
WATS-SMS: A T5-Based French Wikipedia Abstractive Text Summarizer for SMS

 ,
,  , and
, and
Abstract
:1. Introduction
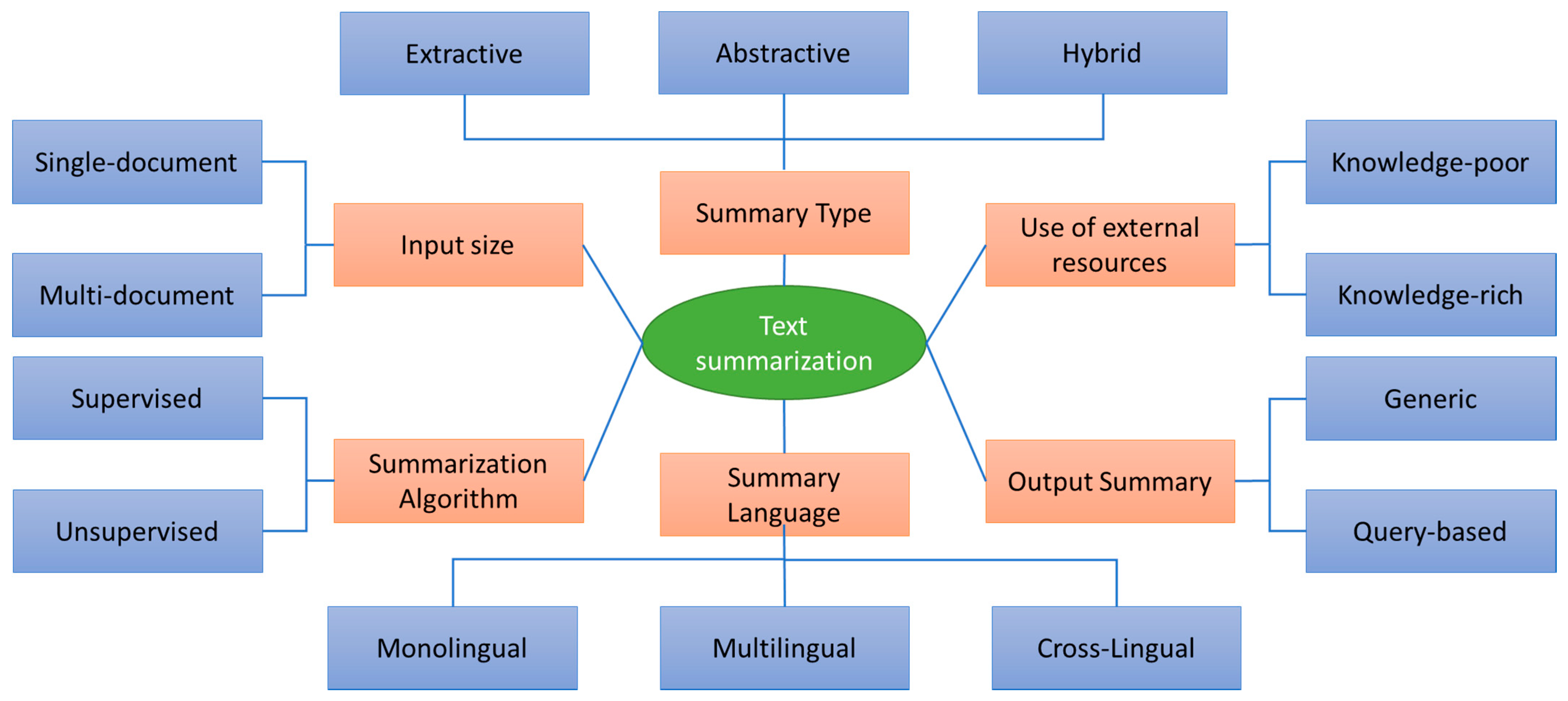
2. Related Works on Text Summarization
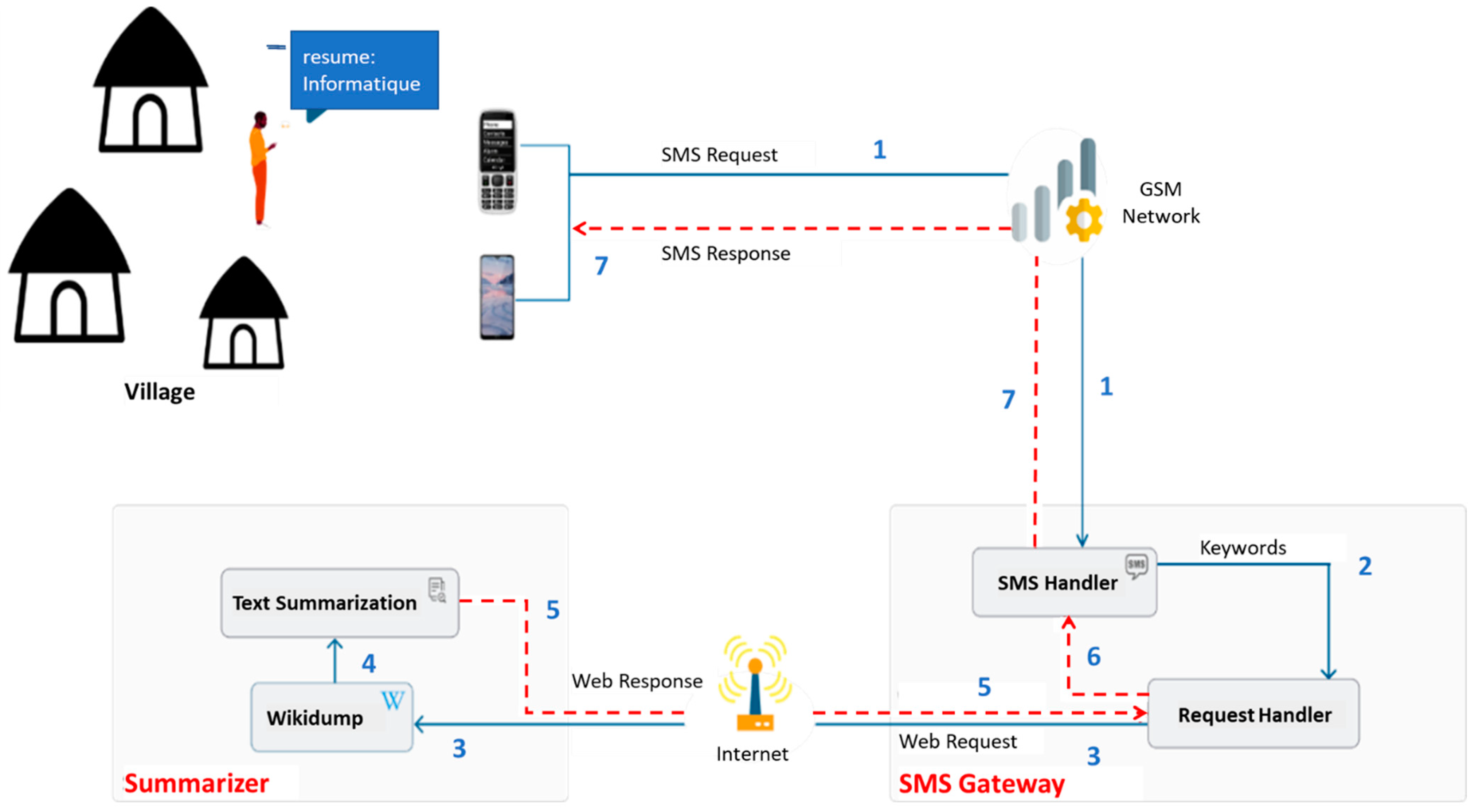
3. WATS-SMS System
3.1. The SMS Gateway
3.2. The Summarizer
- Pre-processing of the requested page (Retrieving and cleaning);
- Summarization process;
- Post-processing the summary.
3.2.1. Pre-Processing of French Wikipedia Pages
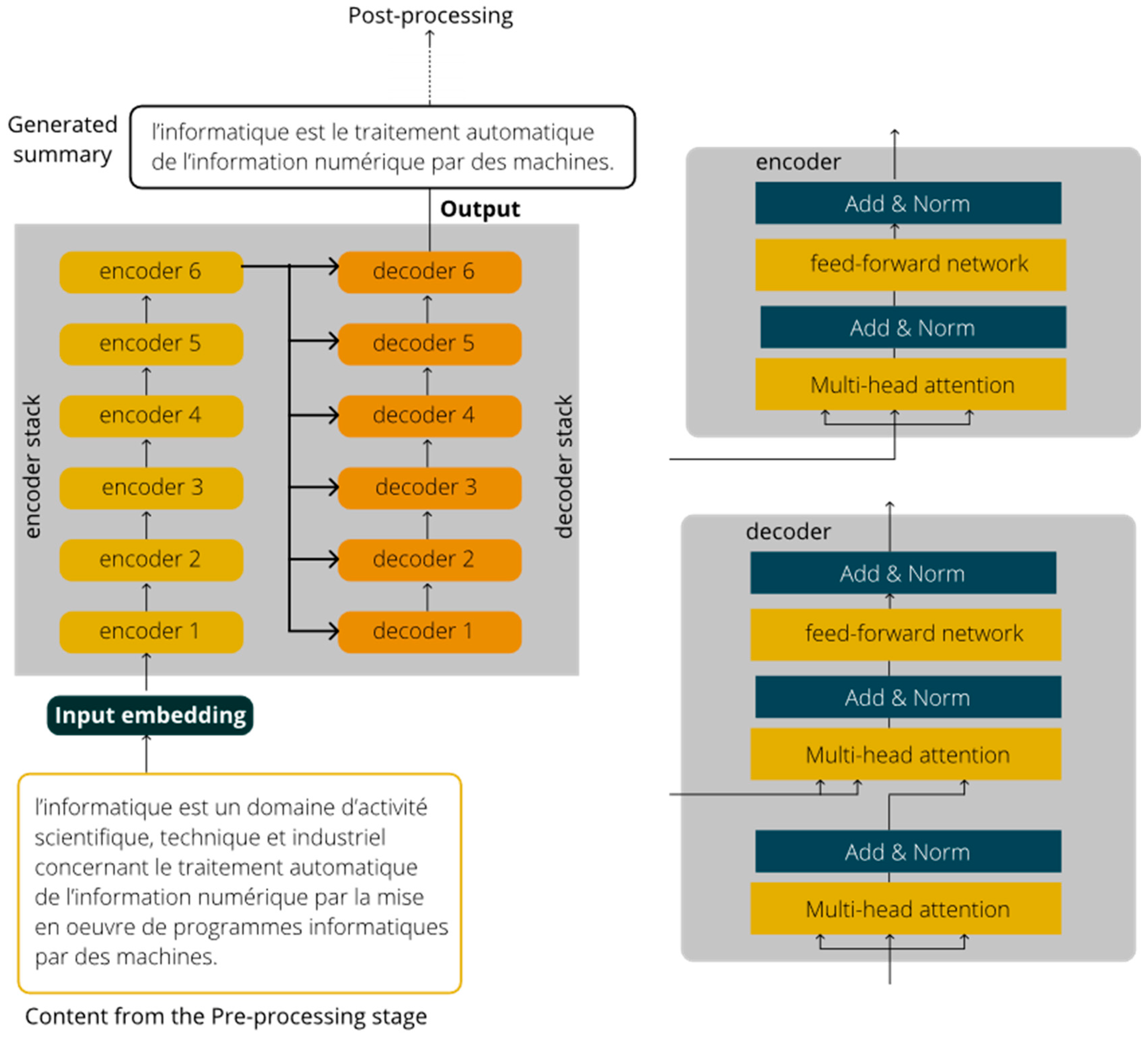
3.2.2. Summarization Process
- Model
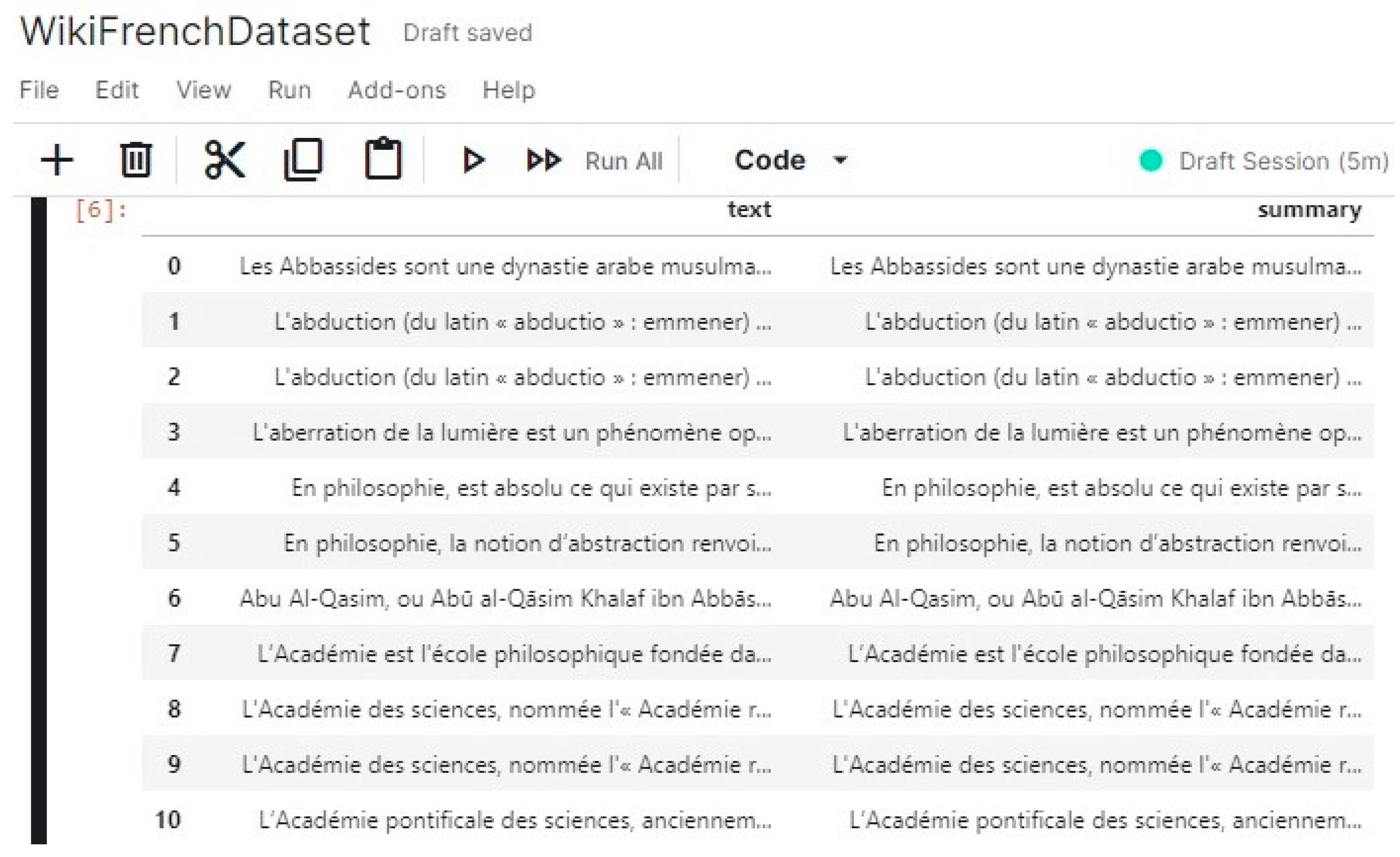
- Dataset
- Training and testing
3.2.3. Post-Processing of the Summary
4. Results
4.1. Comparison
4.1.1. Comparison with Extractive Approaches
4.1.2. Comparison with Abstractive Models
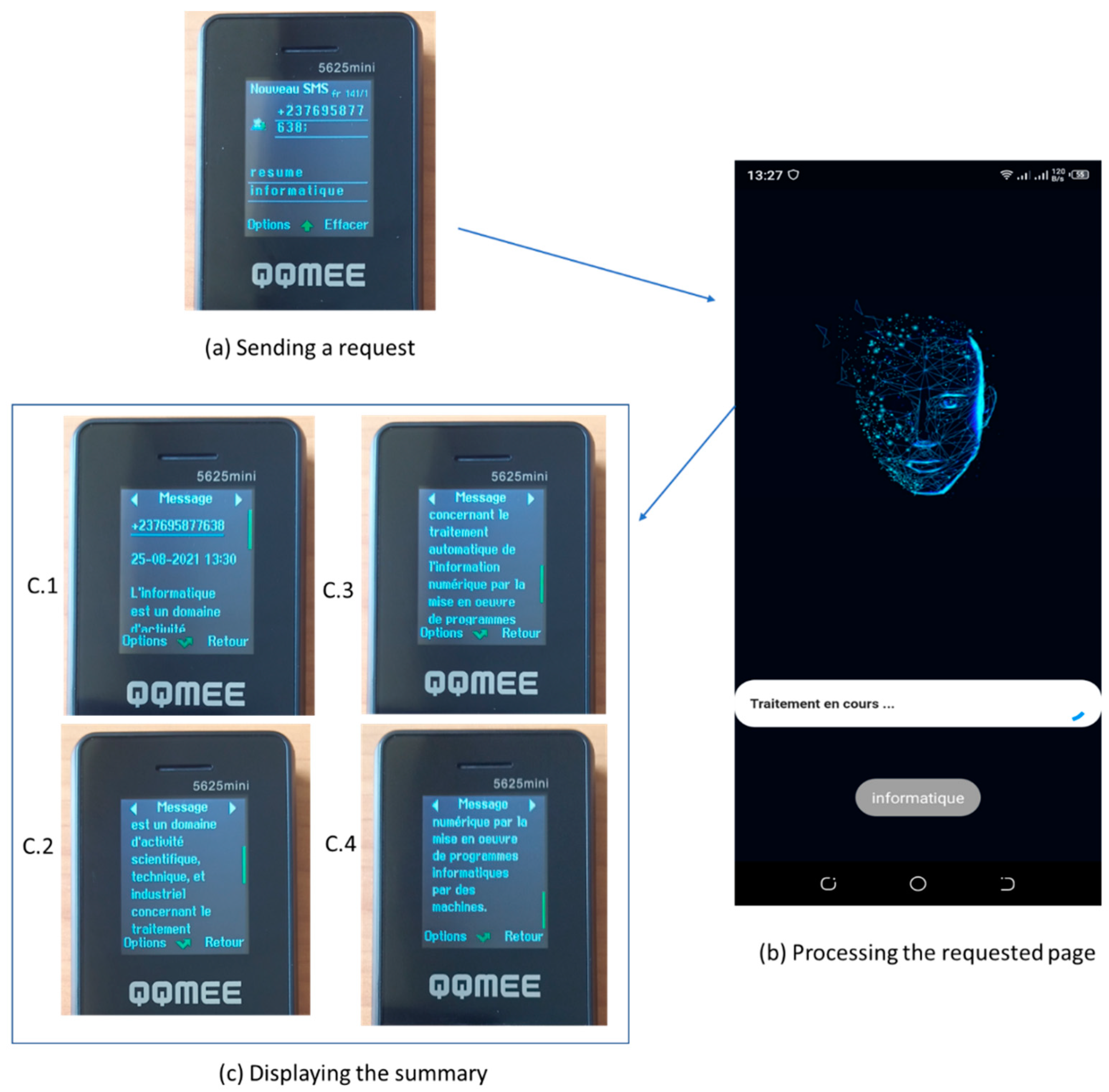
5. Demonstration
6. Conclusions and Future Works
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Wikidump Function
| Algorithm A1. Wikidump. |
| Input: : Title of the requested page Output: : Cleaned Content for summarization process; |
| Begin Import Wikipedia wikipedia.set_lang(“fr”) Connect to fr.wikipedia.org/title wiki = wikipedia.page(title) If a response then Content = wiki.content For every line in the Content text = re.sub(r’==.*?==+’, ‘‘, line) text = text.replace(‘\n’, ‘‘) endFor endIf return End |
Appendix B. Dataset

Appendix C. Length_Checker Function
| Algorithm A2. Length_Checker. |
| Input: : The generated summary by the summarizer Output: : The final summary sent to the user; |
| Begin = If length() <= 455 then return Else While > 455 do remove_last_sentence() return End |
References
- Maybury, M.T. Generating summaries from event data. Inf. Process. Manag. 1995, 31, 735–751. [Google Scholar] [CrossRef]
- El-Kassas, W.S.; Salama, C.R.; Rafea, A.A.; Mohamed, H.K. Automatic text summarization: A comprehensive survey. Expert Syst. Appl. 2021, 165, 113679. [Google Scholar] [CrossRef]
- Antunes, J.; Lins, R.D.; Lima, R.; Oliveira, H.; Riss, M.; Simske, S.J. Automatic cohesive summarization with pronominal anaphora resolution. Comput. Speech Lang. 2018, 52, 141–164. [Google Scholar] [CrossRef]
- Steinberger, J.; Kabadjov, M.; Poesio, M.; Sanchez-Graillet, O. Improving LSA-based summarization with anaphora resolution. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, CB, Canada, 6–8 October 2005; pp. 1–8. [Google Scholar]
- Steinberger, J.; Poesio, M.; Kabadjov, M.A.; Ježek, K. Two uses of anaphora resolution in summarization. Inf. Process. Manag. 2007, 43, 1663–1680. [Google Scholar] [CrossRef]
- Sahni, A.; Palwe, S. Topic Modeling on Online News Extraction. In Intelligent Computing and Information and Communication; Springer: Berlin/Heidelberg, Germany, 2018; pp. 611–622. [Google Scholar]
- Sethi, P.; Sonawane, S.; Khanwalker, S.; Keskar, R.B. Automatic text summarization of news articles. In Proceedings of the 2017 International Conference on Big Data, IoT and Data Science (BID), Pune, India, 20–22 December 2017; pp. 23–29. [Google Scholar]
- Bhargava, R.; Sharma, Y. MSATS: Multilingual sentiment analysis via text summarization. In Proceedings of the 2017 7th International Conference on Cloud Computing, Data Science & Engineering-Confluence, Noida, India, 12–13 January 2017; pp. 71–76. [Google Scholar]
- Mary, A.J.J.; Arockiam, L. ASFuL: Aspect based sentiment summarization using fuzzy logic. In Proceedings of the 2017 International Conference on Algorithms, Methodology, Models and Applications in Emerging Technologies (ICAMMAET), Chennai, India, 16–18 February 2017; pp. 1–5. [Google Scholar]
- Chakraborty, R.; Bhavsar, M.; Dandapat, S.K.; Chandra, J. Tweet summarization of news articles: An objective ordering-based perspective. IEEE Trans. Comput. Soc. Syst. 2019, 6, 761–777. [Google Scholar] [CrossRef]
- Carenini, G.; Ng, R.T.; Zhou, X. Summarizing email conversations with clue words. In Proceedings of the 16th international conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 91–100. [Google Scholar]
- Mohammad, S.; Dorr, B.; Egan, M.; Hassan, A.; Muthukrishnan, P.; Qazvinian, V.; Radev, D.; Zajic, D. Using citations to generate surveys of scientific paradigms. In Proceedings of the Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Boulder, CO, USA, 31 May–5 June 2009; pp. 584–592. [Google Scholar]
- Jiang, X.-J.; Mao, X.-L.; Feng, B.-S.; Wei, X.; Bian, B.-B.; Huang, H. Hsds: An abstractive model for automatic survey generation. In Proceedings of the International Conference on Database Systems for Advanced Applications; Springer: Berlin/Heidelberg, Germany, 2019; pp. 70–86. [Google Scholar]
- Sun, J.-T.; Shen, D.; Zeng, H.-J.; Yang, Q.; Lu, Y.; Chen, Z. Web-page summarization using clickthrough data. In Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 15–19 August 2005; pp. 194–201. [Google Scholar]
- Ebongue, J.L.F.K. Rethinking Network Connectivity in Rural Communities in Cameroon. ar**v 2015, ar**v:1505.04449. Available online: https://arxiv.org/ftp/arxiv/papers/1505/1505.04449.pdf (accessed on 18 June 2021).
- Pinkovskiy, M.; Sala-i-Martin, X. Africa is on time. J. Econ. Growth 2014, 19, 311–338. [Google Scholar] [CrossRef]
- Ebongue, J.L.F.K.; Thron, C.; Nlong, J.M. Mesh Router Nodes placement in Rural Wireless Mesh Networks. ar**v 2015, ar**v:150503332. [Google Scholar]
- Fendji, J.L.E.K.; Thron, C.; Nlong, J.M. A metropolis approach for mesh router nodes placement in rural wireless mesh networks. ar**v 2015, ar**v:150408212. [Google Scholar] [CrossRef] [Green Version]
- Du Plessis, P.; Mestry, R. Teachers for rural schools—A challenge for South Africa. S. Afr. J. Educ. 2019, 39. [Google Scholar] [CrossRef]
- Mulkeen, A. Teachers for Rural Schools: A Challenge for Africa; FAO: Rome, Italy, 2005. [Google Scholar]
- Selwyn, N.; Gorard, S. Students’ use of Wikipedia as an academic resource—Patterns of use and perceptions of usefulness. Internet High. Educ. 2016, 28, 28–34. [Google Scholar] [CrossRef] [Green Version]
- Sankarasubramaniam, Y.; Ramanathan, K.; Ghosh, S. Text summarization using Wikipedia. Inf. Process. Manag. 2014, 50, 443–461. [Google Scholar] [CrossRef]
- Ramanathan, K.; Sankarasubramaniam, Y.; Mathur, N.; Gupta, A. Document summarization using Wikipedia. In Proceedings of the First International Conference on Intelligent Human Computer Interaction; Springer: Berlin/Heidelberg, Germany, 2009; pp. 254–260. [Google Scholar]
- Lin, C.-Y.; Hovy, E. The potential and limitations of automatic sentence extraction for summarization. In Proceedings of the HLT-NAACL 03 Text Summarization Workshop, Stroudsburg, PA, USA, 31 May 2003; pp. 73–80. [Google Scholar]
- Fendji, J.L.E.K.; Aminatou, B.A.H. From web to SMS: A text summarization of Wikipedia pages with character limitation. EAI Endorsed Trans. Creat. Technol. 2020, 7. [Google Scholar] [CrossRef]
- Banerjee, S.; Mitra, P. WikiWrite: Generating Wikipedia Articles Automatically. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; p. 7. [Google Scholar]
- Paulus, R.; **ong, C.; Socher, R. A Deep Reinforced Model for Abstractive Summarization. ar**v 2017, ar**v:170504304. Available online: http://arxiv.org/abs/1705.04304 (accessed on 18 June 2021).
- Gehrmann, S.; Deng, Y.; Rush, A.M. Bottom-Up Abstractive Summarization. ar**v 2018, ar**v:180810792. Available online: http://arxiv.org/abs/1808.10792 (accessed on 18 June 2021).
- Liu, F.; Flanigan, J.; Thomson, S.; Sadeh, N.; Smith, N.A. Toward Abstractive Summarization Using Semantic Representations. ar**v 2018, ar**v:180510399. Available online: http://arxiv.org/abs/1805.10399 (accessed on 20 June 2021).
- Chen, Y.-C.; Bansal, M. Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting. ar**v 2018, ar**v:180511080. Available online: http://arxiv.org/abs/1805.11080 (accessed on 20 June 2021).
- Fan, A.; Grangier, D.; Auli, M. Controllable Abstractive Summarization. ar**v 2018, ar**v:171105217. Available online: http://arxiv.org/abs/1711.05217 (accessed on 22 June 2021).
- Wolf, T.; Chaumond, J.; Debut, L.; Sanh, V.; Delangue, C.; Moi, A.; Cistac, P.; Funtowicz, M.; Davison, J.; Shleifer, S. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Luhn, H.P. The automatic creation of literature abstracts. IBM J. Res. Dev. 1958, 2, 159–165. [Google Scholar] [CrossRef] [Green Version]
- Edmundson, H.P. New methods in automatic extracting. J. ACM JACM 1969, 16, 264–285. [Google Scholar] [CrossRef]
- Gambhir, M.; Gupta, V. Recent automatic text summarization techniques: A survey. Artif. Intell. Rev. 2017, 47, 1–66. [Google Scholar] [CrossRef]
- Christian, H.; Agus, M.P.; Suhartono, D. Single document automatic text summarization using term frequency-inverse document frequency (TF-IDF). ComTech Comput. Math. Eng. Appl. 2016, 7, 285–294. [Google Scholar] [CrossRef]
- Sarkar, K. Automatic single document text summarization using key concepts in documents. J. Inf. Process. Syst. 2013, 9, 602–620. [Google Scholar] [CrossRef]
- Erkan, G.; Radev, D. Lexpagerank: Prestige in multi-document text summarization. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 365–371. [Google Scholar]
- Uçkan, T.; Karcı, A. Extractive multi-document text summarization based on graph independent sets. Egypt. Inform. J. 2020, 21, 145–157. [Google Scholar] [CrossRef]
- Patel, A.; Siddiqui, T.; Tiwary, U.S. A language independent approach to multilingual text summarization. Large Scale Semant. Access Content 2007, 123–132. [Google Scholar]
- Radev, D.R.; Allison, T.; Blair-Goldensohn, S.; Blitzer, J.; Celebi, A.; Dimitrov, S.; Drabek, E.; Hakim, A.; Lam, W.; Liu, D.; et al. MEAD-A Platform for Multidocument Multilingual Text Summarization; European Language Resources Association (ELRA): Lisbon, Portugal, 2004. [Google Scholar]
- Pontes, E.L.; González-Gallardo, C.-E.; Torres-Moreno, J.-M.; Huet, S. Cross-lingual speech-to-text summarization. In Proceedings of the International Conference on Multimedia and Network Information System; Springer: Berlin/Heidelberg, Germany, 2018; pp. 385–395. [Google Scholar]
- Zhu, J.; Wang, Q.; Wang, Y.; Zhou, Y.; Zhang, J.; Wang, S.; Zong, C. NCLS: Neural cross-lingual summarization. ar**v 2019, ar**v:190900156. [Google Scholar]
- Moratanch, N.; Chitrakala, S. A survey on extractive text summarization. In Proceedings of the 2017 International Conference on Computer, Communication and Signal Processing (ICCCSP), Chennai, India, 10–11 January 2017; pp. 1–6. [Google Scholar]
- Moratanch, N.; Chitrakala, S. A survey on abstractive text summarization. In Proceedings of the 2016 International Conference on Circuit, Power and Computing Technologies (ICCPCT), Nagercoil, India, 18–19 March 2016; pp. 1–7. [Google Scholar]
- Hou, L.; Hu, P.; Bei, C. Abstractive document summarization via neural model with joint attention. In Proceedings of the National CCF Conference on Natural Language Processing and Chinese Computing; Springer: Berlin/Heidelberg, Germany, 2017; pp. 329–338. [Google Scholar]
- Wang, S.; Zhao, X.; Li, B.; Ge, B.; Tang, D. Integrating extractive and abstractive models for long text summarization. In Proceedings of the 2017 IEEE International Congress on Big Data (BigData Congress), Honolulu, HI, USA, 25–30 June 2017; pp. 305–312. [Google Scholar]
- Liu, P.; Qiu, X.; Chen, X.; Wu, S.; Huang, X.-J. Multi-timescale long short-term memory neural network for modelling sentences and documents. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2326–2335. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; 2017; pp. 5998–6008. Available online: https://arxiv.org/pdf/1706.03762.pdf (accessed on 15 September 2021).
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. ar**v 2018, ar**v:181004805. [Google Scholar]
- Martin, L.; Muller, B.; Suárez, P.J.O.; Dupont, Y.; Romary, L.; de La Clergerie, É.V.; Seddah, D.; Sagot, B. Camembert: A tasty french language model. ar**v 2019, ar**v:191103894. [Google Scholar]
- Le, H.; Vial, L.; Frej, J.; Segonne, V.; Coavoux, M.; Lecouteux, B.; Allauzen, A.; Crabbé, B.; Besacier, L.; Schwab, D. Flaubert: Unsupervised language model pre-training for french. ar**v 2019, ar**v:191205372. [Google Scholar]
- Liu, Y.; Lapata, M. Text summarization with pretrained encoders. ar**v 2019, ar**v:190808345. [Google Scholar]
- Liu, Y. Fine-tune BERT for extractive summarization. ar**v 2019, ar**v:190310318. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. ar**v 2019, ar**v:191010683. [Google Scholar]
- Google AI Blog: Exploring Transfer Learning with T5: The Text-To-Text Transfer Transformer. Available online: https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html (accessed on 26 August 2021).
- Kale, M. Text-to-text pre-training for data-to-text tasks. ar**v 2020, ar**v:200510433. [Google Scholar]
- Affine. Affine—Bidirectional Encoder Representations for Transformers (BERT) Simplified. 2019. Available online: https://www.affine.ai/bidirectional-encoder-representations-for-transformers-bert-simplified/ (accessed on 26 August 2021).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. ar**v 2014, ar**v:14126980. [Google Scholar]
- Lin, C.-Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, July 2004; pp. 74–81. Available online: https://pdfs.semanticscholar.org/60b0/5f32c32519a809f21642ef1eb3eaf3848008.pdf (accessed on 15 September 2021).
- Liu, P.J.; Saleh, M.; Pot, E.; Goodrich, B.; Sepassi, R.; Kaiser, L.; Shazeer, N. Generating wikipedia by summarizing long sequences. ar**v 2018, ar**v:180110198. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Titre | Kousseri | Eseka | Tibati | Yaou Aissatou | Bafoussam | Chantal Biya |
|---|---|---|---|---|---|---|
| LA 1 (Fr) | 5797 | 9762 | 2875 | 3000 | 10,902 | 4004 |
| LA (En) | 1386 | 510 | 729 | 1233 | 1790 | 1951 |
| RS 2 (Fr) | 372 | 112 | 831 | 1560 | 401 | 341 |
| RS (En) | 459 | 43 | 726 | 1230 | 1516 | 100 |
| LT 3 ROUGE-1 (En) | 0.57 | 1 | 0.56 | 0.68 | 0.52 | 1 |
| LT ROUGE-2 (En) | 0.56 | 1 | 0.5 | 0.60 | 0.45 | 1 |
| WS 4 ROUGE-1 (Fr) | 0.97 | 0.76 | 0.91 | 0.74 | 0.77 | 0.80 |
| WS ROUGE-2 (Fr) | 0.97 | 0.75 | 0.90 | 0.71 | 0.76 | 0.83 |
| Title | Page Content | Generated Summary |
|---|---|---|
| Kousséri | Summary section Kousséri est une commune du Cameroun située dans la région de l’Extrême-Nord et le département du Logone-et-Chari, dont elle est le chef-lieu. À l’époque coloniale, elle se nommait Kusseri au sein de la colonie allemande du Kamerun, puis Fort-Foureau au sein de la colonie du Cameroun français. C’est un important marché, notamment pour les échanges avec le Tchad voisin. Content section Kousséri est une cité très ancienne, remontant au moins à la civilisation Sao (**e—XVIe siècles). Ville Kotoko, l’une de cinq principauté “kotoko”. Son nom d’origine est M’sr. Un peu plus tard appelé (Qussur: les châteaux) en arabe. Au XVIe siècle, elle était la capitale d’un royaume de M’sr en langue Kotoko dont les élites au moins étaient islamisées, et mentionnée sous la forme italienne Uncusciuri par Giovanni Lorenzo d’Anania (en).... | Kousséri est la capitale d’un royaume de M’sr en langue Kotoko dont les élites au moins étaient islamisées, puis Fort-Foureau au sein de la colonie du Cameroun français. |
| Chantal Biya | Summary section Chantal Biya, née Chantal Pulchérie Vigouroux le 4 décembre 1970, est la seconde épouse du second président de la République du Cameroun, Paul Biya. Elle est la troisième Première dame du Cameroun depuis son mariage, le 23 avril 1994. Elle met cette position de Première dame au profit d’un engagement caritatif de lutte contre le SIDA. | née Chantal Vigouroux le 4 décembre 1970, est la seconde épouse du second président de la République du Cameroun depuis son mariage, le 23 avril 1994. |
| Informatique | Summary section L’informatique est un domaine d’activité scientifique, technique, et industriel concernant le traitement automatique de l’information numérique par l’exécution de programmes informatiques par des machines: des systèmes embarqués, des ordinateurs, des robots, des automates, etc. Ces champs d’application peuvent être séparés en deux branches: théorique: concerne la définition de concepts et modèles; pratique: s’intéresse aux techniques concrètes de mise en œuvre… | L’informatique est un domaine d’activité scientifique, technique, et industriel concernant le traitement automatique de l’information numérique par la mise en oeuvre de programmes informatiques par des machines. |
| Summarizer | Descriptions | ROUGE-1 | ROUGE-2 |
|---|---|---|---|
| Wikipedia-based summarizer | Bipartite sentence-concept graph, rank the input sentence | 0.46 | 0.23 |
| WATS-SMS | Models based on Wikipedia Datasets. | 0.52 | 0.41 |
| Model | Language | ROUGE-L | L |
|---|---|---|---|
| Seq2seq-attention | English | 12.7 | 500 |
| Transformer-ED | English | 34.2 | 500 |
| WATS-SMS | French | 52.3 | [0–500] |
| Model | Language | ROUGE-L | L |
|---|---|---|---|
| Transformer-DMCA, no MoELayer | English | 36.2 | 11,000 |
| Transformer-DMCA, MoE-128 | English | 37.9 | 11,000 |
| WATS-SMS | French | 77.0 | 10,902 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fendji, J.L.E.K.; Taira, D.M.; Atemkeng, M.; Ali, A.M. WATS-SMS: A T5-Based French Wikipedia Abstractive Text Summarizer for SMS. Future Internet 2021, 13, 238. https://doi.org/10.3390/fi13090238
Fendji JLEK, Taira DM, Atemkeng M, Ali AM. WATS-SMS: A T5-Based French Wikipedia Abstractive Text Summarizer for SMS. Future Internet. 2021; 13(9):238. https://doi.org/10.3390/fi13090238
Chicago/Turabian StyleFendji, Jean Louis Ebongue Kedieng, Désiré Manuel Taira, Marcellin Atemkeng, and Adam Musa Ali. 2021. "WATS-SMS: A T5-Based French Wikipedia Abstractive Text Summarizer for SMS" Future Internet 13, no. 9: 238. https://doi.org/10.3390/fi13090238