1. Introduction
There are different factors that cause traffic accidents. Among the most common factors that increase the probability of their occurrence are the geometry of the road [
1], the climate of the area [
2], drunk drivers, and speeding [
3,
4]. These accidents can cause harm to the people involved and, although most of these present only material damage, each one affects people’s quality of life in terms of both traffic mobility and personal safety.
Thanks to technological advances, video cameras have become a resource for controlling and regulating traffic in urban areas. They make it possible to analyze and monitor the traffic flowing within the city [
5]. However, the number of cameras needed to perform these tasks has been increasing significantly over time, which makes control difficult if automation mechanisms are not implemented because the number of professionals needed to comply with all the points also increases. Several approaches have been proposed to automate tasks within the control and follow-up process. An example of this is a system based on video camera surveillance in traffic. Through these, it is possible to estimate the speeds and trajectories of the objects of interest [
6], with the objective of predicting and controlling the occurrence of traffic accidents in the area.
The scientific community has presented different approaches to detect traffic accidents [
7]. These include statistics-based methods [
8,
9,
10], social network data analysis [
11,
12], sensor data [
13,
14], machine learning, and deep learning [
15,
16,
17,
18]. These latest techniques have presented improvements in various fields of science, including video-based problem solving (video processing). Therefore, it is important to study these techniques in order to approach a solution to the detection and classification of traffic accidents based on video.
With the advent of convolutional layers in the domain of neural networks, better performance has been achieved in the solution of problems involving digital image processing [
19]. Deep learning techniques have shown high performance in a large number of problems, especially for image understanding and analysis [
20,
21]. These layers exploit the spatial relationship that the input data possess and that, due to the size of the information, it is not possible to achieve with dense neural networks [
22]. The use of convolutions on input data with a large number of features makes it possible, among other things, to avoid the problem of the curse of dimensionality. This is a very frequent problem when working with data with high complexity, such as images. Likewise, it is important to highlight that the use of several convolutional layers helps the extraction of relevant visual features within the same dataset, which defines the performance of the network [
23,
24,
25].
On the other hand, there are problems where the spatial relationship of the data is not a determining characteristic. In some problems, the temporal relationship that the data may have is of greater importance. This is because there are events that depend on past and/or future events, that is, on a context of the event in time in order to understand the real event. This is why a new deep learning model has emerged: recurrent neural networks. These networks have a similar architecture to dense artificial neural networks but differ in that at least one neuron has a connection to itself. This allows them to be able to remember what has been previously processed, i.e., it gives them the ability to store information over periods of time (data memory). They specialize in finding the temporal relationships that a set of data may have. Such networks are used to solve problems such as rate-of-change prediction [
26], text translation [
27], and natural language processing [
28], among others. The data processing in these neurons has a higher complexity than the processing performed from a traditional neuron. In addition, these have been improved over the years. One of the most relevant changes was the possibility that the cell can store short and long term memory, called long short-term memory neurons (LSTM). These networks have presented improvements in several problems with respect to past models. Among these are travel time prediction problems [
29], language understanding [
30], and natural language processing [
31].
However, the analysis of video scenes is not a problem that can be solved using one of the two models mentioned above. This is because a video presents both a spatial and a temporal relationship in its content. Therefore, the scientific community has presented several architectures that use both deep learning layers: convolutional layers and recurrent layers [
32,
33]. Some of the advances they have achieved using these types of architectures are emotion recognition [
33], estimation of a person’s posture [
34], analysis of basketball videos for the automation of tasks such as the score of each team [
35], and action recognition [
36].
Because of this, a method capable of solving the traffic accident detection problem is proposed. However, the process of detecting traffic accidents is a task that involves a lot of processing and, for this reason, these tasks present many difficulties. The occurrence of a road accident is an event capable of occurring in multiple spatio-temporal combinations. This leaves a large domain of diverse distributions of data to be classified as an accident, which makes it difficult to solve the problem. Similarly, the classification of an accident is a complex problem due to the temporal implications it may present. Therefore, we seek to improve the performance of current approaches with the design of a method capable of detecting traffic accidents through video analysis using deep learning techniques.
The rest of the document is organized as follows:
Section 2 describes the previous work carried out.
Section 3 describes the proposed method to specify the architecture of the deep neural network proposed in the detection of traffic accidents.
Section 4 shows the results and the experiments for the determination of the hyper-parameters of the proposed architecture.
Section 5 establishes a discussion regarding bias, generalizability, and some ethical considerations. Finally,
Section 6 establishes the main conclusions, as well as future works.
2. Background
Different authors have proposed various techniques and methods for the detection or classification of accidents. Three study groups are presented based on the taxonomy of the solutions proposed in [
7].
In the first group are those works that implement solutions with methods and algorithms based on the theory of vehicular flow and statistics. One of them uses the theory of vehicular flow with wireless communication between vehicles to give alerts on accident sites or road obstructions [
37]. Other solutions use probability distributions, using the Poisson statistical distribution [
10], based on the analysis of the relationships between heavy vehicle accidents, traffic, and road geometry [
8], based on linear regression models with the Poisson distribution [
38] to solve the problem.
The next group is based on methods related to machine learning and statistics [
7,
9,
39,
40]. Many of these have presented solutions using artificial neural networks [
41,
42,
43], support vector machines [
16,
44], probabilistic neural networks [
45], autoencoders [
46], block clustering [
47], Random Forest [
15], pattern recognition [
18], image processing techniques [
48] and the Hidden Markov Model [
49], among others. These approaches perform well, and are able to partially deal with an unbalanced dataset.
The last group is oriented to the amount of data collected by all the technology currently available in the community. Among them can be found data from social networks [
12,
17,
50,
51], data collected from sensors of a smartphone [
13], structured data [
52,
53], data detected from video cameras [
14,
54,
55], and traffic sensor data [
56]. These datasets are widely used by deep learning, hybrid, and extreme learning methods. However, this group has the highest computational expense, which limits its use in various cases.
In terms of the video in which the accident is detected, there are several types. Among them are cameras inside the vehicle (first-person view), cameras located at intersections within cities, and cameras located on highways. In [
57], an unsupervised model for the detection of accidents in videos obtained with first-person vision is proposed. In this, vehicles are detected and located on the scene by calculating a Bounding-Box for each one. Then the future position of the vehicle is predicted with the help of some calculated attributes to check if there is a collision between boxes. This approach can present false alarms with the auto-occlusion of objects of interest in the video. Using the same type of video with first-person vision, [
40] presents a method for the detection of traffic accidents consisting of three steps: vehicle detection, tracking, and attribute extraction. A mixed Gaussian model is used for the detection of the moving vehicle and, by means of the mean displacement algorithm, the localized vehicle is tracked. Detection is determined by the repeated change of a vehicle’s attributes: change in position, acceleration, and direction. By defining a threshold for the sum of the three attributes, it is possible to detect if an accident has occurred at the scene. However, the proposed model shows a deficiency in the detection of the vehicle in cases where the climatic conditions are highly variable.
In order to anticipate traffic accidents in videos with first-person vision, [
58] proposes a model composed of spatial dynamic attention and a recurrent neural network. The first is in charge of learning to distribute a level of attention to the objects in the scene in each image of the video. This is in order to identify the objects of interest in the problem posed. The second, using short- and long-term memory cells, makes it possible to relate the signals that each object presents with the probability of an accident so that it is possible to anticipate the accident a few seconds in advance. In [
49] a method for the detection of traffic incidents through video is described. The authors explain that surveillance cameras used at intersections present problems if their data are used to track a vehicle. This is because, for the most part, the cameras are located at angles where there is a large amount of occlusion of the objects present. For the detection of accidents, the authors propose an algorithm based on the Hidden Markov Model. However, the method is limited to using a camera located at a high altitude, which limits the scalability of the implementation.
A matrix-based detection model is presented in [
59]. First, the authors divide each image of the video into small windows. With this, they are able to calculate two matrices: velocity vector and velocity magnitude. Using the matrices and data collected from both cases (accident and non-accident), they manage to train a model that differentiates the movements of the sub-spaces in a video segment in order to classify the example as a common event or accident. From video recordings of surveillance cameras in [
60], the authors describe an algorithm based on vehicle tracking for the detection of traffic accidents. The algorithm is made up of three parts: vehicle detection and extraction, moving vehicle characteristics extraction, and event detection. Four metrics are used as accident rates: acceleration, rate of change in position, rate of change in area, and rate of change in direction. By weighting these four variables, it is possible to detect whether or not an event occurred at the scene.
A different approach is presented in [
61]. The authors show that it is possible to detect an accident between two or more vehicles from the sudden change in their speed vector by building a general model of the flow of movement to automatically detect unforeseen changes in the speed of a vehicle. However, the proposed method only shows high performance on the main highways where there is a constant movement and speed of vehicles. It constitutes a limitation in the domain of application due to the complex and different spatial configurations in which an accident can occur, where regular movement or constant speeds are not expected characteristics.
A particular approach for detecting traffic accidents is to consider this as an anomaly within the sequence of a video. Detecting anomalies in the real world has been one of the main problems in the field of computer vision. In [
42], the authors present a model for detecting anomalies from a video. They perform a feature extraction using a neural network based on 3D convolution layers for each of the segments. These characteristics serve as input for a deep neural network model, which returns the anomaly score for each example. Finally, given the score obtained by each video segment, a binary classifier based on support vector machines is applied, which allows for distinguishing between the occurrence of an anomaly and a common event. In [
46], a model is presented to detect traffic accidents through video using the autoencoder’s deep learning architecture. Its framework is divided into two parts that run in parallel: object detection and anomaly detection. The first seeks to detect moving vehicles, track them, and calculate the intersection of the processed objects. The second seeks to exploit the information of the space‒time video to later be represented by an autoencoder and obtain the anomaly score. Since accident detection is based on the definition of a threshold, changing the threshold value will also change the performance of the model. This is why the authors conducted tests with different threshold values.
In [
43], a model based on two deep convolutional networks is proposed for the detection of accidents in traffic videos. The authors show that a video can be decomposed into two parts: a spatial component and a temporal component. The first is addressed to detect each vehicle on the scene together with its nearby region of accident probability, while the second is in charge of tracking the trajectory of each vehicle found in the video. An accident is detected when two objects collide.
In [
62], the authors present a dataset of videos of traffic accidents, together with a predictive model of occurrence. The authors employed a modification to the Faster R-CNN architecture. The modification was made to the pooling layers by implementing context mining. Similarly, in [
63], two models based on video analysis are proposed for the detection and classification of vehicles. The first uses a Gaussian method for background removal, plus a support vector machine as a classifier, while the second is based on an architecture named Faster RCNN, for the detection and classification of vehicles simultaneously.
In [
56], a video-based model is proposed for the detection of traffic accidents. The dataset used was collected by the authors through the YouTube platform. These data are made up of a total of 324 examples of training with six different types of collisions. Each category contains approximately 53 examples.
Recently, in [
64], an automated anomaly detection technique based on deep learning in pedestrian walkways (DLADT-PW) was described. This approach aims to recognize and categorize the dissimilar anomalies present in pedestrian walkways. The analysis is based only on information per frame and does not consider exploiting the natural time component in the input that is used, which is the video.
3. Method for Automatic Detection of Traffic Accidents
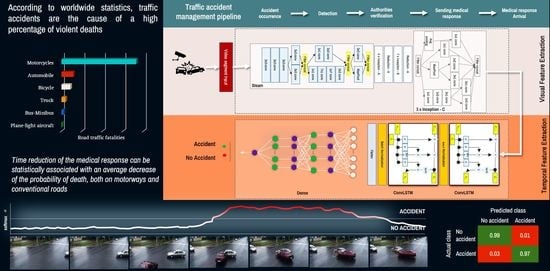
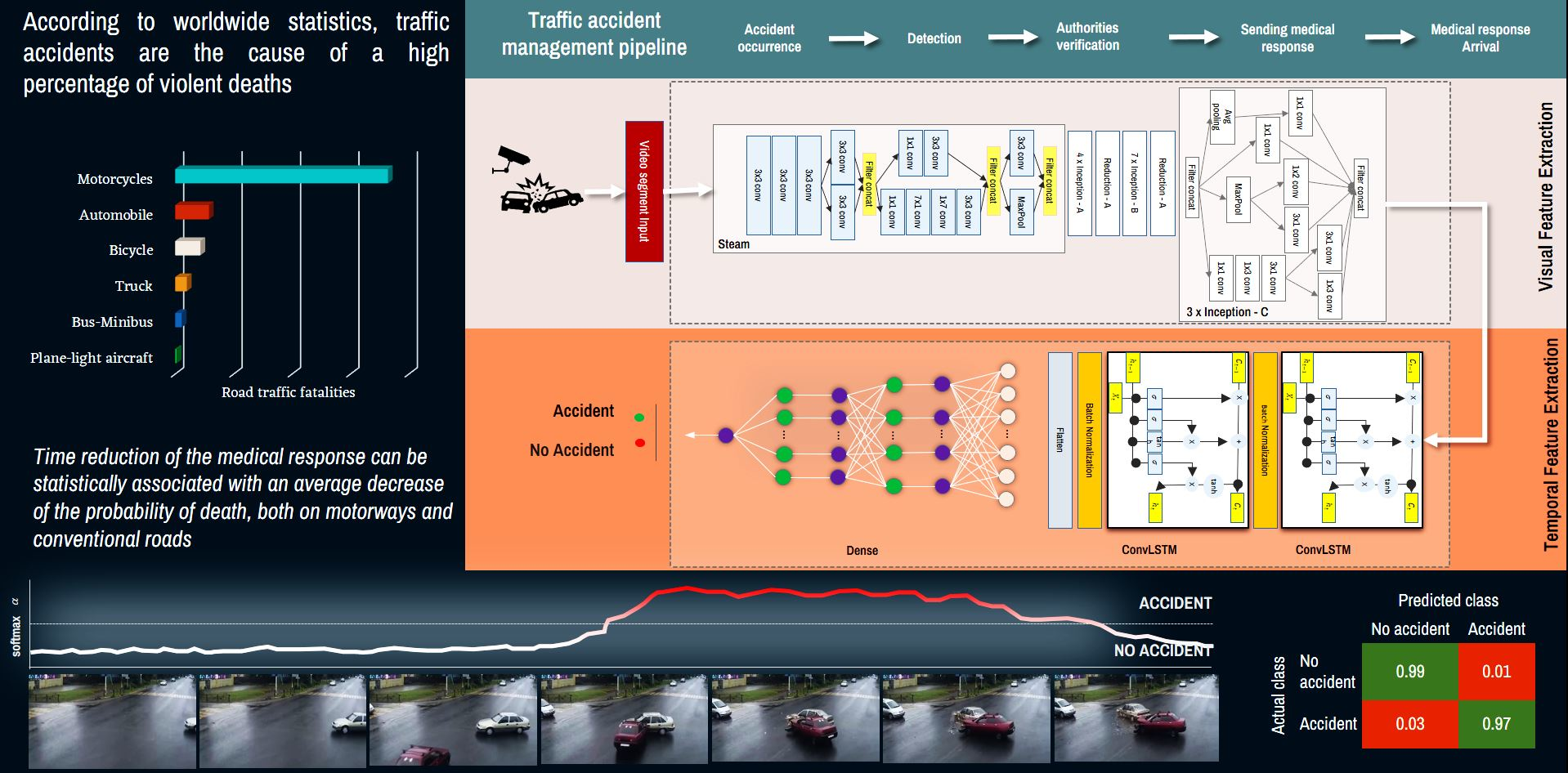
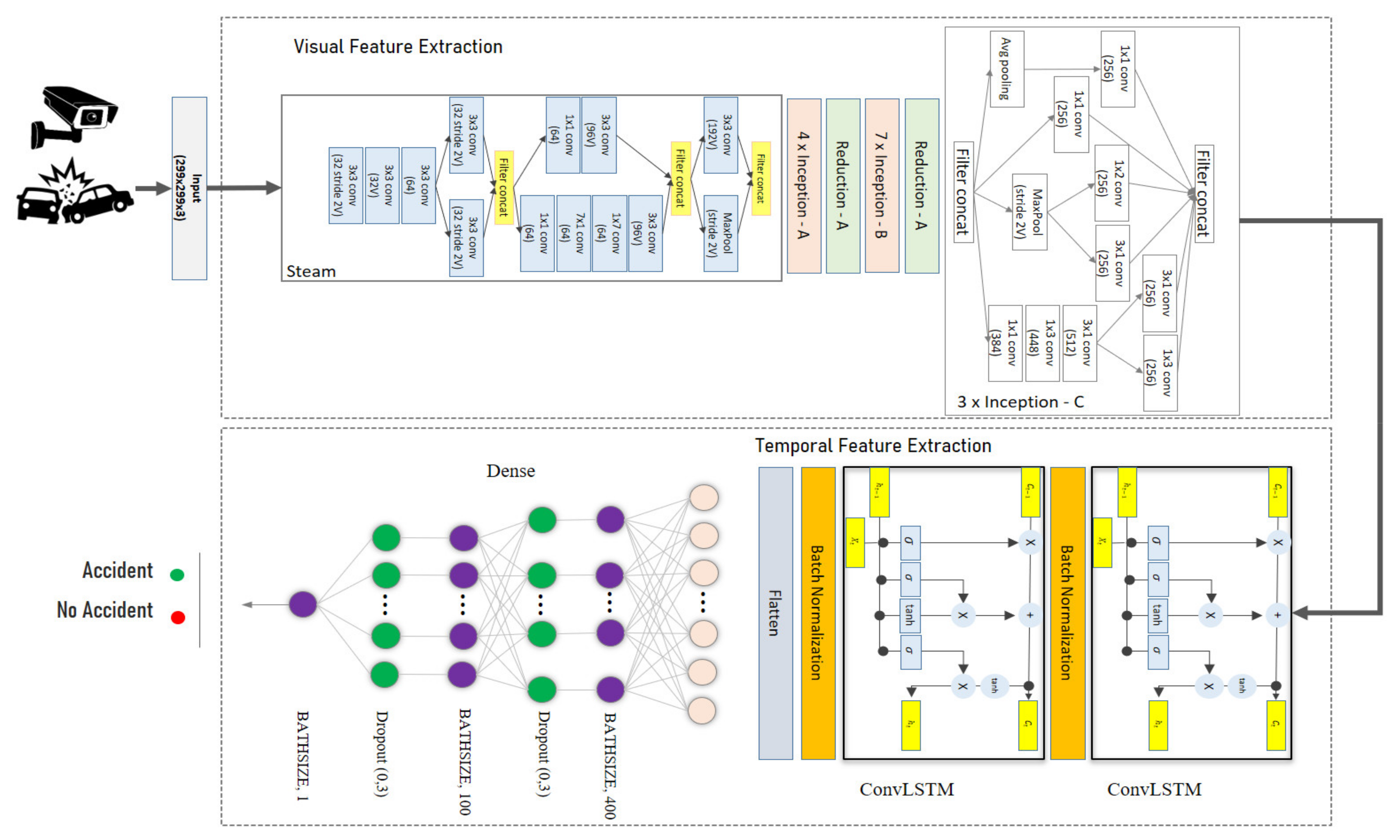
The proposed method is based on techniques used in video analytics. In particular, deep learning neural networks architectures trained to detect the occurrence of a traffic accident are used. Before describing the architecture, it was necessary to define the network input. Since a video must be processed, it is separated into segments. Therefore, the temporal segmentation of the video required a basic analysis to determine which was the most appropriate scheme to generate the segments, considering a tradeoff between the computational cost of processing the segment and the generation of enough visual characteristics to extract patterns that the network learned. Once the input was defined, the accident event was built as the occurrence in time of a set of visual patterns. For this, the architecture has two parts. The first one extracts a vector of visual characteristics using a modified Inception V4 architecture; this set of characteristics is processed by a recurrent component to extract the temporal component associated with the occurrence of the event.
Next, we describe the two stages: temporal video segmentation and automatic detection of traffic accidents.
3.1. Temporal Video Segmentation
Temporal video segmentation is a problem that has been studied for many years by the scientific community since it is the first step towards the development of more general solutions, such as scene understanding of videos [
65]. A video is a sequence of consecutive images with a particular order. When these images are viewed in the correct order and at a specific speed, it is possible to observe the animated event represented by the recorded video.
A video camera can capture, with the help of a mechanism, an event that is happening at the moment, in order to store, observe, and process it in the future. Using the same concept of a digital camera, a video camera makes it possible to capture a number of photographs per second, thus allowing the event that is occurring to be digitally recorded. These images, which represent the video, are known as frames. Video cameras allow recording at different numbers of frames per second (FPS). This means that the higher the number of FPS, the more fluid the movement of the objects on screen. The most commonly used FPS values are 30, 60, and 120 [
66].
Video segmentation can be divided into two categories: spatial and temporal. Spatial segmentation seeks to visually classify objects of interest in the video in order to spatially locate objects in different frames. This type of segmentation is very useful when tracking objects in a video [
67].
On the other hand, time segmentation seeks to solve a different problem. One of these is the reduction in the video time. This can be achieved by dividing the video into multiple fixed time windows in order to transform a long-duration video into a finite number of short-duration videos. However, there are also cases where it is not possible to divide the video into fixed time windows because it may contain multiple events in it, and, if a fixed window division is performed, it is possible that an event will be divided into different segments. In order to be able to discriminate between the multiple situations that the video describes, the scientific community has developed techniques to temporally segment this data, taking into account the scene change frame. This allows a single video to be divided into N temporal segments, where is the number of scenes that can be observed.
Traffic accidents are rare events of short duration. In order to be able to detect them correctly through a video, it is important to preprocess the original recording considering that the video (using a static surveillance camera) will contain many frames with a high similarity index. For this reason, several temporal video segmentation techniques are proposed in order to compare them with the results of the detector model.
Three techniques were used to increase the variety of the data segments. The first is based on the metric named the Structural Similarity Index Measure,
(Equation (1)), applied between consecutive frames in order to eliminate those that exceed an empirically defined threshold
. The threshold is arbitrarily set at a high value
, representing a high similarity of the frames, which implies no additional information for the analysis. With this, we could significantly reduce the number of similar frames in the video segment.
where
and
are two consecutive frames from the video segment, and
is the intensity mean of all the pixels from frame
. The
factor is the covariance between the pixel value from frame
and
, and
is the variance from frame
. The
and
.
is the dynamic range from pixel values (
),
and
. The next technique used consists of a comparison very similar to the previous one. However, this one uses pixel-to-pixel comparison (Equations (2) and (3)) on consecutive frames, thus eliminating those that exceed the empirically defined threshold (
).
where
and
are two consecutive frames of
rows,
columns, and
layers. Therefore,
is the pixel value from the
frame in the position
in layer
.
The last technique performs a selection using a fixed skip window. That is, a value is defined for , which represents the number of frames that must be eliminated before selecting the next candidate to form the segment. If is equal to 1, it means that the frames to be selected should be those with odd indices (1, 3, 5, 7, 9, …, etc.). All this continues until the maximum segment number is reached, for which the following values were defined: 10, 15, 30, 45, and 60.
3.2. Automatic Detection of Traffic Accidents
In order to interpret a video segment to detect whether an event occurs, the data must be exploited in two main ways: visually and temporally.
The convolutional-based architectures [
68] are the most important techniques for visual analysis of images. These are a significant improvement over traditional artificial neural networks in the performance of image classification solutions. However, convolutional layers do not solve all problems. One of the weaknesses of convolutional layers is that they are not good at extracting temporal features from data. Although convolutional layers are powerful in exploiting the spatial characteristics of the data, recurrent neural networks were designed to exploit the temporal characteristics of the data. Convolutional layers are able to process the data in such a way that the spatial information changes to a more abstract representation saving computational cost. Currently, these architectures are used as automatic extractors of image features due to their performance reducing the dimensionality of the input data. However, spatial data is not everything in a video.
Sequential data is of importance in understanding an event that happens over a time span. Recurrent neural networks perform better when processing a sequence over time compared to feed-forward artificial neural networks. There are solutions that use both architectures in order to improve performance in solving video comprehension problems [
69]. However, the scientific community has presented a design capable of exploiting both types of data: the Convolutional LSTM (ConvLSTM) layers. These are a special type of architecture where the cells follow the same operations as a Long Short-Term Memory neuron but differ in that the input operations are convolutions instead of basic arithmetic operations. This architecture has shown high performance in problems with video compression.
To solve the traffic accident detection problem, the first part of the architecture is designed as an automatic image feature extractor to process each frame of the video segment. Then, this new representation of the data is used as input data in an empirically designed recurrent neural network to extract temporal information from the input data. Finally, a dense artificial neural network block is used to perform the binary classification of detecting an accident, as shown in
Figure 1.
The proposed model consists of three parts: a spatial feature extractor, a temporal feature extractor, and a binary classifier. The first part uses an architecture named InceptionV4, proposed in [
70]. This model was trained with the ImageNet dataset, which showed high performance in solving this problem by classifying images among a thousand different categories. However, this pre-trained model does not show good results when detecting a traffic accident in images because the model was trained with a completely different task. Therefore, when applying transfer learning, it seeks to compensate for the acquisition of knowledge in a new task. For this reason, an adjustment is made to the model using a new dataset with examples of traffic accidents in images.
To obtain more information from video type data, it is necessary to know the temporal and the spatial features; therefore, it is required to use a model capable of extracting these kinds of characteristics. Therefore, a ConvLSTM layer-based neural network architecture is proposed that receives as input the feature vector computed by the adjusted InceptionV4 architecture.
Finally, it is necessary to detect whether the video segment contains a traffic accident. For this, a dense artificial neural network block using regularization methods is proposed so that the final model is able to generalize the solution.
5. Discussion
In relation to model bias, the model could be biased towards accidents involving vehicles. This verification is not trivial due to limitations of the validation dataset, which is composed of a majority of accidents involving vehicles. However, the feature extractor was trained considering different types of vehicles, including cars, trucks, and motorcycles but excluding pedestrians and cyclists where there are visible human interventions. Additionally, relating to weather conditions, the bias is present in diurnal accidents due to dataset limitations. There were not enough videos with rain or snow or at night, among other weather conditions.
Regarding the model’s generalization capacity, the model is independent of a particular camera-viewpoint, the structure of the street, or aspects such as vehicle density. We do not describe the technical parameters of the cameras because we used public video datasets for the model validation. However, an adequate analysis in this address will permit defining hardware limitations for a correct model operation. However, it is difficult to perform analysis at the level of device specification, mainly because obtaining a dataset that includes a large number of images from cameras with different lenses, acquisition sensors, and even spatial positions is impractical. In this context, separating or analyzing the effect of the camera parameters is almost impossible [
73]. However, Deep Learning models have the characteristic of being robust to small variations in their input. They require minimal preprocessing and do not need the selection of an extractor of specific characteristics [
74]. In this context, we consider that there are no significant camera parameters restrictions in the model due to the used datasets that include different cameras in multiple positions. Therefore, we assume that the model can operate correctly in the most popular devices used for vehicular traffic systems.
The feature extractor was trained with visual patterns associated with accidents that had already occurred, so the model cannot predict an accident, but it is capable of identifying visual patterns relating to the occurrence of an accident. The temporal feature extractor was trained to recognize the appearance in time of these visual patterns, which strengthens the accident identification only when based on visual patterns. We considered that it is not possible to predict in advance the occurrence of accidents with this configuration.
Addressing ethical considerations, the group of accidents involving pedestrians was not considered because the nature of the training in the fine-tuning process of the feature extractor model required images that included injured bodies. To include this category (pedestrians), consideration should be given to obtaining a representative group of images to avoid biases due to aspects such as age, height, or skin color.
6. Conclusions and Future Work
Pre-trained neural networks are not able to compute a vector with relevant features for very specific problems. Therefore, it is necessary to adjust the weights of these models using examples of the problem to be solved.
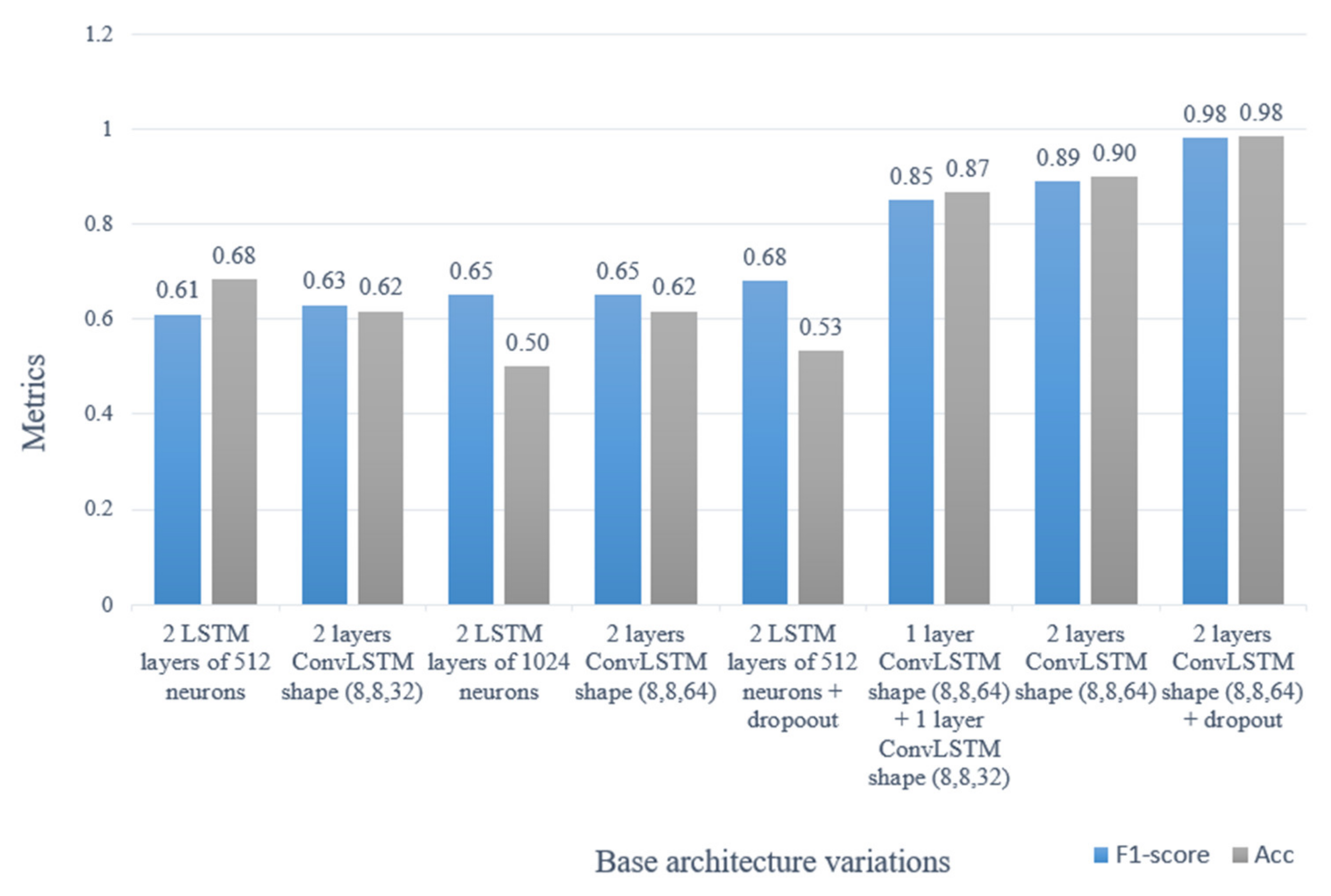
The technique that best represents a temporal segment of a traffic accident does not eliminate any data, because the similarity values between the segments of the techniques with frame selection present negligible differences between them, while the computational cost, processing time and accuracy in accident detection present better results by not conditioning the selection of frames to a metric.
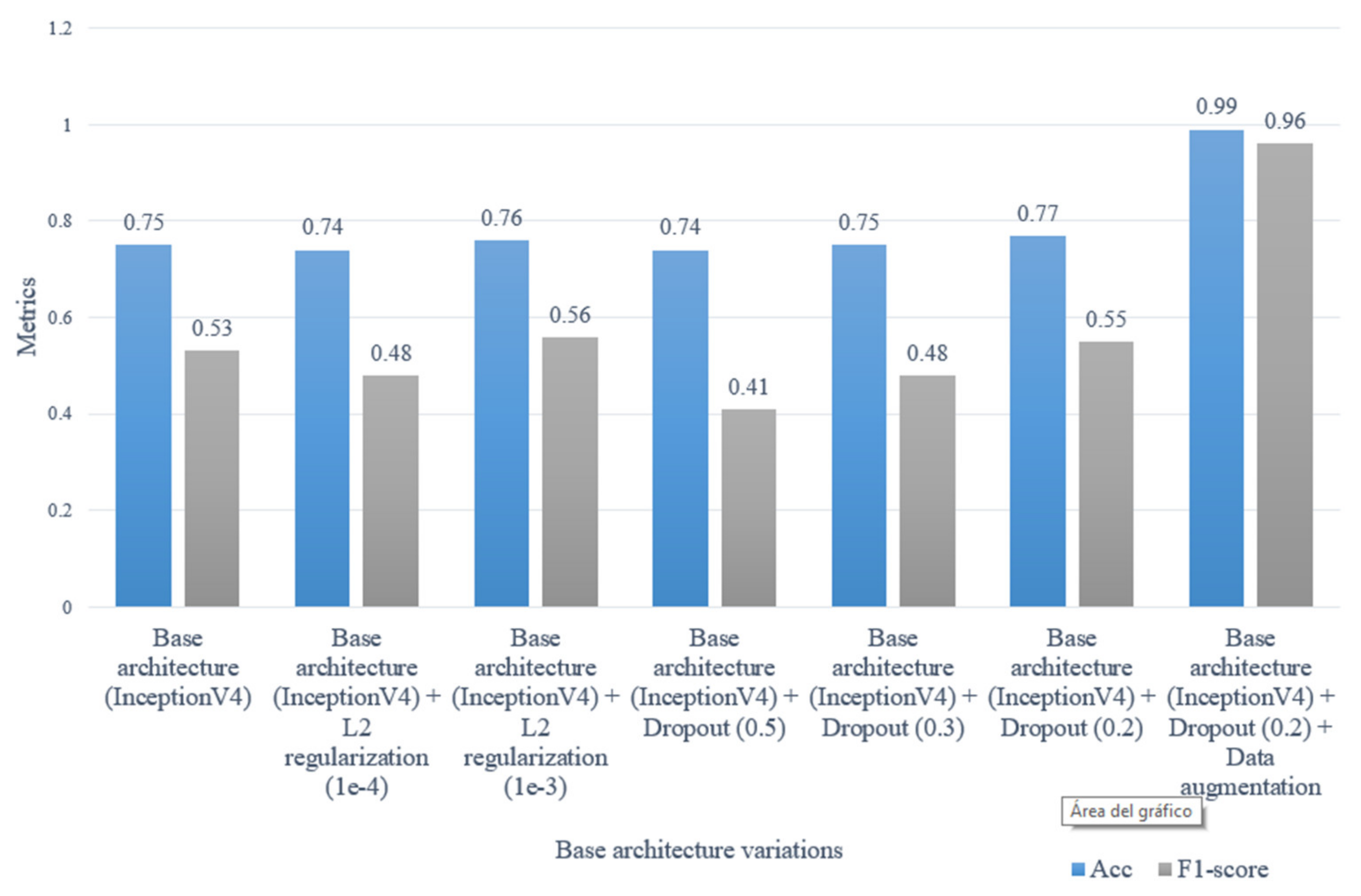
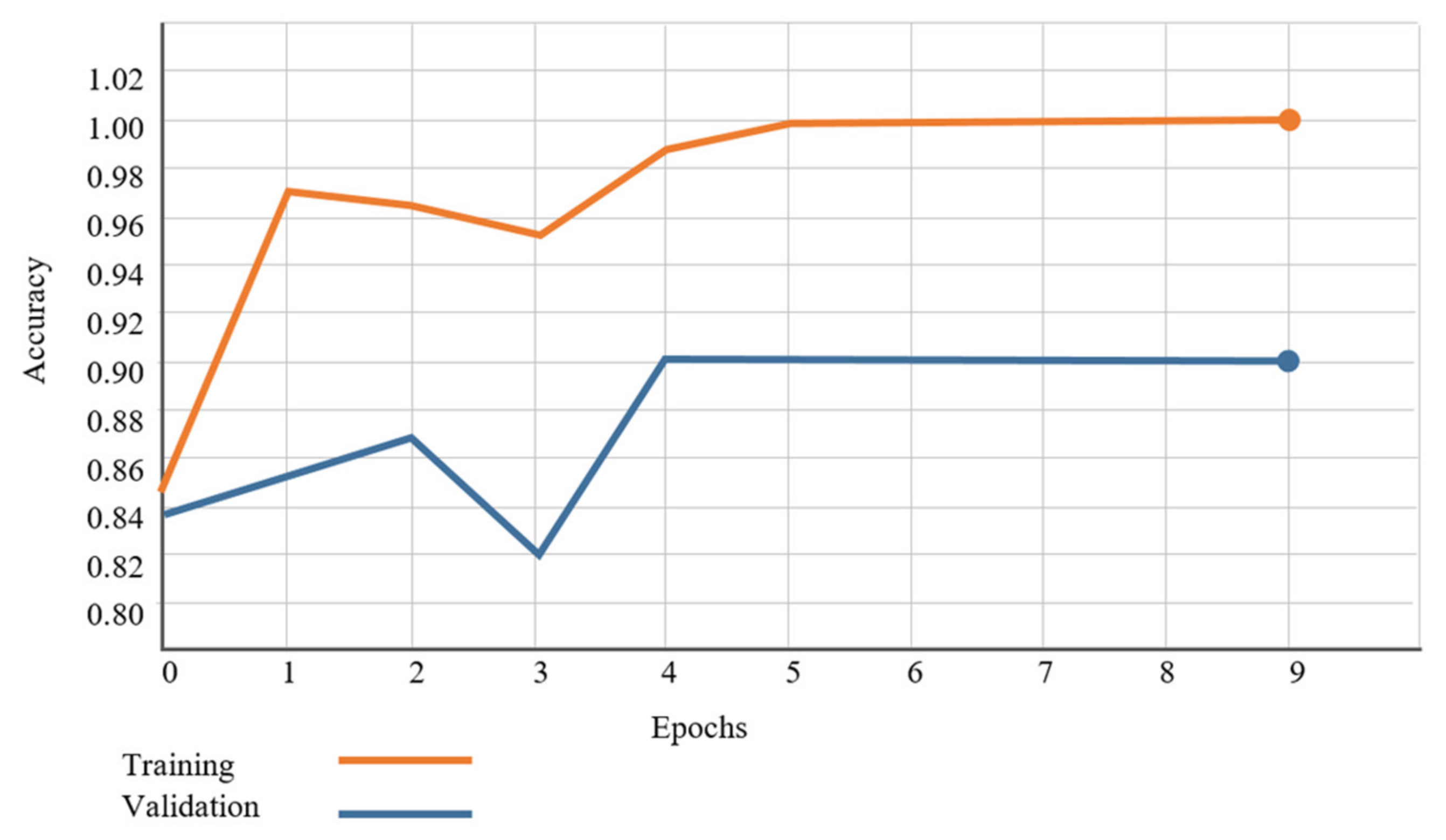
Artificial vision has made great advances in the understanding of video scenes. One of the best-performing techniques is artificial neural networks. Many of these models are based on architectures composed of convolutional layers and recurrent layers, in order to extract as much information as possible from the input data. The proposed method is based on this type of architecture and achieves a high performance when detecting traffic accidents in videos, achieving an F1 score of 0.98 and an accuracy of 98%.
The proposed model shows high performance for video traffic accident detection. However, due to the paucity of such datasets in the scientific community, the conditions under which the model works are limited. The solution is restricted to vehicular collisions, excluding motorcycles, bicycles, and pedestrians due to the negligible number of these types of examples available. In addition, the model has errors in determining accident segments with low illumination (such as nighttime videos) or low resolution and occlusion (low quality video cameras and locations).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}