1. Introduction
With the development of remote sensing technology, large amounts of Earth-observation images with high resolution are becoming increasingly available and playing an ever-more important role in remote sensing scene classification [
1]. High-Resolution Satellite (HRS) images provide much of the appearance and spatial arrangement information that is useful for remote sensing scene category recognition [
2]. However, it is difficult to recognize remote sensing scene categories because they usually cover multiple land use categories or ground objects [
3,
4,
5,
6,
7,
8,
9,
10] such as airports with airplanes, runways, and grass. The classification of HRS images turns from a single remote sensing scene category-based or single object-based classification to a remote sensing scene-based semantic classification [
11]. Remote sensing scene categories are largely affected and determined by human and social activities, and the recognition of remote sensing scene image is therefore based on a priori knowledge. As a result of such difficulties, traditional pixel-based [
12] and low-level feature-based image classification techniques [
13,
14] can no longer achieve satisfactory results for remote sensing scene classification.
In the past few years, a large number of feature representation models have been proposed for scene classification. One of the most popularly used models is the Bag-Of-Visual-Words (BOVW) model [
15,
16,
17,
18], which provides an efficient solution for remote sensing scene classification. The BOVW model, initially proposed for text categorization, treats an image as a collection of unordered appearance descriptors, and represents the images with the frequency of “visual words” that are constructed by quantizing local features, such as the Scale-Invariant Feature Transform (SIFT) [
19] or Histograms of Oriented Gradients (HOGs) [
20] with a clustering method (for example, k-means) [
15]. The original BOVW method discards the spatial order of the local features and severely limits the descriptive capability of image representation. Therefore, many variant methods [
4,
21,
22,
23] based on the BOVW model have been developed for improving the ability to depict the spatial relationships of local features. These methods are based on hand-crafted features, which rely heavily on the experience and domain knowledge of experts. Due to the lack of consideration for the details of actual data, it is difficult with these low-level features to attain a balance between discriminability and robustness [
24]. Such features often fail to accurately characterize the complex remote sensing scenes found in HRS images [
25].
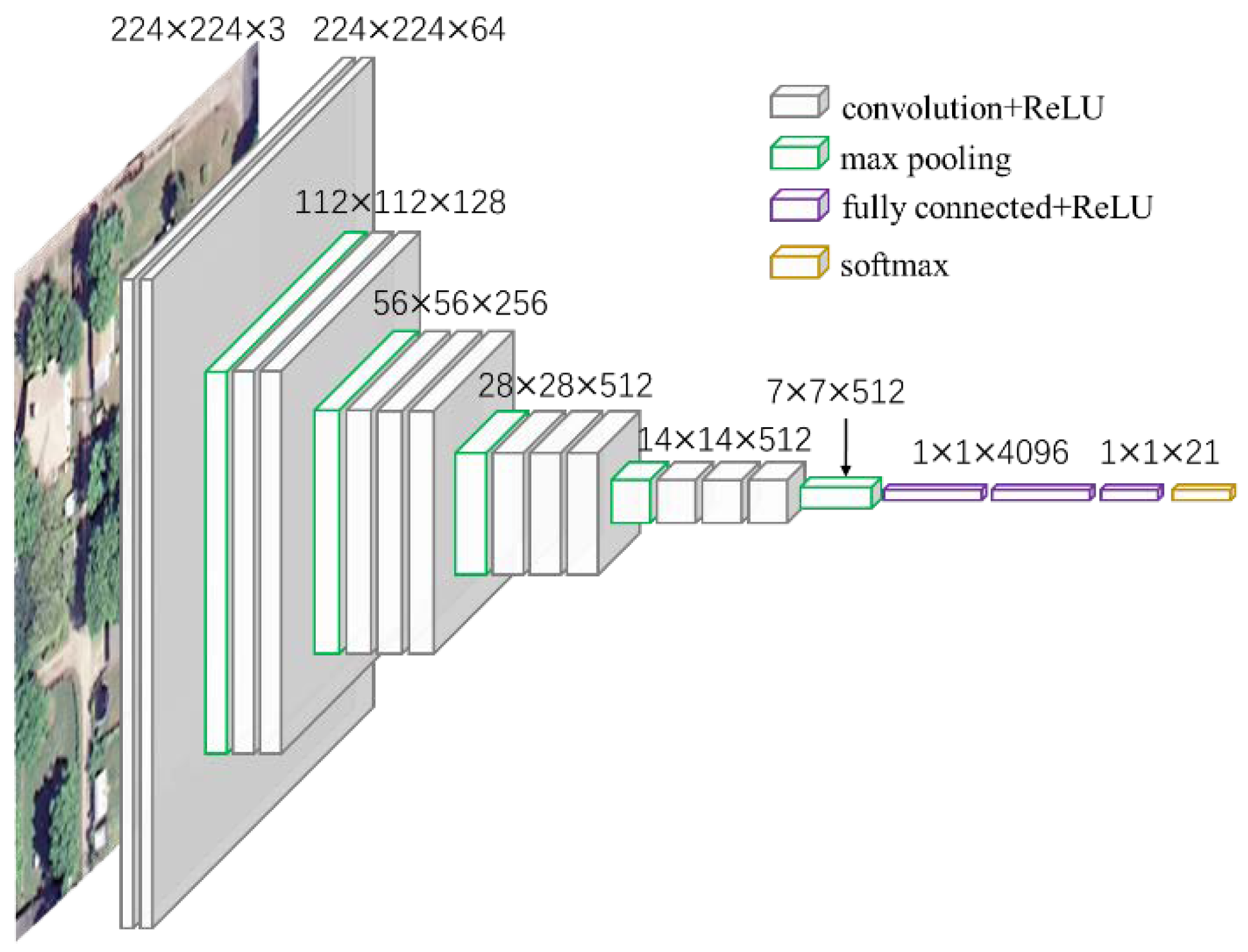
Deep Learning (DL) algorithms, especially Convolutional Neural Networks (CNNs), have achieved great success in image classification [
26], detection [
27], and segmentation [
28] on several benchmarks [
29]. CNN is a hierarchical network invariant to image translations, which is composed of convolutional layers, pooling layers, and fully-connected layers. The key to success is the ability to learn the increasingly complex transformations of the input and to capture invariances from large labelled datasets [
30]. However, it is difficult to directly apply the CNNs to remote sensing scene classification for millions of parameters to train the CNNs, which the training samples are insufficient for training. The studies in References [
31,
32,
33,
34,
35,
36,
37] have demonstrated that CNNs can be pre-trained on large natural image datasets such as ImageNet [
38], which contains general-purposed feature extractors, and can be transferable to many other domains. This is very helpful in the remote sensing scene classification because of the difficulty of training a deep CNN with a small number of training samples. Many approaches utilize the outputs of a deep and fully-connected layer as features to achieve transfer in CNNs. These methods, however, concatenate the outputs of the last convolutional layer to link with the fully-connected layer. This transformation does not capture the information concerning the spatial layout, which has limited descriptive ability in remote sensing scene classification. The works in References [
4,
25,
39] can capture the spatial arrangement for the local features. They are designed for the hand-craft features and are not end-to-end trainable as CNNs are. The Spatial Pyramid Pooling (SPP) [
40,
41,
42,
43,
44] (popularly known as the Spatial Pyramid Matching or SPM [
21]) can incorporate spatial information by partitioning the image into increasingly fine subregions and computing the histograms of local features found inside each subregion. He et al. [
41] introduce an SPP layer, which should, in general, improve the CNN-based image classification methods. Nevertheless, this pooling method was designed for natural image scene classification using ordered regular grids that incorporate spatial information into the representation, and therefore, are sensitive to the rotation of image scenes. This sensitivity problem inevitably causes the misclassification of scene images, especially for remote sensing scene images, and influences classification performance. These works in References [
45,
46] can learn a rotation-invariant CNN model object detection in remote sensing images by using data augmentation method which generates a set of new training samples by rotating transformation. These methods were designed for object detection and the data augmentation operation will inevitably increase the computational cost especially on large dataset because several transformations are required for each training samples.
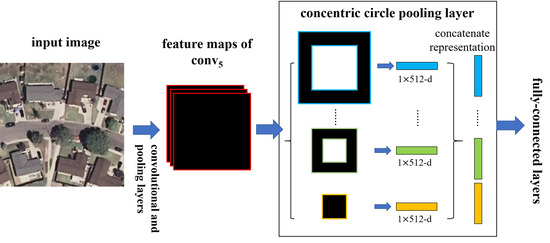
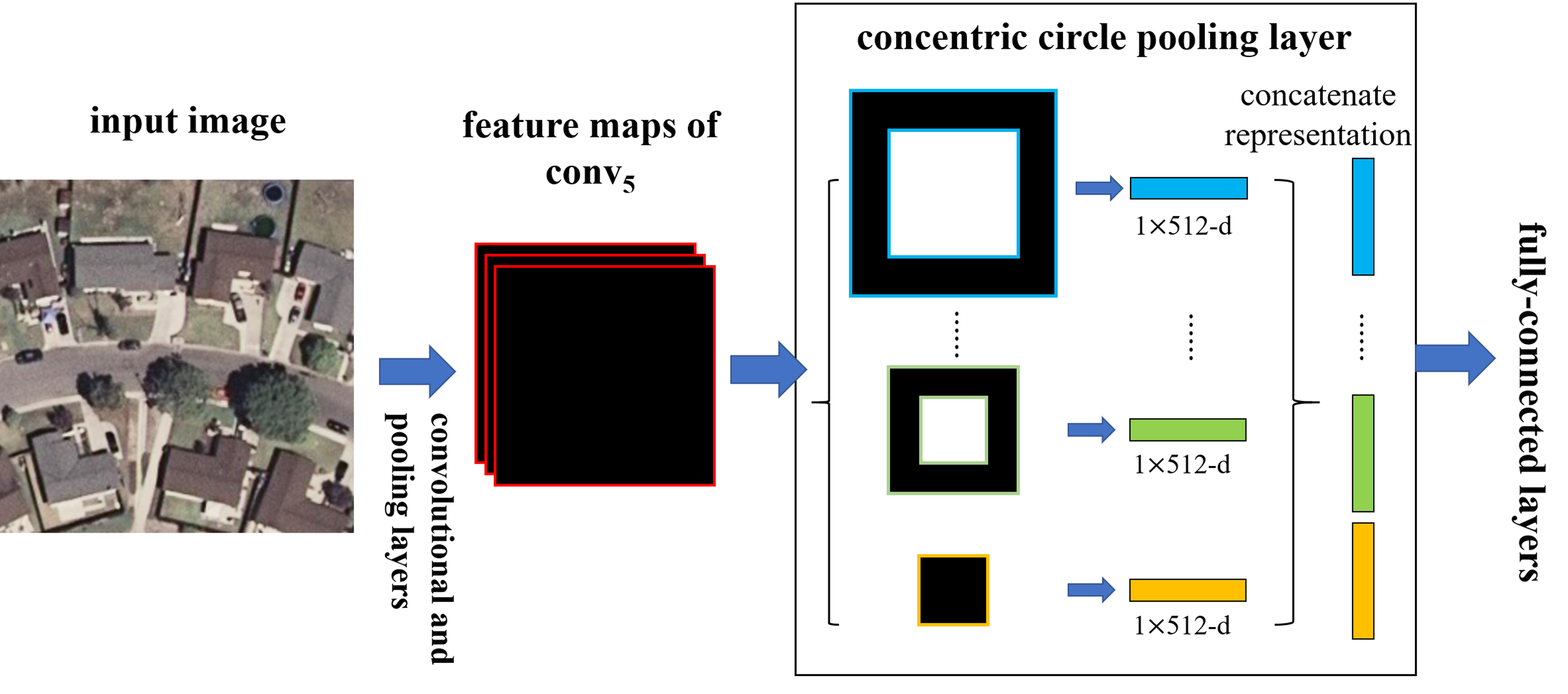
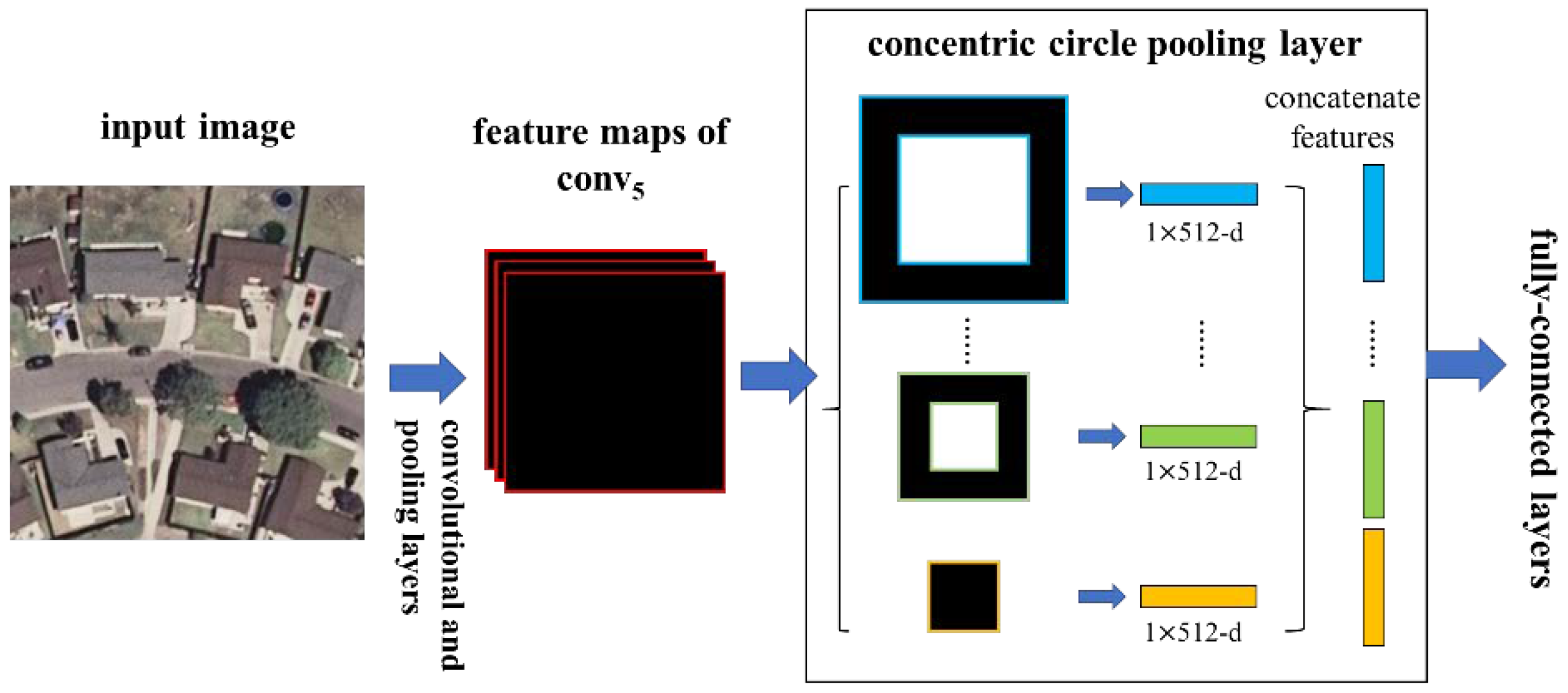
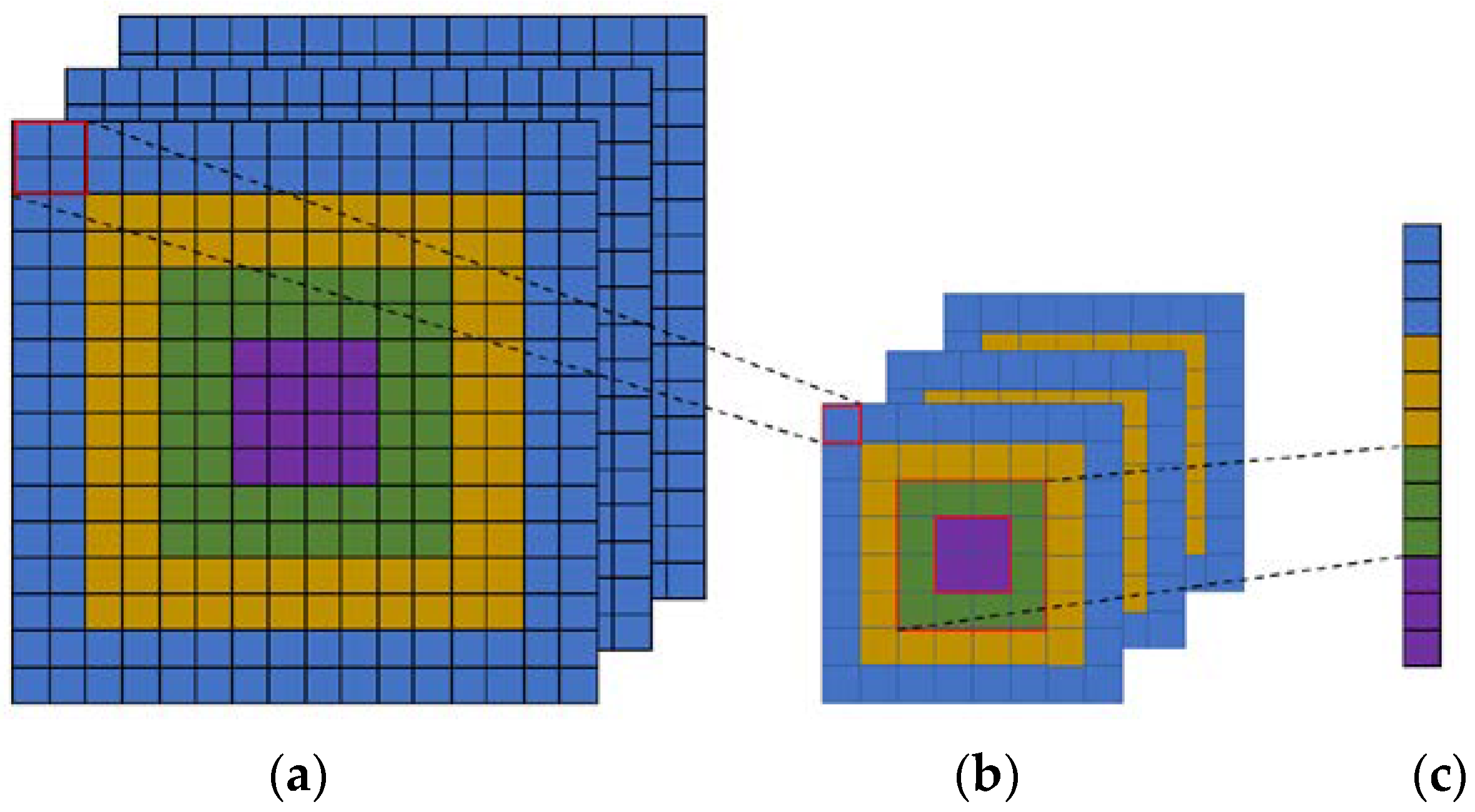
In this paper, we introduce a Concentric Circle Pooling (CCP) layer to incorporate rotation-invariant spatial layout information of remote sensing scene images. The concentric circle-based partition strategy of an image has been proven effective for rotation-invariant spatial information representation in color and texture feature extraction [
47,
48] and the BOVW [
11] and FV representations [
49]. It partitions the image into a series of annular subregions and aggregates the local features found inside each annular subregion. However, concentric circle pooling has not been considered in the context of CNNs for remote sensing images. We applied this strategy to CNN models and designed a new network structure (called CCP-net) for remote sensing scene classification. Specifically, we added a CCP layer on top of the last convolutional layer. The CCP layer pools the convolutional features and then feeds them into the fully-connected layers. Thus, for the CCP layer, using annular spatial bins, we can pool the convolutional features to achieve a rotation invariant spatial representation. The experiments were conducted based on two public ground truth image datasets, manually extracted from publicly available high-resolution overhead imagery. The experimental results show that the CCP layer helps CNNs to represent the remote sensing scene images and achieve high classification accuracies.
The remainder of this paper is organized as follows:
Section 2 introduces the proposed CCP layer for remote sensing scene classification. The experimental results and analysis are presented in
Section 3, followed by an analysis and discussion in
Section 4. In
Section 5, some concluding remarks are presented and perspectives on future work close the paper.
4. Discussion
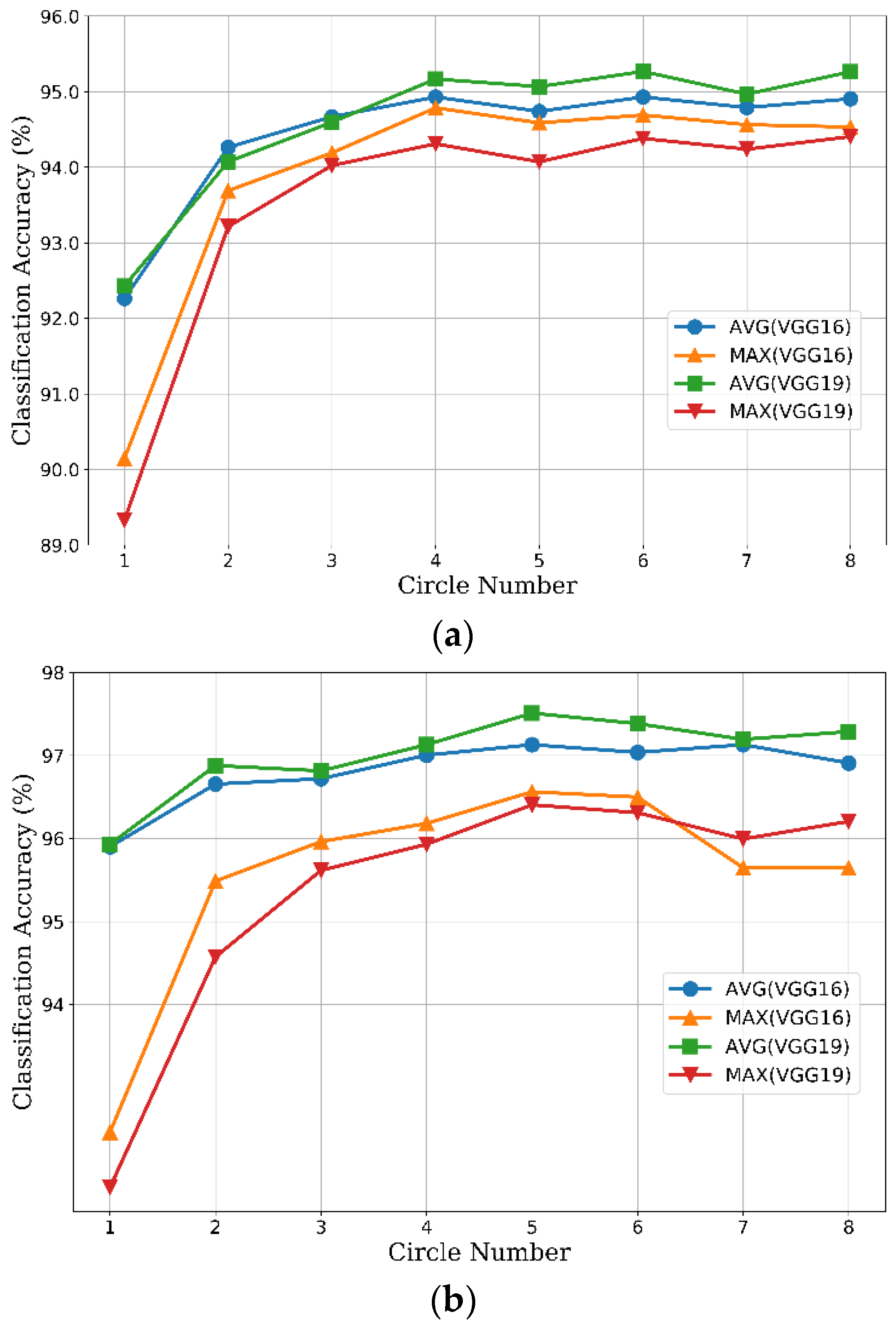
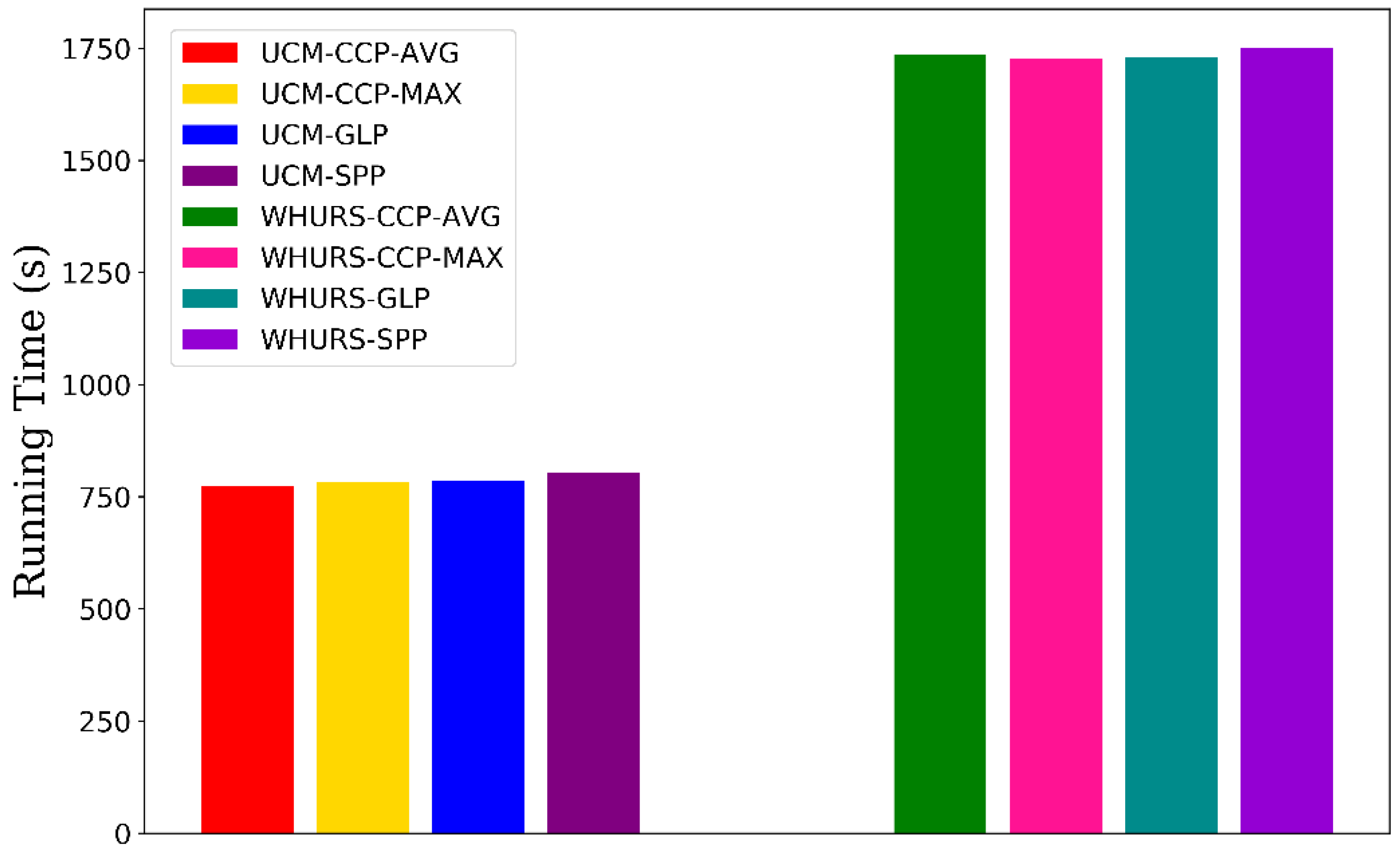
Extensive experiments show that our CCP-net is simple but very effective for remote sensing scene classification in HRS images. We use the concentric circle pooling to capture the rotation-invariant spatial information for the CNN architectures. We create a rotated dataset based on the UCM dataset with each image randomly rotated. Thus, each class includes 200 images in the rotated dataset.
In
Table 3 we compare the CCP-net and SPP-net on the UCM and the rotated datasets. We froze all the convolutional layers and set the initial learning rate to 1 × 10
−4. These networks use the optimal parameters obtained in
Section 3.2.2. For these two networks, the overall classification accuracies on the rotated dataset are greater than the results on the UCM dataset. This may be because the rotated dataset contains additional rotated images based on the UCM dataset, which makes the sample images more abundant. For the additional rotated images, the CCP-net has more advantage over the SPP-net in the classification accuracy. This proves that the CCP-net are insensitive to the rotation of remote sensing scenes. The performance of CCP-net in almost all categories are improved more than SPP-net. The classification accuracies of some categories in the SPP-net are decreased more than 1%. The possible reason is that some of the classes are similar in part of scene image and the rotated images will increase their similarity. For example, the freeway and overpass are more easily to be confused, and the forest are more easily to be recognized as sparse residential. This is an indication of the importance of rotation-invariance for the remote sensing scene images. Compare with the results on the UCM dataset, the classification accuracies on the rotated dataset are 1.7% higher for CCP-net and 0.74% higher for SPP-net. The promotion of CCP-net is more than twice that of SPP-net. To sum up, our proposed method is rotation-invariant to image scenes and is effective for remote sensing scene image classification.
We use attention heatmap and gradient-weighted class activation maps [
57] to assess whether a network is attending to correct parts of the image to generate a decision. The entire models were trained as
Section 3.3 to fine-tune the convolutional layers that transfer from VGG-VD16.
Figure 11 show the visualization results of CCP-net and SPP-net on the UCM dataset. In
Figure 11b,d, the heatmap images indicate that the edges and corners in the scene images are contribute minimizing the weighted losses the most for these two methods. The saliency regions in the heatmaps of CCP-net are relatively concentrated for the concentric circle pooling in CCP-net. Due to the multiple pyramid-level pooling, the SPP-net may pay attention to more regions, especially for the categories with flat and similar pattern, e.g., forest and river. In
Figure 11c,e, we show the gradient based class activation maps to produce a coarse localization map of the important regions in the image for CCP-net and SPP-net. These maps use the class-specific gradient information flowing into the final convolutional layer of CNNs. It is shown that these networks can learn meaningful representation for scene classification, e.g., tennis courts and baseball diamond. Owing to the rotation invariance, the CCP-net can take notice of the distinguishing parts in scene images, for example, intersection part in the overpass, and airplane in the airport. This illustrates that the rotation invariance can help the CNNs to follow the discriminative parts between remote sensing scene categories.
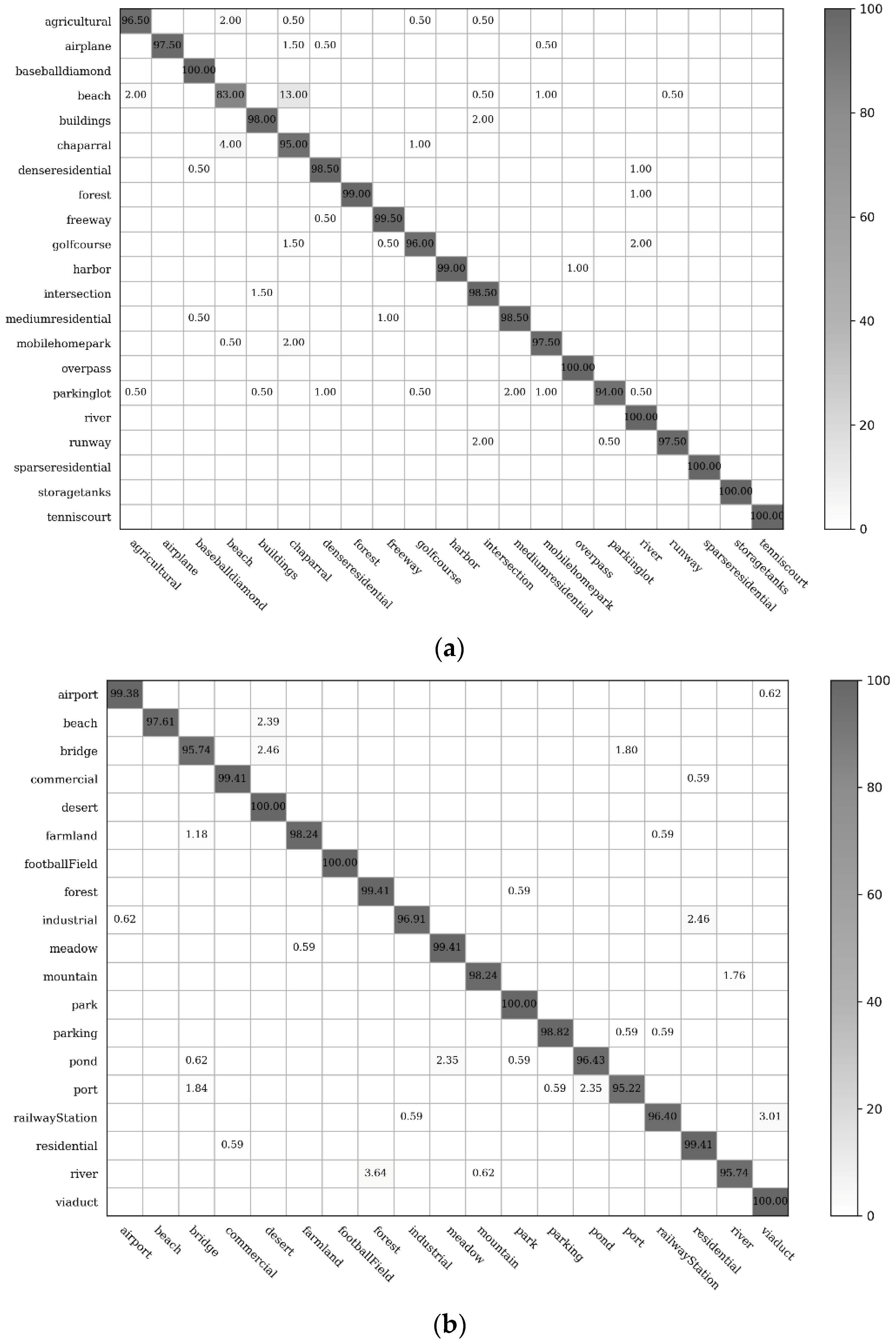
Several example images are presented in
Figure 12 and
Figure 13 that compare results from the networks with concentric circle pooling and spatial pyramid pooling on the UCM and WHU-RS datasets. As shown in
Figure 12, these remote sensing scene images containing small objects, like the baseball diamond and storage tank, can be recognized by our CCP-net model. These remote sensing scenes are easily misclassified using SPP-net; the occurrences of small objects in different subregions, such as the baseball diamond, are recognized incorrectly as a golf course. Due to the rotation-invariant information, our model is more robust with respect to clutter background, like tennis courts in
Figure 8 and parks in
Figure 13. SPP-net, however, is more suitable for the scene images with regular grid layouts, like mobile home parks and beaches in
Figure 12 and parks in
Figure 13. Overall, CCP-net outperform SPP-net in classification accuracy because the remote sensing scene images are orthographical and irregular. The rotation-invariant is more import than the regular spatial arrangement for the remote sensing scene classification tasks.
These experimental results demonstrate the importance of rotation-invariant information for deep CNN features for remote sensing scene datasets. Our proposed concentric circle pooling method can assist the CNNs to be insensitive to the rotation of scenes and localize class-discriminative regions, thus, improve classification accuracies for remote sensing scene images.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}