

Few-Shot Aircraft Detection in Satellite Videos Based on Feature Scale Selection Pyramid and Proposal Contrastive Learning

Abstract
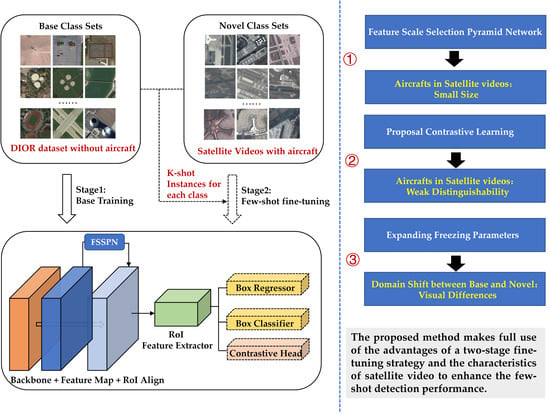
:
1. Introduction
- (1)
- To the best of our knowledge, the method proposed herein is the first few-shot object detection method for satellite videos. As such, it may serve as a significant reference for related research in the field.
- (2)
- FSSPN and proposal contrastive learning loss are constructed to improve the two-stage fine-tuning method based on Faster R-CNN, making it more suitable for the small size objects and weak object distinguishability of aircraft in satellite videos. In addition, in the fine-tuning stage, we expand the network freezing parameters to reduce the interference of visual differences due to domain shift.
- (3)
- We evaluated the proposed method with large-scale satellite video data. The experimental results showed that our technology makes full use of the advantages of a two-stage fine-tuning strategy and the characteristics of satellite video to enhance the few-shot detection performance.
2. Related Work
2.1. Few-Shot Object Detection
2.2. Few-Shot Object Detection in Remote Sensing
3. Method
3.1. Problem Definition and Analysis
3.2. Method Framework
| Algorithm 1. Processing Flow | |
| 1: | Create training set from , fine-tuning set from and testing set from via few-shot detection definition, . |
| 2: | Initialize the parameters in the Backbone, FSSPN, RPN, and RoI Feature Extractor. |
| 3: | for each sample (,) do |
| 4: | Base training. |
| 5: | end for |
| 6: | Frozen the parameters in the Backbone, FSSPN, RPN, and RoI feature extractor, and Reshape the bounding box head of base model. |
| 7: | for k instance per class (,) do |
| 8: | Few-shot fine-tuning. |
| 9: | end for |
| 10: | for each sample (,) do |
| 11: | Generate bounding boxes and category scores of aircraft in each image. |
| 12: | Calculate the precision of the correctly detected aircrafts. |
| 13: | end for |
3.3. Feature Scale Selection Pyramid Network
3.4. Proposal Contrastive Learning
3.5. Loss Function
4. Experiments and Results
4.1. Experimental Setup
4.1.1. Experimental Data
4.1.2. Evaluation
4.1.3. Implementation Details
4.2. Results
4.2.1. Comparison with Other Methods
4.2.2. Ablation Studies
5. Discussion
5.1. Visualization and Analysis
5.2. Performance between Frames of Video
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| FSSPN | Feature scale selection pyramid network |
| FPN | Feature pyramid network |
| RPN | Region proposal network |
| RoI | Region of interest |
| CAM | Contextual attention module |
| FSEM | Feature scale enhancement module |
| FSSM | Feature scale selection module |
| ASPP | Atrous spatial pyramid pooling |
| IoU | Intersection over union |
| SGD | Stochastic gradient descent |
| EFP | Expanding freezing parameters |
| FPS | Frames per second |
References
- Xuan, S.; Li, S.; Han, M.; Wan, X.; **a, G.-S. Object Tracking in Satellite Videos by Improved Correlation Filters with Motion Estimations. IEEE Trans. Geosci. Remote Sens. 2019, 58, 1074–1086. [Google Scholar] [CrossRef]
- Gu, Y.; Wang, T.; **, X.; Gao, G. Detection of Event of Interest for Satellite Video Understanding. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7860–7871. [Google Scholar] [CrossRef]
- Shao, J.; Du, B.; Wu, C.; Zhang, L. Can We Track Targets from Space? A Hybrid Kernel Correlation Filter Tracker for Satellite Video. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8719–8731. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-Cnn: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE international conference on computer vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Gong, H.; Mu, T.; Li, Q.; Dai, H.; Li, C.; He, Z.; Wang, W.; Han, F.; Tuniyazi, A.; Li, H. Swin-Transformer-Enabled YOLOv5 with Attention Mechanism for Small Object Detection on Satellite Images. Remote Sens. 2022, 14, 2861. [Google Scholar] [CrossRef]
- Li, Z.; Wang, Y.; Zhang, N.; Zhang, Y.; Zhao, Z.; Xu, D.; Ben, G.; Gao, Y. Deep Learning-Based Object Detection Techniques for Remote Sensing Images: A Survey. Remote Sens. 2022, 14, 2385. [Google Scholar] [CrossRef]
- Wu, X.; Hong, D.; Tian, J.; Chanussot, J.; Li, W.; Tao, R. ORSIm Detector: A Novel Object Detection Framework in Optical Remote Sensing Imagery Using Spatial-Frequency Channel Features. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5146–5158. [Google Scholar] [CrossRef]
- Fu, K.; Chang, Z.; Zhang, Y.; Xu, G.; Zhang, K.; Sun, X. Rotation-Aware and Multi-Scale Convolutional Neural Network for Object Detection in Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2020, 161, 294–308. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Li, J.; **a, G.-S. Align Deep Features for Oriented Object Detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–11. [Google Scholar] [CrossRef]
- Lei, J.; Luo, X.; Fang, L.; Wang, M.; Gu, Y. Region-Enhanced Convolutional Neural Network for Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5693–5702. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-Scale Object Detection in Remote Sensing Imagery with Convolutional Neural Networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Wu, B.; Shen, Y.; Guo, S.; Chen, J.; Sun, L.; Li, H.; Ao, Y. High Quality Object Detection for Multiresolution Remote Sensing Imagery Using Cascaded Multi-Stage Detectors. Remote Sens. 2022, 14, 2091. [Google Scholar] [CrossRef]
- **a, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Ding, J.; Xue, N.; **a, G.-S.; Bai, X.; Yang, W.; Yang, M.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M. Object Detection in Aerial Images: A Large-Scale Benchmark and Challenges. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object Detection in Optical Remote Sensing Images: A Survey and a New Benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-Class Geospatial Object Detection and Geographic Image Classification Based on Collection of Part Detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Zhao, M.; Li, S.; Xuan, S.; Kou, L.; Gong, S.; Zhou, Z. SatSOT: A Benchmark Dataset for Satellite Video Single Object Tracking. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5617611. [Google Scholar] [CrossRef]
- Yin, Q.; Hu, Q.; Liu, H.; Zhang, F.; Wang, Y.; Lin, Z.; An, W.; Guo, Y. Detecting and Tracking Small and Dense Moving Objects in Satellite Videos: A Benchmark. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5612518. [Google Scholar] [CrossRef]
- Xuan, S.; Li, S.; Zhao, Z.; Zhou, Z.; Zhang, W.; Tan, H.; **a, G.; Gu, Y. Rotation Adaptive Correlation Filter for Moving Object Tracking in Satellite Videos. Neurocomputing 2021, 438, 94–106. [Google Scholar] [CrossRef]
- Sun, X.; Wang, B.; Wang, Z.; Li, H.; Li, H.; Fu, K. Research Progress on Few-Shot Learning for Remote Sensing Image Interpretation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2387–2402. [Google Scholar] [CrossRef]
- Zeng, Q.; Geng, J. Task-Specific Contrastive Learning for Few-Shot Remote Sensing Image Scene Classification. ISPRS J. Photogramm. Remote Sens. 2022, 191, 143–154. [Google Scholar] [CrossRef]
- Zheng, X.; Gong, T.; Li, X.; Lu, X. Generalized Scene Classification from Small-Scale Datasets with Multitask Learning. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5609311. [Google Scholar] [CrossRef]
- Gong, T.; Zheng, X.; Lu, X. Meta Self-Supervised Learning for Distribution Shifted Few-Shot Scene Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6510005. [Google Scholar] [CrossRef]
- Sun, Q.; Liu, Y.; Chua, T.-S.; Schiele, B. Meta-Transfer Learning for Few-Shot Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 403–412. [Google Scholar]
- Perez-Rua, J.-M.; Zhu, X.; Hospedales, T.M.; **ang, T. Incremental Few-Shot Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13846–13855. [Google Scholar]
- Li, A.; Li, Z. Transformation Invariant Few-Shot Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3094–3102. [Google Scholar]
- Fan, Q.; Zhuo, W.; Tang, C.-K.; Tai, Y.-W. Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4013–4022. [Google Scholar]
- Wang, X.; Huang, T.E.; Darrell, T.; Gonzalez, J.E.; Yu, F. Frustratingly Simple Few-Shot Object Detection. ar**v 2020, ar**v:2003.06957. [Google Scholar]
- **ao, Y.; Marlet, R. Few-Shot Object Detection and Viewpoint Estimation for Objects in the Wild. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland; pp. 192–210. [Google Scholar]
- Sun, B.; Li, B.; Cai, S.; Yuan, Y.; Zhang, C. Fsce: Few-Shot Object Detection via Contrastive Proposal Encoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7352–7362. [Google Scholar]
- Wu, J.; Liu, S.; Huang, D.; Wang, Y. Multi-Scale Positive Sample Refinement for Few-Shot Object Detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany; pp. 456–472. [Google Scholar]
- Ren, X.; Zhang, W.; Wu, M.; Li, C.; Wang, X. Meta-YOLO: Meta-Learning for Few-Shot Traffic Sign Detection via Decoupling Dependencies. Appl. Sci. 2022, 12, 5543. [Google Scholar] [CrossRef]
- Kang, B.; Liu, Z.; Wang, X.; Yu, F.; Feng, J.; Darrell, T. Few-Shot Object Detection via Feature Reweighting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 21 October–5 November 2019; pp. 8420–8429. [Google Scholar]
- Li, X.; Deng, J.; Fang, Y. Few-Shot Object Detection on Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5601614. [Google Scholar] [CrossRef]
- Huang, X.; He, B.; Tong, M.; Wang, D.; He, C. Few-Shot Object Detection on Remote Sensing Images via Shared Attention Module and Balanced Fine-Tuning Strategy. Remote Sens. 2021, 13, 3816. [Google Scholar] [CrossRef]
- Zhao, Z.; Tang, P.; Zhao, L.; Zhang, Z. Few-Shot Object Detection of Remote Sensing Images via Two-Stage Fine-Tuning. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Zhou, Y.; Hu, H.; Zhao, J.; Zhu, H.; Yao, R.; Du, W.-L. Few-Shot Object Detection via Context-Aware Aggregation for Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8021805. [Google Scholar] [CrossRef]
- Wang, Y.-X.; Ramanan, D.; Hebert, M. Meta-Learning to Detect Rare Objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 21 October–5 November 2019; pp. 9925–9934. [Google Scholar]
- Yan, X.; Chen, Z.; Xu, A.; Wang, X.; Liang, X.; Lin, L. Meta R-Cnn: Towards General Solver for Instance-Level Low-Shot Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 21 October–5 November 2019; pp. 9577–9586. [Google Scholar]
- Quan, J.; Ge, B.; Chen, L. Cross Attention Redistribution with Contrastive Learning for Few Shot Object Detection. Displays 2022, 72, 102162. [Google Scholar] [CrossRef]
- Cheng, M.; Wang, H.; Long, Y. Meta-Learning-Based Incremental Few-Shot Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 2158–2169. [Google Scholar] [CrossRef]
- Zhang, G.; Luo, Z.; Cui, K.; Lu, S. Meta-Detr: Few-Shot Object Detection via Unified Image-Level Meta-Learning. ar**v 2021, ar**v:2103.11731. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A. Overcoming Catastrophic Forgetting in Neural Networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef]
- Karlinsky, L.; Shtok, J.; Harary, S.; Schwartz, E.; Aides, A.; Feris, R.; Giryes, R.; Bronstein, A.M. Repmet: Representative-Based Metric Learning for Classification and Few-Shot Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5197–5206. [Google Scholar]
- Zhang, T.; Zhang, Y.; Sun, X.; Sun, H.; Yan, M.; Yang, X.; Fu, K. Comparison Network for One-Shot Conditional Object Detection. ar**v 2019, ar**v:1904.02317. [Google Scholar]
- Hsieh, T.-I.; Lo, Y.-C.; Chen, H.-T.; Liu, T.-L. One-Shot Object Detection with Co-Attention and Co-Excitation. Adv. Neural Inf. Process. Syst. 2019, 32, 2725–2734. [Google Scholar]
- Lu, Y.; Chen, X.; Wu, Z.; Yu, J. Decoupled Metric Network for Single-Stage Few-Shot Object Detection. IEEE Trans. Cybern. 2022, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Cheng, G.; Yan, B.; Shi, P.; Li, K.; Yao, X.; Guo, L.; Han, J. Prototype-CNN for Few-Shot Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5604610. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, C.; Liu, C.; Li, Z. Context Information Refinement for Few-Shot Object Detection in Remote Sensing Images. Remote Sens. 2022, 14, 3255. [Google Scholar] [CrossRef]
- Chen, H.; Wang, Y.; Wang, G.; Qiao, Y. Lstd: A Low-Shot Transfer Detector for Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft Coco: Common Objects in Context. In Proceedings of the European conference on computer vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany; pp. 740–755. [Google Scholar]
- Chen, G.; Wang, H.; Chen, K.; Li, Z.; Song, Z.; Liu, Y.; Chen, W.; Knoll, A. A Survey of the Four Pillars for Small Object Detection: Multiscale Representation, Contextual Information, Super-Resolution, and Region Proposal. IEEE Trans. Syst. man Cybern. Syst. 2020, 52, 936–953. [Google Scholar] [CrossRef]
- **ao, A.; Wang, Z.; Wang, L.; Ren, Y. Super-Resolution for “Jilin-1” Satellite Video Imagery via a Convolutional Network. Sensors 2018, 18, 1194. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning Spatial Fusion for Single-Shot Object Detection. ar**v 2019, ar**v:1911.09516. [Google Scholar]
- Zhang, P.; Wang, L.; Wang, D.; Lu, H.; Shen, C. Agile Amulet: Real-Time Salient Object Detection with Contextual Attention. ar**v 2018, ar**v:1802.06960. [Google Scholar]
- Wang, T.; Anwer, R.M.; Khan, M.H.; Khan, F.S.; Pang, Y.; Shao, L.; Laaksonen, J. Deep Contextual Attention for Human-Object Interaction Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–5 November 2019; pp. 5694–5702. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. ar**v 2015, ar**v:1511.07122. [Google Scholar]
- Hong, M.; Li, S.; Yang, Y.; Zhu, F.; Zhao, Q.; Lu, L. SSPNet: Scale Selection Pyramid Network for Tiny Person Detection from UAV Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8018505. [Google Scholar] [CrossRef]
- Zhang, J.; Shi, Y.; Zhang, Q.; Cui, L.; Chen, Y.; Yi, Y. Attention Guided Contextual Feature Fusion Network for Salient Object Detection. Image Vis. Comput. 2022, 117, 104337. [Google Scholar] [CrossRef]
- Zhang, J.; **e, C.; Xu, X.; Shi, Z.; Pan, B. A Contextual Bidirectional Enhancement Method for Remote Sensing Image Object Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4518–4531. [Google Scholar] [CrossRef]
- Fan, B.; Shao, M.; Li, Y.; Li, C. Global Contextual Attention for Pure Regression Object Detection. Int. J. Mach. Learn. Cybern. 2022, 13, 2189–2197. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected Crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised Contrastive Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Sun, Y.; Chen, Y.; Wang, X.; Tang, X. Deep Learning Face Representation by Joint Identification-Verification. Adv. Neural Inf. Process. Syst. 2014, 27, 1988–1996. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Venue | 3-Shot | 5-Shot | 10-Shot |
|---|---|---|---|---|
| Meta R-CNN | ICCV 2019 | 15.2 | 32.3 | 41.1 |
| FSDetView | ECCV 2020 | 10.6 | 22.5 | 37.5 |
| Attention-RPN | CVPR 2020 | 11.3 | 30.2 | 42.3 |
| FSCE | CVPR 2021 | 13.5 | 34.4 | 47.5 |
| Ours | - | 14.7 | 37.1 | 51.3 |
| Baseline | FSEM | FSSM | FEP | 3-Shot | 5-Shot | 10-Shot |
|---|---|---|---|---|---|---|
| √ | 13.5 | 34.4 | 47.5 | |||
| √ | √ | 13.6 | 35.2 | 48.3 | ||
| √ | √ | √ | 14.4 | 36.2 | 50.5 | |
| √ | √ | √ | √ | 14.7 | 37.1 | 51.3 |
| Contrast Head Dimension | Temperature | ||
|---|---|---|---|
| 0.07 | 0.2 | 0.5 | |
| 50.9 | 51.3 | 50.8 | |
| 51.0 | 51.1 | 50.7 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Z.; Li, S.; Guo, W.; Gu, Y. Few-Shot Aircraft Detection in Satellite Videos Based on Feature Scale Selection Pyramid and Proposal Contrastive Learning. Remote Sens. 2022, 14, 4581. https://doi.org/10.3390/rs14184581
Zhou Z, Li S, Guo W, Gu Y. Few-Shot Aircraft Detection in Satellite Videos Based on Feature Scale Selection Pyramid and Proposal Contrastive Learning. Remote Sensing. 2022; 14(18):4581. https://doi.org/10.3390/rs14184581
Chicago/Turabian StyleZhou, Zhuang, Shengyang Li, Weilong Guo, and Yanfeng Gu. 2022. "Few-Shot Aircraft Detection in Satellite Videos Based on Feature Scale Selection Pyramid and Proposal Contrastive Learning" Remote Sensing 14, no. 18: 4581. https://doi.org/10.3390/rs14184581