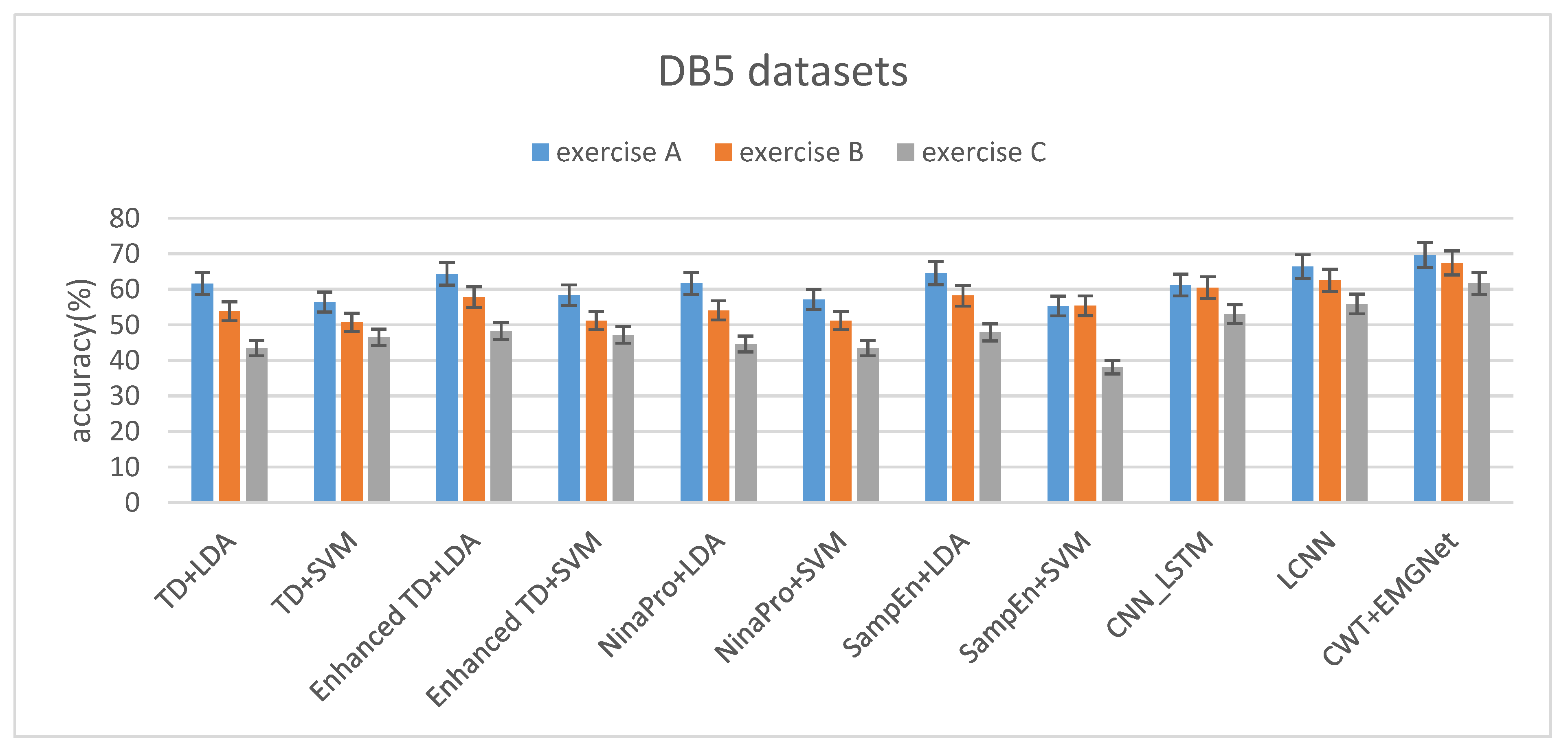
Table 4 shows the accuracy of three subsets of DB5 Dataset. Time domain characteristics (TD) [
5], Enhanced TD [
4], Nina Pro Features [
6,
22] and SampEn Pipeline [
23] were selected as the classification features of the classical machine learning algorithm (LDA and SVM). The LCNN and CNN_LSTM we proposed previously did not perform feature extraction on the data and directly processed the sEMG signal. The proposed method uses continuous wavelet transform (CWT) to process the data as the input of EMGNet. From the experimental results, we can conclude that the classification accuracy of our proposed EMGNet model is higher than that of the classical machine learning algorithm.
With the increase of the categories of gestures, the classification algorithms decline at different degrees. The degree of decline of EMGNet is lower than that of the classical machine learning algorithms (see
Figure 11 and
Table 4).
The classification accuracy of both the classical machine learning method and EMGNet is not as high as that tested on the Myo Dataset (see
Table 4). Two reasons are as follows:
- (1)
The DB5 dataset has a relatively small amount of data per gesture and a relatively large number of gesture categories. For example, there are at most 7 gestures in the Myo dataset, while the smallest exercise A in DB5 dataset has 12 gestures.
- (2)
There are a large number of similar gestures in the DB5 dataset.
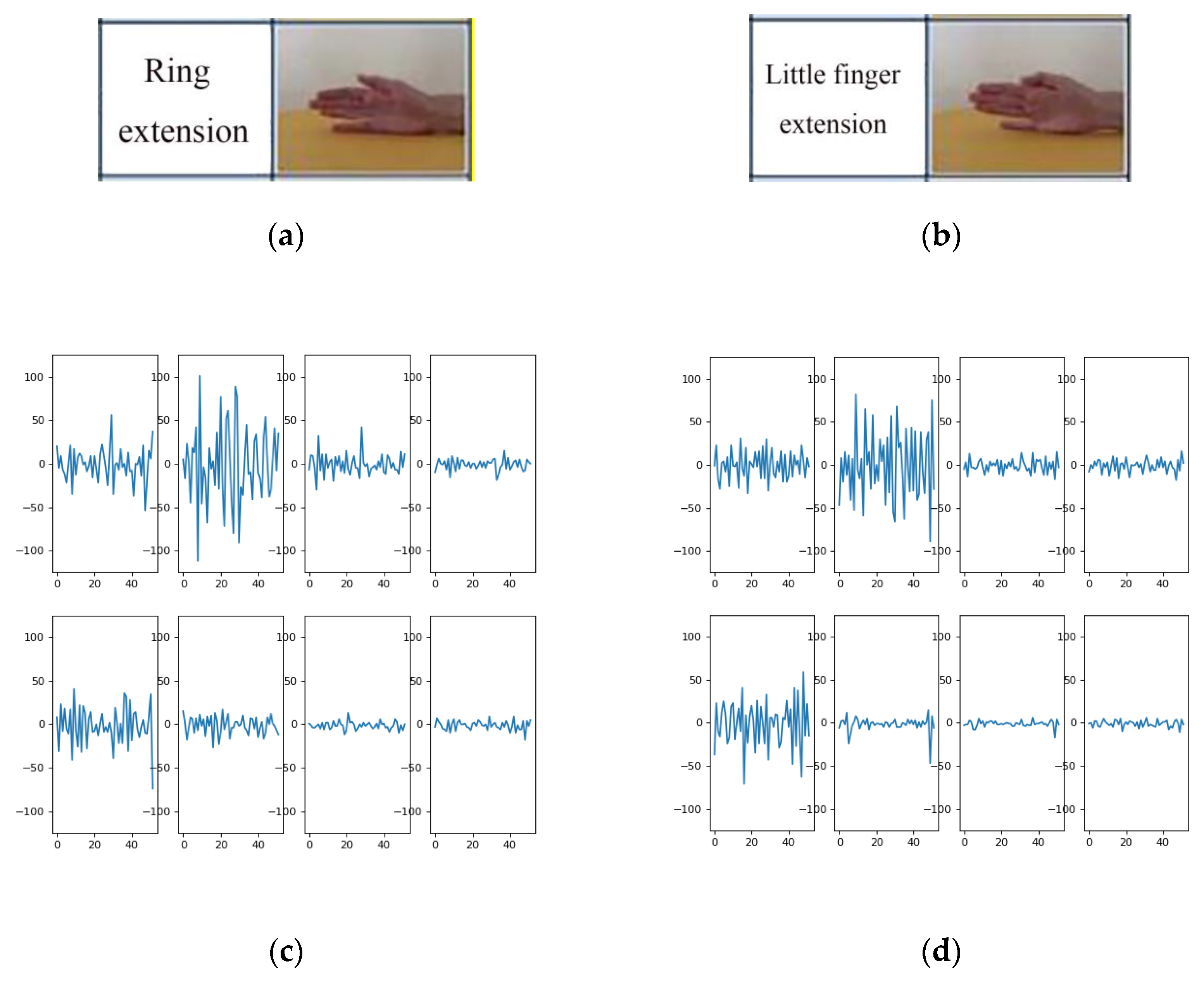
Figure 12 shows the sEMG signal spectrum of two processed samples in exercise A. The two samples shown in
Figure 12c,d belong to different gesture categories, and it can be seen from
Figure 12 that the channels with large fluctuations of the two gestures are almost the same. When the sample number of each gesture is insufficient, the model can easily misidentify it as the same gesture.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}