In this section, we outline quantitative and qualitative evaluations conducted of EAAU-Net on SIRST datasets.
Section 4.1 describes our evaluation criteria. The details of the experimental implementation are detailed in
Section 4.2.
Section 4.3 compares the proposed approach with state-of-the-art methods. The detailed ablation study conducted to verify the efficacy of the components of our proposed network architecture is presented in
Section 4.4.
Section 4.5 analyses the evaluation results.
4.1. Evaluation Metrics
The signal-to-noise ratio gain (SCRG), background suppression factor (BSF), and receiver operating characteristic (ROC) curve are commonly used as performance metrics for infrared small target detectors. However, we do not consider SCRG and BSF to be suitable in terms of detection performance, as BSF only focuses on the global standard deviation, and SCRG is infinite in most cases. Instead, we use five other metrics—IoU, nIoU, PR curve, ROC curve, and F-area—to further evaluate infrared small target detection methods in the present work. In the formulas below, N is the total number of samples, TP, FP, TN, FN, T, and P denote true positive, false positive, true negative, false negative, true, and positive, respectively.
- (1)
Intersection-over-union (IoU). IoU is a pixel-level evaluation metric that evaluates the contour description capability of the algorithm. It is calculated as the ratio of the intersection and union regions between predictions and labels, as follows:
- (2)
Normalised IoU (nIoU). To avoid the impact of the network segmentation of large targets on the evaluation metrics and to better measure the performance of network segmentation of infrared small targets, nIoU is specifically designed for infrared small target detection. It is defined as follows:
- (3)
PR curve: Precision is used as the vertical axis and recall as the horizontal axis. The closer the curve is to the top right, the better the performance when using the PR curve to show the trade-off between precision and recall for the classifier:
- (4)
Receiver operating characteristic: The ROC is used to describe the changing relationship between the true positive rate (
TPR) and the false positive rate (
FPR). They are defined as:
- (5)
New metric: F-area. F-measure is a precision- and recall-weighted summed average to measure the performance of the harmony. When operating with a fixed threshold, these methods do not sufficiently improve the average accuracy, which is valuable for practical applications. F-area considers both F-measure and average accuracy, taking into account the harmony and potential performance aspects of any technique. It is expressed as given below, where
.
4.2. Implementation Details
Datasets. Our proposed EAAU-Net was evaluated on the SIRST datasets, which comprise 427 images and 480 instances with high-quality image annotations [
19]. Approximately 55% of these targets occupy only 0.02% of the image area, i.e., only 3 × 3 pixels of the target in a 300 × 300-pixel image.
Figure 1 shows some representative and challenging images, from which it may be observed that many targets are very dim, submerged in a complex and cluttered background. In addition, only 35% of the targets in the dataset contain the brightest pixels in the image. In our experiments, we divided the dataset in a 5:2:3 ratio to form a training set, a validation set, and a testing set.
Implementation details. We conducted all CNN- based experiments on the PyTorch platform using a single TITAN RTX GPU, CUDA 10.1, and cuDNN v7. All methods based on traditional manual design were implemented in MATLAB. EAAU-Net was trained using an AdaGrad [
52] optimiser, and we set the initial learning rate to 0.05, the batch size to 8, and the weight decay to 1 × 10
−4. The input images were randomly cropped to 480 × 480 pixels, and the network was trained for a total of 300 epochs.
4.3. Comparison to State-of-the-Art Methods
To demonstrate the superiority of EAAU-Net, we performed quantitative and qualitative comparisons on the SIRST dataset and compared the proposed network with the state-of-the-art methods top-hat filter [
53], max-median filter [
5], relative local contrast method (RLCM) [
54], multi-scale patch-based contrast measure (MPCM) [
55], multiscale grey difference weighted image entropy (MGDWE) [
56], local intensity and gradient properties (LIGP) [
57], facet kernel and random walker (FKRW) [
58], infrared patch-image model (IPI) [
10], and reweighted infrared patch-tensor model (RIPT) [
11]. These methods are listed in
Table 2 with their hyperparameter settings. The CNN-based methods FPN [
43], U-Net [
31], TBC-Net [
25], ACM-FPN [
19], ACM-U-Net [
19], and ALCNet [
24] were also considered.
(1) Quantitative results: For all traditional methods, to obtain better detection performance, we first obtained their predicted values and, then, performed noise suppression by setting a threshold to remove low response areas. The adaptive threshold was calculated by Equation (17). For the CNN-based methods, we used the same experimental parameter settings as in the original works.
where
and
denote the average value and largest value of the output, respectively.
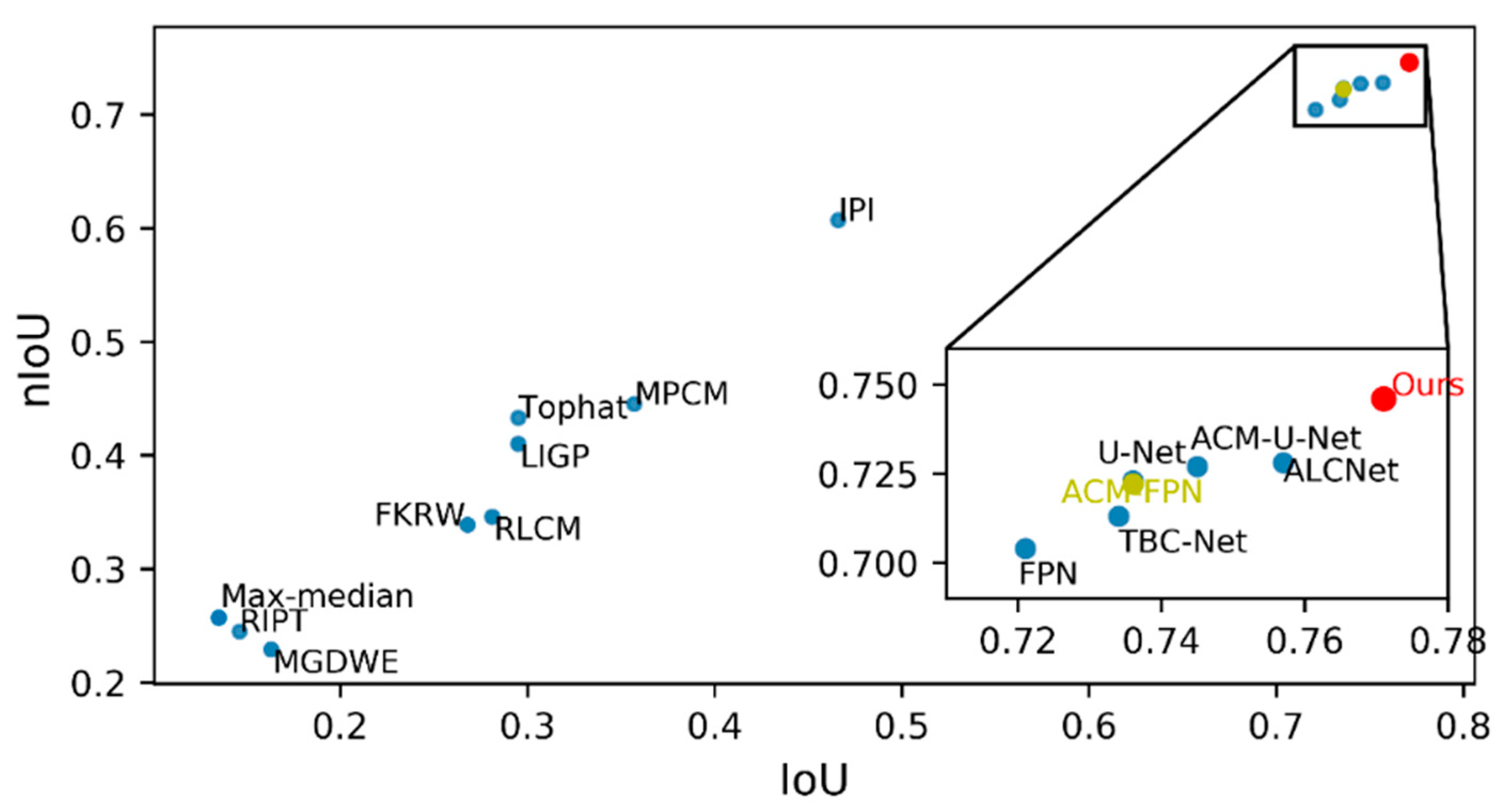
Table 3 details the quantitative results of IoU, nIoU, and inference speed for all the methods, and
Figure 4 shows a visual comparison in terms of IoU and nIoU; EAAU-Net achieved the best performance in terms of both IoU and nIoU. The significant increase in these values demonstrates that our proposed algorithm significantly improved in terms of accuracy for the shape-matching of prior infrared small targets. The SIRST dataset contains challenging images with different signal-to-noise ratios, background clutter, target shapes, and target sizes; this suggests that our proposed method can learn distinguishing features that are robust to scene variations. Furthermore, as illustrated in
Figure 4, the deep-learning-based algorithm achieved a significant improvement over methods based on handcrafted aspects, which are traditionally designed for specific scenes (e.g., specific target sizes and clutter backgrounds), and manually selected parameters (e.g., structure size in top-hat filters and block size in IPI) limit the generalisation performance of these methods.
As presented in
Table 3, the improvements achieved by EAAU-Net over other CNN-based approaches (i.e., FPN, U-Net, TBC-Net, ACM-FPN, ACM-U-Net, and ALCNet) are evident. EAAU-Net performed the best; IoU was improved by 0.014, from 0.757 to 0.771, and nIoU by 0.018, from 0.728 to 0.746 for EAAU-Net compared to the next best method, ALCNet, with an increase in network parameters of only 0.63 M. This can be attributed to the design of the new backbone network tailored for infrared small target detection. The U-shaped basic backbone allows for feature fusion across layers through a skip connection and an encoder–decoder structure capable of maintaining and fully learning the primitive features of infrared small targets in the network. In the skip connection and up-sampling paths, we designed the EAA module specifically for infrared small target detection. This module first exchanges information between the channels and spaces by shuffling the feature maps from deep and shallow layers through a shuffle unit. Then, through a bottom-up global channel attention module, fine features from the lower layers are used to dynamically weight and modulate the higher-layer feature maps containing rich semantic information. The EAA module helps the model learn to distinguish features and selectively augment informative features in the deeper layers of the CNN for better performance, significantly improving the detection performance.
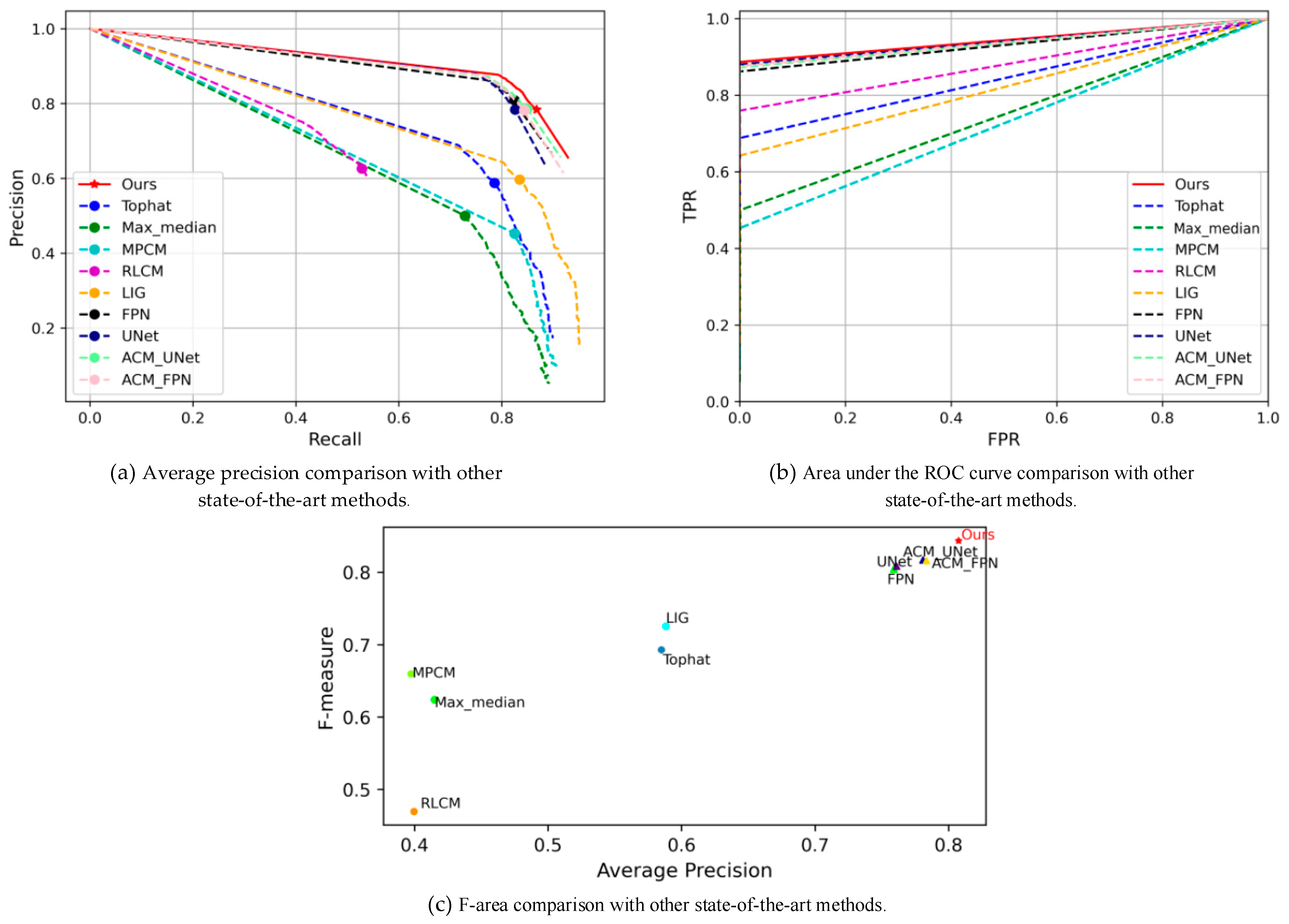
Figure 5 illustrates the PR curves, ROC curves, and F-area performance evaluation results against all the state-of-the-art methods. EAAU-Net outperformed all existing CNN-based and traditional handcraft-based infrared small target detection methods for every metric. The PR curve (i.e.,
Figure 5a) shows that our proposed method was able to achieve the best accuracy and completeness rates, implying that our network has the capacity to focus on the overall target localisation in challenging scenarios where the targets vary in size, type, and location while ensuring detection accuracy. The experimental results for the ROC curve (i.e.,
Figure 5b) show that our method was able to consistently achieve state-of-the-art performance when the false alarm rate (FA) changed and the probability detection (PD) was able to respond quickly to changes in this false alarm rate. The experimental results for the F-area (i.e.,
Figure 5c) show that our method still achieved the best performance when both the harmony and accuracy of the algorithm were considered, implying the high potential of our method for practical applications.
(2) Qualitative results:
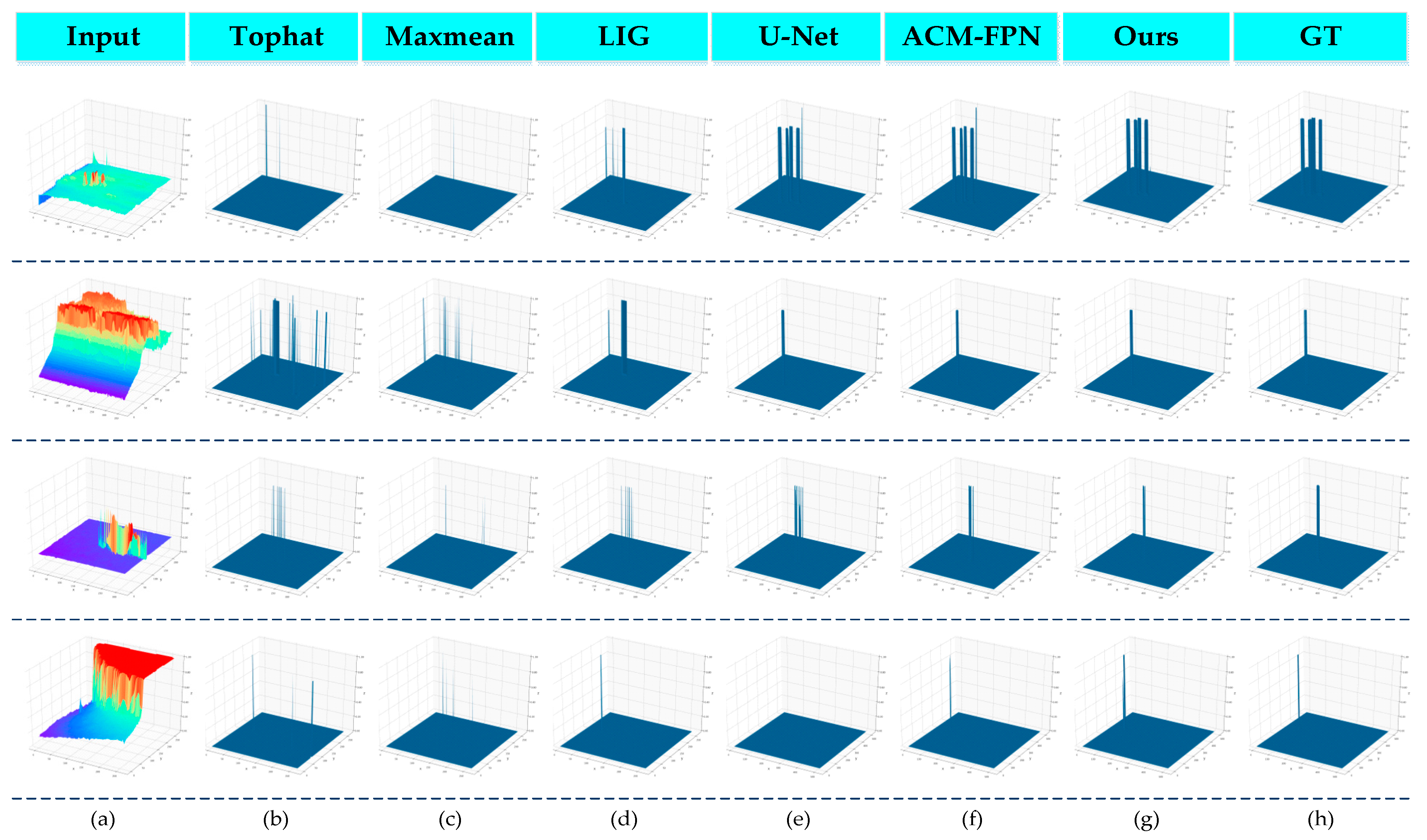
Figure 6 shows the 3D visualisation qualitative results of the traditional handcraft-based method and the CNN-based method. Compared with the traditional method, our proposed method was able to produce accurate target localisation and shape segmentation output at a very low false alarm rate. The traditional handcrafted setting-based method is prone to producing several false alarms and missed regions in complex scenes (as shown in
Figure 6a,b), owing to the fact that the performance of traditional methods relies heavily on manually extracted features and cannot adapt to changes in the target size. CNN-based methods (i.e., U-Net and ACM-FPN) perform much better than traditional methods. However, U-Net also appears to lose targets (as shown in
Figure 6e). EAAU-Net is more robust to these scenario changes. In addition, EAAU-Net was able to generate better shape segmentation than ACM-FPN. This is because we designed the EAA module to help the network adapt well to various types of background clutter, target shapes, and target size challenges using bottom-up cross-layer feature fusion and exchange of channel and spatial information between the same layers, resulting in better performance.
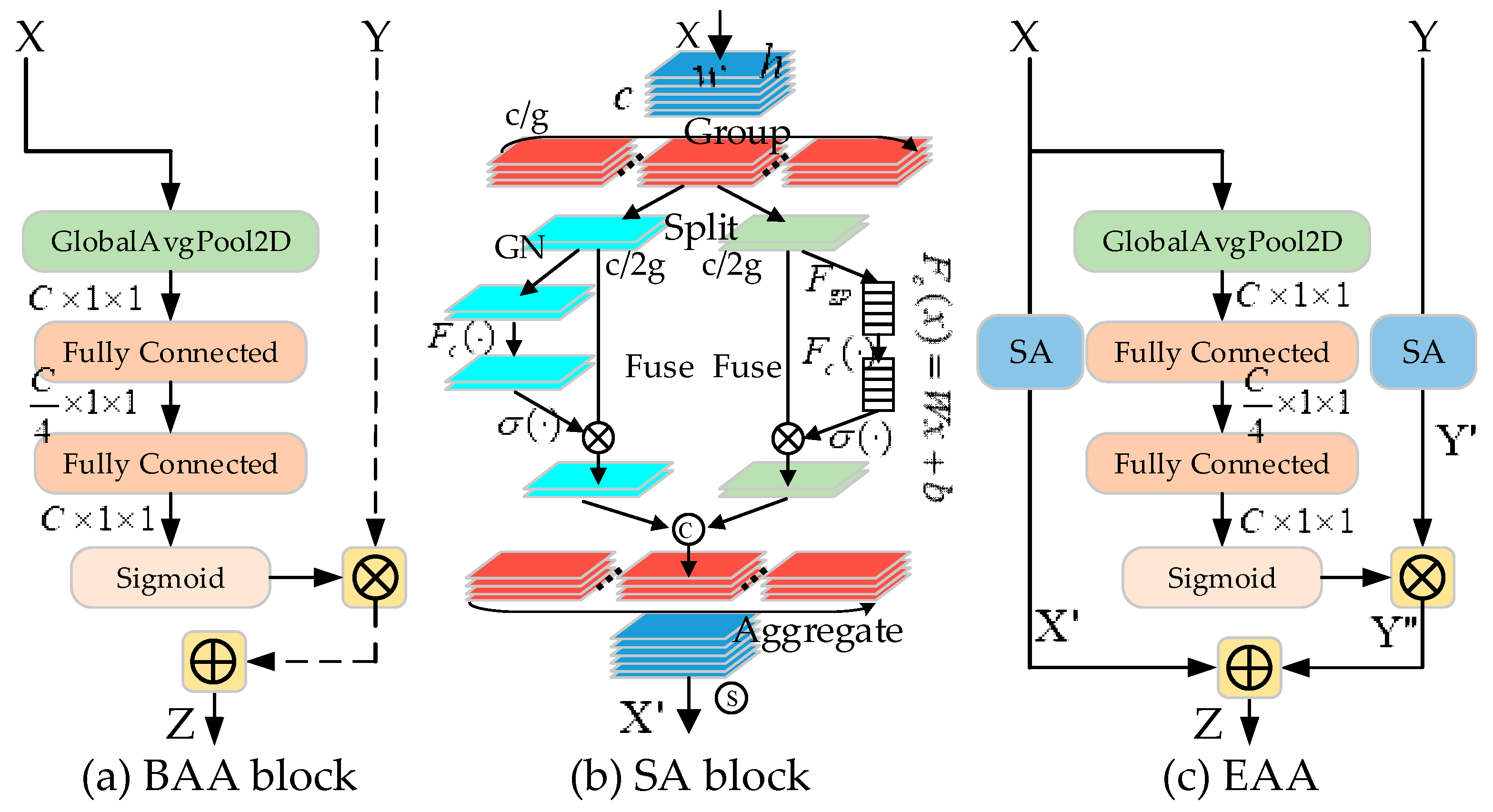
4.4. Ablation Study
In this subsection, we compare the EAA module with several other variants to investigate the potential benefits of our proposed network module and design choices to ensure that the contribution of our proposed model components is justified.
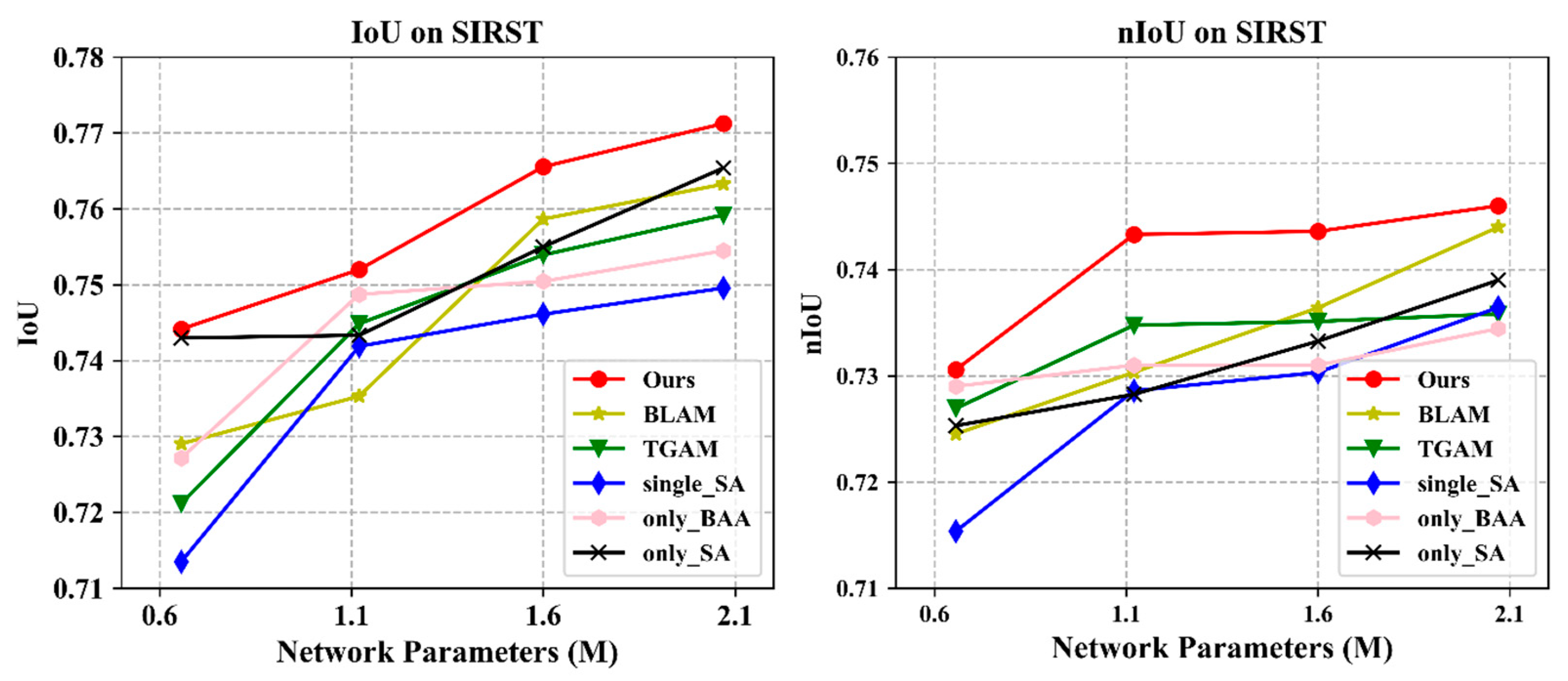
Ablation study for down-sampling depth. The feature information of infrared small targets tends to be very weak, and thus, methods to retain and highlight the deeper features of such targets are of primary concern in target detection network design. Therefore, to avoid losing the deep features of infrared small targets, we applied different down-sampling schemes by changing the block number b in each stage to examine the effects of varying the down-sampling depth. The comparative results are shown in
Figure 7; it may be observed that the network performance of EAAU-Net increased gradually with the depth of the network, while the increase in network parameters was less.
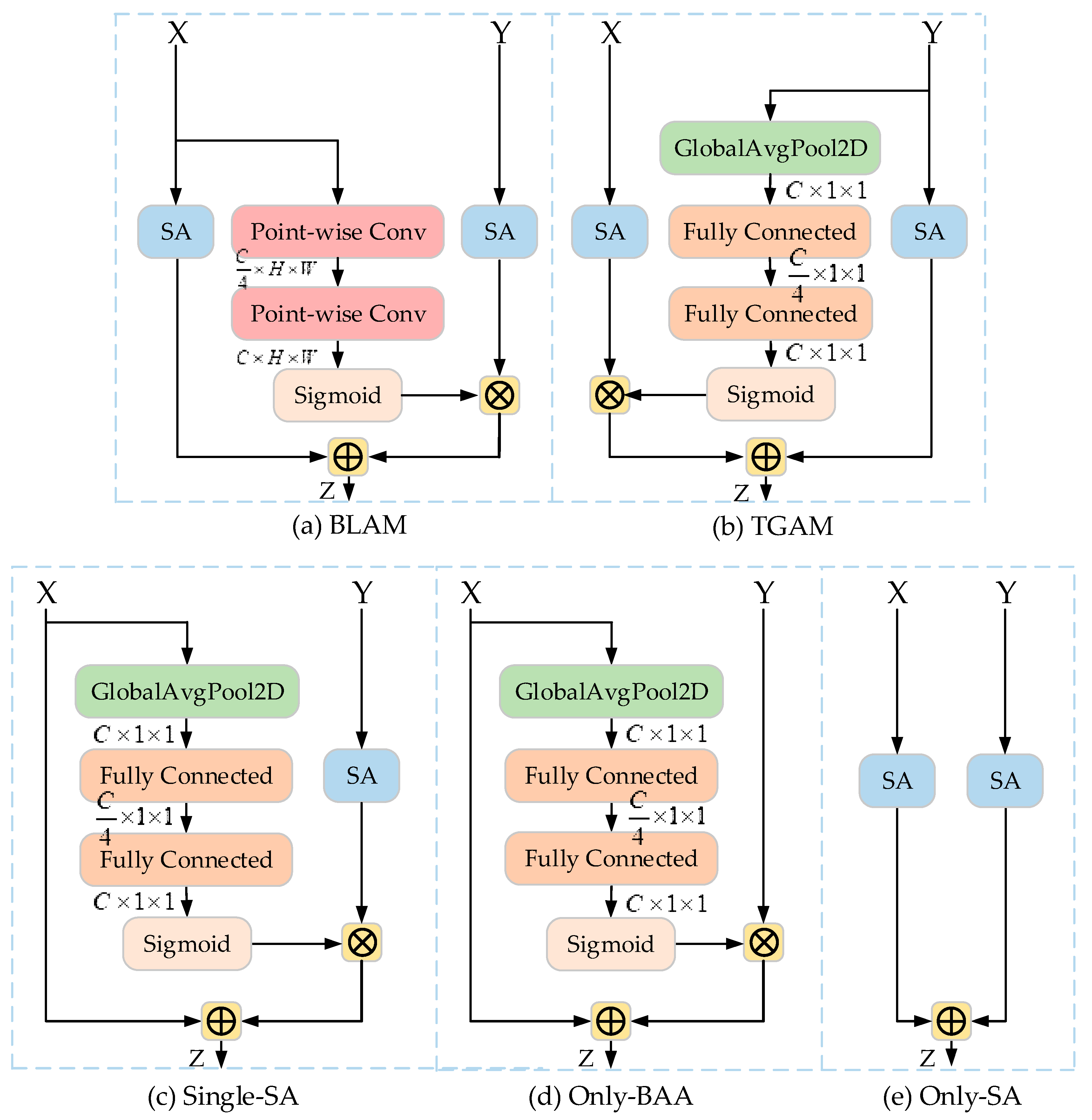
Ablation study for the cross-layer fusion approach. We investigated and compared the bottom-up cross-layer fusion approach with two other ablation modules. The first was a bottom-up local attention modulation (BLAM) module, which aggregates the channel feature context at each spatial location via a local channel attention module (as shown in
Figure 8a). The second was a top-down global attention modulation (TGAM) module taking opposite directions from the EAA module and guiding low-level features through high-level coarse information (as shown in
Figure 8b). The experimental results are shown in
Figure 7, from which it may be observed that the BLAM and TGAM did not perform as well as the EAA module. These results suggest that for infrared small targets, with a given set of computational cost and parameter constraints, fine-grained global contextual information should be aggregated as a guide to refine a high-level feature map by using low-level features as a guide, rather than relying on local information or embedding high-level semantic information into low-level features. Therefore, detailed bottom-up information is more useful for accurate segmentation than top-down semantic guidance.
Ablation study for the SA block. We further investigated and compared the addition of the SA block to both low- and high-level feature maps with two alternate modules. First, a separate SA block considering only spatial and channel information fusion in deep network layers (as shown in
Figure 8c) was studied, along with a model lacking an SA block without considering spatial and channel information fusion within the network layers (as shown in
Figure 8d), to verify the necessity of adding an SA block to both low- and high-layer networks in the EAA module.
Figure 7 provides the results, from which it can be seen that, compared to other modulation schemes, the proposed EAA module performed better in all settings, demonstrating the effectiveness of incorporating an SA block in low- and high-level feature maps to enhance the representation of the CNN by fusing the information of different sub-features using feature dependencies in the spatial and channel dimensions, thus enhancing the original features of the infrared small target.
Ablation study for the EAA module. A comparison between a model using only the BAA block (
Figure 8d), SA block (
Figure 8e), and the proposed EAA module is given in
Figure 7 to verify the effectiveness of the proposed EAA modulation. It can be observed that, compared to using only the BAA block and only the SA block modulation schemes, the proposed EAA module performed better in all settings by exploiting the features in the spatial and channel dimensions and performing information fusion in both low- and high-level feature maps, while using the low-level features obtained by global contextual channel attention in bottom-up pathways to guide the refinement of the high-level feature maps. The results validate the effectiveness of our proposed EAA modulation, i.e., a bottom-up global channel attention mechanism relying on low-level detail information to guide the high-level features for dynamic weighted modulation when low- and high-level feature maps are fused using the spatial and channel feature information. Thus, strong support is provided for the design of bottom-up modulation paths for infrared small target detection and for the fusion of spatial and channel information mechanisms within layers.
4.5. Discussion
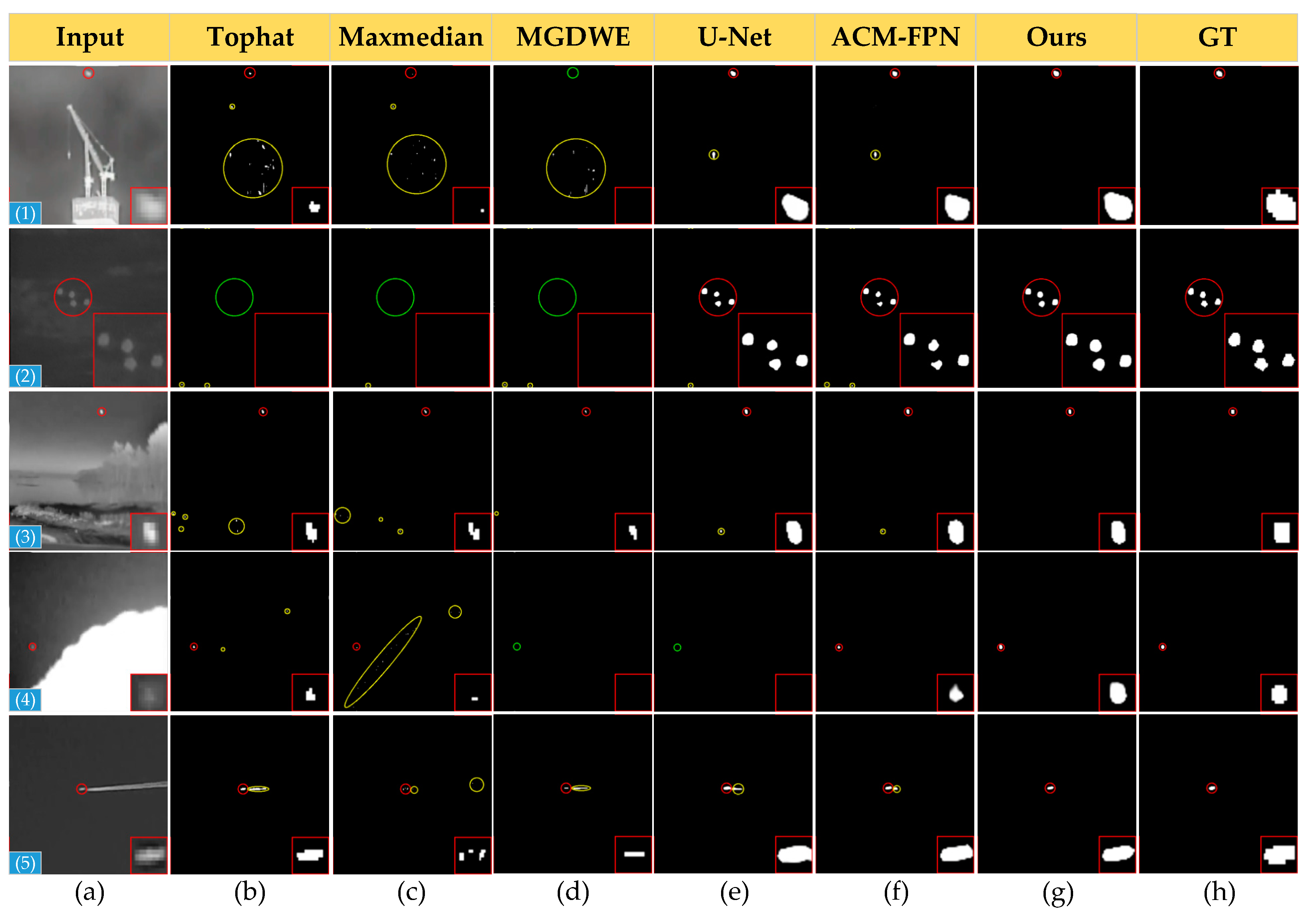
Figure 9 shows the qualitative results achieved by the different detection methods on the SIRST dataset. The target areas are enlarged in the lower right corner to allow for a more visual presentation of the fine segmentation results. Correctly detected targets, false positives, and missed regions are indicated by red, yellow, and green dashed circles, respectively. As traditional methods rely on manually extracted features, they cannot adapt to target size and complex background variations, and numerous false alarms and missed detection areas are present. The CNN-based methods (i.e., U-Net and ACM-FPN) are much better than the traditional methods, which also inevitably show varying degrees of false alarms and missed regions due to the infrared small targets being merged into complex backgrounds. EAAU-Net not only generates better shape segmentation for these scene targets, but also generates no false alarms and missed regions, demonstrating the robustness of our proposed method against cluttered backgrounds, dim and small targets, and its better detection performance.
Although our proposed method achieves better performance, it also has the limitation of not being able to accurately segment the boundaries of infrared small targets.
Figure 10 shows a partial visualisation of the output of the results of the proposed EAAU-Net on the SIRST dataset. The manually labelled ground truth is ambiguous in terms of one- or two-pixel shifts and had a significant impact on our final IoU and nIoU metrics; for example, a 2 × 2-pixel pinpoint target with even a single pixel of shift would result in the pixel being labelled as 3 × 3; this would result in an error of approximately 50% for that target. Therefore, the proposed EAAU-Net suffers from a certain degree of segmentation error (as shown in
Figure 10b,c), which originates from target boundaries that either exceed the labelling mask by a few pixels or segment the target incompletely. Such boundary errors are also present in general vision tasks. Notably, errors are inevitable in manually labelled masks, and the proposed EAAU-Net was able to produce more accurate segmentation results than manually labelled ground truth masks (shown in
Figure 10d,e).
As can be seen in
Figure 10f, the main reason for the inaccurate detection of infrared small targets is that they are too faint. In addition, the small size of the target also results in its small weight in the loss function, which is easily swamped by the boundary error of the larger target during training. In future work, we will focus on reducing the model complexity while adding attention mechanisms and feature fusion modules to the network to enable the exchange of feature information across the different layers of infrared small targets. This is very promising and deserves further research.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}