1. Introduction
Information about forests is collected at many spatial scales and with many different methods to deliver the information required for local, strategic and operational purposes. The forest growing stock volume (GSV) is an important variable for forest resource management. GSV provides the foundation for monitoring silvicultural treatments and changes in the forest ecosystem structure and functions. GSV can be based on data collected in the field or based on remote sensing-derived information. Ground-based National Forest Inventory (NFI) programs are usually carried out to obtain information at the strategic level. Information gathered on NFI field sample plots is subsequently used for national or regional forest management and planning, sustainability assessments or reporting to international conventions [
1]. At the national or regional scale, forest volume is most commonly estimated on the basis of NFI data [
2,
3]. However, at the local scale, remote sensing data are increasingly used to obtain information on the smallest parts of the forest, particularly forest stands [
4,
5]. At present, remotely sensed data, especially Airborne Laser Scanning (ALS) point clouds, are used in forest inventories, where they are designed to support short-term forest management decisions at the local (stand) level related to harvest planning, the assessment of GSV and the planning of silvicultural activities [
6]. GSV is one of the forest parameters with the highest interest for forest inventory activities. Detailed information about stand volume is crucial for making reasonable decisions concerning forest management. Accurate estimates of GSV are very important in the context of planning silvicultural activities and modelling forest productivity [
7]. GSV is also the most important variable in carbon budget modelling [
8].
The most common method for the estimation of GSV based on remotely sensed data is the area-based approach (ABA [
9]). In this method, different remotely sensed data—most often ALS point clouds—are used for calculating various metrics that are then used as predictors in models developed using co-located ground plot measurements. This approach requires in situ data, such as field sample plots, with accurate information about their localization [
10]. Unfortunately, precisely accurate measurements of sample plot positions require an expensive and time-consuming process because of the necessity to use, for example, advanced Global Navigation Satellite System (GNSS) receivers and perform post-processing procedures with data from the base-stations [
11]. Only permanent sample plots do not generate additional costs after their establishment. On the other hand, relaxing requirements for the positioning accuracy of field plots may reduce the costs of the forest inventory but may also decrease the accuracy of the biophysical parameter estimates [
4]. Accurate measurements of the plot coordinates and sizes of the sample plots are important factors that influence the accuracy of the forest inventory based on ALS data [
12]. To some extent, a larger plot size can compensate for inaccurate measurements of sample plot coordinates [
13,
14] but the measurement costs will increase significantly.
The use of NFI field sample plots seems to be a reasonable logical compromise for optimizing the costs of the RS data used in national scale inventories, which provide operational and strategic information about the forest. The first attempts at integrating NFI plots with Landsat images began 30 years ago in Finland [
15]. There are also other more recent positive experiences in the integration of remotely sensed data and NFI for descriptions of forest characteristics [
16], specifically using ALS point clouds [
17,
18,
19]. Hollaus et al. [
18] used NFI plots and ALS point clouds for creating GSV model based on ALS data in Austria. Nord-Larsen et al. [
19] developed models for selected forest parameters combing Danish NFI plots with ALS point clouds and the same was done for Sweden [
17]. All these studies assumed that accurate measurements of sample plot positions are required for creating GSV predictive models. However, in some countries, such as Poland, NFI plots do not offer accurate information about plot coordinates. The positions of Polish NFI plots were measured using low-class GPS receivers; thus, their positional accuracy may vary from several to about 15 m. Socha et al. [
7] proposed a method for using NFI data together with ALS point clouds even without any information about the plot coordinates. However, that method was concentrated on pure Scots pine-dominated stands and was tested in only one forest district. In this research, we aimed to evaluate Polish NFI plots as a source for the development of predictive models for GSV using ALS and Landsat data in varying types of stands located in different parts of Poland. We assessed whether the accuracy of GSV determination at the stand scale based on Polish NFI plots is sufficient for forest management purposes.
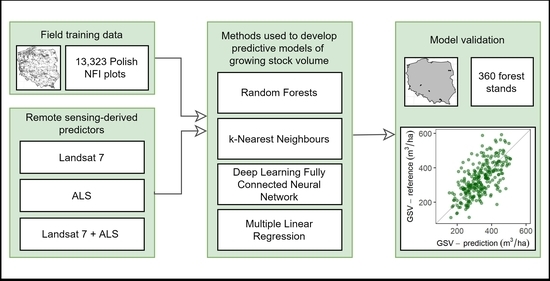
The main objectives of this study were (i) to evaluate the possibility of predicting the growing stock volume at the stand level using an area-based approach with NFI plots without accurate information about the plot coordinates; (ii) to compare the performance of different predictive approaches; (iii) to evaluate the possible differences in model performance using different types of predictor variables (e.g., Landsat, ALS, Landsat and ALS metrics); and (iv) to evaluate the model performance within stands dominated by different tree species (Scots pine, European beech, sessile oak and silver fir).
2. Materials and Methods
2.1. Study Area
Poland is located in Central Europe (
Figure 1a) and covers a total area of 312,679 km
2. According to the Central Statistical Office [
20], forest covers 29.6% of the country’s area, which corresponds to 92,420 km
2. Poor and moderately rich forest habitats predominate and cover 57% of the forested area which is reflected in the dominance of coniferous tree species, which dominate over 68% of the area of Polish forests [
21]. According to the National Forest Inventory [
22], Scots pine (
Pinus sylvestris L.) is predominant in most Polish tree stands. Among the deciduous species, oaks (
Quercus spp.), silver birch (
Betula pendula Roth.) and black alder (
Alnus glutinosa Gaertn) are the species with the largest share. In mountainous areas, the share of Norway spruce (
Picea abies Karst.), silver fir (
Abies alba Milland) and European beech (
Fagus sylvatica L.) is more significant. Forest ownership also has an impact on its management. In Poland, public forests are predominant (80.7%), with most of them under the administration of the State Forests. The age structure is mainly represented by III and IV age classes (41–60 and 61–80 years old, respectively). As reported by the National Forest Inventory at the end of 2016, the timber resources in Polish forests reached 2587 million m
3 of gross merchantable timber, out of which almost 80% is in the State Forests [
21]. The mean growing stock volume of Polish forests is 269 m
3/ha, which is much higher than the average in European forests (163 m
3/ha) [
23].
2.2. Polish National Forest Inventory Data
The National Forest Inventory started in Poland in 2005. This system uses a systematic scheme within a 4 km square grid of permanent sample plots. The 4 km grid is based on the pan-European 16 × 16 km forest monitoring network of the International Co-operative Programme on the Assessment and Monitoring of Air Pollution Effects on Forests [
24]. Measurements of the NFI plots are performed in a 5-year inventory cycle measuring approximately 20% of the plots each year. In the first two cycles of the NFI, the sample plots were circular with 7.98 m (200 m
2), 11.28 m (400 m
2) and 12.62 m (500 m
2) radii depending on the forest stand age. In the last recent cycle (2015–2019), a radius of 11.28 m (400 m
2) was used for all plots. At each NFI sample plot, many tree and stand characteristics were measured. The diameter at breast height (DBH) was measured for all trees with a DBH ≥ 7 cm. The heights of the selected trees were measured to estimate the height curve. To obtain the GSV for a sample plot, first, the allometric models are used to predict individual tree volumes. Then, after aggregation from single trees, the plot-level GSV is calculated [
25,
26]. In this research, measurements from the second cycle of the NFI (2010–2014) were used since these measurements guaranteed the smallest difference between the time of the field measurements and the time of the ALS point cloud acquisition. For the analysis, 13,323 NFI sample plots were used, where the full area of the sample plot was located within the borders of a single forest stand and for which the ALS point clouds were available. The basic characteristics of the GSV at the plot level are presented in
Table 1. The species share at the plot level was calculated using the volume of single trees.
2.3. Landsat Images
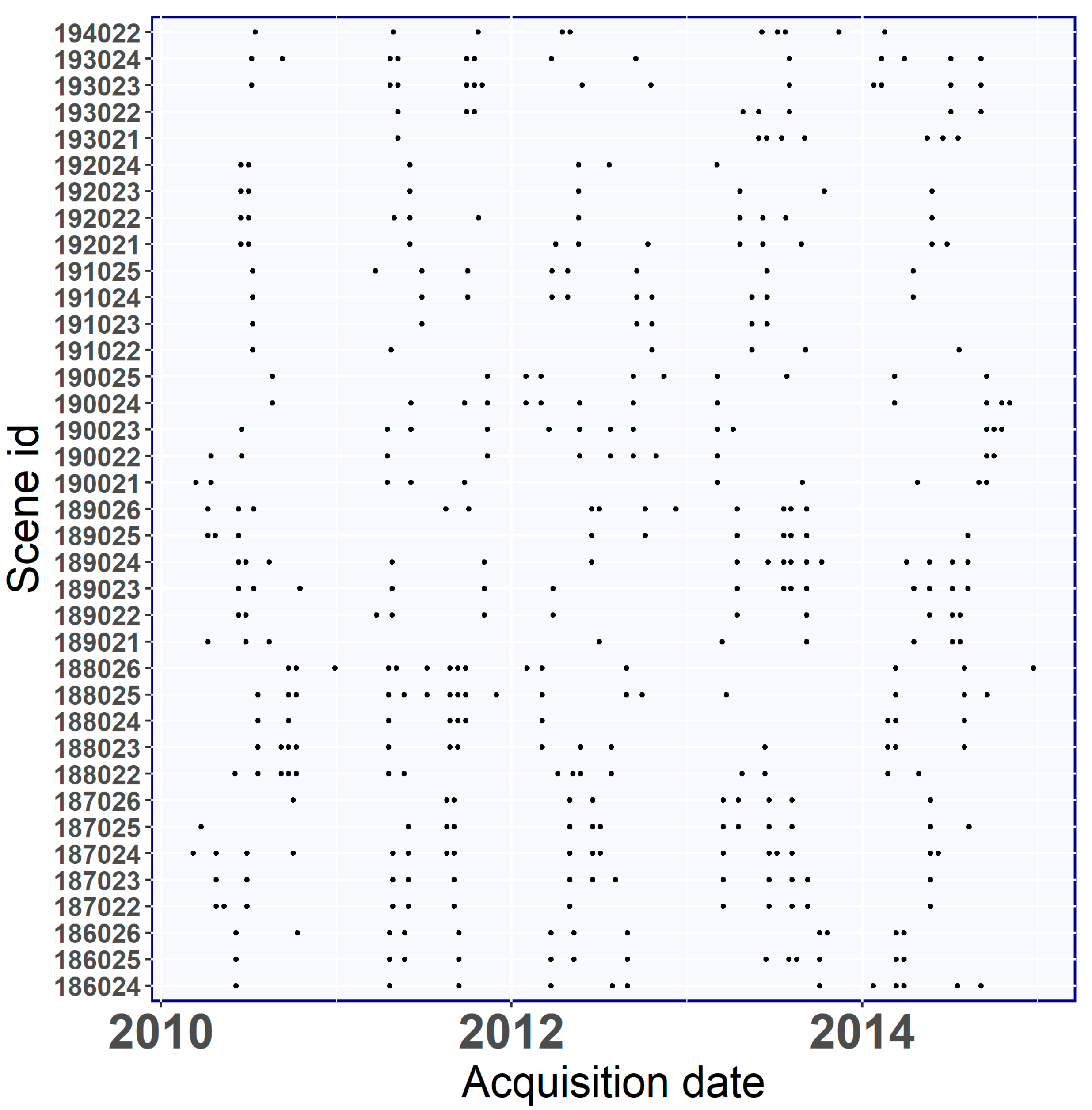
After considering the possibility of using other forms of optical satellite imagery, we chose the imagery of Landsat 7 ETM+ to cover the study area because the scenes are freely available at a moderate resolution (30 × 30 m) compared to other types of satellite data that require a fee (e.g., Quickbirds and Ikonos) or are not available for the years of interest (e.g., Sentinel-2). In total, Poland is covered by 37 Landsat scenes (
Figure 2), so we used the Google Earth Engine Platform (GEE) to obtain a cloud-free composite image. GEE provides a full repository of Landsat data and offers the possibility to select and process images with a specific threshold of cloud cover and a specific time range, as well as quickly obtain free cloud composite images that are produced combining different images of the same scenes [
27]. Based on the cloud cover thresholds (i.e., less than 10%), the solar zenith angle (i.e., less than 76°) and the specific acquisition period (i.e., 1 January 2010−31 December 2014), we found that 420 images were available for all of Poland’s area, with an average of 11 images for each Landsat scene (
Figure 2). Among the 420 images selected, 24 were acquired between November and February.
For all the selected images, we used the bottom of the atmosphere reflectance values (BOA) calculated using the LEDAPS (Landsat ecosystem disturbance adaptive processing system) algorithm [
28]. The images were subsequently masked for clouds using the Fmask (Function of the mask) algorithm [
29]. Based on the processed images for reflectance and cloud masking, using GEE, we produced a cloud-free composite image for the whole of Poland. The spectral value of each pixel of the composite image was calculated as the
‘median’ of all Landsat images available for the specific pixel. More details on GEE and composite images can be found in Gorelick et al. [
27].
2.4. Airborne Laser Scanning Point Clouds
The primary dataset for develo** the GSV models in this research consisted of ALS point clouds acquired during the country-wide projects aimed mainly at creating a detail Digital Terrain Model for the whole of Poland. In the years 2011–2015, the Main Office of Geodesy and Cartography in Poland commissioned the development of altitude data using ALS technology for an area encompassing 92% of the country—i.e., 288,806 km
2 of Poland. In the following years (2015–2017), data collection for other areas of the country continued. ALS data were obtained in two standards: Standard I (mainly forest and rural areas outside cities), where the point density is at least four pulses per square meter (ppsm) and Standard II (94 cities in most without forests), with a density of at least 12 ppsm. The acquisition of ALS point clouds took place from mid-October to April, that is, in the leaf-off period, which at the transverse scan angle (allowed up to 25 degrees) guaranteed good penetration of the laser beams through the stand hood to the ground. Since the second cycle of the NFI (2010–2014) took place at nearly the same time as ALS data acquisition with the ISOK project (2011–2015), the absolute time difference between the two datasets was, in most cases (90.4%), less than three years (
Table 2).
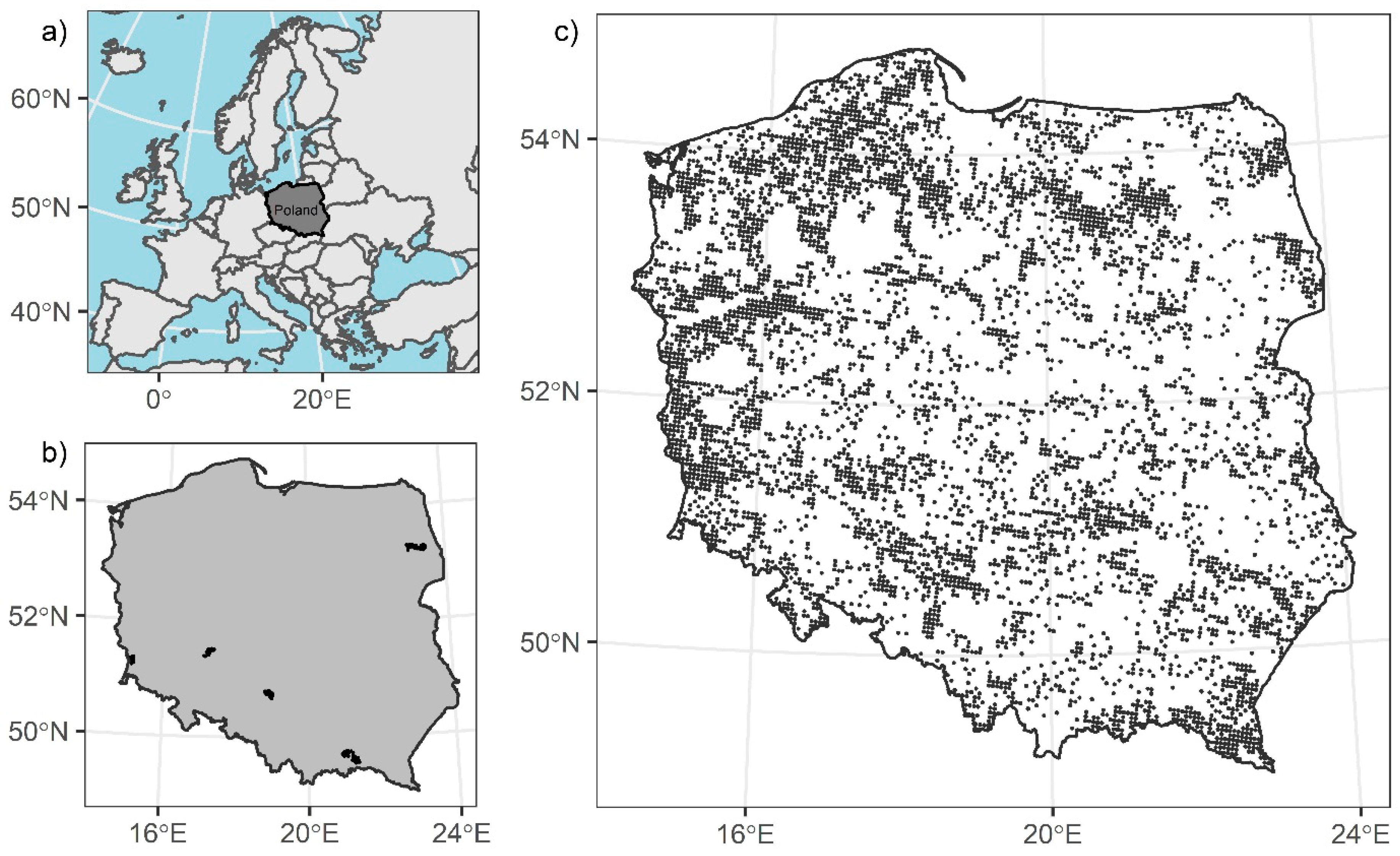
The second set of ALS data used in this study included point clouds obtained in 2015 and 2016 for the REMBIOFOR project. These data were used for validation of the developed predictive models on the validation stands. The data acquisition area included 6 forest districts where the reference forest stands were established (
Figure 1b). Every single validation stand was scanned with the Riegl LiteMapper LMSQ680i laser scanning system. The scanner’s operating frequencies were in the range of 300 to 400 kHz. The aircraft was flying at around 550 m above the mean ground level altitude, maintaining 30% tile-side overlap with a 60° FOV. The above mission parameters enabled the acquisition of spatially homogeneous multi-echo point clouds with average densities in the range from 10 to 14 ppsm.
2.5. Extraction of Predictor Variables
Two different sets of predictor variables were extracted from the remote sensing data associated with each NFI plot and each stand: optical metrics from Landsat cloud-free composites and ALS normalized point cloud-derived metrics.
In particular, we extracted the median value of each band of the Landsat 7 ETM+ composite image from the pixels associated with the area of each NFI plot and each reference forest stand. Based on the normalized ALS point clouds, the sets of metrics were calculated using the lidR package for R (
Table 3 [
30]).
2.6. Validation Data
The 360 forest stands located in 6 forest districts across Poland with a mean area of 1.1 ha were used as validation data (
Figure 1b;
Table 4). Field measurements were conducted in summer and autumn 2015 (four districts) and 2016 (two districts). In each stand, only trees with a DBH of at least 7 cm were measured. Moreover, in each stand, several heights for a dominant tree species were measured (minimum 20 trees). The measured trees were distributed evenly across the DBH range and forest stand layers. Height measurements were made using a Haglof Vertex IV ultrasonic hypsometer. Then, the volume for single trees was calculated using the allometric models created for Poland [
25]. To calculate the GSV, the volumes of individual trees in the stand were summed and divided by the stand area. The ALS-derived metrics listed in
Table 3 were calculated for each forest stand within a 30 × 30 m raster grid corresponding to the Landsat pixel size. The predicted GSV for each stand was calculated using GEE as the weighted mean from the raster cells overlap** with the stand borders. The overlap** area was used as the weight. See the GEE documentation for more in-depth information (
https://developers.google.com/earth-engine/reducers_reduce_region#pixels-in-the-region).
2.7. Predictive Methods
We evaluated four methods for predicting GSV: three nonparametric approaches—Random Forest (RF), k-Nearest Neighbours (k-NN) and deep learning neural network (DL)—and one parametric approach—the multiple linear regression (LM) model.
The training set for develo** the predictive models consisted of the GSV values measured in the field at the National Forest inventory plots (
n = 13,323), while the validation set consisted of 360 stands with a mean area of 1.1 ha, ranging between 0.44 ha and 3.78 ha. For both the training set and validation set, the predictor variables consist of (i) Landsat metrics and (ii) ALS metrics (
Table 3).
The predictive approaches were tested using three different sets of predictor variables (i.e., Landsat; ALS; and combined Landsat and ALS metrics) to compare the performance of each predictive approach using different types of predictors. Therefore, each imputation-predictive approach was optimized three times using the three different sets of predictors. In the following paragraphs, we detail how the predictive models were parametrized.
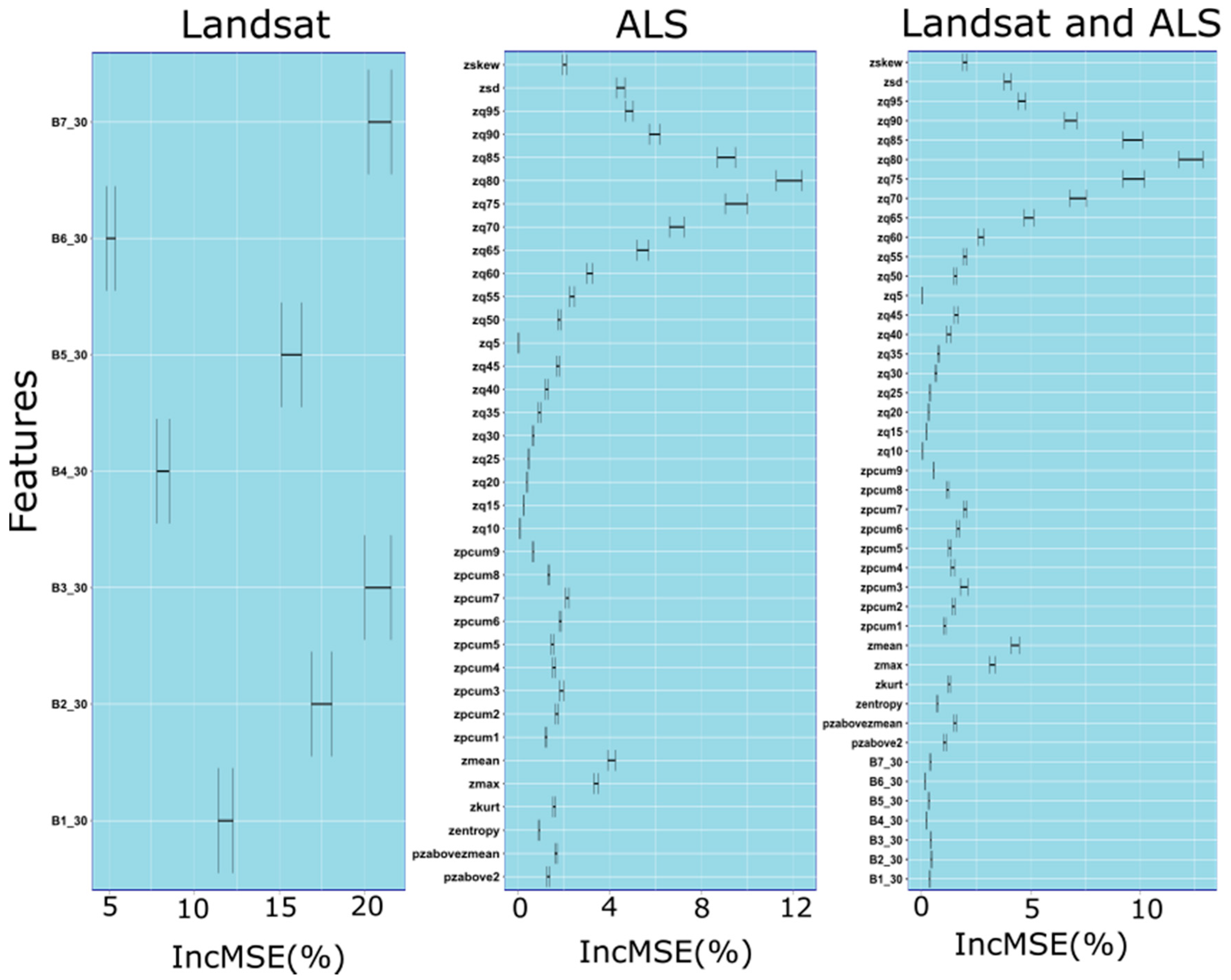
For each set of predictors (i.e., Landsat, ALS and Landsat+ALS), we calculated the variables’ importance rankings using Random Forests and calculating the percentage increase in the mean square error (IncMSE%) by removing all variables one at a time. We calculated the IncMSE% through a 5-fold-cross-validation procedure that associates the relative standard error (MSE) to each variable.
Among the 7 Landsat predictors, the 41 ALS predictors and the 48 predictors for both Landsat and ALS, we identified the relevant and irrelevant predictors by iteratively removing the variables that were identified as less important [
32]. At the end of each 5-fold cross-validation, we selected the set of predictor variables that had the lowest Mean Squared Error (MSE). Therefore, we selected a set of predictor variables for Landsat, a set of predictor variables for ALS and a set of predictor variables combining the Landsat and ALS variables. Then, the three sets of predictors were used to optimize the four predictive approaches.
Each predictive approach (i.e., Random Forest, k-NN, Neural Network and Multiple Linear Regression) was optimized three times using the three sets of predictor variables selected with the procedure described above. In this section, we will describe the different predictive approaches used.
2.7.1. Random Forests
RF is a decision tree algorithm introduced by Breiman [
33]. It is commonly used for the spatial prediction of forest variables using remotely sensed data [
34,
35,
36,
37,
38]. RF grows a set of regression trees (
ntree) with a certain depth (
tdepth), using a randomly chosen subset of predictors for each one (
mtry). To build trees, the out-of-bag samples (
OOB) procedure is applied, where each tree is built independently based on bootstrap samples from the training dataset, while the remaining one-third of the samples are randomly left out. More details on the RF method can be found in the review of Belgiu and Drăgu [
39] and in the article of Li et al. [
32].
The hyperparameter optimization was performed using a random search tuning approach, through which we tested 50 randomly extracted combinations of
ntree,
mtry and tdepth (
Table 5), searching for the combination that minimizes the Root Mean Square Error:
where
and
denote the reference and predicted values, respectively, for the
i-th
sample plot and
n is the number of plots.
The was evaluated using k-fold cross-validation. For each hyperparameter combination, we randomly divided the NFI plots into 5 reference set units and each one was deleted in sequence and predicted using the remaining plots. Thus, each sample plot was never used for both training and testing.
2.7.2. k-Nearest Neighbours
The k-NN imputation approach is well known method often used for develo** predictive models in context of applications of remote sensing data in forestry [
40]. With the k-Nearest Neighbours (k-NN) technique, predictions are calculated as linear combinations of observations for sample units that are the nearest to the population units for which the predictions are desired with respect to a selected distance metric in the space of the feature (auxiliary) variables. The optimization of k-NN parameters was performed using the same procedure used for RF but optimizing
k (the number of nearest neighbours), the
Minkowski distance parameter (among Euclidean or Manhattan distance) and the
distance metric. A full list of the tested hyperparameters is provided in
Table 5.
2.7.3. Deep Learning Fully Connected Neural Network
The Deep Learning model (DL) consists of N stacked layers composed of M nodes that facilitate learning through successive representations of the input data [
41]. The DL model that we used was a Fully Connected Neural Network (FCNN), in which all nodes or neurons, in one layer are connected to the nodes in the next layer. The data are transformed in each layer using weights, which are specific parameters that link the nodes of subsequent layers [
42]. During training, the optimum value of the weight of each node was optimized based on the loss function, which measures the difference between the observed and predicted values. In this study, modelling was done using the TensorFlow backend.
DL models require several hyperparameters to be set: (i) the number of hidden layers, (ii) the number of nodes, (iii) the optimizer and relative Learning Rate, (iv) the number of dropout layers, (v) the percentage of dropped out units in each layer, (vi) the different activation function configurations, (vii) the different values of lambda for L1 and L2 regularization strategies, (viii) the number of epochs and (ix) the activation function.
These hyperparameters are too numerous to use the same automatic random search optimization procedure used for k-NN and RF. Therefore, we used a trial-and-error approach, which, compared to random search, is more time consuming and requires more in-depth knowledge of the model and the effects of the hyperparameters.
As for RF and k-NN, we chose the best model configuration by minimizing the RMSE resulting from the 5-fold-cross validation procedure.
2.7.4. Multiple Linear Regression
Multiple linear regression (LM) method can be defined in the form of
where
i indexes the sample units,
represents the single response variable,
p ≥ 1 denotes the number of explanatory variables,
j = {1, …,
p} indexes the explanatory variables,
j is the respective regression coefficient and
denotes a random residual term with the distribution of
. LM does not have hyperparameters and does not require an optimization phase. However, we calculated the performance of LM with the same 5-fold-cross validation procedure used for RF, k-NN and DL.
2.8. Models Training and Validation
As a result of the previous processes, we identified the model configurations that ensure the best performance in terms of the RMSE. Then, we ultimately trained the k-NN, RF, DL and LM models with the identified configuration using all 13,323 NFI plots. We tested the best twelve models (i.e., the four predictive approaches using the three different sets of predictors) using a bootstrap** approach based on the reference stands (n = 360) to evaluate the performance using an independent dataset (never-seen-before data).
Resampling methods such as the bootstrap resampling technique can be applied to assess uncertainty for predictive approaches such as parametric and nonparametric approaches [
43,
44]. Bootstrap** is based on the notion of a bootstrap sample and the bootstrap** pair approach was used to construct bootstrap samples for this study [
45]. We created 100,000 bootstrap samples (nboot = 100,000) that were considered to be consistent [
43,
45]. Each sample consisted of a sample drawn with a replacement from the original reference set with the same dimension of the original stand dataset (
n = 360).
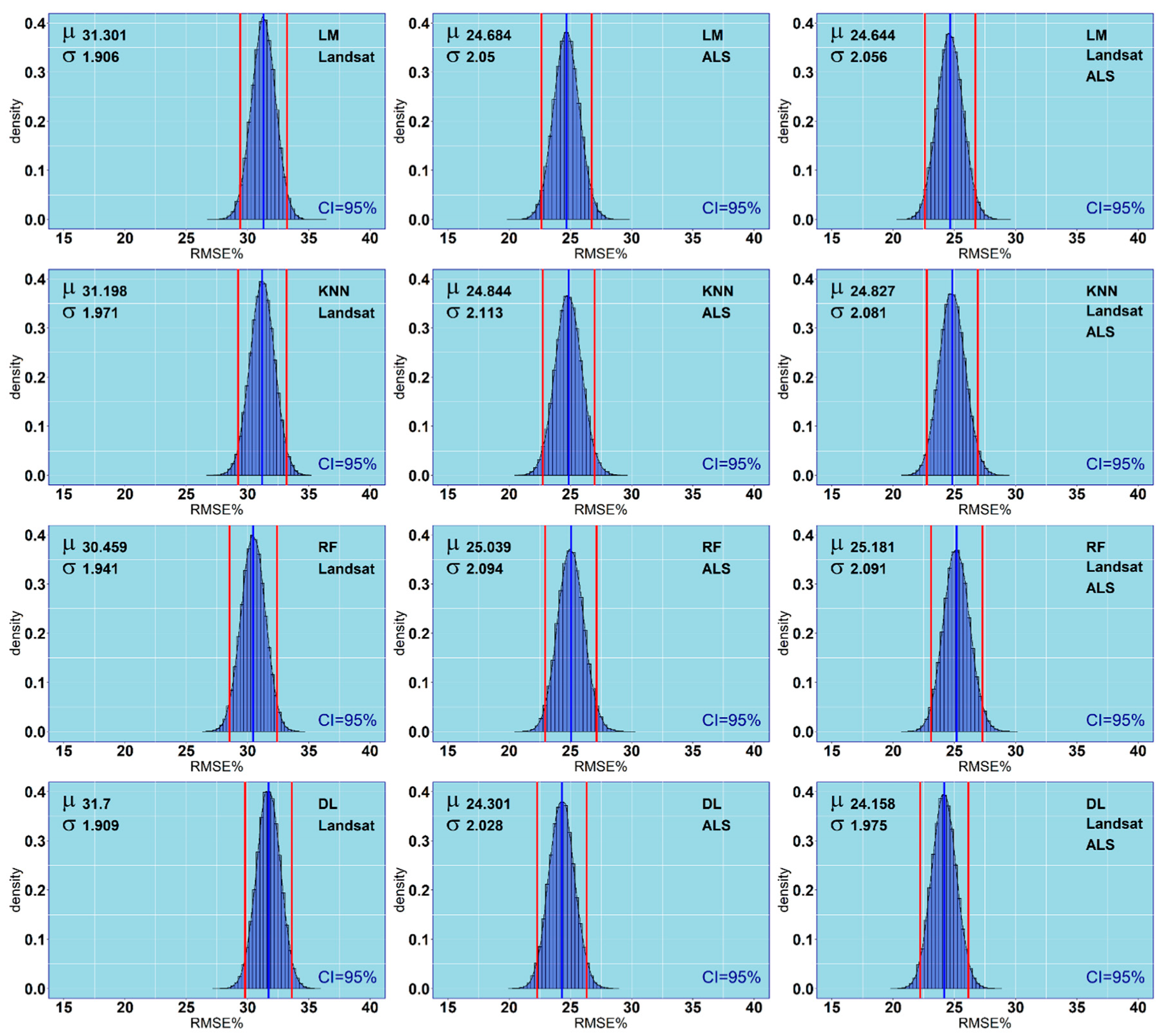
Based on each 100,000 bootstrap sample, we applied the models and calculated the RMSE as done in the optimization phase (Equation (1)). In this case, the n value was equal to the number of stands (n = 360). Moreover, we calculated the relative RMSE% as the percentage of the average ground reference value of the bootstrap samples.
For each model, at the end of the bootstrap** procedure, we calculated the mean
RMSE (
μ) and the RMSE% (
μ%) as the mean of the RMSE. The mean of the RMSE% achieved for each bootstrap sample was calculated as
where
and
are the results achieved for the
i-th bootstrap sample and
b is the number of bootstrap samples; in our case,
b = 100,000. Using the same procedure, we calculated the R
2, the bias and the relative bias for the bootstrap samples.
Moreover, we calculated confidence intervals of 95% for each parameter of performance as
where
is the significant value,
is the
percentile of Student’s t-distribution (in our case 1.96) and
is the standard deviation.
Additionally, the were calculated and analysed for the dominant tree species with at least 20 validation stands available.
4. Discussion
In this article, four predictive approaches (LM, KNN, RF and DL) trained based on NFI plots combined with ALS point clouds and Landsat images were evaluated for predicting GSV at the stand level. Three sets of predictor variables were tested (ALS, Landsat and Landsat+ALS) for all methods. Validation of the developed models was performed on 360 forest stands measured in the field.
When creating the Landsat mosaic, we did not divide the Landsat images into leaf-on (396 images) and leaf-off (24 images) datasets. Although we are aware that mixing leaf-on and leaf-off images is not a perfect approach, we assumed that since the final reflectance value was calculated as the median, the rare leaf-off images would not affect the final image consistently. On the other hand, rare high quality leaf-off images (cloud cover < 10% and solar zenith angle smaller than 76°) selected in winter can be informative for evergreen trees and areas when there are no images acquired during the leaf-on season, which may occur when algorithms are applied over huge areas.
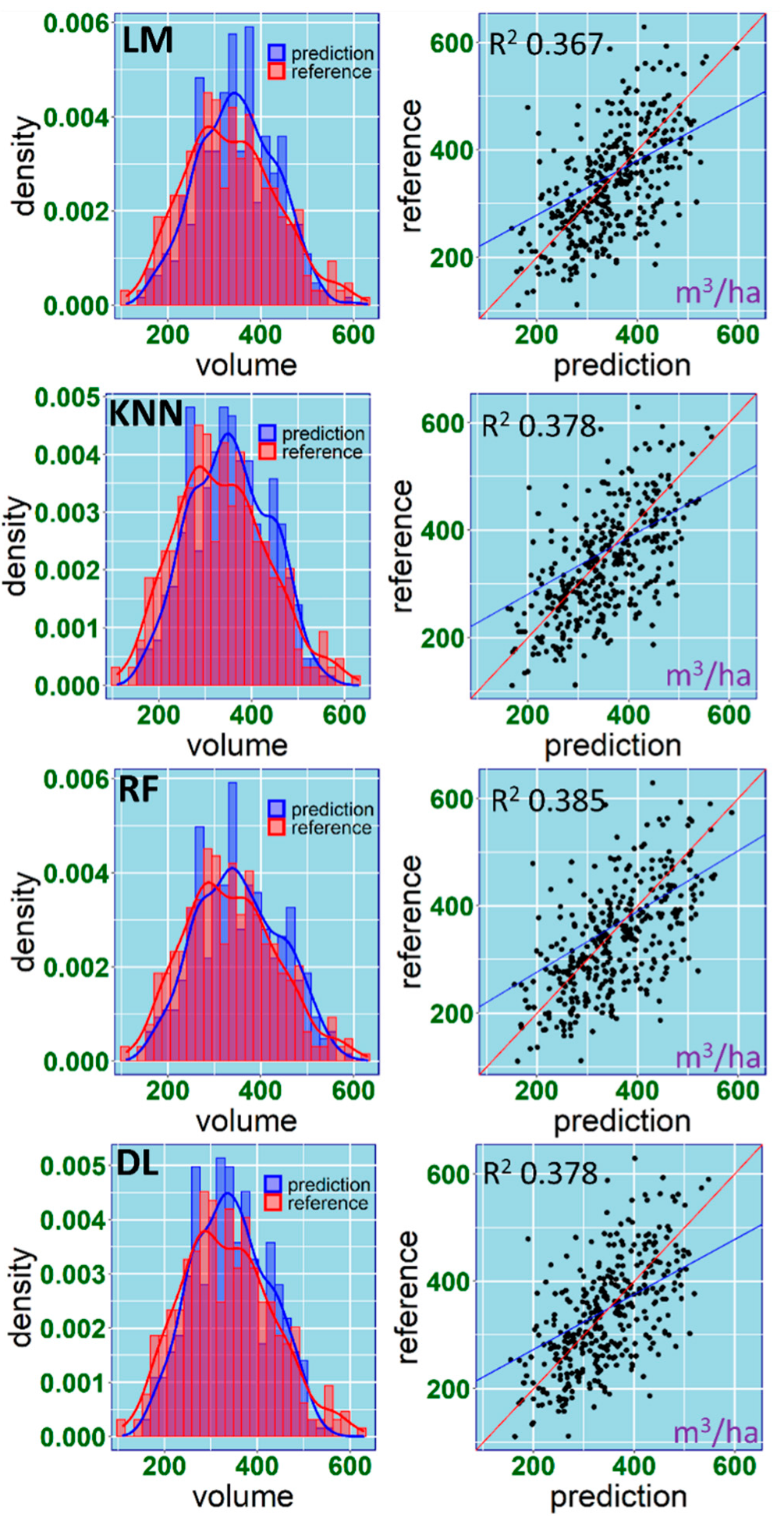
The obtained results showed that there are no considerable differences in accuracy between the evaluated predictive approaches (
Table 7,
Figure 4 and
Figure 5). Generally, the DL method provided the lowest RMSE and bias; however, the differences between models were minimal. Larger differences between the predictive models were observed when validating within groups of dominant tree species. The results show that multiple linear regression (LM) can provide satisfactory results but there are no or only small, benefits from using more advanced methods, including machine learning (KNN and RF) or deep learning (DL). The linear model was used by Nilsson et al. [
17] for country-level forest variables estimation in Sweden. The RMSE of 24.69% obtained in our study (LM) regardless of tress species is larger than that obtained by Nilsson et al. ([
17]; RMSE: 17.2%–22.0%); however, this might be related to the higher species and structural variability of Polish forests. Parametric and nonparametric methods each have their own pros and cons. Previous works [
9,
48] pointed to the undoubted advantage of classic multiple linear regression, highlighting the ease of interpreting the model. The advantage of LM is also its ability to extrapolate extreme values. The construction of such models, however, requires more experience and more work for the selection of appropriate predictors. This problem disappears with the nonparametric methods of KNN, RF and DL used in this paper. These models can also provide good performance in the case of non-linear relationships between variables. However, the possibility of more frequent model overfitting and poor results in the case of overly small observation sets are potential disadvantages of these approaches [
49,
50].
The obtained results showed differences in the performance of the developed predictive models between dominant tree species. Nilsson et al. [
17] reported for Sweden that when the proportion of broadleaved trees increased to 76%, the RMSE% of the GSV estimation increased to 27.9%. For our study, a similar relationship was observed. The model performance was relatively good for pine and fir, moderate for oak and the worst for beech. However, the obtained differences in RMSE% for coniferous and broadleaved stands were not so obvious. For example, the RMSE% for oak-dominated stands was even lower than that for pine-dominated stands. We observed that the systemic error (bias) is higher for stands dominated by broadleaved trees. In the case of beech-dominated stands, the relative bias increased to more than −20%, meaning that the developed models are not appropriate for these kinds of stands. It can be expected that creating species-specific models will improve the accuracy and reduce model bias [
19]. However, the large overestimation of GSV for broadleaved stands is likely the result of using the ALS point clouds of different characteristics for model validation, and for model development. In cases when the ALS point clouds are collected with different pulse densities and at different times throughout the year, the ALS metrics obtained for broadleaved trees might not be comparable between two acquisitions. Our results suggest that such an approach can be acceptable for the prediction of GSV in coniferous forests but not in areas dominated by broadleaved species. To deal with this issue, predictive models for broadleaved trees could be developed based on metrics derived from the Canopy Height Model instead of using the point cloud-derived metrics.
In our research, we tested a deep learning method as a fully connected neural network using the same predictor variables applied in the other three predictive methods. When validating the results regardless of the dominant tree species, the best model accuracy among all tested predictive approaches and sets of predictor variables was obtained with the DL utilizing Landsat+ALS variables (RMSE% = 24.2; bias% = −2.2%) but this performance was only slightly better than that of the other tested methods. However, to derive reliable conclusions about the performance of DL for GSV predictions, different neural network architecture types must be evaluated, including the Convolutional Neural Network (CNN). Deep learning with CNN architecture—especially 3D CNN—can interpret raw data (e.g., ALS point clouds) without the need for human-derived explanatory variables such as height percentiles or density metrics, which are usually used as predictor variables in other imputation-predictive methods [
51,
52]. Ayrey et al. [
51] showed that 3D CNN can considerably outperform the random forest method in predicting forest parameters based on ALS and satellite data.
In similar studies on using NFI plots and ALS point clouds for GSV estimation [
17,
18,
19], the detailed selection of training plots and high accuracy measurements of the plot centres were used, while in our study, accurate coordinates of the plot centres were not available. This is likely the main reason for the relatively low R
2 values that we obtained. Nevertheless, our study shows that for coniferous species (Scots pine and silver fir), relatively low RMSE% (22%–23%) and bias% (1%) can be obtained for stand-level GSV predictions when combining ALS point clouds and Landsat images with NFI data, even when the positional errors of the field plots vary from several to about 15 m. It can be assumed that collecting accurate information about the plot centre coordinates in the next cycles of the Polish NFI may increase the accuracy of the predictive models of GSV. However, McRoberts et al. [
53] observed only a small decrease in the standard error of the mean aboveground biomass in ALS-assisted estimates of aboveground biomass when using survey-grade GPS receivers with sub-meter accuracy compared to field grade GPS receivers with a 5–10 m accuracy. The aforementioned authors concluded that the high costs of acquiring a survey-grade GPS receiver are not justified in the case of ALS-assisted estimates of aboveground biomass at the national scale level in the USA.
Notably, in our study, for some of the NFI plots, there was up to a 5-year difference between the year of laser scanning and the year of the field survey. This difference may provide additional noise in the data used for training the predictive models because of tree growth, thinning activities, clear cutting or the occurrence of forest disturbances. As we are aware of these limitations, we assumed that the influence of these imperfections (positional inaccuracy and time lag) in the NFI data might be mitigated by using many training plots (13,323) through averaging the model parameters. We also maintain that a few-year difference between field measurements on NFI plots and the available ALS point clouds (or image-derived point clouds) may often be the case in real-world applications. Thus, we decided to use all NFI plots for which ALS data were available. The influence of time lag on the accuracy of GSV predictive models should be analysed in future studies.
When considering the forest management inventory at a local scale, an absolute bias of about 0%–3% (like that obtained for coniferous tree species) can be acceptable. However, this level of systematic error might be problematic for large areas of ALS-assisted estimates with GSV. The obtained bias might partially be the result of the abovementioned inaccuracies in the NFI data but it might also be the result of resolution difference between the differently sized training field plots (200 m
2, 400 m
2 and 500 m
2) and grids used for the model predictions (30 × 30 m; 900 m
2). Nevertheless, we decided to use a 30 × 30 m resolution grid for prediction to avoid resampling and average the Landsat-derived predictors. Packalen et al. [
54] reported that a resolution mismatch between the field plot size and grid cell size used for predictions caused only a small increase of bias in ABA. The authors indicated that a higher prediction resolution compared to training resolution caused an underestimation of AGB. However, in our study, overestimation of GSV was observed in most cases, even though the prediction grid was larger than the training sample size.
Future research should evaluate how the time lag between NFI and ALS data influences the predictions of growing stock volume at the national level. It would also be valuable to evaluate more complex DL models based on raw ALS point cloud data including convolutional layers. On the other hand, simpler multiple regression models based on Canopy Height Models may be potentially more transferable compared to point cloud-based models, especially for stands dominated by broadleaved trees. The use of predictors from Sentinel-2 + ALS instead of Landsat+ALS also seems worth exploring.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}