



Tree Species Classification from Airborne Hyperspectral Images Using Spatial–Spectral Network

Abstract
:1. Introduction
- Classification methods based on spectral features [19,20]. This method utilizes 1D-CNN to extract features from the raw spectral information of pixels to complete classification. ** of the spatiotemporal distribution and characteristics of tree species over wide areas. Many researchers have successfully utilized remote sensing technology for tree species classification studies [32,33,34]. Park et al. [35] combined high-resolution RGB images (spatial resolution of 7 cm) acquired using UAV with machine learning algorithms to monitor trees and leaf phenology in Panama’s tropical forests. Grabska et al. [36] created nine different subsets of variables from multi-temporal Sentinel-2 data and environmental terrain data (elevation, slope, and slope direction) using a Random Forest-based variable importance selection algorithm (VSURF) and Recursive Feature Elimination (RFE). They classified the tree species using Random Forest, Support Vector Machine, and XGBoost algorithms, respectively. The results showed that the Support Vector Machine classifier outperforms the other two classifiers, obtaining the highest accuracy of 86.9%. Although RGB and multispectral remote sensing data have been widely used in tree species classification, the characteristics between some tree species (especially those of the same genus) are very similar, making it difficult to classify them finely with these two data sources.
2.2. Classification Methods Based on Hyperspectral Images
While RGB and multispectral data were reported to have potential for tree species map**, the continuous spectral information contained in hyperspectral data seems even more suitable to differentiate tree species with similar spectral properties. In previous studies, tree species classification using hyperspectral data mainly adopted traditional machine learning methods [37,38,39], such as Support Vector Machine, Random Forest, BP neural network, etc. For example, Dalponte et al. [40] used hyperspectral data and three classifiers (SVM, RF, and Maximum Likelihood method) to evaluate the accuracy of boreal forest species classification at the pixel level and crown level, respectively. However, traditional machine learning methods need to process and transform the raw data and manually extract features with distinction, such as important bands, vegetation indices, and texture features. The performance results of the methods largely depend on whether the selected features are reasonable or not. However, feature selection often relies on experience and is somewhat blind. In addition, the selected feature type depends on the specific task and dataset, which needs to be decided according to the actual situation, resulting in poor generalization ability. Wei et al. [41] proposed a fine classification method based on multi-feature fusion and deep learning. In their research, the morphological profiles, GLCM texture and endmember abundance features were leveraged to exploit the spatial information of the hyperspectral imagery. Then, the spatial information was fused with the original spectral information to generate classification results by using the deep neural network with a conditional random field (DNN + CRF) model. Although this method can yield good classification results, the spatial features are manually extracted from the raw data, which consumes time.2.3. Attention Mechanism
As is known to all, the importance of every spectral channel and the area of the input patch is different when the network extracts features. The attention mechanisms can focus on the most informative part and decrease the weight of other regions. Many researchers have introduced an attention mechanism into hyperspectral image classification. Ma et al. [42] introduced the Convolutional Block Attention Module (CBAM) into hyperspectral images classification and proposed a Double-Branch Multi-Attention mechanism network (DBMA) for HSI classification. The experimental results demonstrated the effectiveness of the attention mechanism in hyperspectral images classification. However, current attention mechanisms often use additional sub-networks to generate attention weights [43,44,45], increasing the number of parameters in the model. The hyperspectral images have a massive amount of data compared to other remote sensing data sources. Accordingly, the number of parameters in the network model is also huge. The parameter-free attention mechanism does not introduce additional parameters to the network in generating weights, which is more suitable for hyperspectral images classification.3. Materials and Methodology
3.1. Dataset Introduction
To verify the robustness of the proposed method, we conducted tree species classification experiments on three different hyperspectral datasets. The three study areas are located in different spatial locations, and the datasets are acquired using various hyperspectral sensors, with different spatial resolutions and different tree species categories. Next, the three datasets are described in detail.3.1.1. TEF Dataset
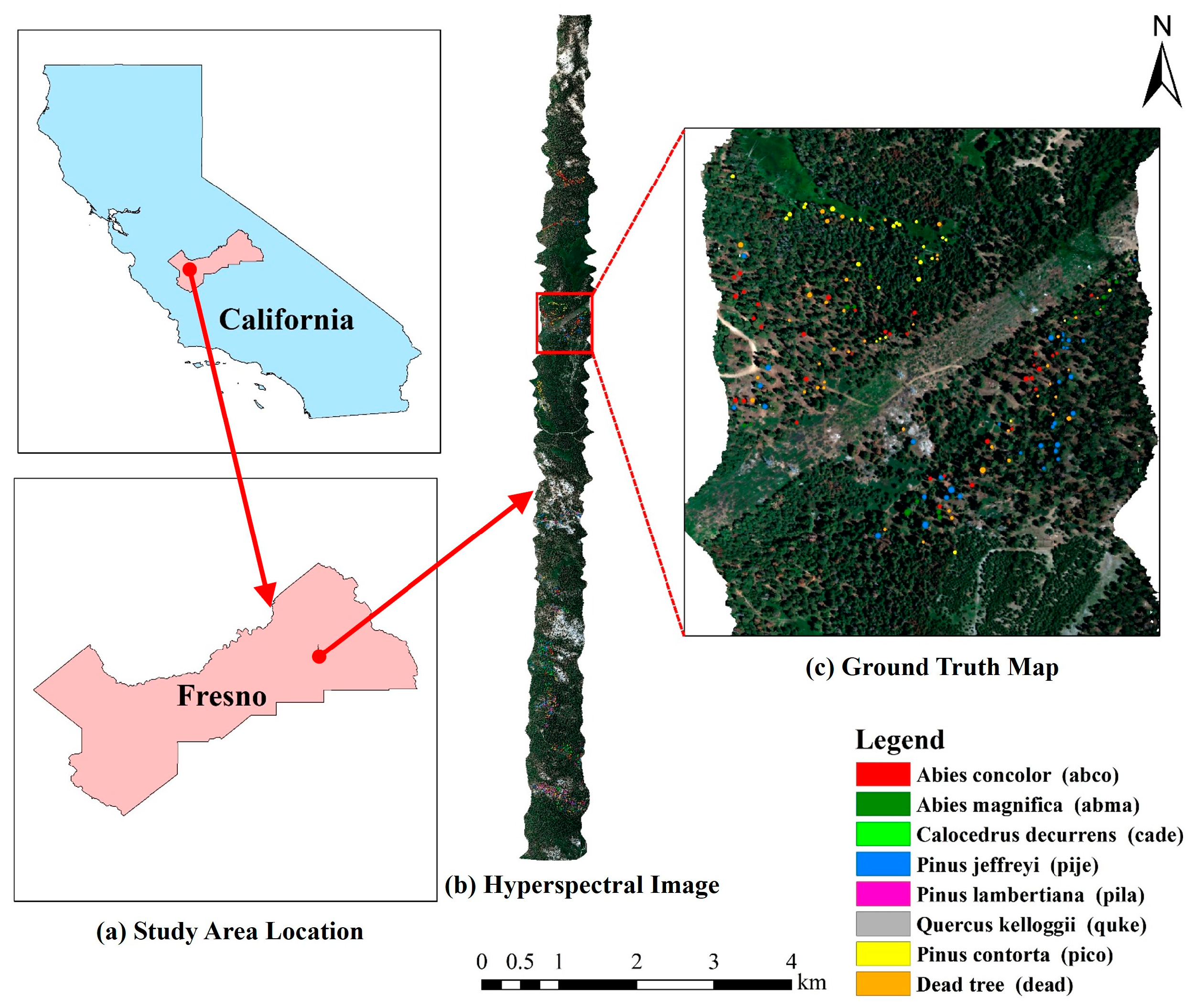
The Teakettle Experimental Forest (TEF) study area is located in northeastern Fresno, California, USA (36°59′51″N, 119°1′28″W), near the southern Sierra Nevada Mountains, as shown in Figure 1a. The TEF dataset was collected in 2017 by the National Ecological Observatory Network (NEON) using the airborne remote sensing platform AOP. A south-to-north flight strip, approximately 16 km long and 1 km wide, covering a portion of the Teakettle Experimental Forest, was used for this study. The hyperspectral sensor covers a wavelength range of 380–2510 nm with a spectral sampling interval of 5 nm, resulting in 426 bands. Data acquisition using the remote sensing platform occurred at an altitude of approximately 1000 m above the ground, resulting in an image spatial resolution of 1 m. After removing the empty band and the bands affected by water vapor absorption, the remaining 388 bands were used for experiments. The hyperspectral data was preprocessed by NEON at the time of dataset release, including radiometric calibration, geometric correction, atmospheric correction, and orthometric correction. Field data was provided by Geoffrey et al. [24], and includes seven dominant tree species and dead trees.The dataset was divided using a stratified random sampling method in this study. Specifically, a fixed proportion of data from each category was selected as the training and test sets. To avoid the chance of random selection in the dataset production process, we adopted a 5-fold cross-validation method to obtain five datasets. In each experiment, five datasets were trained and tested, respectively, and the average value was taken as the final classification result. The specific number of training and test sets for each category in the TEF dataset is shown in Table 1.3.1.2. Tiegang Reservoir Dataset
The Tiegang Reservoir study area is located in the southeastern part of Baoan District, Shenzhen City, Guangdong Province, China (22°36′30″N, 113°54′30″E), as shown in Figure 2a. The image was collected using an independently integrated UAV hyperspectral system of the Chinese Academy of Surveying and Map**. The hyperspectral sensor is a push-broom scanner that records 112 bands in the 400–1000 nm spectral range with a spectral resolution of 5 nm. The flight altitude was set to 100 m above ground level, resulting in an image spatial resolution of 0.1 m. We performed pre-processing operations such as outlier removal, radiometric calibration, geometric correction, atmospheric correction, and image mosaic on the raw image. The hyperspectral image is shown in Figure 2b. Field data was collected at the end of the flight process, and contained a total of seven tree species.Because the spatial resolution of the Tiegang Reservoir dataset is 0.1 m, and the number of pixels is more compared to the TEF dataset, we did not use a 5-fold cross-validation method to produce the dataset; instead, the training set and the test set were divided according to the ratio of 1:1. The above operation was repeated five times, and its average value was calculated as the final classification result. The specific number of training and test sets for each category in the Tiegang reservoir dataset is shown in Table 2.3.1.3. **ongan New Area Dataset
The **ongan New Area study area is located in the Matiwan Village, in the southeastern part of **ongan New Area, Hebei Province, China (38°56′40″N, 116°3′57″E), as shown in Figure 3a. The hyperspectral image was collected in October 2017 by the Institute of Remote Sensing and Digital Earth and the Shanghai Institute of Technical Physics of the Chinese Academy of Sciences. The hyperspectral sensor covers a wavelength range of 390-1000 nm, with a spectral sampling interval of approximately 2.4 nm, resulting in 256 bands. The data was collected using the airborne remote sensing platform at about 2000 m from the ground, resulting in an image spatial resolution of 0.5 m. The image contains 3750 × 1580 pixels, as shown in Figure 3b. Through the field investigation of land cover types, 20 categories were annotated, as shown in Figure 3c, including many tree species, such as Pyrus sorotina, Acer negundo, Salix babylonica, etc.The **ongan New Area dataset differs from the other two datasets. All trees are artificial plantations, which are uniformly distributed, and the boundaries between different tree species are clear. Considering the difficulty and high cost of sample acquisition in practical remote sensing applications for forests, the tree species classification performance of the network was explored with limited training samples. Specifically, we randomly selected 0.5% of the data from each category as the training set and 5% of the data as the test set. The objects of the study were various typical broadleaf tree species in northern China, so the categories of non-tree objects were categorized as other. Similarly, the above operation was repeated five times to avoid the chance of random selection, resulting in five datasets. The five datasets were trained and tested in each experiment, and the average value was taken as the final classification result. The specific number of training and test sets for each category in the **ongan New Area dataset is shown in Table 3.3.2. Methodology
The hyperspectral image data (where and denote the spatial size of HSI and the number of spectral bands, respectively) are a three-dimensional structure, which contains spatial information and rich spectral information. To better classify HSI pixels with spectral and spatial information, the HSI patch is cropped from and input into the neural network to extract spatial–spectral features. Here, the center pixel of is , and is patch size, chosen in this study to be 9 × 9. Moreover, to fully utilize the advantages of hyperspectral images, we proposed a double-branch spatial–spectral joint network based on the SimAM attention mechanism for tree species classification. The network structure is shown in Figure 4, and consists of three parts: spectral branch, spatial branch, and feature fusion. Specifically, the spectral branch mainly uses a 3D-CNN to extract the spectral features of pixels. The spatial branch mainly uses a 2D-CNN to extract the spatial features of pixels. To make further use of the spatial–spectral information of hyperspectral data, we fuse the features extracted from the spectral branch with those extracted from the spatial branch, and introduce the SimAM attention mechanism in the fusion stage. By assigning different weights to each part of the feature map, important features are extracted, and unimportant features are suppressed, thus improving the classification accuracy of tree species.3.2.1. Spectral Branch
When extracting the spectral features of pixels using a 1D-CNN, the spatial information of the data will be lost, while a 3D-CNN extracts the spectral features along with their spatial features, which can avoid the loss of spatial information. Therefore, in the spectral branch, we utilize a 3D-CNN to extract the spectral features of pixels. The 3D convolution operation is as in Equation (1):where, is the value at position on the jth feature cube in the lth layer. and denote the height and width of the 3D convolution kernel in the spatial dimension, respectively, and denotes the 3D convolution kernel in the spectral dimension. is the weight parameter at position of the th convolution kernel in the th layer, and the convolution kernel is connected to the mth feature cube in the th layer. is the value at position on the th feature cube in the th layer. is the bias value. is the activation function; we chose the ReLU activation function in this study.The input data format for the spectral branch is (1, 9, 9, band), which contains all pixels within a neighborhood size of 9 × 9 centered on the pixel to be classified. First, we convolve the data using a 3D convolution kernel of size (1, 1, 7) to increase the number of channels to 32. After that, we design two spectral residual blocks to extract features further. The residual structure connects the convolutional layers through identity map**, which promotes a better backpropagation of the gradient and helps to solve the problem of gradient vanishing and explosion [46]. Each spectral residual block consists of two 3D convolutional layers. Meanwhile, in order to speed up the training and convergence of the network and prevent model overfitting, we add a Batch Normalization (BN) layer after each convolutional layer of the network to improve the model performance. Finally, we utilize a 3D convolutional kernel of size (1, 1, kernel), where kernel denotes the number of bands remaining after a series of convolutions, to obtain a spectral feature map of size (128, 9, 9), denoted by .3.2.2. Spatial Branch
In the spatial branch, we utilize a 2D-CNN to extract the spatial features of hyperspectral images. A 2D-CNN mainly uses a 2D convolution kernel to perform convolution operations on 2D data. The value at position on the th feature map in the th layer is:where, and denote the height and width of the 2D convolution kernel, respectively. is the weight parameter at position of the th convolution kernel in the th layer, and the convolution kernel is connected to the th feature map in the th layer. is the value at position on the th feature map in the th layer. is the bias value. is the activation function; similarly, we chose the ReLU activation function in the spatial branch.In previous studies, when researchers extracted spatial features of hyperspectral images using a 2D-CNN, they first processed the raw data using a dimensionality reduction algorithm (e.g., PCA algorithm), and then used the neural network for classification. However, in the process of performing feature dimensionality reduction, the spectral information of the data will be lost. To avoid the loss of information, instead of performing dimensionality reduction on the data, we input all of the original spectral bands of the pixels into the network. Hence, the input data format of the spatial branch is (band, 9, 9). In the spatial branch, we first extract the multi-scale spatial features of the data using multi-scale convolution (the convolution kernels are 1 × 1, 3 × 3, and 5 × 5, respectively). The number of output channels is 32, and three sets of feature maps with sizes of (32, 9, 9) are obtained, respectively. Then, the three sets of features are combined to form a muti-scale feature map used as input to the subsequent convolutional layers, as shown in Equation (3).where, denotes the muti-scale feature map. , , and denote the feature maps obtained after different scales of convolutional layers, respectively.After multi-scale convolution, we utilize a 2D convolution with a kernel size of (1, 1) for the multi-scale feature map, and the number of output channels is set to 32 to reduce the number of parameters. Similarly, in the spatial branch, we also design two spatial residual blocks with a convolution kernel size of (3, 3). Finally, after a convolutional layer with kernel size (1, 1), a spatial feature map with size (128, 9, 9) is obtained, denoted by .3.2.3. Feature Fusion
After the raw data goes through the spectral branch and the spatial branch, the spectral features and the spatial features of size (128, 9, 9) are obtained, respectively. We combine these two features to utilize the spatial–spectral information of the data further. Since the spectral and spatial features are in different domains, the concatenate operation is chosen instead of the addition operation so that the two features can be kept independent. The features are merged to form spatial–spectral features of size (256, 9, 9).All features in the feature have the same weight. However, different spatial locations and channels have different distinguishing abilities for tree species. In order to extract features with stronger discriminative ability, we introduce the SimAM attention mechanism into the network to weight the feature maps. The SimAM attention mechanism can find the weight of each neuron in the feature maps by minimizing an energy function [47]. The energy function of the th neuron is shown in Equation (5).where, and denote the mean and variance of all neurons on the channel, respectively. represents the number of neurons per channel as H × W. denotes the regularization term.The lower the energy , the greater the difference between the target neuron and the surrounding neurons, i.e., the more important the neuron. Therefore, the weight of each neuron on the feature maps can be obtained by . Then, the feature maps enhanced using the attention mechanism can be expressed by Equation (6).where the activation function is designed to restrict too large of a value in . denotes Hadamard product.The SimAM attention mechanism does not introduce additional parameters into the weight generation process. It belongs to parameter-free attention, which reduces the number of model parameters compared to other attention mechanisms. Furthermore, in order to aggregate the features further, we use a 2D convolution with kernel size (1, 1) before and after the attention mechanism, respectively. Then, the features are subject to globally averaged pooling, and finally complete the tree species classification through the fully connected layer and the softmax function.In summary, the network proposed in this study makes full use of the advantages of hyperspectral images. First, the input data of the spectral branch is not only the spectral information of the pixel to be classified, but also contains the spectral information of other pixels in its neighborhood range, which avoids the loss of spatial information. Second, in the spatial branch, we do not reduce the dimensionality of the original data, but input all the spectral bands into the spatial branch, which avoids the loss of spectral information in the process of dimensionality reduction. Finally, we further combine the spectral and spatial information using a double-branch network structure.3.3. Comparison Methods
To demonstrate the superiority and effectiveness of the proposed method in this study, we compare it with traditional machine learning methods such as SVM and RF, and other state-of-the-art deep learning methods such as 3D-CNN, DBMA, DBDA, ConvNeXt and SSFTT. Next, the compared methods are briefly described separately.- 1.
- SVM: Support Vector Machine. A support vector machine with a radial basis function was used in this study, and the input features were important bands, vegetation index, the first three principal components after PCA dimensionality reduction, and eight spatial texture features corresponding to each principal component.
- 2.
- RF: Random Forest. The parameter n_estimators was set to 500, and the input features were consistent with those of the SVM.
- 3.
- 3D-CNN: Three-Dimensional Convolutional Neural Network. The specific network architecture is described in Zhang et al. [27]. The method is based on the 3D-CNN, and the input data size is 1 × 9 × 9 × bands, where “band” represents the number of spectral bands, and 9 denotes patch size.
- 4.
- DBMA: Double-Branch Multi-Attention Mechanism Network. The specific network architecture is described in Ma et al. [42]. The method is based on a double-branch network structure, dense blocks and the CBAM attention mechanism, and the input data size is consistent with a 3D-CNN.
- 5.
- DBDA: Double-Branch Dual-Attention Mechanism Network. The specific network architecture is described in Li et al. [48]. The method is based on a double-branch network structure, dense blocks and the DANet attention mechanism, and the input data size is consistent with a 3D-CNN.
- 6.
- ConvNeXt: A pure ConvNet model. The specific network architecture is described in Liu et al. [49]. The method is based on the ideas of ResNet and Swin Transformer, and the input data size is band × 9 × 9.
- 7.
- SSFTT: Spectral–Spatial Feature Tokenization Transformer. The specific network architecture is described in Sun et al. [50]. The method is based on the 3D-CNN and Transformer Encoder. The input data size is 1 × 30 × 13 × 13, where 30 denotes the first thirty principal components after PCA dimensionality reduction, and 13 denotes patch size.
To fairly compare the classification performance of each deep learning method, we set the same training parameters. In particular, the batch size is set to 128, and the Adam optimizer is adopted. The learning rate is set to 0.0001, and we train each model for 50 epochs.All methods were implemented in Python 3.6. SVM and RF were implemented based on the scikit-learn library, and deep learning methods were implemented based on the Pytorch 1.9.1 open-source deep learning framework. The operating platform configuration consisted of two Intel(R) Xeon(R) Gold 5218R @2.10GHz CPU (Intel Corporation, Santa Clara, CA, USA) and an NVIDIA GeForce RTX 3080 GPU (NVIDIA Corporation, Santa Clara, CA, USA).4. Experiments
4.1. The Classification Results of the TEF Dataset
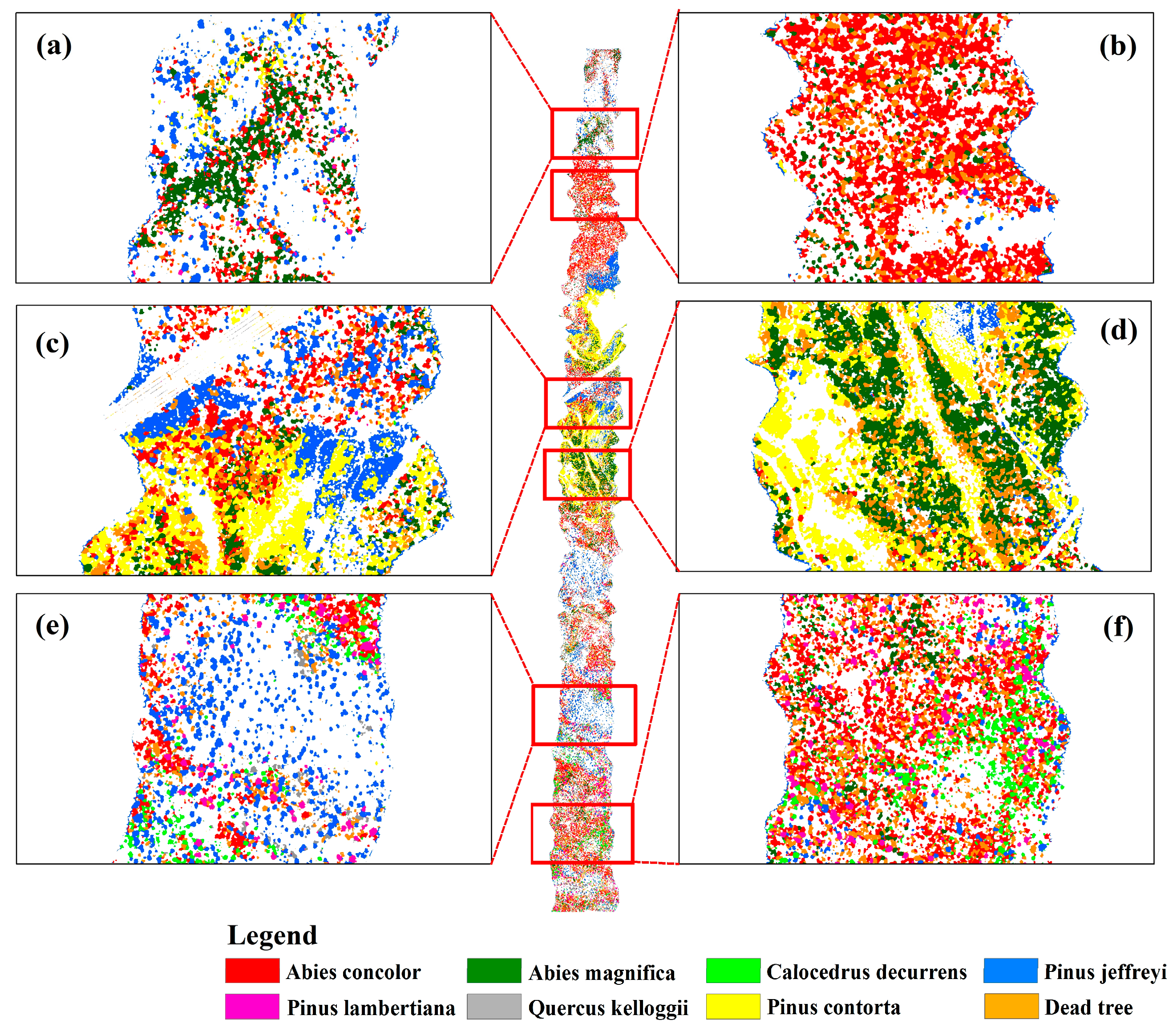
The classification results of the TEF dataset using different methods are shown in Table 4. It can be observed that all deep learning-based methods achieve higher classification accuracy compared to the traditional machine learning methods (SVM and RF). The SVM method achieved the lowest classification accuracy with an OA value of only 44.65%. Compared with other classification methods, the method proposed in this study achieved the highest classification accuracy, with an OA value of 93.31%, an AA value of 90.89%, and a Kappa coefficient of 0.9183. Except for Pinus lambertiana and Quercus kelloggii, the highest classification accuracy of other tree species was obtained using the proposed method. The highest classification accuracy (99.43%) for Pinus lambertiana was obtained using the DBDA method. The proposed method achieved the second-highest classification accuracy for Pinus lambertiana, with a classification accuracy of 98.87%, and the difference between these two methods was only 0.56%. Among all the tree species, the classification accuracy of Abies magnifica and Quercus kelloggii was relatively low, with most below 60%. Abies concolor and Abies magnifica both belong to the genus abies of the pine family, and their spectral information is similar. Additionally, as known from Table 1, the number of Abies magnifica pixels used for training was 718, only one-third of the number of Abies concolor pixels (2330). These two factors caused the mixed classification between the two tree species, which led to the lower classification accuracy of Abies magnifica. The number of Quercus kelloggii pixels used for training was only 96, and the serious shortage of training samples may be the main reason for its low classification accuracy. The proposed method achieved classification accuracy above 80% for both of these tree species, indicating that the method can obtain good classification results in the case of sample imbalance and limited training samples.The hyperspectral image was predicted using the proposed method, and the classification map of the study area is shown in Figure 5. From the classification map, it can be observed that the most prevalent tree species in the study area are Abies concolor, Pinus jeffreyi, and Pinus contorta. Specifically, Abies concolor is mainly distributed in the northern (Figure 5b) and southern (Figure 5f) regions of the study area. Pinus jeffreyi is distributed in the northern (blue-colored area in Figure 5), central (Figure 5c), and southern (Figure 5e) regions of the study area. Pinus contorta is mainly distributed in the central region of the study area, as shown in Figure 5c,d.4.2. The Classification Results of the Tiegang Reservoir Dataset
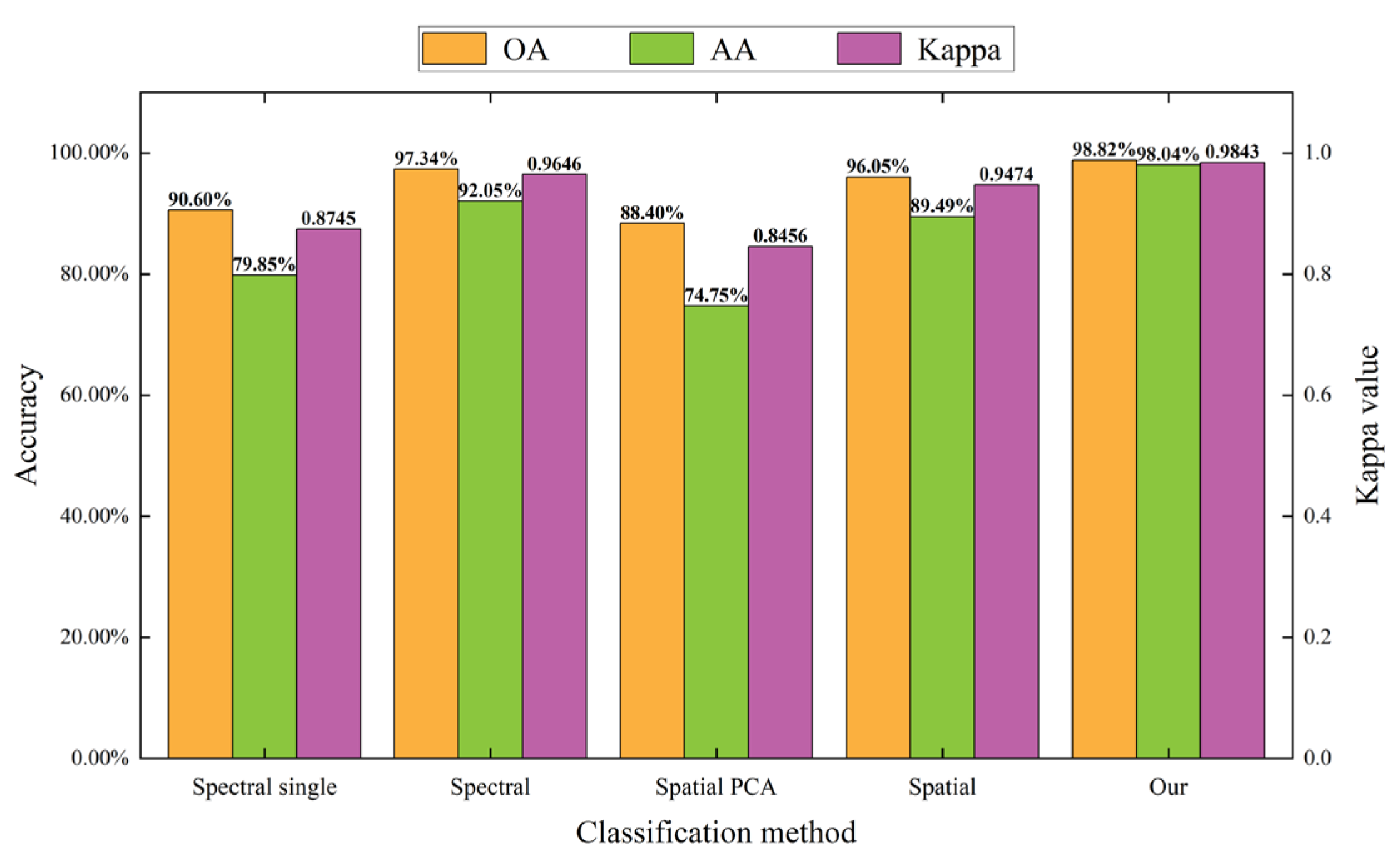
The classification results of the Tiegang Reservoir dataset using different methods are shown in Table 5. Similarly, we observed that all deep learning-based methods achieve higher classification accuracy than traditional machine learning methods. This is because SVM and RF classifiers use shallow features of the dataset, which makes it difficult to distinguish complex classification objects such as tree species with similar spectral information, whereas deep learning methods automatically learn nonlinear high-level features from the training set, which provides a strong advantage in classifying hyperspectral tree species. Compared with other deep learning neural networks, the proposed method makes full use of the spectral and spatial information of hyperspectral images and minimizes the loss of information. The optimal accuracy of tree species classification was obtained using the proposed method with an OA value of 95.7%, an AA value of 88.16%, and a Kappa coefficient of 0.9389. Among all tree species, Ficus altissima species obtained the lowest classification accuracy, all were below 30%. The proposed method obtained the highest classification accuracy, but only of 24.4%. Compared with other tree species, fewer Ficus altissima samples were used for training, and the severe shortage in sample size is the most important reason for its lower classification accuracy.The tree species prediction maps of the Tiegang Reservoir study area that were generated using deep learning methods are shown in Figure 6. From the classification maps, it can be observed that the distribution of different tree species is relatively concentrated, mainly in the form of pure forests. The areas of tree species predicted using the different methods are generally consistent. The classification maps obtained using the 3D-CNN and DBMA have more noise than other classification methods. The main dominant tree species in the study area are Cinnamomum camphora, Glyptostrobus pensilis, and Platycladus orientalis. Cinnamomum camphora is the most widely distributed tree species in the study area, with distribution across various regions. Glyptostrobus pensilis is mainly distributed in the southern region of the study area, closer to the reservoir. Platycladus orientalis is primarily distributed in the northwest region of the study area.4.3. The Classification Results for the **ongan New Area Dataset
The results of classifying the **ongan New Area dataset using different methods are shown in Table 6. Similar to the results obtained from the TEF and Tiegang Reservoir datasets, all deep learning-based methods obtained higher classification accuracy than traditional machine learning methods. The proposed method achieved optimal accuracy compared to other deep learning methods, with an OA value of 98.82%, an AA value of 98.04%, and a Kappa coefficient of 0.9843, which far exceeded the classification performance of other methods. Among all tree species, the classification accuracy of Robinia pseudoacacia was the lowest, in which RF and DBDA methods could not separate Robinia pseudoacacia from other tree species, with a classification accuracy of 0.00%, and the classification accuracy of other classification methods was also lower than 30%. This was because the number of training samples for Robinia pseudoacacia was relatively small compared to other categories. As can be seen from Table 3, only 28 Robinia pseudoacacia samples were used for training, which makes it difficult for the classifier to learn distinguishable features. However, under the conditions of unbalanced samples and limited training samples, the proposed method can perform well in distinguishing Robinia pseudoacacia from other tree species, with a classification accuracy of 95.29%, which proves the robustness of the method.The ground truth map and the classification maps, obtained using various methods, for the **ongan New Area dataset are shown in Figure 7. Although each classifier can distinguish the boundaries between tree species well, different degrees of “salt and pepper” noise phenomenon exist. The “salt and pepper” noise in the classification map (Figure 7b) obtained using SVM is the most serious. The method proposed in this study not only uses the spectral information, but also makes full use of the spatial information of pixels. Compared to other methods, the phenomenon of “salt and pepper” noise is significantly improved, and the classification map (Figure 7i) is basically consistent with the ground truth map.5. Discussion
5.1. The Importance of Joint Spatial–Spectral Features
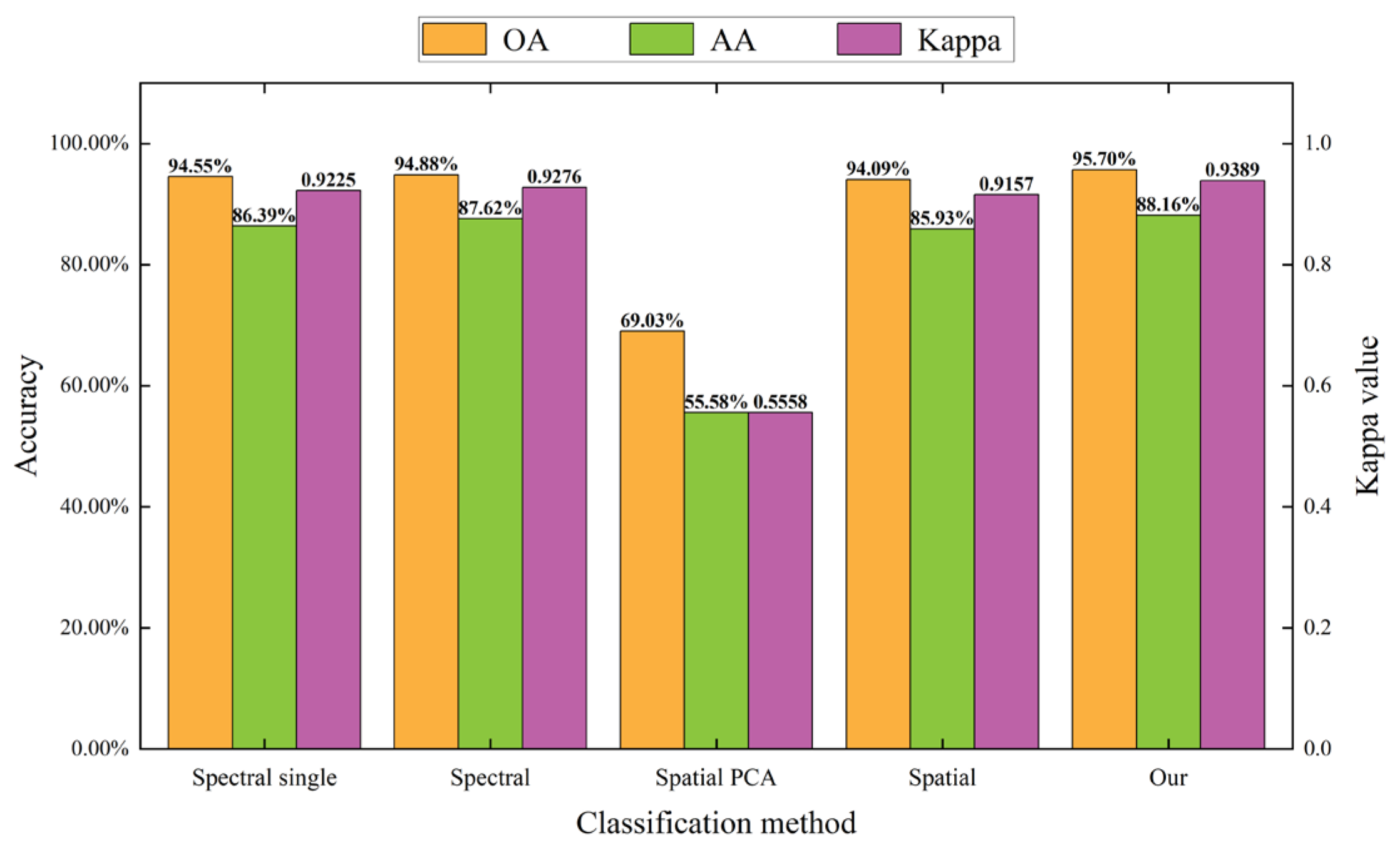
In this study, a series of comparative experiments were conducted to discuss the importance of combining spatial–spectral information in the classification of spectral branch, spatial branch, and double-branch network structures.In the spectral branch, the 3D convolution operation was changed to a 1D convolution operation, the input data was changed to the spectral information of the pixels to be classified, excluding the spectral information of their neighboring pixels, and other operations remained unchanged. Specifically, only the spectral information of pixels to be classified was considered in the spectral branch, and no spatial information was included. The spectral branch was to classify the tree species on the three datasets. For the TEF dataset, when the input of the spectral branch was only the spectral information of pixels to be classified (“Spectral single” in Figure 8), the OA value was 84.92%, and the AA value was 76.96%. However, when the spectral information of other pixels in the neighborhood was added (“Spectral” in Figure 8), the obtained OA value increased to 91.82% (an improvement of 6.9 percentage points), and the AA value increased to 87.87% (an improvement of 10.91 percentage points). Similar results were obtained for the Tiegang Reservoir and the **ongan New Area datasets, with improvements in OA of 0.33% and 6.74%, respectively, when the spatial information was added to the spectral branch. The above experiments demonstrate the advantage of joint spatial–spectral information in the spectral branch. An individual tree generally occupies multiple pixels in airborne hyperspectral images with high spatial resolution. Therefore, the spectral information of pixels to be classified cannot be considered only when extracting features using the spectral branch, ignoring its spatial dependence with neighboring pixels. Reasonable use of the neighborhood information of pixels is helpful in improving the classification accuracy.When using spatial information to classify hyperspectral tree species, the conventional method is first to reduce the dimension of the hyperspectral image, and then extract the spatial information of pixels from the data after dimensionality reduction to classify tree species. Following this approach, the input data of the spatial branch was modified to be the first three principal components data after PCA dimensionality reduction, and other operations remained unchanged. Specifically, the spatial information of pixels was mainly utilized in the spatial branch for classification. For the TEF dataset, when the input data of the spatial branch was the data after PCA dimensionality reduction (“Spatial PCA” in Figure 8), the obtained OA value was only 69.64%, and the AA value was 53.17%. However, when all of the original band information was selected to be input into the spatial branch (“Spatial” in Figure 8), the obtained OA value increased to 89.45% (an improvement of 19.81 percentage points), and the AA value increased to 84.74% (an improvement of 31.57 percentage points). Similar results were obtained with the other two datasets. When the input data of the spatial branch was the original band information, the OA values were improved by 25.06% and 7.65%, respectively, and the classification performance was better than the data after PCA reduction. During the process of PCA dimensionality reduction in hyperspectral data, although the spatial information of pixels will be retained, a certain amount of spectral information will be lost in the dimensionality reduction process. In contrast, the proposed method selects all of the original band information to be put into the network in the spatial branch, avoiding the loss of spectral information. The above experiments demonstrate the advantage of joint spatial–spectral information in the spatial branch.Although the spectral branch and the spatial branch in this study both make use of the spatial–spectral information of hyperspectral data, the focus of feature extraction for the spectral branch and the spatial branch is different; the spectral branch focuses on extracting spectral features using a 3D-CNN (with convolution kernel of (1, 1, 7)) and the spatial branch focuses on extracting spatial features using a 2D-CNN (with convolution kernel of (3, 3)). Using only a single branch may not be able to utilize the advantages of the hyperspectral image fully. Therefore, a double-branch network was designed to fuse the two branches for tree species classification, which further utilizes spatial–spectral information. Taking the TEF dataset as an example, the proposed method achieved classification accuracy with an OA value of 93.31% and an AA value of 90.89%. Compared to the spectral branch (“Spectral” in Figure 8), there was an improvement of 1.49 percentage points in OA and 3.02 percentage points in AA. Compared to the spatial branch (“Spatial” in Figure 8), there was an improvement of 3.86 percentage points in OA and 6.15 percentage points in AA. Similar results were obtained for the other two tree species datasets. For the Tiegang Reservoir dataset, the proposed method outperforms the spectral branch (“Spectral” in Figure 9) by 0.82 percentage points and the spatial branch (“Spatial” in Figure 9) by 1.61 percentage points in terms of OA value. For the **ongan New Area dataset, the proposed method outperforms the spectral branch (“Spectral” in Figure 10) by 1.48 percentage points and the spatial branch (“Spatial” in Figure 10) by 2.77 percentage points in terms of OA value. The above experiments demonstrate the advantages of the double-branch network in hyperspectral tree species classification. These findings are consistent with the experimental results obtained by Ma et al. [42] and Li et al. [48]. In practical tree species classification applications, due to the complexity and similarity of tree canopy structure, it is difficult to obtain ideal tree species classification results by simply using the spectral information or spatial structure of trees. The method proposed in this study fully utilizes the spectral and spatial information of trees, which is conducive to improving the accuracy of tree species classification in hyperspectral images.5.2. The Effectiveness of the SimAM Attention Mechanism
In order to analyze the effect of the SimAM attention mechanism on tree species classification, the ablation experiment of the attention mechanism was conducted, that is, the classification results of tree species with and without the attention mechanism network were compared. The comparison results of the three datasets are shown in Table 7. For the TEF dataset, the inclusion of the SimAM attention mechanism in the network resulted in an improvement of 1.29 percentage points in OA and 2.29 percentage points in AA. Similarly, the OA values obtained in the Tiegang Reservoir and the **ongan New Area datasets improved by 0.6% and 1.04%, respectively. These results prove the effectiveness of introducing the SimAM attention mechanism into our proposed method. The attention mechanism can extract important features by assigning different weights to each part of the feature maps, thus effectively improving the classification accuracy of tree species.5.3. The Influence of Shallow Features on Tree Species Classification
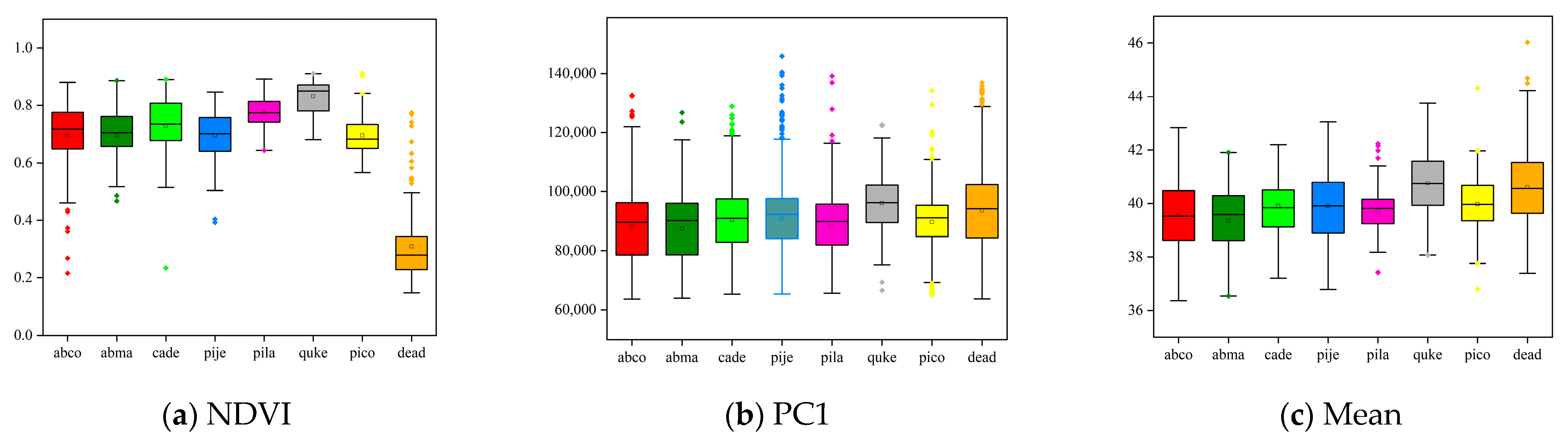
In this study, we used the neural network to extract deep features of data for tree species classification. However, in previous studies, many scholars used artificially extracted shallow features for classification. Figure 11 illustrates the shallow feature differences between the various tree species. As in NDVI, there are significant differences between the “Dead tree” category and other tree species. So, whether adding shallow features (Vegetation Index, PCA principal component, etc.) to the neural network will improve the classification results needs to be further verified. Therefore, we designed two different schemes. One way is to add shallow features to the head of the neural network, as shown in Figure 12a. First, the shallow features are extracted within a neighborhood (9 × 9) of pixels, then they are merged with the corresponding raw spatial–spectral information, and finally, the merged features are inputted into the neural network for classification. Another way is to add shallow features at the end of the neural networks, as shown in Figure 12b. First, the raw spatial–spectral information of pixels is inputted into the network to generate corresponding deep features, then the shallow features of pixels are merged with the extracted deep features, and finally, the two features are further fused through the fully connected layer to complete the classification.We used the input features of traditional machine learning methods (SVM and RF) as shallow features and conducted experiments on three datasets. The classification results obtained are shown in Figure 13. In the three datasets, whether at the head or end of the networks, adding shallow features did not significantly improve the classification accuracy and even showed a decrease. The result is consistent with the findings of Nezami et al. [51], who added Canopy Height Model (CHM) features to the networks for classification and showed that adding CHM did not improve the classification accuracy in most cases. The reason for this phenomenon may be that the relevant information needed to separate the tree species is already contained by deep features, while shallow features are low-level features of images. If too many shallow features are added to the neural networks, it will interfere with the neural network’s learning of the higher-level features, thus affecting the classification accuracy. Combining shallow features with spectral features from hyperspectral data as inputs to the neural network may also lead to feature redundancy and increase the number of model parameters, resulting in overfitting of the model and negatively affecting the performance of the neural networks.5.4. T-SNE Visualization
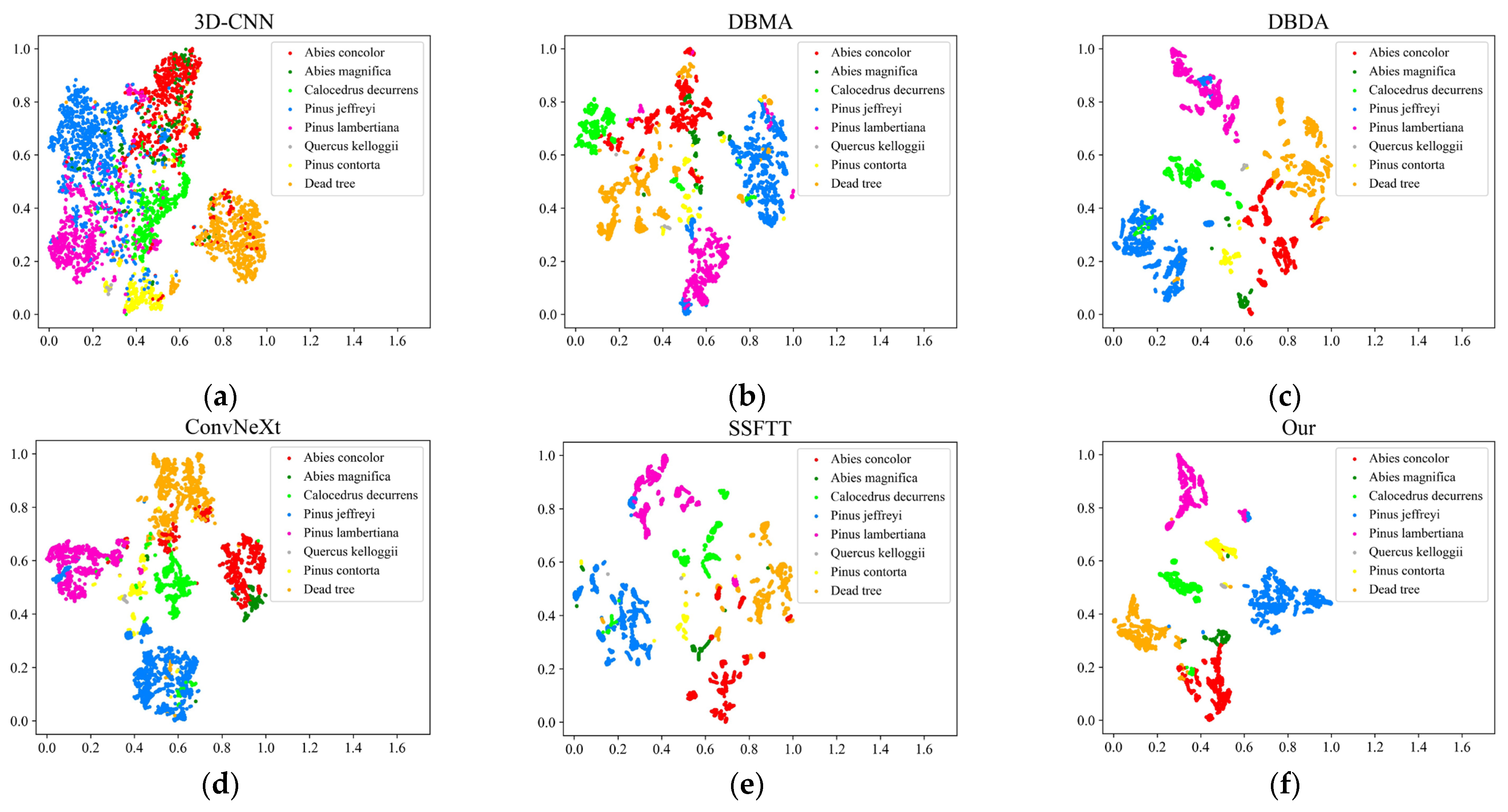
The T-distributed Stochastic Neighbor Embedding (T-SNE) algorithm is currently one of the most commonly employed techniques for data dimensionality reduction and visualization, which can reduce high-dimensional data to two-dimensional or three-dimensional data for visualization, and then can intuitively show the effect of tree species classification. In this study, the T-SNE algorithm was used to visualize the features extracted by the neural network. The visualization results obtained from the three datasets are shown in Figure 14, Figure 15 and Figure 16. For the TEF dataset, it can be seen that the features extracted using the 3D-CNN method are more dispersed, and there is more mixing between the categories compared to other classification methods, which leads to lower classification accuracy. The phenomenon of spectral variability within the same object occurs during the imaging process of targets by hyperspectral sensors due to factors such as the influence of tree growth environment and individual tree position. For instance, Calocedrus decurrens and Pinus contorta are divided into multiple clusters in DBMA and DBDA. Although these two methods achieve high overall classification accuracy, they cannot solve the phenomenon of spectral variability within the same object. The ConvNeXt and the proposed method alleviate this phenomenon to some extent, in which the trees of the same class are basically grouped into a cluster. The boundaries between each category of ConvNeXt are clear, but the mixing phenomenon between various categories is more serious, such as the mixing between Abies concolor and Abies magnifica, Pinus jeffreyi, and Pinus lambertiana. From the visualization results of the method proposed in this study, it can be seen that the boundaries between the categories are clear, and there is less mixing between the categories, which explains why the method achieves the highest accuracy. The visualization effects obtained from the Tiegang reservoir and the **ongan New Area datasets are similar to those obtained from the TEF dataset, that is, the proposed method performs best in T-SNE visualization compared with other methods, with clear classification boundaries among tree species and fewer misclassified pixels.5.5. Robustness Assessment
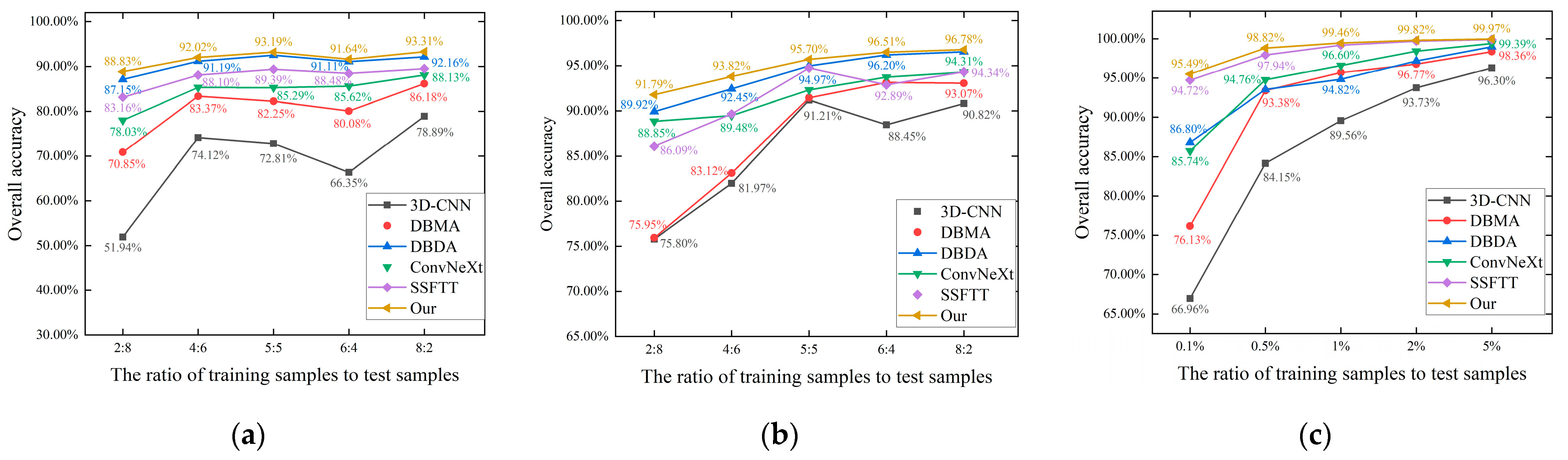
Deep learning is a data-driven algorithm that relies on high-quality labeled datasets. The number or proportion of training samples is one of the important factors affecting classification accuracy. In this study, deep learning methods were trained with different proportions of training samples to verify the robustness of the proposed method. Specifically, the ratios of training sets and test sets selected for the TEF and the Tiegang Reservoir datasets were 2:8, 4:6, 5:5, 6:4, and 8:2, respectively. The training sets selected for the **ongan New Area dataset were 0.1%, 0.5%, 1%, 2%, and 5% of the entire sample set, respectively, and the test set was unified into 5% of the sample set. The classification results obtained are shown in Figure 17.It can be observed that different proportions of training samples yield different classification results. As expected in this study, in most cases, the performance of the network model improves as the proportion of training samples increases. The performance gap between different models will decrease with the increase in the proportion of training samples. The most obvious is the **ongan New Area dataset. When the proportion of training samples is 0.1%, the performance gap between the 3D-CNN and the proposed method is as high as 28.53 percentage points. However, as the proportion of training samples reaches 5%, the performance gap narrows to 3.67 percentage points. In addition, the proposed method achieves the highest accuracy with different proportions of training samples in all three datasets. In the **ongan New Area dataset, the classification accuracy obtained using the proposed method is as high as 99.97% when the proportion of training samples is 5%. Compared with other methods, the classification performance of the method in this study is more stable under different proportions of training samples, and the classification accuracy does not change drastically with different proportions of training samples, which indicates that the model is robust to changes in the training data.The proposed method exhibits commendable performance even with limited training samples. Specifically, the classification accuracy obtained using the proposed method on the TEF dataset and the Tiegang Reservoir dataset is 88.83% and 91.79%, respectively, when the ratio of the training set to the test set is 2:8. For the **ongan New Area dataset, when the proportion of the training set is 0.1% of the sample set, the classification accuracy obtained is 95.49%, which is much better than the performance of other models. During the actual collection of tree species samples, obtaining a large number of samples is challenging due to factors such as the complexity and limited accessibility of forest areas. The difficulties and high costs associated with sample acquisition make it impractical to gather a substantial dataset. However, the proposed method achieves a high classification performance even with limited training samples, thereby saving time and reducing costs. This approach proves to be suitable for scenarios with limited sample availability.6. Conclusions
In this study, we combine the ideas of the attention mechanism and double-branch network structure to propose a double-branch spatial–spectral joint deep learning network for airborne hyperspectral tree species classification. Compared with other classification methods, the network shows better robustness in three tree species datasets. Experimental results are shown the following:- 1.
- In hyperspectral tree species classification, deep learning methods are better than traditional machine learning methods (SVM and RF) in distinguishing tree species, and the method proposed in this study achieved the highest classification accuracy in all three study areas. The OA value, AA value, and Kappa coefficient in the TEF dataset were 93.31%, 90.89%, and 0.9183, respectively. The OA value, AA value, and Kappa coefficient in the Tiegang reservoir dataset were 95.7%, 88.16%, and 0.9389, respectively. The OA value, AA value, and Kappa coefficient in the **ongan New Area dataset were 98.82%, 98.04%, and 0.9843, respectively.
- 2.
- Using only the spectral or spatial information of pixels cannot fully utilize the advantages of hyperspectral images, and the combined spectral and spatial information can help to improve the accuracy of tree species classification. The double-branch network structure is better than the single-branch network in terms of tree species classification performance. Furthermore, the SimAM attention mechanism can make the network pay more attention to important features and then improve the network classification performance, which proves the effectiveness of the SimAM attention mechanism in high-precision tree species classification in forest areas.
- 3.
- The proposed method performs best in T-SNE visualization, with clear classification boundaries between tree species and fewer misclassified pixels. The method obtains the highest accuracy under different training sample proportions, and good classification performance can be obtained even under the lowest training sample proportions. Moreover, the classification accuracy does not change drastically with different training sample proportions, which are somewhat stable.
The proposed network fully utilizes the spectral and spatial information of hyperspectral images to realize the high-precision classification of forest tree species, which has a broad application prospect in forest resources investigation. However, the method has limitations in limited samples classification and crown level classification. In the future, we will investigate semi-supervised classification algorithms to solve the case of few-shot samples based on this method. In addition, trees have unique properties, the same tree contains multiple pixels in high-resolution images from airborne or unmanned aerial vehicles (UAV). Therefore, tree species classification at the crown level may help to improve the classification results. In subsequent experiments, we will conduct tree species classification studies based on the crown level.
Author Contributions
Funding
Data Availability Statement



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Code | Scientific Name | Abbreviation | Train Samples | Test Samples |
|---|---|---|---|---|
| 1 | Abies concolor | abco | 2323 | 593 |
| 2 | Abies magnifica | abma | 742 | 113 |
| 3 | Calocedrus decurrens | cade | 1452 | 403 |
| 4 | Pinus jeffreyi | pije | 3654 | 924 |
| 5 | Pinus lambertiana | pila | 2205 | 583 |
| 6 | Quercus kelloggii | quke | 96 | 14 |
| 7 | Pinus contorta | pico | 741 | 154 |
| 8 | Dead tree | dead | 2745 | 796 |
| Total | 13,958 | 3580 |
| Code | Scientific Name | Abbreviation | Train Samples | Test Samples |
|---|---|---|---|---|
| 1 | Glyptostrobus pensilis | glpe | 10,013 | 6581 |
| 2 | Cinnamomum camphora | cica | 53,577 | 49,912 |
| 3 | Eucalyptus robusta Smith | euro | 14006 | 7868 |
| 4 | Ficus altissima | fial | 1783 | 3990 |
| 5 | Platycladus orientalis | plor | 19,287 | 10,021 |
| 6 | Ficus microcarpa | fimi | 10,226 | 6997 |
| 7 | Castanopsis hystrix | cahy | 9627 | 14,518 |
| Total | 118,519 | 99,887 |
| Code | Scientific Name | Abbreviation | Train Samples | Test Samples |
|---|---|---|---|---|
| 1 | Acer negundo | acne | 1128 | 11282 |
| 2 | Salix babylonica | saba | 903 | 9038 |
| 3 | Ulmus pumila | ulpu | 76 | 767 |
| 4 | Sophora japonica | soja | 2377 | 23,779 |
| 5 | Fraxinus chinensis | frch | 846 | 8467 |
| 6 | Koelreuteria paniculata | kopa | 116 | 1165 |
| 7 | Robinia pseudoacacia | rops | 28 | 280 |
| 8 | Pyrus sorotina | pyso | 5132 | 51,325 |
| 9 | Populus simonii | posi | 455 | 4553 |
| 10 | Amygdalus persica | ampe | 327 | 3275 |
| 11 | Other | other | 6987 | 69,915 |
| Total | 18,375 | 183,846 |
| Species | SVM | RF | 3D-CNN | DBMA | DBDA | ConvNeXt | SSFTT | Our |
|---|---|---|---|---|---|---|---|---|
| abco | 39.12% | 66.12% | 73.33% | 79.03% | 87.07% | 78.83% | 82.20% | 88.40% |
| abma | 7.11% | 14.91% | 25.29% | 51.26% | 85.24% | 64.90% | 76.14% | 88.08% |
| cade | 20.02% | 60.09% | 78.38% | 86.46% | 92.30% | 89.42% | 90.21% | 93.76% |
| pije | 48.04% | 82.34% | 84.73% | 94.08% | 96.13% | 95.15% | 96.05% | 97.40% |
| pila | 34.23% | 83.10% | 85.65% | 93.07% | 99.43% | 93.63% | 95.26% | 98.87% |
| quke | 12.68% | 42.11% | 53.12% | 48.62% | 76.72% | 84.63% | 68.51% | 80.17% |
| pico | 14.64% | 47.07% | 70.58% | 82.19% | 89.47% | 87.96% | 89.34% | 90.94% |
| dead | 83.30% | 86.63% | 85.33% | 85.01% | 87.59% | 86.71% | 85.40% | 89.53% |
| OA | 44.65% | 73.18% | 78.89% | 86.18% | 92.16% | 88.13% | 89.52% | 93.31% |
| AA | 32.39% | 60.30% | 69.55% | 77.47% | 89.24% | 85.15% | 85.39% | 90.89% |
| Kappa | 0.3158 | 0.6675 | 0.7418 | 0.8307 | 0.9043 | 0.8551 | 0.8721 | 0.9183 |
| Species | SVM | RF | 3D-CNN | DBMA | DBDA | ConvNeXt | SSFTT | Our |
|---|---|---|---|---|---|---|---|---|
| glpe | 25.59% | 76.77% | 77.06% | 83.39% | 98.32% | 91.08% | 99.21% | 98.54% |
| cica | 83.56% | 94.27% | 96.07% | 95.34% | 97.99% | 98.22% | 97.72% | 98.34% |
| euro | 65.06% | 89.10% | 96.88% | 96.90% | 96.92% | 97.18% | 96.84% | 97.65% |
| fial | 2.48% | 4.30% | 14.25% | 11.92% | 19.09% | 4.41% | 19.14% | 24.40% |
| plor | 63.29% | 86.59% | 96.02% | 94.66% | 98.79% | 92.45% | 98.08% | 99.58% |
| fimi | 35.20% | 66.10% | 89.54% | 91.07% | 98.05% | 84.05% | 97.86% | 98.97% |
| cahy | 50.16% | 86.82% | 96.49% | 98.60% | 98.73% | 98.01% | 98.44% | 99.64% |
| OA | 64.77% | 85.29% | 91.21% | 91.45% | 94.97% | 92.32% | 94.76% | 95.7% |
| AA | 46.48% | 71.99% | 80.9% | 81.70% | 86.84% | 80.77% | 86.75% | 88.16% |
| Kappa | 0.4709 | 0.7874 | 0.875 | 0.8791 | 0.9284 | 0.8900 | 0.9255 | 0.9389 |
| Species | SVM | RF | 3D-CNN | DBMA | DBDA | ConvNeXt | SSFTT | Our |
|---|---|---|---|---|---|---|---|---|
| acne | 55.27% | 62.28% | 76.54% | 87.58% | 84.32% | 90.13% | 96.06% | 98.64% |
| saba | 53.58% | 66.58% | 74.93% | 93.40% | 93.86% | 94.19% | 98.02% | 99.04% |
| ulpu | 17.58% | 45.44% | 75.83% | 89.31% | 78.59% | 94.26% | 97.26% | 99.43% |
| soja | 62.91% | 61.12% | 80.93% | 94.91% | 91.10% | 94.34% | 99.04% | 98.99% |
| frch | 45.29% | 41.97% | 78.05% | 94.45% | 97.99% | 93.81% | 98.81% | 99.49% |
| kopa | 63.77% | 76.99% | 82.63% | 95.93% | 95.45% | 93.39% | 99.83% | 99.88% |
| rops | 1.30% | 0.00% | 1.43% | 27.57% | 0.00% | 12.86% | 66.43% | 95.29% |
| pyso | 72.37% | 84.98% | 85.80% | 93.25% | 95.84% | 95.64% | 98.39% | 98.86% |
| posi | 30.66% | 43.27% | 61.52% | 81.66% | 86.51% | 81.75% | 89.46% | 93.33% |
| ampe | 26.83% | 35.35% | 53.42% | 84.06% | 81.40% | 87.85% | 95.66% | 96.43% |
| other | 79.04% | 85.61% | 90.55% | 95.22% | 95.07% | 96.73% | 98.19% | 99.11% |
| OA | 68.22% | 75.59% | 84.15% | 93.38% | 93.52% | 94.76% | 97.94% | 98.82% |
| AA | 46.24% | 54.87% | 69.24% | 85.21% | 81.83% | 84.99% | 94.29% | 98.04% |
| Kappa | 0.5768 | 0.6699 | 0.7886 | 0.9119 | 0.9137 | 0.9301 | 0.9727 | 0.9843 |
| Dataset Name | Method | OA Value | AA Value | Kappa Value |
|---|---|---|---|---|
| TEF dataset | No Attention | 92.02% | 88.6% | 0.9025 |
| Attention | 93.31% | 90.89% | 0.9183 | |
| Tiegang Reservoir dataset | No Attention | 95.1% | 87.35% | 0.9303 |
| Attention | 95.7% | 88.16% | 0.9389 | |
| **ongan New Area dataset | No Attention | 97.78% | 94.31% | 0.9705 |
| Attention | 98.82% | 98.04% | 0.9843 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, C.; Liu, Z.; Chen, Y.; Wang, S.; Liu, A. Tree Species Classification from Airborne Hyperspectral Images Using Spatial–Spectral Network. Remote Sens. 2023, 15, 5679. https://doi.org/10.3390/rs15245679
Hou C, Liu Z, Chen Y, Wang S, Liu A. Tree Species Classification from Airborne Hyperspectral Images Using Spatial–Spectral Network. Remote Sensing. 2023; 15(24):5679. https://doi.org/10.3390/rs15245679
Chicago/Turabian StyleHou, Chengchao, Zhengjun Liu, Yiming Chen, Shuo Wang, and Aixia Liu. 2023. "Tree Species Classification from Airborne Hyperspectral Images Using Spatial–Spectral Network" Remote Sensing 15, no. 24: 5679. https://doi.org/10.3390/rs15245679