1. Introduction
As aerial and satellite remote sensing images have become convenient information sources, extracting various artificial features from image information has become a research hotspot. Buildings, as one of the main artificial features in a city, have special significance in the automatic extraction of urban areas, map updating, urban change detection, urban planning, building energy consumption assessment, and infrastructure construction. The acquisition of buildings from remote sensing images has evolved into a mature research field after decades of development [
1,
2,
3,
4]. However, many challenges persist in this domain. First, given the building materials and their very close proximity to roads, buildings are easily confused with other elements. Second, the structure and spectrum of buildings are complex and diverse. Moreover, the considerable variance that occurs within this class makes buildings difficult to identify. Third, image structure is easily affected by the shadows of buildings and trees. Thus, automatically extracting buildings from remote sensing images is challenging.
Therefore, improving the recognition ability of feature representation in pixel-level recognition is necessary to extract buildings. Early image segmentation adopted a traditional image processing method based on artificial design characteristics, such as spectral information [
5], tone [
6], texture [
7], and geometric shape [
8,
9]. At present, image processing technologies based on convolutional neural networks (CNNs) have obtained remarkable development, and their accuracy and even efficiency far exceed those of traditional methods. Remote sensing image processing methods according to artificial intelligence (AI) and machine learning (ML) provide opportunities and possibilities for the automatic acquisition of buildings from remote sensing images. Particularly key to these technologies is the development of image classification [
10,
11,
12,
13], object detection [
14,
15,
16], and semantic segmentation [
17,
18,
19], as represented by deep learning. Semantic segmentation for the image is the purpose of each pixel in the allocation of a single category, and it can be seen as a dense classification problem. Most object parsing issues in image segmentation can be regarded as semantic segmentation. The depth of the continuous development of CNNs has helped many remarkable achievements in the semantic segmentation field. Long et al. [
18] extended the original convolutional neural network structure and proposed an end-to-end full convolutional neural network (FCN). Their FCN could achieve the intensive prediction of images without the use of fully connected layers. This kind of network is an encoder–decoder structure and enables the segmentation network to generate images of any size, which improves processing efficiency compared with the traditional image block classification method. Since then, almost all research on semantic segmentation has adopted the FCN structure [
19,
20,
21].
Many improved methods of FCN are employed to extract ground objects from remote sensing images. Maggiori et al. [
10] used a multi-scale structure to improve FCN to alleviate the tradeoff between increasing contexts and increasing the number of parameters. Mou et al. [
19] proposed a method that combined FCN and a recurrent neural network that used the most superficial boundary perception feature map to achieve accurate object boundary inference and semantic segmentation. Marmanis et al. [
20] adopted a parallel processing chain with two identical structures to improve FCN through delayed fusion with the help of a network layer in an early active deconvolution and cyclic feature graph. Xu et al. [
21] applied manual characteristics and the guided filtering technique to optimize building extraction with the res-u-net network they proposed.
Compared with the traditional manual design feature model, the semantic segmentation model based on a CNN has been significantly improved. However, in this model, the CNN uses the pooling layer many times to increase the receptive field. The use of down-sampling to compress data is irreversible, resulting in information loss and thereby causing translation invariance and smooth results. At the same time, this development leads to an inaccurate image contour generated by the convolutional network and an unclear boundary. On the basis of the strong recognition ability of CNNs, Chen et al. [
22] used fully connected conditional random fields (CRFs) for post-processing, which improved the quality of the object boundary in their segmentation results.
However, image segmentation still requires the precise position information of each pixel. Consequently, such a segmentation is inapplicable to pooling layers or striding convolution as boldly as a classification task to reduce computation. A mainstream method involves utilizing an encoder–decoder structure network [
18,
22,
23,
24,
25]. The encoder reduces the resolution of the input image through down-sampling to generate a feature map with low resolution. Then, the decoder performs upper sampling on these feature descriptions to restore the segmentation graph with full resolution, thereby significantly reducing the necessary calculation by decreasing the size of the feature map. Zeiler et al. [
26] proposed deconvolution for the first time for the reconstruction of feature maps to help them recover their original size. Tian et al. [
27] believed that the use of bilinear interpolation up-sampling to restore the resolution of a feature map might lead to an unsatisfactory segmentation result, so they designed a data-dependent up-sampling method called DUpsampling to replace bilinear interpolation.
In addition to computation, the multi-scaling of objects is also a challenge for CNNs. The extraction of any target feature is conducted on a certain scale, and different scales produce dissimilar results. To enlarge the receptive field of a feature map, Yu et al. [
28] proposed atrous convolution, an approach that can increase the receptive field without pooling operation. It allows each convolution operation to extract a wider range of information. Conversely, the pyramid pooling module developed by Zhao et al. [
29] can maximize the global feature hierarchy’s prior knowledge to understand different scenarios and aggregate the context information of various regions so as to give the feature map more semantic information using more global information. Chen et al. [
25] recommended atrous spatial pyramid pooling, which combines atrous convolution and spatial pyramid pooling. Using their scheme allows for the re-sampling of the convolutional features extracted from a single scale and the accurate and effective classification of regions at any scale. Liu et al. [
30] added low-level features to adjacent upper floors and combined them into new features. At the same time, each layer of feature maps could be predicted separately to realize detection at different scales.
In the recent semantic segmentation community, researchers have also shifted their attention toward the improvement of multi-task learning in addition to the enhancement of the encoder–decoder structure and multi-scaling. Scholars have increasingly begun to pay attention to multi-task learning. That learning entails the simultaneous learning of multiple related tasks and facilitates the sharing of the learned information among tasks. Dai et al. [
31] reduced the risk of model over-fitting and improved the accuracy of the results by learning the three tasks of mask estimation, instance differentiation, and object classification. Zhang et al. [
32] used head posture estimation and facial attribute inference as auxiliary tasks for improving the effectiveness of facial key-point detection.
The above studies not only developed various CNN models for semantic segmentation but also provided numerous ideas for our research. In addition, Zeiler et al. [
33] proved that a feature map gains more semantic information and loses more detailed information as the layers of its neural network deepen. However, as a pixel-level prediction task, semantic segmentation requires detailed and accurate information. As part of detailed information, semantic segmentation is widely concerned with the edge in to boost the performance of neural networks. Yu et al. [
34] obtained as many features as possible through inter-class differences to enhance semantic segmentation performance under precise boundary supervision. Qin et al. [
35] implicitly injected precise boundary prediction targets into mixing loss to reduce false errors from the cross-propagation of information learned in other areas of the boundary and image.
Inspired by multi-task learning and edge information utilization, we hereby designed a new edge perception network according to edge information supervision to automatically extract buildings from high-resolution aerial images. The main contributions of this work are as follows.
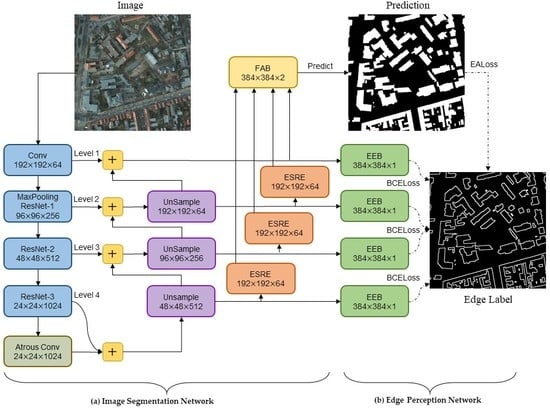
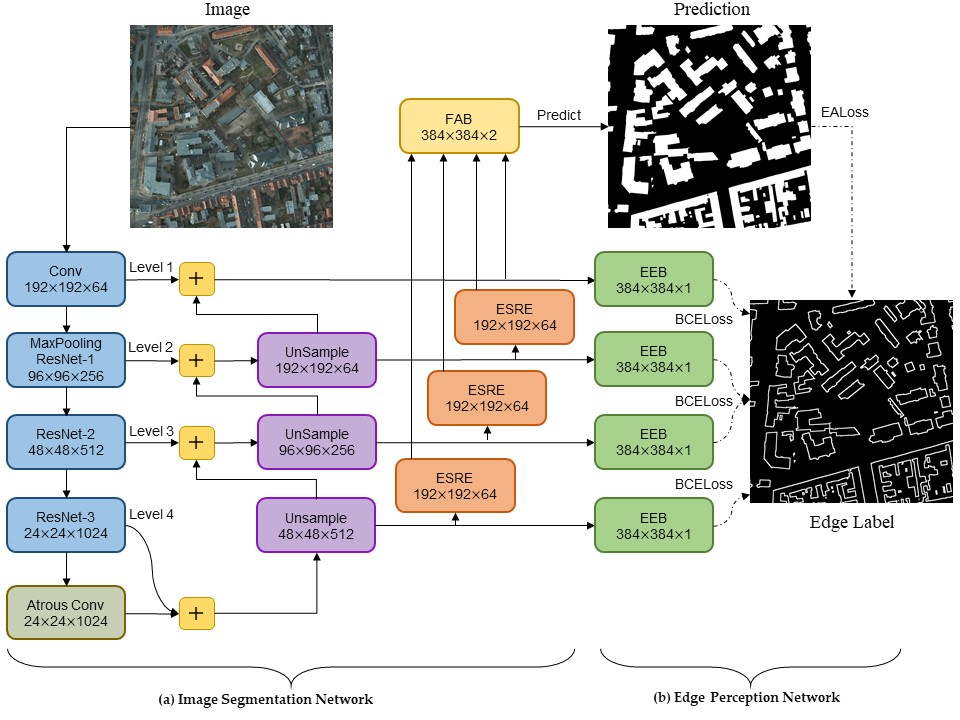
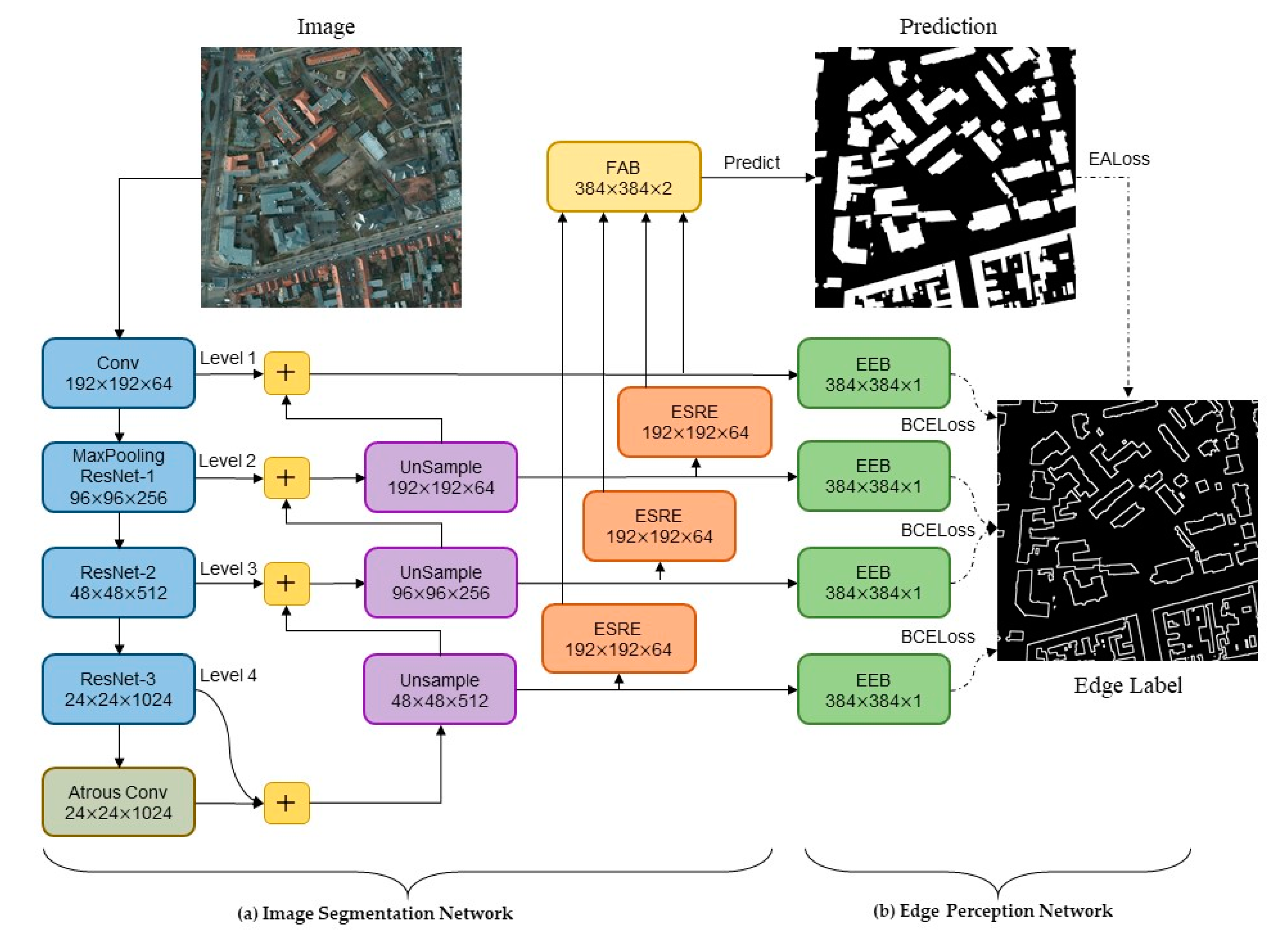
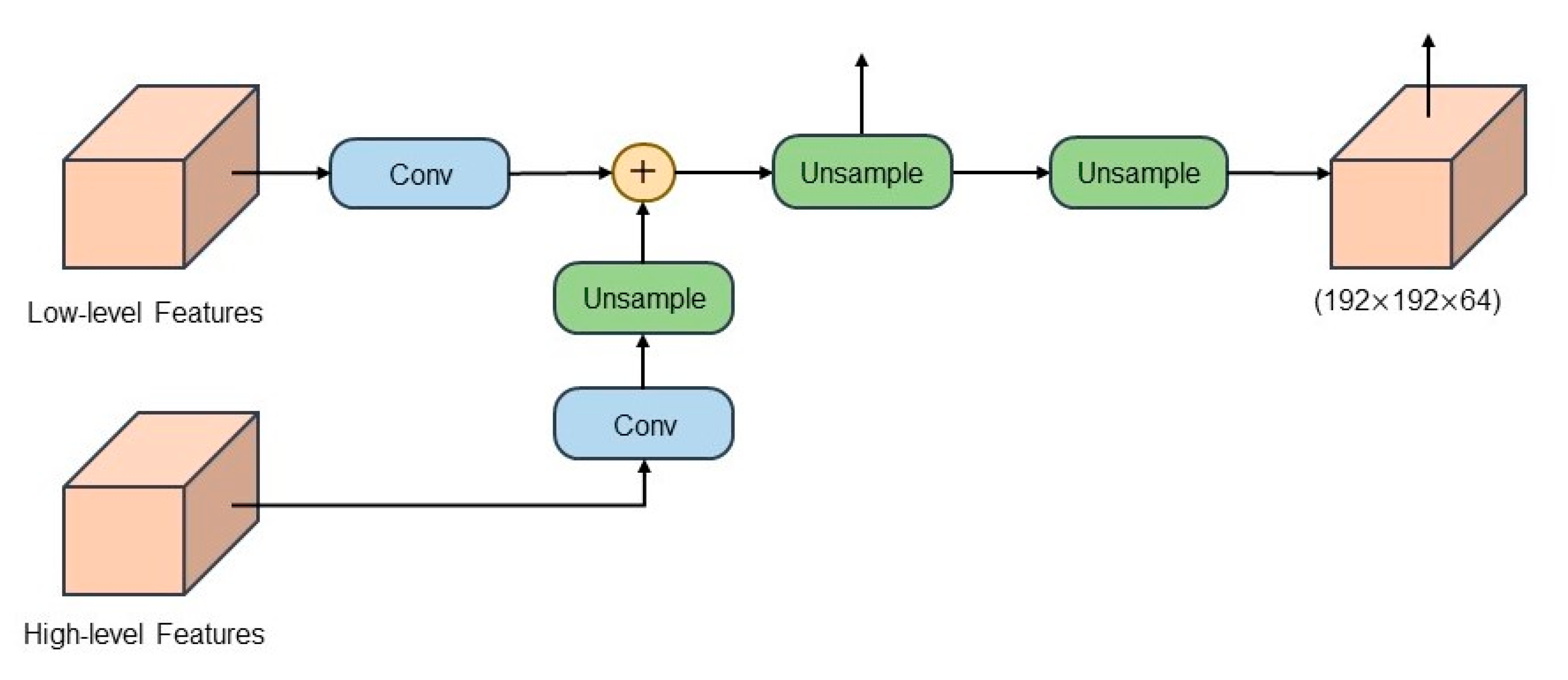
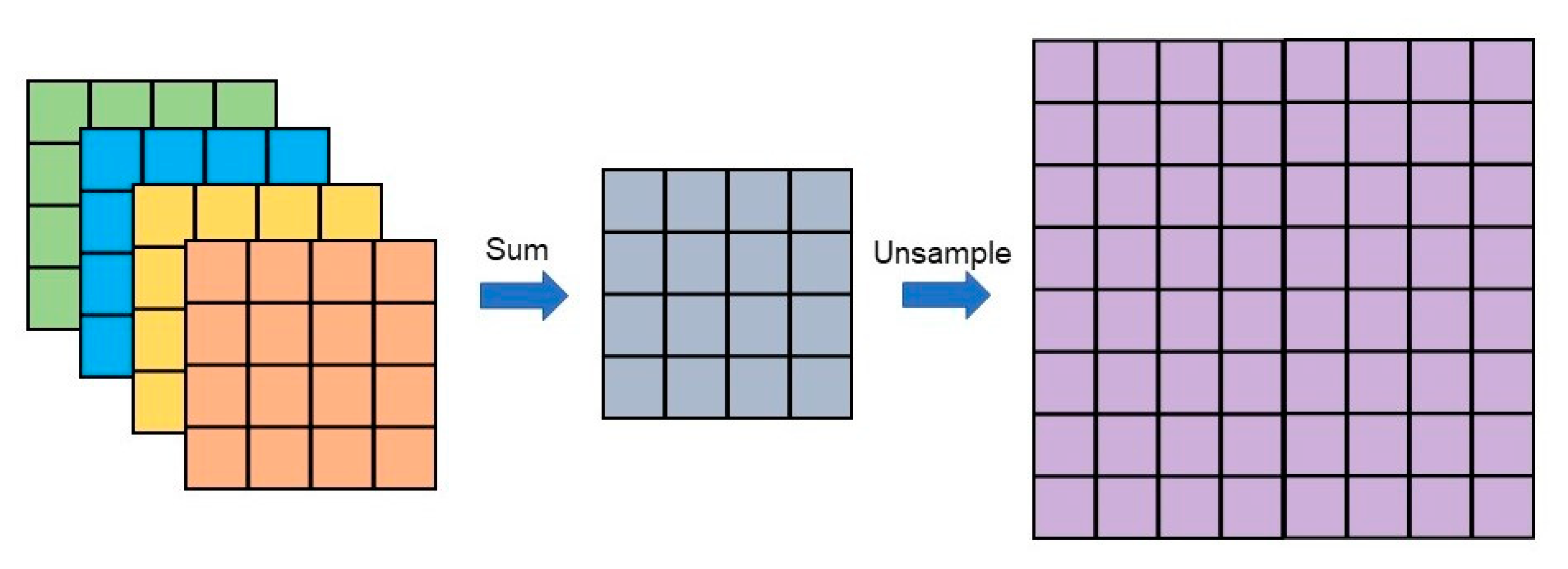
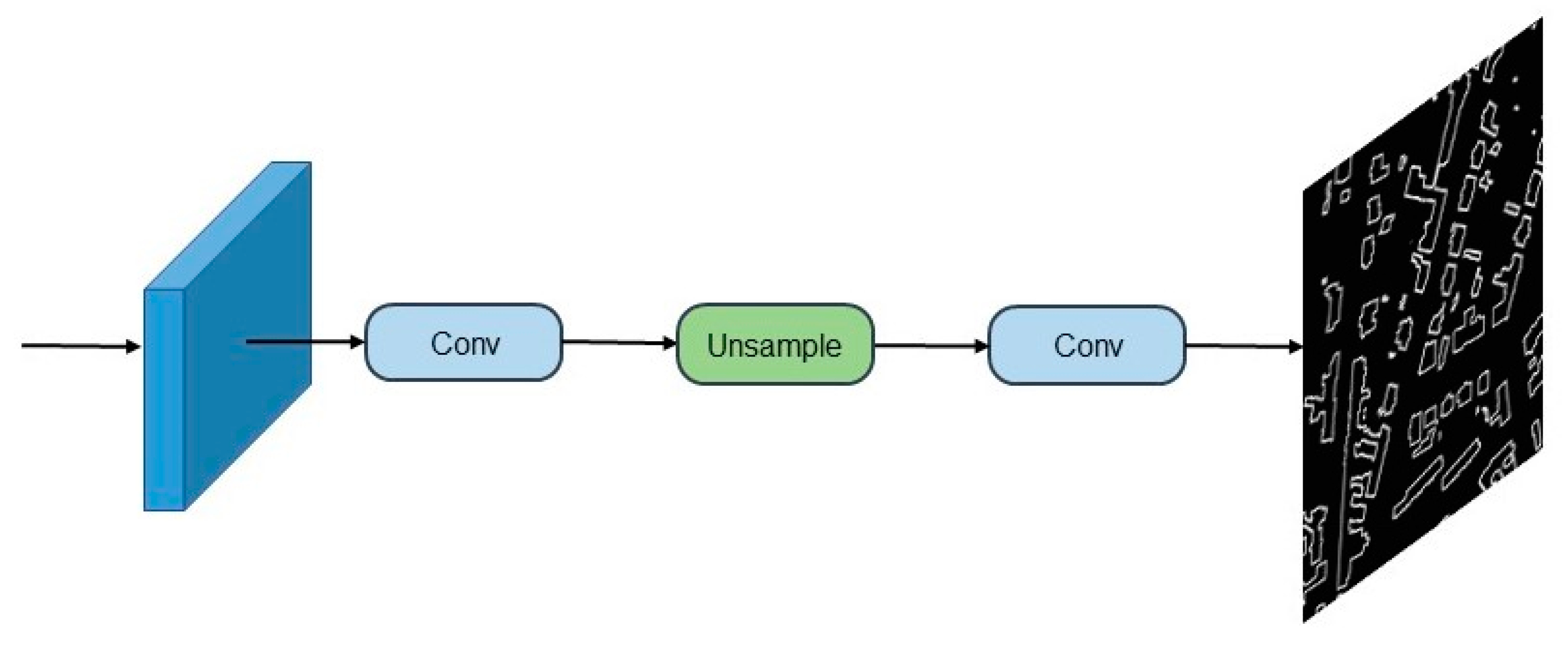
The EANet, a multi-task learning network based on the encoder–decoder structure, is proposed to automatically extract buildings from high-resolution aerial images. Our proposed network EANet was trained end-to-end through a series of loss functions. The EANet consists of an image segmentation network and an edge perception network. The former predicts the segmentation of images using remote sensing images, and the latter aims to supervise the segmentation network and further enhance the accuracy of edge prediction.
EALoss, a new loss function, is proposed to refine the prediction results of the segmentation network and was designed to supervise the learning process of accurate prediction for the binary boundary segmentation of images.
Without using additional datasets, data augmentation, and post-processing, the EANet achieves top performance on two remote sensing image semantic segmentation datasets, i.e., The International Society for Photogrammetry and Remote Sensing (ISPRS) Potsdam [
36] and Wuhan University (WHU) building datasets [
37].
The rest of this article is organized as follows.
Section 2 introduces the composition of the model in detail.
Section 3 describes the experimental dataset, model evaluation methods, experimental design, and the analysis of the experimental results.
Section 4 discusses the effectiveness of the EANet and future work.
Section 5 summarizes the paper.
5. Conclusions
This work proposed the EANet, a novel encoder–decoder edge-aware network with an edge-aware loss for accurate building extraction from remote sensing images. The EANet presents an end-to-end architecture consisting of two components: an image segmentation network and an edge perception network. The image segmentation network aims to obtain high-quality segmentation results from images. Conversely, the edge perception network guides the segmentation network toward paying more attention to edge information and restores lost low-level details as much as possible. The ISPRS Potsdam and the WHU building datasets, respectively, cover two different cities. Both datasets contain civil and industrial buildings that fully demonstrate the complexity of urban buildings. Compared with the existing eleven state-of-the-art methods, our network was found to have the best performance for the extraction of buildings according to experiments with the ISPRS Potsdam and WHU building datasets, with the proposed EANet achieving the highest F1 and IoU (97.52% and 93.33%, respectively) compared with Deeplabv3-plus (96.76% and 91.96%, respectively), PSPNet (96.69% and 91.82%, respectively), U-Net (91.35% and 88.13%, respectively), SRINet (94.23% and 89.09%, respectively), DeNet (94.80% and 90.12%, respectively) for the WHU buildings dataset. For the extraction of dense buildings, the results showed that our method performed better. Meanwhile, our network is simple and efficient, and it can not only be applied to the extraction of buildings in other cities or regions but can also be easily extended to the extraction of other ground objects of remote sensing images.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}