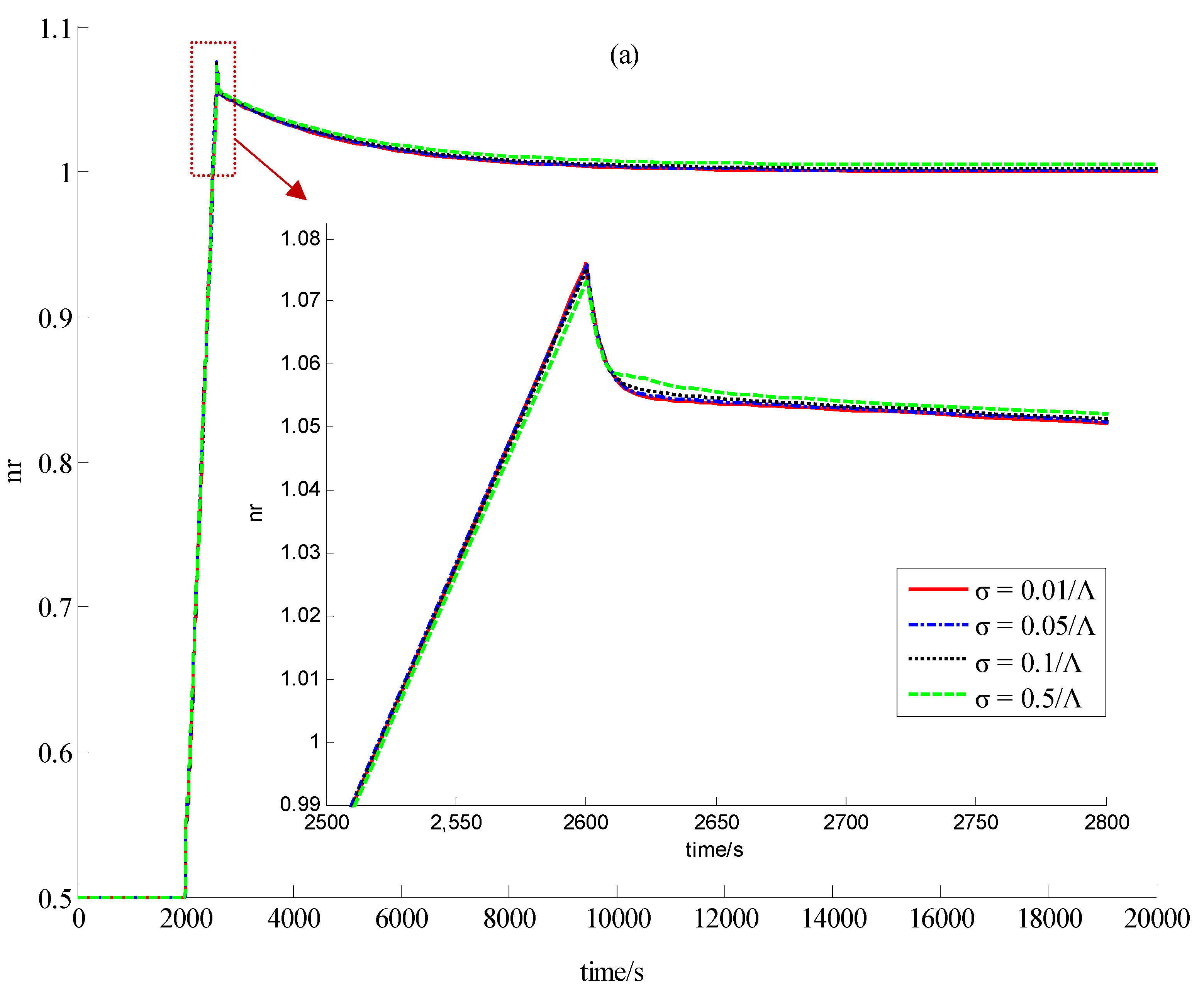
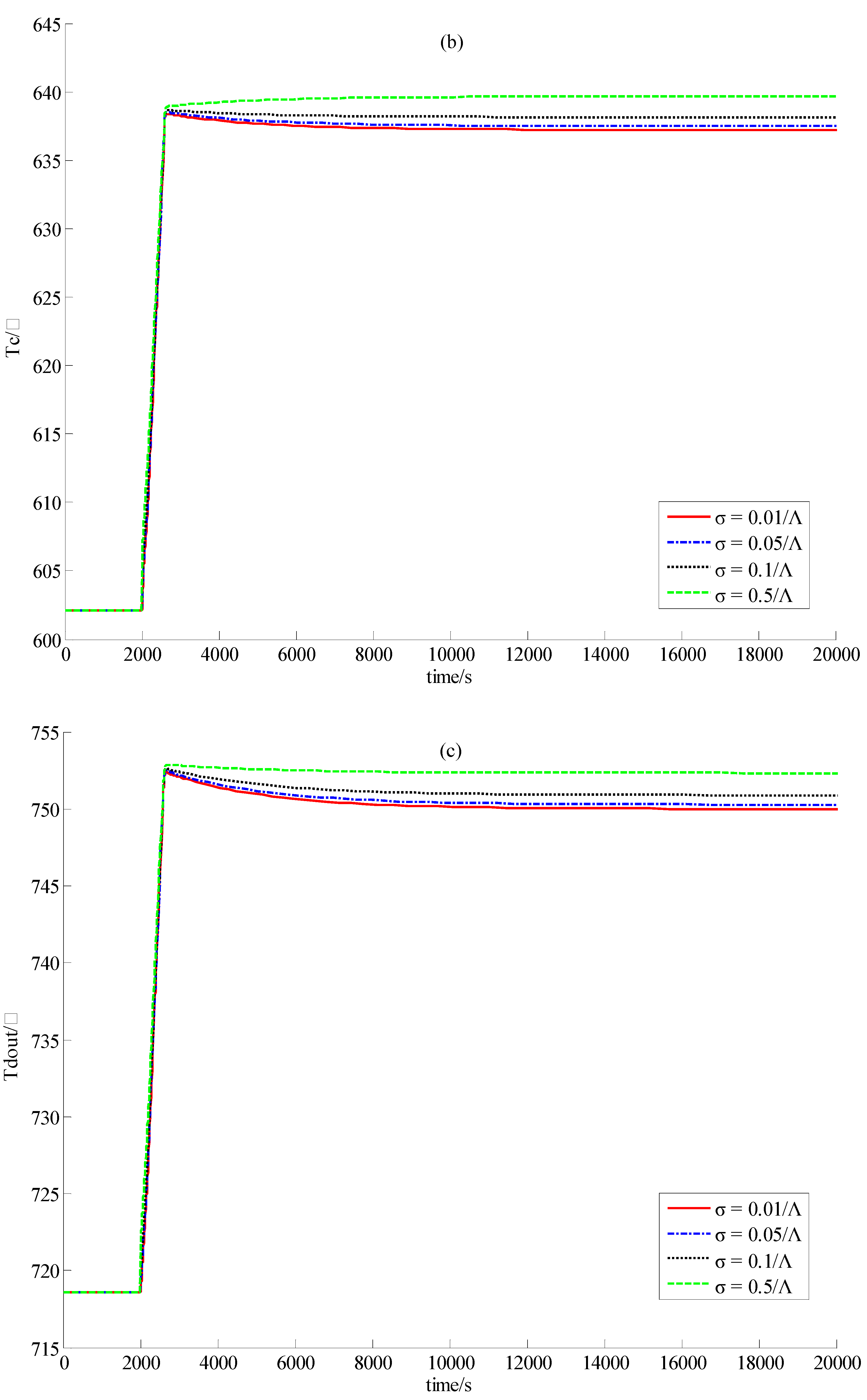
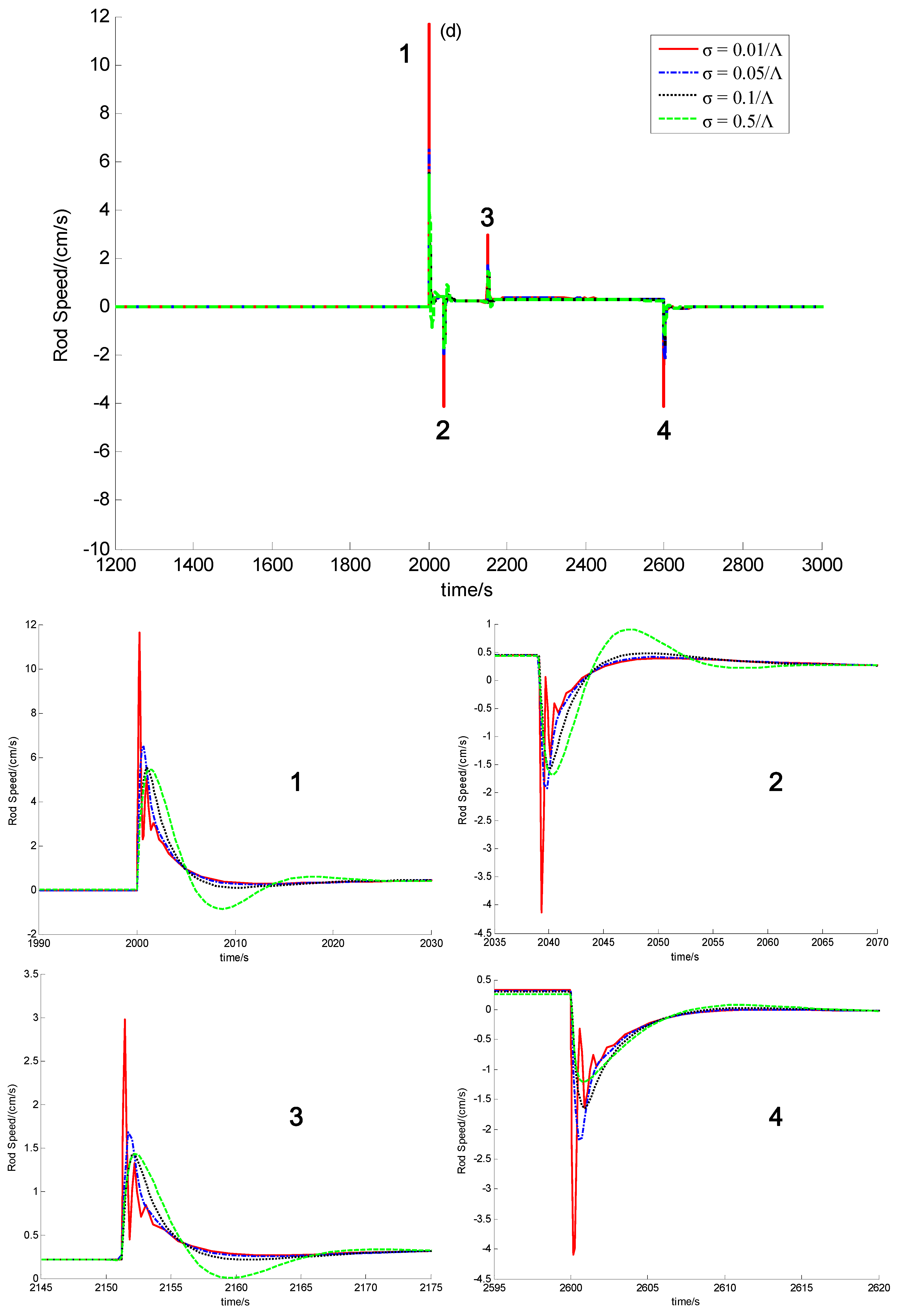
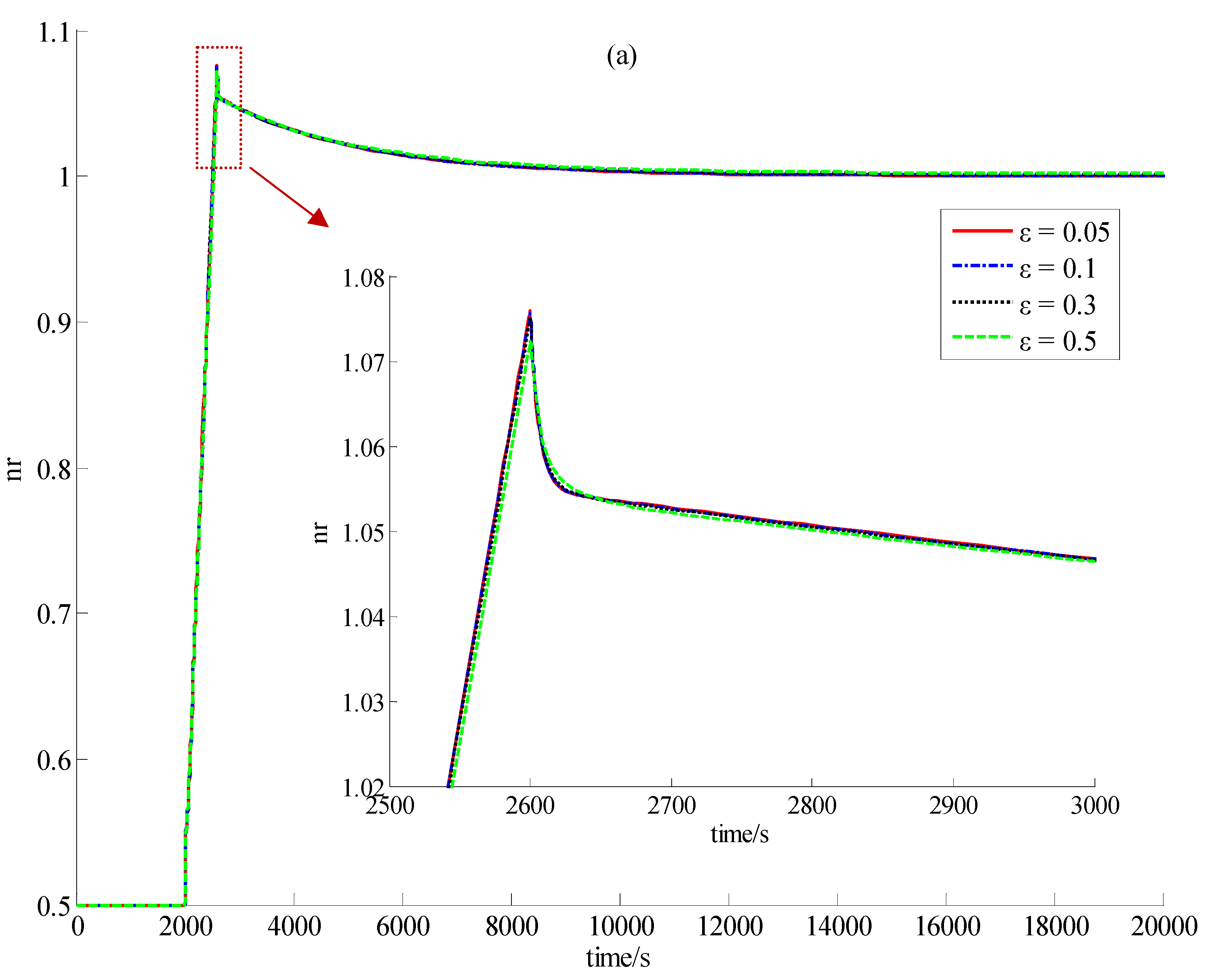
3.1. Introduction to the Concept of Feedback Dissipation Control
To introduce the concept of the feedback dissipation control, the concept of the dissipative system is firstly given as follows:
Definition 2: consider the following nonlinear autonomous system:
where
χ ∈
Rn and
ω(
O) =
O. If there exists a smooth function
Γ(·): R
n→R
+ = [0, ∞) called Hamiltonian function so that inequality is satisfied:
Then System (15) is said to be a dissipative system corresponding to Hamiltonian function Γ. Moreover, if Inequality (16) holds strictly, then System (15) is strictly dissipative. After introducing the dissipative system, the concept of the generalized Hamiltonian realization is given as follows:
Definition 3: System (15) is called to have a generalized Hamiltonian realization (GHR) if there is a suitable subsets of R
n such that System (15) can be expressed as:
where
![Energies 05 01782 i096]()
,and
T ∈
Rn×n is called the structure matrix. Moreover, if structure matrix
T can be written as:
with skew-symmetric
J and symmetric nonnegative definite
R.
Remark 2: if the structure matrix of System (15) can be represented as Equation (18), then it is dissipative. Moreover, if symmetric matrix R is strict positive definite, then System (15) is strict dissipative.
From Definition 2, system dissipation means shrinkage of a given Hamiltonian function. However, not all of the dynamic systems are dissipative for a given Hamiltonian function, it is reasonable to force a system to be dissipative by the means of feedback. This leads to the definition of feedback dissipation control given as follows:
Definition 4: consider the following nonlinear system:
where
χ ∈
Rn is the system state vector;
v ∈
Rp is the control input;
θ ∈
Rm is the system output, and
ω(
O) =
O. For a given Hamiltonian function
Γ(
χ), feedback control
υ is called a feedback dissipation control if Inequality (20) is satisfied:
If Inequality (20) is strictly satisfied, then υ is called a strict feedback dissipation control. If υ = υ(χ), then it is a state-feedback dissipation control. If υ = υ(θ), then it is called an output-feedback dissipation control. Finally, in order for the closed-loop stability analysis, the concepts of zero-state detectability and observability are introduced as follows:
Definition 5 [
15]: consider nonlinear System (19), and System (19) is called zero-state detectable if
θ ≡
O and
υ ≡
O (∀
t ≥ 0) implies:
Moreover, this system is called zero-state observable if θ ≡ O and υ ≡ O implies z(t) ≡ O for ∀t ≥ 0.
3.2. Design of the Power-Level Control Based on Iterative Dam** Assignment
Firstly, we adopt the following the state transformation:
and then reactor Dynamics (6) can be rewritten as:
where:
and:
In the following, the iterative dam** assignment for system (23) is done through state-feedback dissipation step by step:
Step 1:
Define:
and then reactor dynamics can be rewritten as:
where:
We can see from the first equation of Equation (29) that it already has the form like a GHR. Next, we shall do like this iteratively.
Step 2:
Based on coordinate Transformation (28), define:
where:
and:
From Equations (28,30), the reactor dynamics can be transformed to:
where:
Step 3:
Based on Equation (33), we choose the feedback control
u as:
where:
where
v is the compensation term to be designed for guaranteeing the dissipation or stability characteristics of the closed-loop system, and here both
κ and
σ are given positive scalars.
Substituting control law Equation (33) to Equation (34), we can obtain:
where:
From Equations (28,30), the coordinate transformation from
z to
ξ can be expressed as:
Moreover, from Equations (22,46), it is clear that the transformation from
x to
ξ is:
Under coordinate
x, feedback law Equation (34) can be written as:
The following Proposition 1, which is the first main result of this paper, gives the condition so that feedback law Equation (34) is an L2 disturbance attenuator corresponding to a given evaluation signal.
Proposition 1: choose the evaluation signal as:
where
ξ,
H and
p is determined by Equations (40,43,47), respectively. If the compensation term
v satisfies:
where
K is a given positive scalar, then feedback law composed of Equations (48,50) is an
L2 disturbance attenuator corresponding to evaluation signal Equation (49). Moreover, the
L2 gain can be adjusted by feedback gain
K. Moreover, if there is no disturbance,
i.e.:
then the closed-loop system is globally asymptotically stable.
Proof: based on the above discussion, it is so clear that differentiating Hamiltonian function Equation (40) along the trajectory given by Equations (6,48,50) is equivalent to that along the trajectory given by Equations (38,50). Then, we can derive that:
where:
From Equation (42) and Inequality (52), we can properly choose the values of
κ and
γ such that inequality is satisfied:
where
τ is a small positive scalar. Based upon Inequalities (52,54), we have:
By the use of Inequality (55) and Definition 1, we can easily see that the feedback law composed of Equations (48,50) is an
L2 attenuator of system Equation (6) corresponding to evaluation signal Equation (49). Moreover, from Inequality (55), the
L2 gain from disturbance
w to evaluation signal
ζ is:
which means that the influence of
w to
ζ can be effectively reduced by choosing a large
K or a large
σ. In the following, we shall prove the globally asymptotic closed-loop stability when Condition (51) is satisfied. It is clear that if Equation (51) holds, we have:
where:
From Equations (40,57,58), state-vector
x asymptotically converges to the set defined as:
Based upon coordinate Transformation (47), set
Ξ is equivalent to:
Moreover, from Equations (6,7), for ∀
x ∈
Ξ1, it is quite clear that:
which manifests that the closed-loop system is globally asymptotically stable if
w ≡
O. This completes the proof of this proposition.
Remark 3: based on Inequality (57) and Equation (58), when there is no disturbance, the closed-loop system is still globally asymptotically stable even if K = 0. That is to say, feedback law Equation (34) with v = 0 is enough to guarantee the globally asymptotic closed-loop stability in case of w ≡ O.
Remark 4: from Equations (40,43,47), it is easily to see that:
and:
Substituting Equation (48) to Equation (62), we can get the total feedback control law,
i.e.,
where:
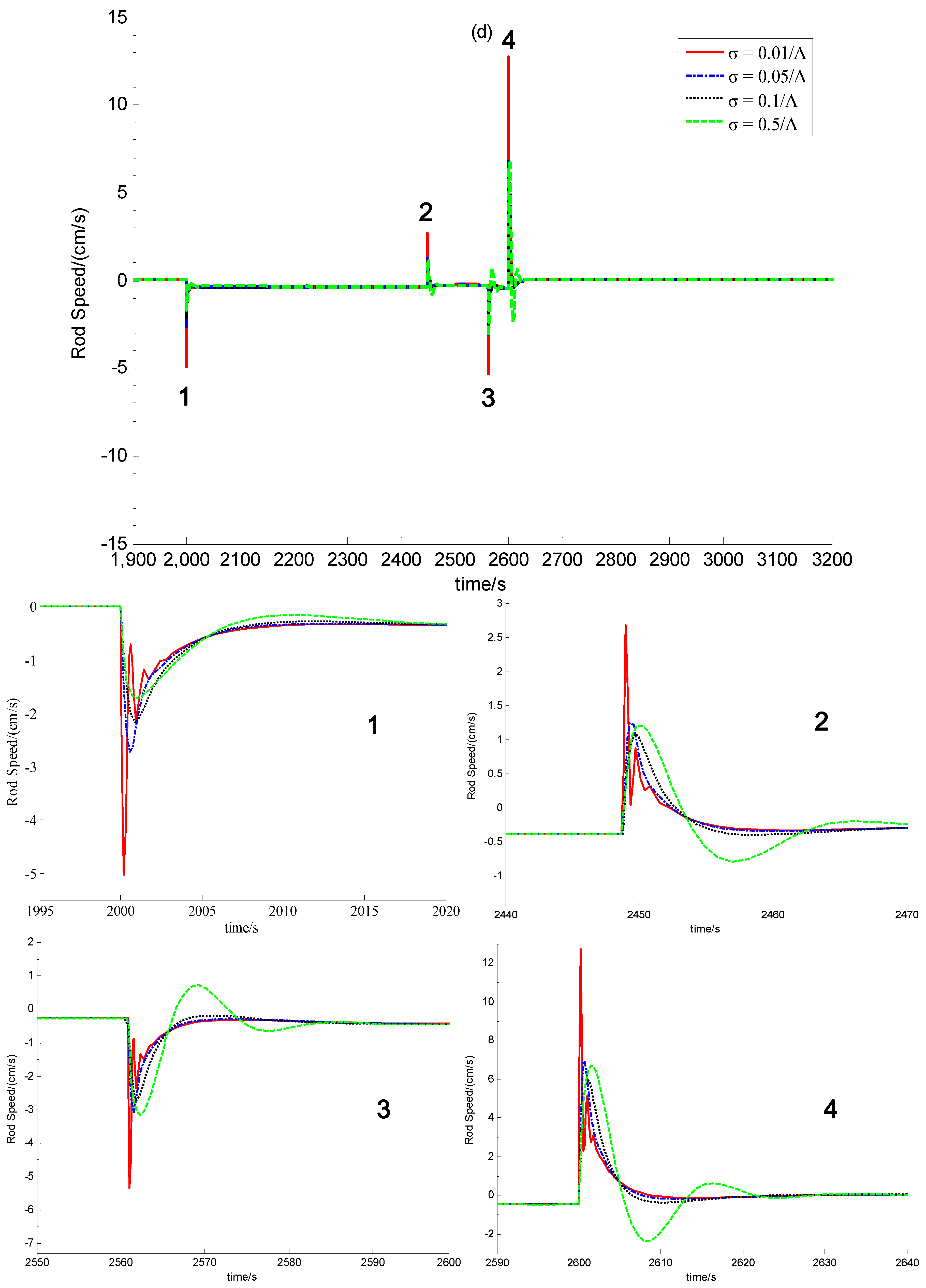
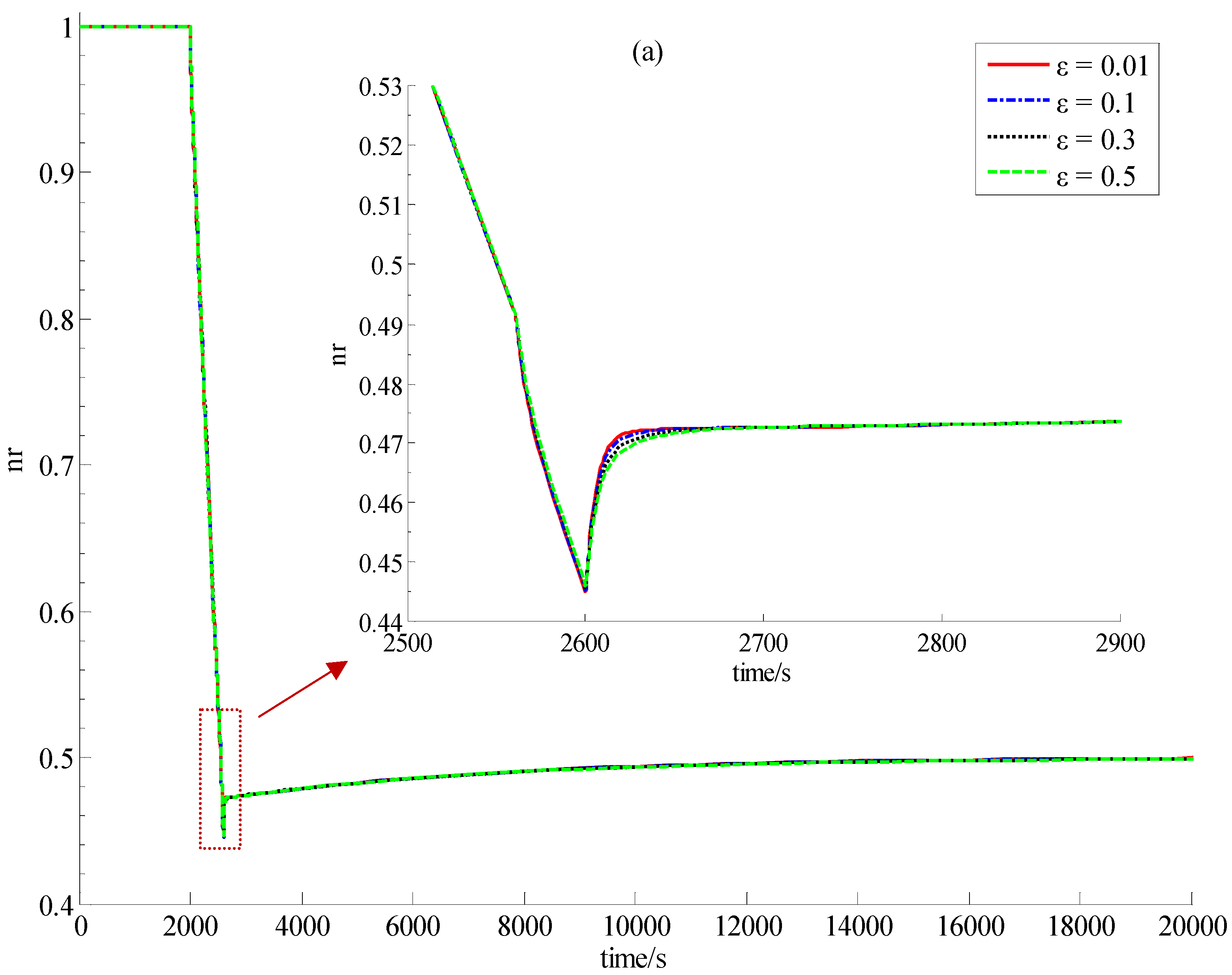
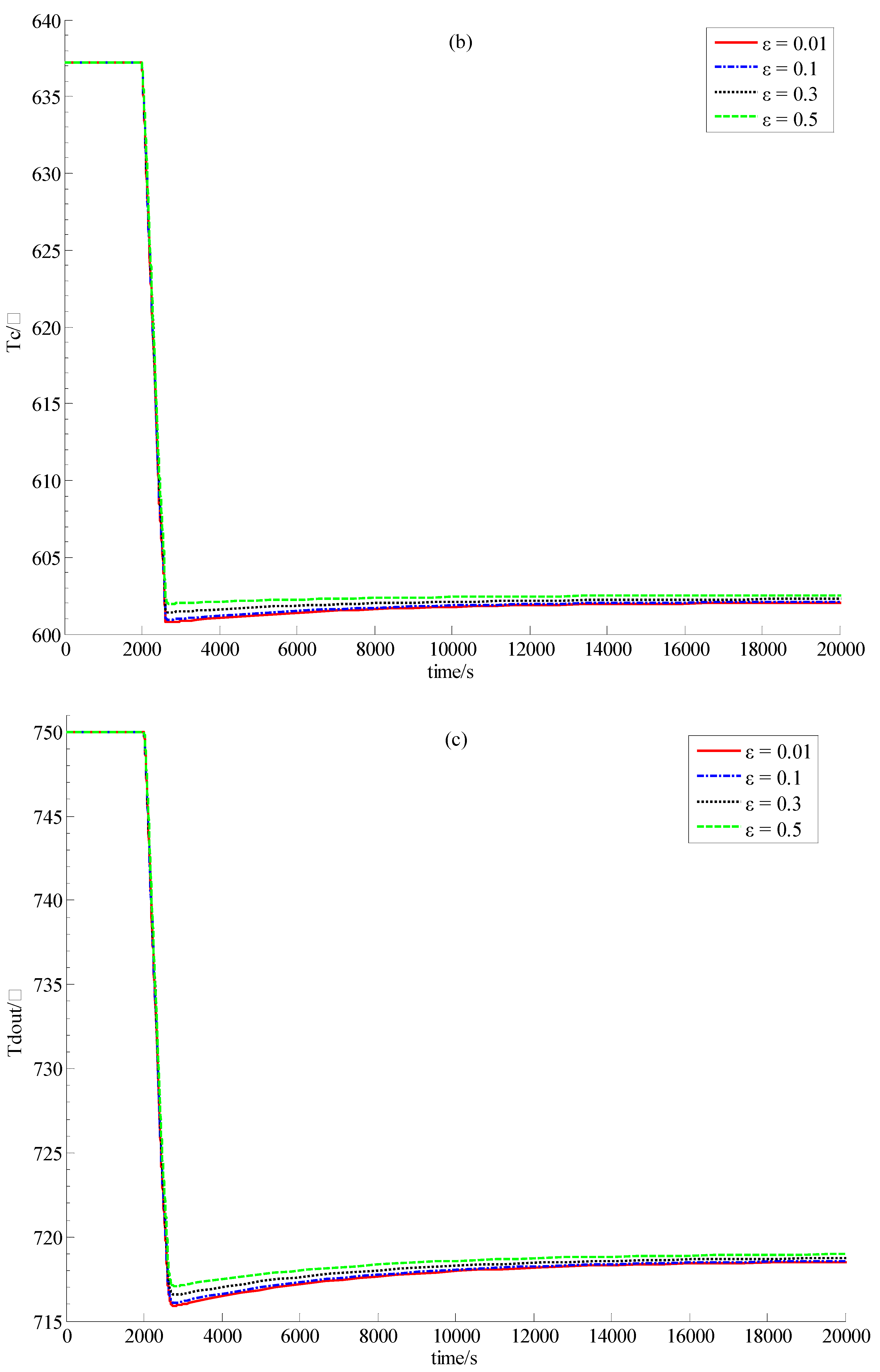
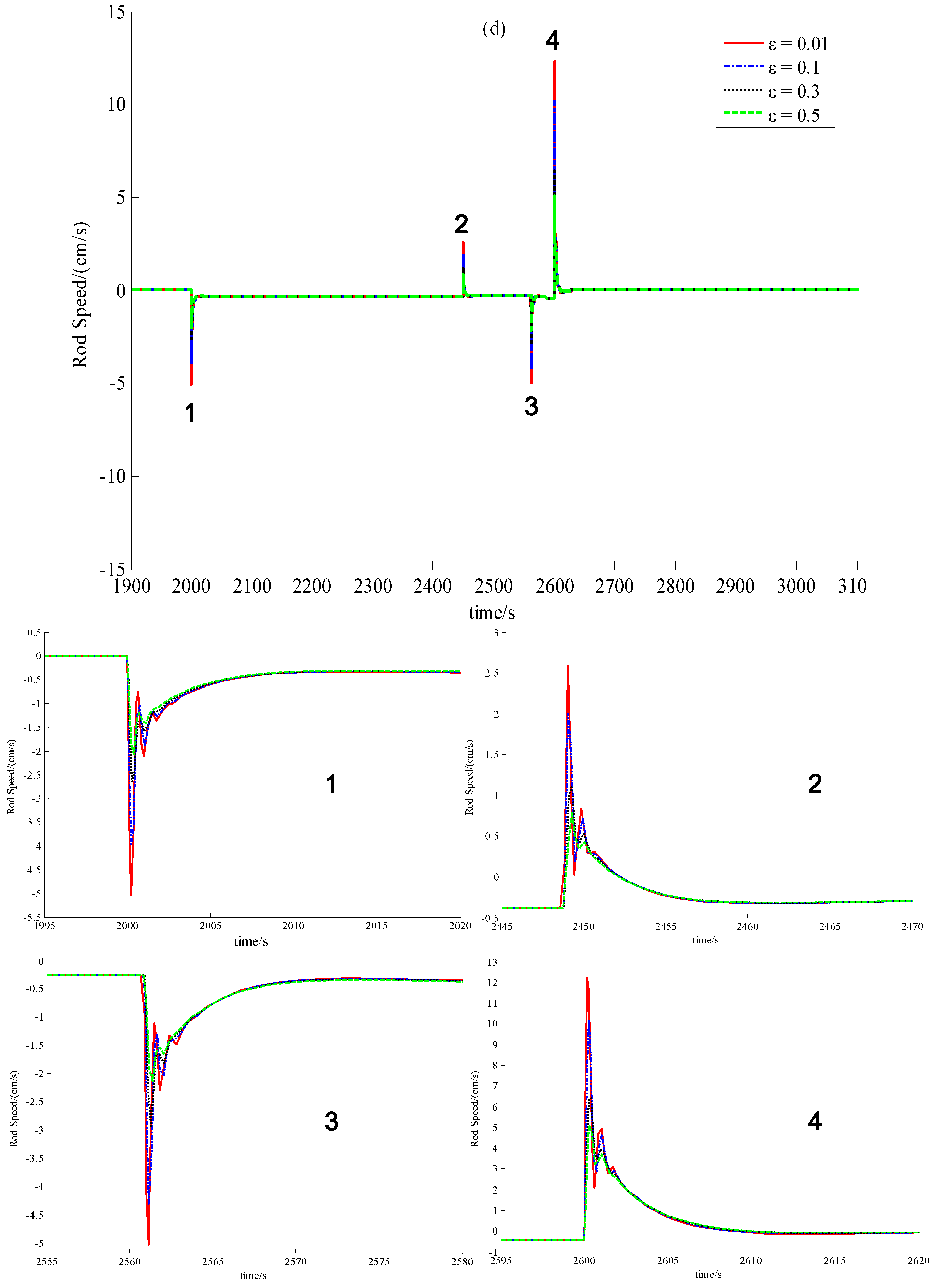
It can be easily seen from Equation (63) that the function of this control law is realized through feeding back all the state-variables. Since only x1 and x3, i.e., δnr and δTd can be obtained through measurement, it is quite necessary to design a convergent state-observer for the implementation of this newly-built power-level control strategy.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


















 ,and T ∈ Rn×n is called the structure matrix. Moreover, if structure matrix T can be written as:
,and T ∈ Rn×n is called the structure matrix. Moreover, if structure matrix T can be written as:






















































 is the state-observation, Fo ∈ Rn×m is the gain matrix of the observer,
is the state-observation, Fo ∈ Rn×m is the gain matrix of the observer,







































