
A Comprehensive Review of Vision-Based 3D Reconstruction Methods

Abstract
:1. Introduction
1.1. Explicit Expression
1.2. Implicit Expression
2. Traditional Static 3D Reconstruction Methods
2.1. Active 3D Reconstruction Methods
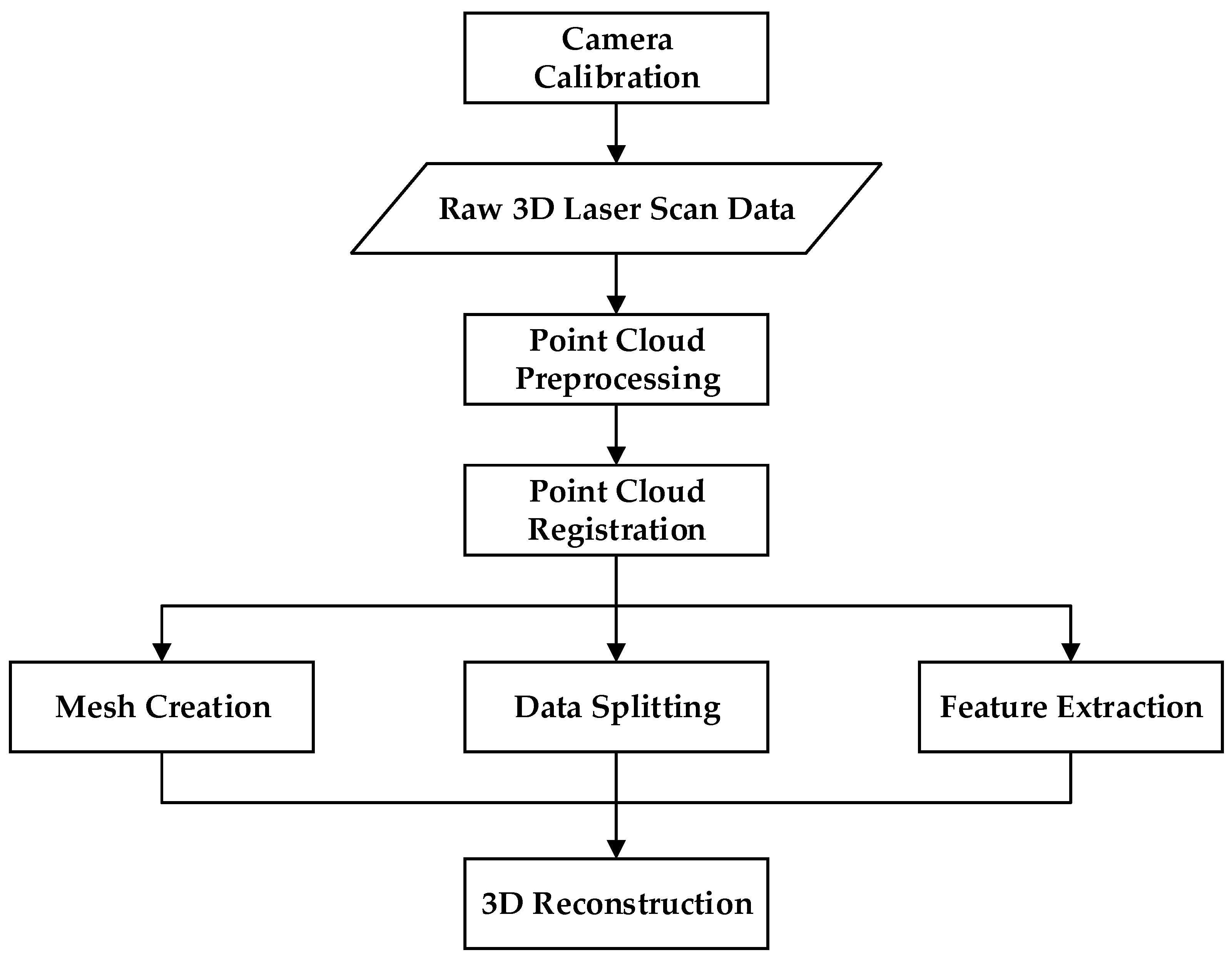
2.1.1. Laser Scanning
2.1.2. CT Scanning
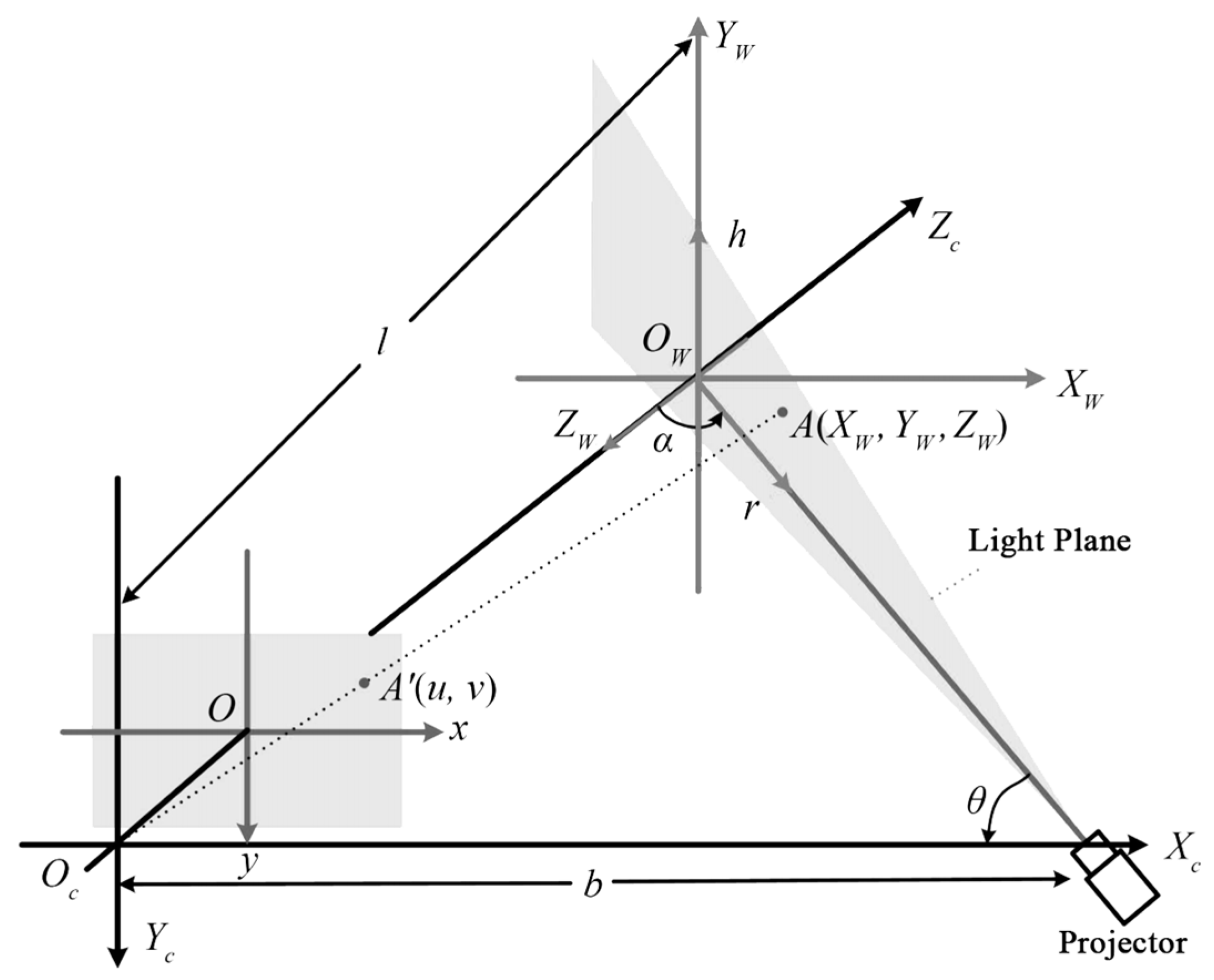
2.1.3. Structured Light
2.1.4. TOF
2.1.5. Photometric Stereo
2.1.6. Multi-Sensor Fusion
2.2. Passive 3D Reconstruction Methods
2.2.1. Texture Map**
2.2.2. Shape from Focus
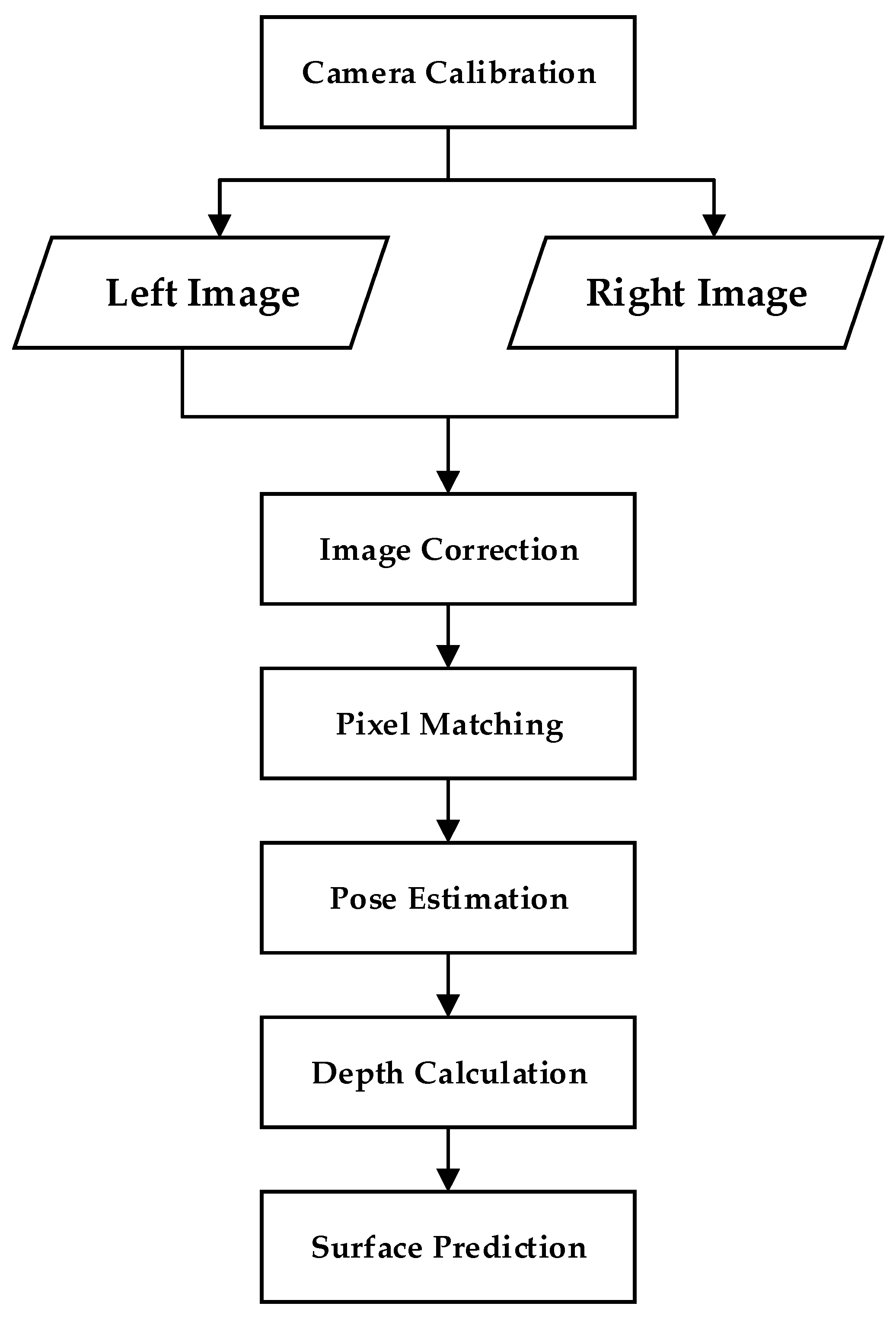
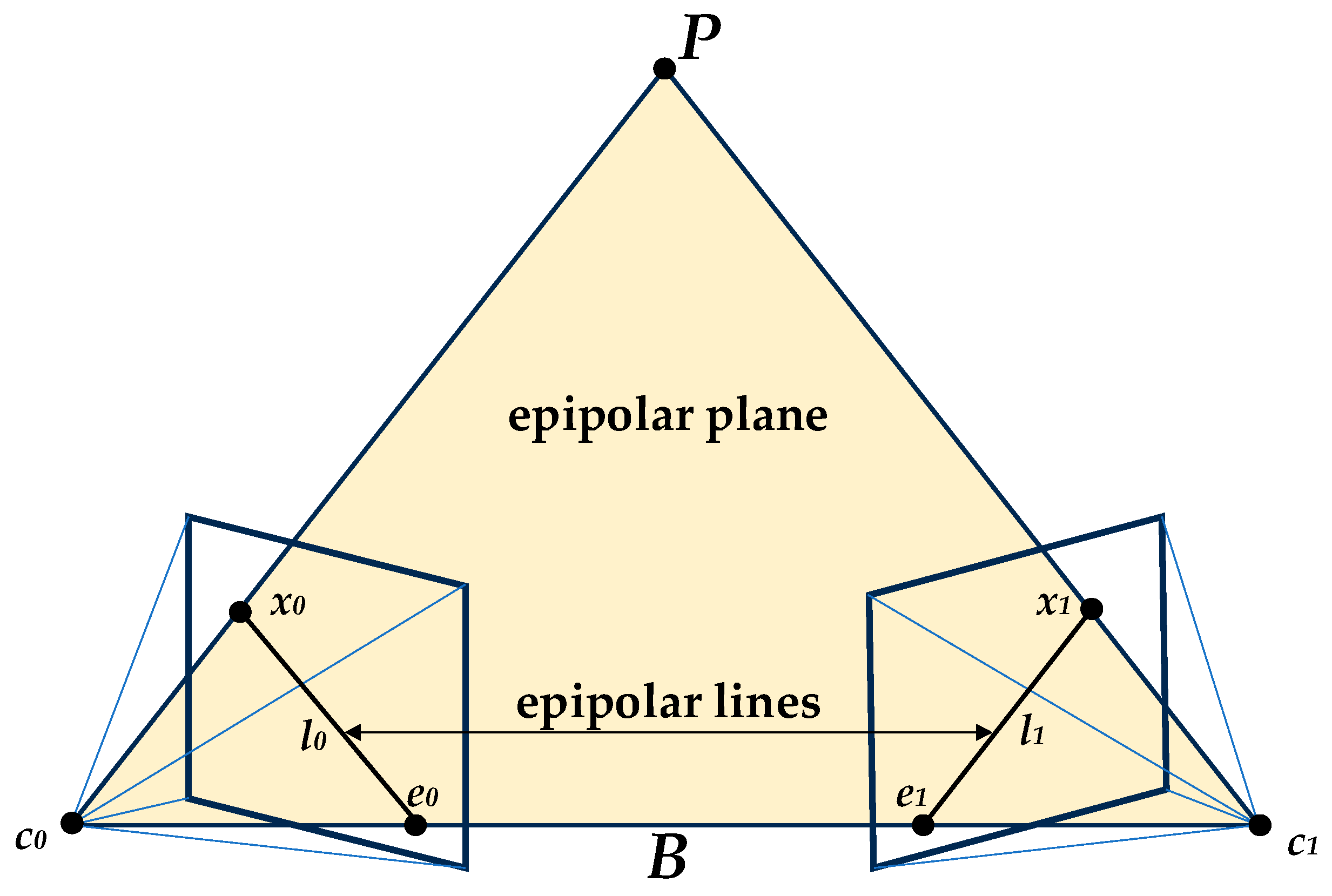
2.2.3. Binocular Stereo Vision
- (1)
- Factorization methods are mathematical models based on factorization, which obtain 3D structural information by decomposing image matrices [97]. Extract feature points from images captured at various viewing angles and then match them. These feature points can be corner points, edge points, and other points that have corresponding relationships in different viewing angles. The process involves converting the matched feature points into an observation matrix, which contains multiple feature point coordinates under each viewing angle. The next step is to factorize the observation matrix to decompose the factor matrix containing the 3D structure and camera motion information. Subsequently, the 3D structure information of the scene is extracted from the factor matrix, which includes the spatial coordinates of each feature point and the camera motion information, such as rotation and translation parameters, used to optimize the reconstruction results. Nonlinear optimization methods are typically utilized to enhance the accuracy of reconstruction. The advantage of the factorization method is that it can estimate the 3D structure and camera motion simultaneously without prior knowledge of the camera’s internal parameters. However, it is sensitive to noise and outliers, necessitating the use of suitable optimization methods to enhance robustness. Paul et al. [98] assumed that points are located on the object surface as a geometric prior to construct 3D point reconstruction and used affine and perspective cameras to estimate these quadratic surfaces and recover the 3D space in a closed form. Cin et al. [99] estimated the fundamental matrix by conducting motion segmentation on unstructured images to encode rigid motion in the scene. The depth map is used to resolve scale ambiguity, and the multi-body plane scanning algorithm is employed to integrate the multi-view depth and camera pose estimation network for generating the depth map.
- (2)
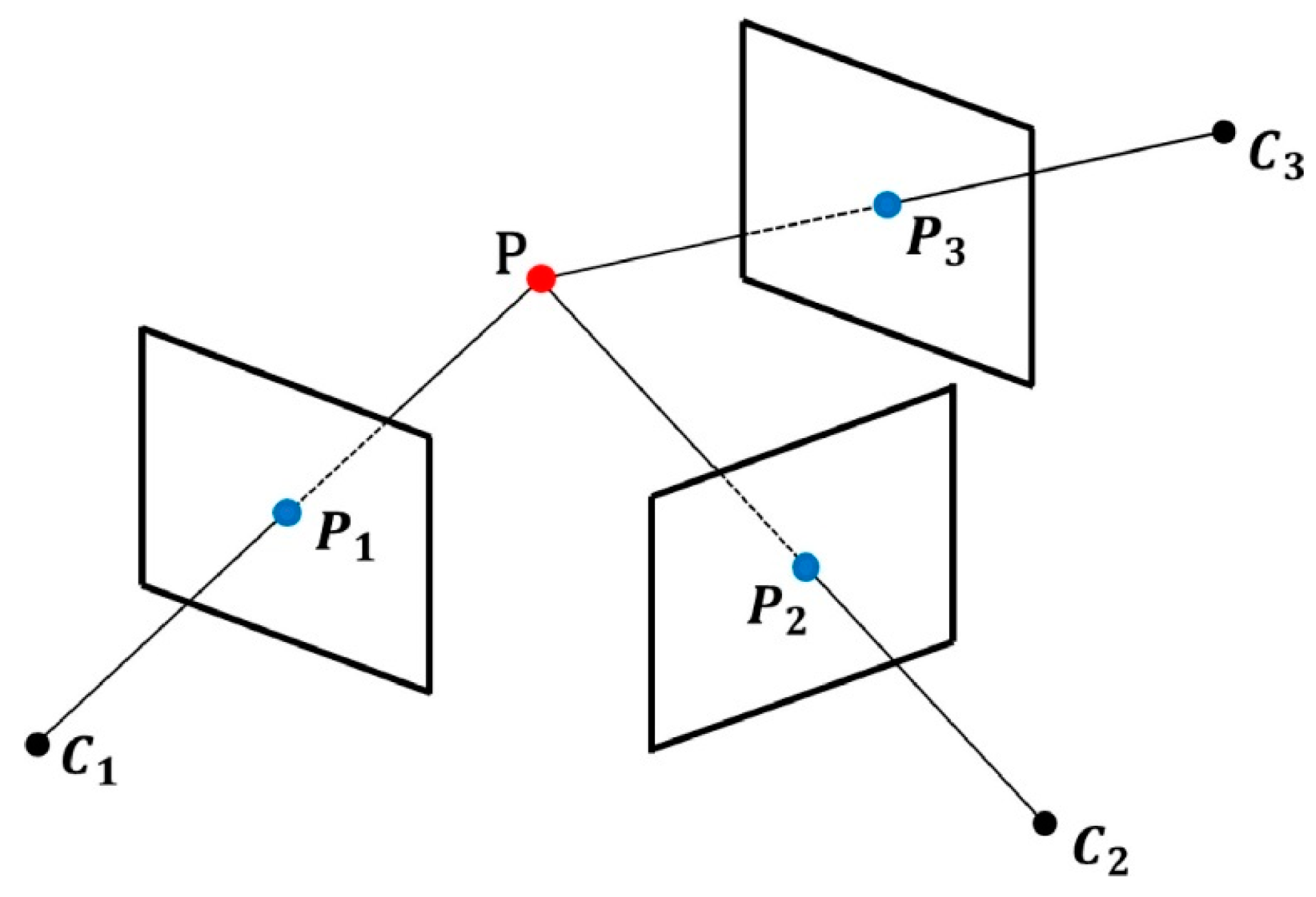
- Multi-view 3D reconstruction is a method based on observing the same scene from multiple perspectives or cameras and reconstructing the 3D structure of the scene using image or video information [100], as illustrated in Figure 5. The MVS method has high requirements for image quality and viewing angle. It needs to address challenges such as inadequate viewing angle overlap and shadows. At the same time, the accuracy of the image matching algorithm also greatly impacts the reconstruction effect. The primary objective of image registration is to address variations in viewing angles and postures in scale and time, ensuring consistent geometric information. This, in turn, enhances the reliability and accuracy of the subsequent 3D reconstruction process. This method has high requirements for camera calibration.
2.3. Introduction to 3D Reconstruction Technology
2.3.1. Camera Calibration
2.3.2. Image Local Feature Point Detection
2.3.3. Image Segmentation
2.3.4. Rendering
- (1)
- Rasterization rendering is a pixel-based rendering method that fragments the triangles of the 3D model into two-dimensional pixels and then colors each pixel, such as scanline rendering [159]. It has good real-time performance, but it struggles with handling transparency and reflection. It may not be as accurate as other methods when dealing with complex effects.
- (2)
- Ray tracing rendering is a method of simulating the propagation of light in a scene. It calculates the lighting and shadows in the scene by tracing the path of the light and considering the interaction between the light and the object. It takes into account the reflection, refraction, shadows, etc., of the light [160]. Ray tracing produces high-quality images but is computationally expensive. Monte Carlo rendering estimates the rendering equation through random sampling [161] and uses Monte Carlo integration to simulate real lighting effects [162]. In order to improve rendering efficiency, Monte Carlo rendering uses Importance Sampling to select the direction of the light path.
- (3)
- The radiometric algorithm is used to simulate the global illumination effect in the scene [163]. It considers the mutual radiation between objects and achieves realistic lighting effects by iteratively calculating the radiometric value of the surface.
- (4)
- Shadow rendering is a technology that generates shadows in real time. It renders the scene from the perspective of the light source, stores the depth information in the shadow map, and then uses the shadow map in regular rendering to determine whether the object is in shadow, simulating the interaction between light and objects. The occlusion relationship between them is used to produce realistic shadow effects [164]. Shadow rendering is divided into hard shadows and soft shadows. In the former, there are obvious shadow boundaries between objects, while in the latter, the shadow boundaries are gradually blurred, producing a more natural effect.
- (5)
- Ambient occlusion is a local lighting effect that considers the occlusion relationship between objects in the scene. It enhances shadows in deep recesses on the surface of objects, thereby enhancing the realism of the image [165].
- (6)
- The non-photorealistic rendering (NPR) method aims to imitate painting styles and produce non-realistic images, such as cartoon style and brush effects [166].
- (7)
- Volume rendering is a rendering technology used for visualizing volume data. It represents volume data as 3D textures and utilizes methods such as ray tracing to visualize the structure and features within the volume. The direct volume renderer [167] maps each sample value to opacity and color. The volume ray casting technique can be derived directly from the rendering equation. Volume ray casting is classified as an image-based volume rendering technique because the calculations are based on the output image rather than input volumetric data as in object-based techniques. The shear distortion method of volume rendering was developed by Cameron and Undrill and popularized by Philippe Lacroute and Marc Levoy [168]. Texture-based volume rendering utilizes texture map** to apply images or textures to geometric objects.
- (8)
- The splash operation blurs or diffuses the point cloud data into the surrounding area, transferring the color and intensity information of the points during the splashing process. This can be achieved by transferring the attributes of the point (such as color, normal vector, etc.) to the surrounding area using a specific weighting method. In adjacent splash areas, there may be overlap** parts where color and intensity superposition operations are performed to obtain the final rendering result [169].
3. Dynamic 3D Reconstruction Methods
3.1. Introduction to Multi-View Dynamic 3D Reconstruction
3.2. Dynamic 3D Reconstruction Based on RGB-D Camera
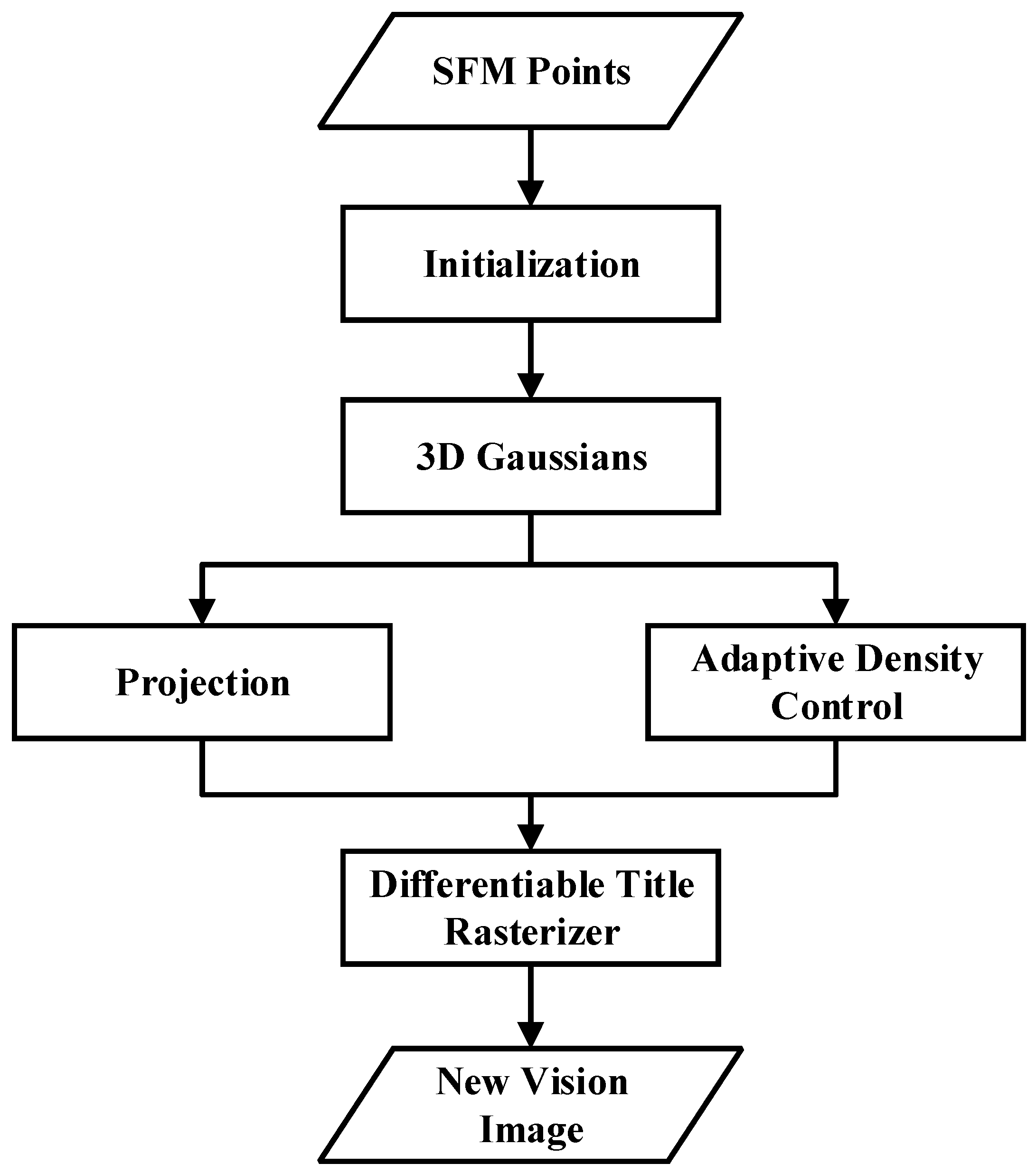
3.3. 3D Gaussian Splatting (3DGS)
3.4. Simultaneous Localization and Map** (SLAM)
4. 3D Reconstruction Methods Based on Machine Learning
4.1. Statistical Learning Methods
4.2. 3D Semantic Occupancy Prediction Methods
4.3. Deep Learning Methods
4.3.1. Depth Map
4.3.2. Point Cloud
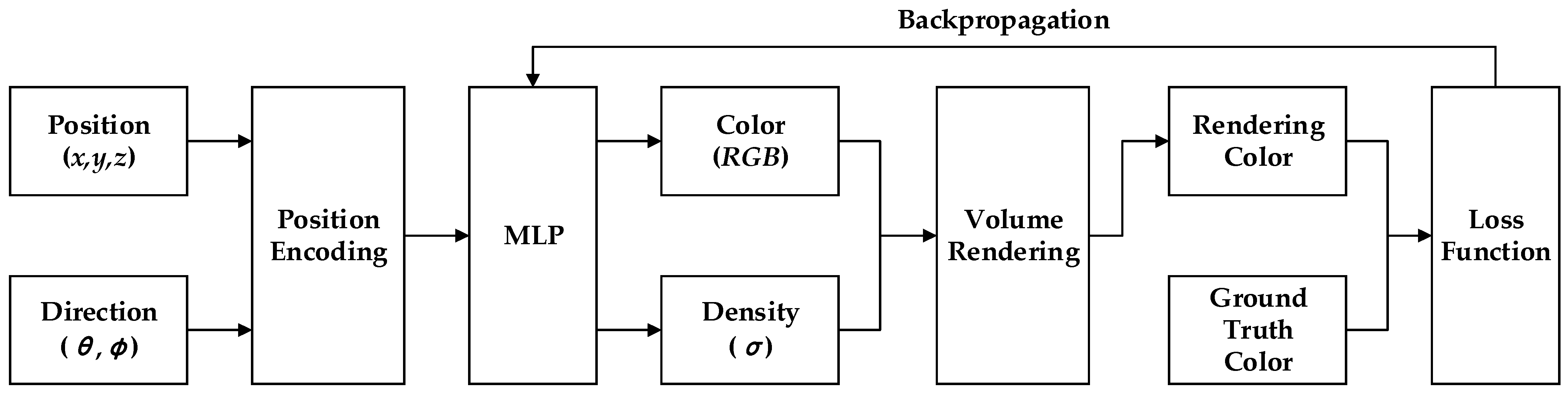
4.3.3. Neural Radiance Field (NeRF)
5. Datasets
6. Outlook and Challenges
6.1. Outlook
6.2. Challenges
7. Summary
Author Contributions
Funding
Conflicts of Interest
References
- Scopigno, R.; Cignoni, P.; Pietroni, N.; Callieri, M.; Dellepiane, M. Digital fabrication techniques for cultural heritage: A survey. Comput. Graph. Forum 2017, 36, 6–21. [Google Scholar] [CrossRef]
- Mortara, M.; Catalano, C.E.; Bellotti, F.; Fiucci, G.; Houry-Panchetti, M.; Petridis, P. Learning cultural heritage by serious games. J. Cult. Herit. 2014, 15, 318–325. [Google Scholar] [CrossRef]
- Hosseinian, S.; Arefi, H. 3D Reconstruction from Multi-View Medical X-ray images–review and evaluation of existing methods. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 40, 319–326. [Google Scholar] [CrossRef]
- Laporte, S.; Skalli, W.; De Guise, J.A.; Lavaste, F.; Mitton, D. A biplanar reconstruction method based on 2D and 3D contours: Application to the distal femur. Comput. Methods Biomech. Biomed. Eng. 2003, 6, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Zheng, L.; Li, G.; Sha, J. The survey of medical image 3D reconstruction. In Proceedings of the SPIE 6534, Fifth International Conference on Photonics and Imaging in Biology and Medicine, Wuhan, China, 1 May 2007. [Google Scholar]
- Thrun, S. Robotic map**: A survey. In Exploring Artificial Intelligence in the New Millennium; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2003; pp. 1–35. [Google Scholar]
- Keskin, C.; Erkan, A.; Akarun, L. Real time hand tracking and 3d gesture recognition for interactive interfaces using hmm. In Proceedings of the ICANN/ICONIPP 2003, Istanbul, Turkey, 26–29 June 2003; pp. 26–29. [Google Scholar]
- Moeslund, T.B.; Granum, E. A survey of computer vision-based human motion capture. Comput. Vis. Image Underst. 2001, 81, 231–268. [Google Scholar] [CrossRef]
- Izadi, S.; Kim, D.; Hilliges, O.; Molyneaux, D.; Newcombe, R.; Kohli, P.; Shotton, J.; Hodges, S.; Freeman, D.; Davison, A.; et al. Kinectfusion: Real-time 3d reconstruction and interaction using a moving depth camera. In Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology, Santa Barbara, CA, USA, 16–19 October 2011. [Google Scholar]
- Remondino, F.; Nocerino, E.; Toschi, I.; Menna, F. A critical review of automated photogrammetric processing of large datasets. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 591–599. [Google Scholar] [CrossRef]
- Roberts, L.G. Machine Perception of 3D Solids. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1963. [Google Scholar]
- Marr, D.; Nishihara, H.K. Representation and recognition of the spatial organization of 3D shapes. Proc. R. Soc. Lond. Ser. B Biol. Sci. 1978, 200, 269–294. [Google Scholar]
- Grimson, W.E.L. A computer implementation of a theory of human stereo vision. Philos. Trans. R. Soc. Lond. B Biol. Sci. 1981, 292, 217–253. [Google Scholar] [PubMed]
- Zlatanova, S.; Painsil, J.; Tempfli, K. 3D object reconstruction from aerial stereo images. In Proceedings of the 6th International Conference in Central Europe on Computer Graphics and Visualization’98, Plzen, Czech Republic, 9–13 February 1998; Volume III, pp. 472–478. [Google Scholar]
- Niemeyer, M.; Mescheder, L.; Oechsle, M.; Geiger, A. A Differentiable volumetric rendering: Learning implicit 3d representations without 3d supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3504–3515. [Google Scholar]
- Varady, T.; Martin, R.R.; Cox, J. Reverse engineering of geometric models—An introduction. Comput.-Aided Des. 1997, 29, 255–268. [Google Scholar] [CrossRef]
- Williams, C.G.; Edwards, M.A.; Colley, A.L.; Macpherson, J.V.; Unwin, P.R. Scanning micropipet contact method for high-resolution imaging of electrode surface redox activity. Anal. Chem. 2009, 81, 2486–2495. [Google Scholar] [CrossRef] [PubMed]
- Zheng, T.X.; Huang, S.; Li, Y.F.; Feng, M.C. Key techniques for vision based 3D reconstruction: A review. Acta Autom. Sin. 2020, 46, 631–652. [Google Scholar]
- Isgro, F.; Odone, F.; Verri, A. An open system for 3D data acquisition from multiple sensors. In Proceedings of the Seventh International Workshop on Computer Architecture for Machine Perception (CAMP’05), Palermo, Italy, 4–6 July 2005. [Google Scholar]
- Kraus, K.; Pfeifer, N. Determination of terrain models in wooded areas with airborne laser scanner data. ISPRS J. Photogramm. Remote Sens. 1998, 53, 193–203. [Google Scholar] [CrossRef]
- Göbel, W.; Kampa, B.M.; Helmchen, F. Imaging cellular network dynamics in three dimensions using fast 3D laser scanning. Nat. Methods 2007, 4, 73–79. [Google Scholar] [CrossRef] [PubMed]
- Flisch, A.; Wirth, J.; Zanini, R.; Breitenstein, M.; Rudin, A.; Wendt, F.; Mnich, F.; Golz, R. Industrial computed tomography in reverse engineering applications. DGZfP-Proc. BB 1999, 4, 45–53. [Google Scholar]
- Rocchini, C.M.P.P.C.; Cignoni, P.; Montani, C.; **i, P.; Scopigno, R. A low cost 3D scanner based on structured light. In Computer Graphics Forum; Blackwell Publishers Ltd.: Oxford, UK; Boston, MA, USA, 2001; Volume 20. [Google Scholar]
- Park, J.; Kim, H.; Tai, Y.W.; Brown, M.S.; Kweon, I. High quality depth map upsampling for 3D-TOF cameras. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Al-Najdawi, N.; Bez, H.E.; Singhai, J.; Edirisinghe, E.A. A survey of cast shadow detection algorithms. Pattern Recognit. Lett. 2012, 33, 752–764. [Google Scholar] [CrossRef]
- Schwarz, B. Map** the world in 3D. Nat. Photonics 2010, 4, 429–430. [Google Scholar] [CrossRef]
- Arayici, Y. An approach for real world data modeling with the 3D terrestrial laser scanner for built environment. Autom. Constr. 2007, 16, 816–829. [Google Scholar] [CrossRef]
- Dassot, M.; Constant, T.; Fournier, M. The use of terrestrial LiDAR technology in forest science: Application fields, benefits and challenges. Ann. For. Sci. 2011, 68, 959–974. [Google Scholar] [CrossRef]
- Yang, Y.; Shi, R.; Yu, X. Laser scanning triangulation for large profile measurement. J.-** of the lunar surface. ISPRS J. Photogramm. Remote Sens. 2020, 159, 153–168. [Google Scholar] [CrossRef]
- Li, Z.; Ji, S.; Fan, D.; Yan, Z.; Wang, F.; Wang, R. Reconstruction of 3D Information of Buildings from Single-View Images Based on Shadow Information. ISPRS Int. J. Geo-Inf. 2024, 13, 62. [Google Scholar] [CrossRef]
- Wang, M.; Wei, S.; Liang, J.; Liu, S.; Shi, J.; Zhang, X. Lightweight FISTA-inspired sparse reconstruction network for mmW 3-D holography. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–20. [Google Scholar] [CrossRef]
- Schramm, S.; Osterhold, P.; Schmoll, R.; Kroll, A. Combining modern 3D reconstruction and thermal imaging: Generation of large-scale 3D thermograms in real-time. Quant. InfraRed Thermogr. J. 2022, 19, 295–311. [Google Scholar] [CrossRef]
- Geiger, A.; Ziegler, J.; Stiller, C. Stereoscan: Dense 3d reconstruction in real-time. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011. [Google Scholar]
- Costa, A.L.; Yasuda, C.L.; Appenzeller, S.; Lopes, S.L.; Cendes, F. Comparison of conventional MRI and 3D reconstruction model for evaluation of temporomandibular joint. Surg. Radiol. Anat. 2008, 30, 663–667. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, Y.; Niu, Q. Multi-sensor fusion in automated driving: A survey. IEEE Access 2019, 8, 2847–2868. [Google Scholar] [CrossRef]
- Yu, H.; Oh, J. Anytime 3D object reconstruction using multi-modal variational autoencoder. IEEE Robot. Autom. Lett. 2022, 7, 2162–2169. [Google Scholar] [CrossRef]
- Buelthoff, H.H. Shape from X: Psychophysics and computation. In Computational Models of Visual Processing, Proceedings of the Sensor Fusion III: 3-D Perception and Recognition, Boston, MA, USA, 4–9 November 1990; Society of Photo-Optical Instrumentation Engineers: Bellingham, WA, USA, 1991; pp. 235–246. [Google Scholar]
- Yemez, Y.; Schmitt, F. 3D reconstruction of real objects with high resolution shape and texture. Image Vis. Comput. 2004, 22, 1137–1153. [Google Scholar] [CrossRef]
- Alexiadis, D.S.; Zarpalas, D.; Daras, P. Real-time, realistic full-body 3D reconstruction and texture map** from multiple Kinects. In Proceedings of the IVMSP 2013, Seoul, Republic of Korea, 10–12 June 2013. [Google Scholar]
- Lee, J.H.; Ha, H.; Dong, Y.; Tong, X.; Kim, M.H. Texturefusion: High-quality texture acquisition for real-time rgb-d scanning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Xu, K.; Wang, M.; Wang, M.; Feng, L.; Zhang, T.; Liu, X. Enhancing Texture Generation with High-Fidelity Using Advanced Texture Priors. ar** for 3-D video. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 357–369. [Google Scholar] [CrossRef]
- Newcombe, R.A.; Fox, D.; Seitz, S.M. Dynamicfusion: Reconstruction and tracking of non-rigid scenes in real-time. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 343–352. [Google Scholar]
- Innmann, M.; Zollhöfer, M.; Nießner, M.; Theobalt, C.; Stamminger, M. Volumedeform: Real-time volumetric non-rigid reconstruction. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VIII 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 362–379. [Google Scholar]
- Yu, T.; Zheng, Z.; Guo, K.; Zhao, J.; Dai, Q.; Li, H.; Pons-Moll, G.; Liu, Y. Doublefusion: Real-time capture of human performances with inner body shapes from a single depth sensor. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7287–7296. [Google Scholar]
- Dou, M.; Khamis, S.; Degtyarev, Y.; Davidson, P.; Fanello, S.R.; Kowdle, A.; Escolano, S.O.; Rhemann, C.; Kim, D.; Taylor, J.; et al. Fusion4d: Real-time performance capture of challenging scenes. ACM Trans. Graph. ToG 2016, 35, 1–13. [Google Scholar] [CrossRef]
- Lin, W.; Zheng, C.; Yong, J.H.; Xu, F. Occlusionfusion: Occlusion-aware motion estimation for real-time dynamic 3d reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1736–1745. [Google Scholar]
- Pan, Z.; Hou, J.; Yu, L. Optimization RGB-D 3-D reconstruction algorithm based on dynamic SLAM. IEEE Trans. Instrum. Meas. 2023, 72, 1–13. [Google Scholar] [CrossRef]
- Kerbl, B.; Kopanas, G.; Leimkühler, T.; Drettakis, G. 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph. 2023, 42, 1–14. [Google Scholar] [CrossRef]
- Yan, Y.; Lin, H.; Zhou, C.; Wang, W.; Sun, H.; Zhan, K.; Lang, X.; Zhou, X.; Peng, S. Street gaussians for modeling dynamic urban scenes. ar** (SLAM) with sensor handover. Robot. Auton. Syst. 2013, 61, 195–208. [Google Scholar] [CrossRef]
- Li, M.; He, J.; Jiang, G.; Wang, H. DDN-SLAM: Real-time Dense Dynamic Neural Implicit SLAM with Joint Semantic Encoding. ar** from Single-View Images. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023. [Google Scholar]
- Dai, P.; Tan, F.; Yu, X.; Zhang, Y.; Qi, X. GO-NeRF: Generating Virtual Objects in Neural Radiance Fields. ar** of objects. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part IV 16. Springer International Publishing: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Zhu, X.; Liao, T.; Lyu, J.; Yan, X.; Wang, Y.; Guo, K.; Cao, Q.; Li, Z.S.; Lei, Z. Mvp-human dataset for 3d human avatar reconstruction from unconstrained frames. ar**v 2022, ar**v:2204.11184. [Google Scholar]
- Pumarola, A.; Sanchez-Riera, J.; Choi, G.; Sanfeliu, A.; Moreno-Noguer, F. 3dpeople: Modeling the geometry of dressed humans. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ international conference on intelligent robots and systems, Vilamoura-Algarve, Portugal, 7–12 October 2012. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In Proceedings of the Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Proceedings, Part V 12. Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- **ao, J.; Owens, A.; Torralba, A. Sun3d: A database of big spaces reconstructed using sfm and object labels. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Couprie, C.; Farabet, C.; Najman, L.; LeCun, Y. Indoor semantic segmentation using depth information. ar**v 2013, ar**v:1301.3572. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. Shapenet: An information-rich 3d model repository. ar**v 2015, ar**v:1512.03012. [Google Scholar]
- Song, S.; Lichtenberg, S.P.; **ao, J. Sun rgb-d: A rgb-d scene understanding benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- McCormac, J.; Handa, A.; Leutenegger, S.; Davison, A.J. Scenenet rgb-d: 5m photorealistic images of synthetic indoor trajectories with ground truth. ar**v 2016, ar**v:1612.05079. [Google Scholar]
- Hua, B.S.; Pham, Q.H.; Nguyen, D.T.; Tran, M.K.; Yu, L.F.; Yeung, S.K. Scenenn: A scene meshes dataset with annotations. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016. [Google Scholar]
- Song, S.; Yu, F.; Zeng, A.; Chang, A.X.; Savva, M.; Funkhouser, T. Semantic scene completion from a single depth image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wasenmüller, O.; Meyer, M.; Stricker, D. CoRBS: Comprehensive RGB-D benchmark for SLAM using Kinect v2. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016. [Google Scholar]
- Chang, A.; Dai, A.; Funkhouser, T.; Halber, M.; Niessner, M.; Savva, M.; Song, S.; Zeng, A.; Zhang, Y. Matterport3d: Learning from rgb-d data in indoor environments. ar**v 2017, ar**v:1709.06158. [Google Scholar]
- Armeni, I.; Sax, S.; Zamir, A.R.; Savarese, S. Joint 2d-3d-semantic data for indoor scene understanding. ar**v 2017, ar**v:1702.01105. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Li, W.; Saeedi, S.; McCormac, J.; Clark, R.; Tzoumanikas, D.; Ye, Q.; Huang, Y.; Tang, R.; Leutenegger, S. Interiornet: Mega-scale multi-sensor photo-realistic indoor scenes dataset. ar**v 2018, ar**v:1809.00716. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- **ang, Y.; Mottaghi, R.; Savarese, S. Beyond pascal: A benchmark for 3d object detection in the wild. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Steamboat Springs, CO, USA, 24–26 March 2014. [Google Scholar]
- Schops, T.; Schonberger, J.L.; Galliani, S.; Sattler, T.; Schindler, K.; Pollefeys, M.; Geiger, A. A multi-view stereo benchmark with high-resolution images and multi-camera videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. Semantic3d. net: A new large-scale point cloud classification benchmark. ar**v 2017, ar**v:1704.03847. [Google Scholar]
- Roynard, X.; Deschaud, J.-E.; Goulette, F. Paris-Lille-3D: A large and high-quality ground-truth urban point cloud dataset for automatic segmentation and classification. Int. J. Robot. Res. 2018, 37, 545–557. [Google Scholar] [CrossRef]
- Song, X.; Wang, P.; Zhou, D.; Zhu, R.; Guan, C.; Dai, Y.; Su, H.; Li, H.; Yang, R. Apollocar3d: A large 3d car instance understanding benchmark for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Gählert, N.; Jourdan, N.; Cordts, M.; Franke, U.; Denzler, J. Cityscapes 3d: Dataset and benchmark for 9 dof vehicle detection. ar**v 2020, ar**v:2006.07864. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Zhang, J.; Ren, Y.; Zhou, L.; Fang, T.; Quan, L. Blendedmvs: A large-scale dataset for generalized multi-view stereo networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Tong, G.; Li, Y.; Chen, D.; Sun, Q.; Cao, W.; **ang, G. CSPC-dataset: New LiDAR point cloud dataset and benchmark for large-scale scene semantic segmentation. IEEE Access 2020, 8, 87695–87718. [Google Scholar] [CrossRef]
- Tan, W.; Qin, N.; Ma, L.; Li, Y.; Du, J.; Cai, G.; Yang, K.; Li, J. Toronto-3D: A large-scale mobile LiDAR dataset for semantic segmentation of urban roadways. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Chen, M.; Hu, Q.; Yu, Z.; Thomas, H.; Feng, A.; Hou, Y.; McCullough, K.; Ren, F.; Soibelman, L. Stpls3d: A large-scale synthetic and real aerial photogrammetry 3d point cloud dataset. ar**v 2022, ar**v:2203.09065. [Google Scholar]
- Liao, Y.; **e, J.; Geiger, A. Kitti-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3292–3310. [Google Scholar] [CrossRef] [PubMed]
- Jeong, S.; Kim, H.; Cho, Y. DiTer: Diverse Terrain and Multi-Modal Dataset for Field Robot Navigation in Outdoor Environments. IEEE Sens. Lett. 2024, 8, 1–4. [Google Scholar] [CrossRef]
- Zhao, S.; Gao, Y.; Wu, T.; Singh, D.; Jiang, R.; Sun, H.; Sarawata, M.; Whittaker, W.C.; Higgins, I.; Su, S.; et al. SubT-MRS Dataset: Pushing SLAM Towards All-weather Environments. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024. [Google Scholar]
- Martin-Martin, R.; Patel, M.; Rezatofighi, H.; Shenoi, A.; Gwak, J.; Frankel, E.; Sadeghian, A.; Savarese, S. Jrdb: A dataset and benchmark of egocentric robot visual perception of humans in built environments. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 45, 6748–6765. [Google Scholar] [CrossRef] [PubMed]
- Shuifa, S.U.N.; Yongheng, T.A.N.G.; Ben, W.A.N.G.; Fangmin, D.O.N.G.; **aolong, L.I.; Jiacheng, C.A.I.; Yirong, W.U. A Review of Research on 3D Reconstruction of Dynamic Scenes. J. Front. Comput. Sci. Technol. 2021, 1, 91–97. [Google Scholar]
- Broxton, M.; Flynn, J.; Overbeck, R.; Erickson, D.; Hedman, P.; Duvall, M.; Dourgarian, J.; Busch, J.; Whalen, M.; Debevec, P. Immersive light field video with a layered mesh representation. ACM Trans. Graph. TOG 2020, 39, 86:1–86:15. [Google Scholar] [CrossRef]
- Li, T.; Slavcheva, M.; Zollhoefer, M.; Green, S.; Lassner, C.; Kim, C.; Schmidt, T.; Lovegrave, S.; Goesele, M.; Newcombe, R.; et al. Neural 3d video synthesis from multi-view video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Park, K.; Sinha, U.; Barron, J.T.; Bouaziz, S.; Goldman, D.B.; Seitz, S.M.; Martin-Brualla, R. Nerfies: Deformable neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Karaev, N.; Rocco, I.; Graham, B.; Neverova, N.; Vedaldi, A.; Rupprecht, C. Dynamicstereo: Consistent dynamic depth from stereo videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Palazzolo, E.; Behley, J.; Lottes, P.; Giguere, P.; Stachniss, C. ReFusion: 3D reconstruction in dynamic environments for RGB-D cameras exploiting residuals. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019. [Google Scholar]
- Yang, X.; Zhou, L.; Jiang, H.; Tang, Z.; Wang, Y.; Bao, H.; Zhang, G. Mobile3DRecon: Real-time monocular 3D reconstruction on a mobile phone. IEEE Trans. Vis. Comput. Graph. 2020, 26, 3446–3456. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Persons | Total of Data | Type of Data |
|---|---|---|---|
| Human3.6M [274] | 11 | 3.6 million | images |
| MPII-Pose [275] | / | 25K | images |
| BUFF [276] | 5 | 11,054 | 3D scans |
| UP-3D [277] | / | 7126 | images |
| SHPD [278] | / | 23,334 | images |
| SMPL-X [279] | 31 | 5586 | images, 3D scans |
| THUman [280] | 230 | 7K | images |
| HUMBI [281] | 772 | 67 million | images |
| HUMAN4D [282] | 4 | 50,306 | mRGBD, meshes |
| GRAB [283] | 10 | 1.6M | images |
| MVP-Human [284] | 400 | 6K, 48K | 3D scans, images |
| 3DPeople Dataset [285] | 80 | 2.5 million | images |
| Dataset | Total of Data | Type of Data | Scenes | Objects |
|---|---|---|---|---|
| TUM RGB-D [286] | 39 sequences | images, depth | 39 | / |
| NYUD2 [287] | 1449 | images, 3D point cloud | 464 | 894 |
| SUN 3D [288] | 415 scenes | images, video | 254 | 41 |
| NYU v2 [289] | 407,024 | images, depth | 464 | 894 |
| ShapeNet [290] | 300M | CAD | / | 3135 |
| SUNRGBD [291] | 10,335 | images | 47 | 700 |
| SceneNet RGB-D [292] | 5M | images | 57 | 255 |
| SceneNN [293] | 100 scenes | images, 3D meshes | 100 | / |
| SUNCG [294] | 130,269 | depth, 3D meshes | 24 | 84 |
| CoRBS [295] | 20 sequences | images | 20 | 20 |
| Matterport3D [296] | 194,400 | images, 3D meshes | 90 | 10,800 |
| 2D-3D-S [297] | 70,496 | images, 3D point cloud | 11 | 13 |
| Scannet [298] | 2.5M, 36123 | images, 3D point cloud | 1513 | 21 |
| InteriorNet [299] | 20M, 1M | images, CAD | 15k | / |
| Dataset | Total of Data | Type of Data | Scenes | Objects |
|---|---|---|---|---|
| KITTI [300] | 41K | images | 22 | 80,256 |
| PASCAL3D+ [301] | 22,394 | images, CAD | / | 13,898 |
| Eth3D [302] | 24 megapixels | images, 3D point cloud | / | / |
| Semantic3D [303] | 4 billion points | images, 3D point cloud | 30 | 8 classes |
| Paris-Lille-3D [304] | 57.79 million | images, 3D point cloud | 2 | 50 classes |
| ApolloCar3D [305] | 5277 | images | / | 60k |
| Cityscapes 3D [306] | 5000 | images, 3D point cloud | / | 8 classes |
| BlendedMVS [307] | 17k | images, 3D meshes | 113 | / |
| CSPC-Dataset [308] | 68 million points | images, 3D point cloud | 5 | 6 classes |
| Toronto-3D [309] | 78.3 million points | images, 3D point cloud | / | 8 classes |
| STPLS3D [310] | 16 km2 | images, 3D point cloud | / | / |
| KITTI-360 [311] | 300k, 1 billon points | images, 3D point cloud | / | / |
| DiTer [312] | / | images, 3D point cloud | / | / |
| SubT-MRS [313] | 30 scenes | images, 3D point cloud | 30 | / |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, L.; Wu, G.; Zuo, Y.; Chen, X.; Hu, H. A Comprehensive Review of Vision-Based 3D Reconstruction Methods. Sensors 2024, 24, 2314. https://doi.org/10.3390/s24072314
Zhou L, Wu G, Zuo Y, Chen X, Hu H. A Comprehensive Review of Vision-Based 3D Reconstruction Methods. Sensors. 2024; 24(7):2314. https://doi.org/10.3390/s24072314
Chicago/Turabian StyleZhou, Linglong, Guoxin Wu, Yunbo Zuo, Xuanyu Chen, and Hongle Hu. 2024. "A Comprehensive Review of Vision-Based 3D Reconstruction Methods" Sensors 24, no. 7: 2314. https://doi.org/10.3390/s24072314