
Deepfake Attacks: Generation, Detection, Datasets, Challenges, and Research Directions

Abstract
:1. Introduction
- A summary of the state-of-the art deepfake generation and detection techniques;
- An overview of fundamental deep learning architectures used as backbone in deepfake video detection models;
- A list of existing deepfake datasets contributing to the improvement of the performance, generalization and robustness of deepfake detection models;
- A discussion of the limitations of existing techniques, challenges, and research directions in the field of deepfake detection and mitigation.
2. Related Surveys
3. Deepfake Generation
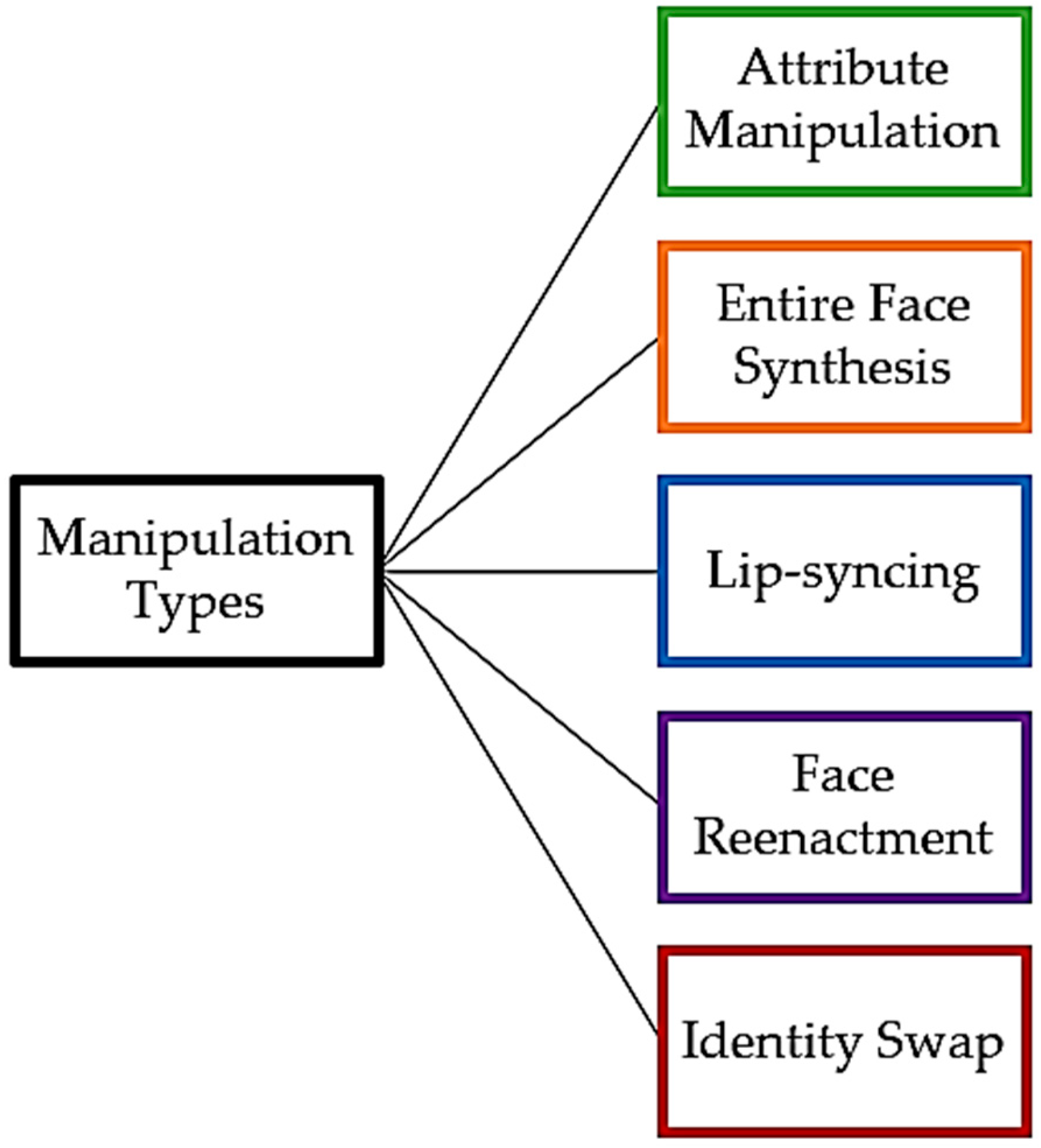
3.1. Deepfake Manipulation Types
3.2. Deepfake Generation Techniques
4. Deepfake Detection
4.1. Deepfake Detection Clues
4.1.1. Detection Based on Spatial Artifacts
4.1.8. Detection Based on Spatial-Temporal Features
4.2. Deep Learning Models for Deepfake Detection
5. Datasets
6. Challenges and Future Directions
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hancock, J.T.; Bailenson, J.N. The Social Impact of Deepfakes. Cyberpsychol. Behav. Soc. Netw. 2021, 24, 149–152. [Google Scholar] [CrossRef] [PubMed]
- Giansiracusa, N. How Algorithms Create and Prevent Fake News: Exploring the Impacts of Social Media, Deepfakes, GPT-3, and More; Apress: Berkeley, CA, USA, 2021; ISBN 978-1-4842-7154-4. [Google Scholar]
- Fallis, D. The Epistemic Threat of Deepfakes. Philos. Technol. 2021, 34, 623–643. [Google Scholar] [CrossRef] [PubMed]
- Karnouskos, S. Artificial Intelligence in Digital Media: The Era of Deepfakes. IEEE Trans. Technol. Soc. 2020, 1, 138–147. [Google Scholar] [CrossRef]
- Ridouani, M.; Benazzouza, S.; Salahdine, F.; Hayar, A. A Novel Secure Cooperative Cognitive Radio Network Based on Chebyshev Map. Digit. Signal Process. 2022, 126, 103482. [Google Scholar] [CrossRef]
- Whittaker, L.; Mulcahy, R.; Letheren, K.; Kietzmann, J.; Russell-Bennett, R. Map** the Deepfake Landscape for Innovation: A Multidisciplinary Systematic Review and Future Research Agenda. Technovation 2023, 125, 102784. [Google Scholar] [CrossRef]
- Seow, J.W.; Lim, M.K.; Phan, R.C.W.; Liu, J.K. A Comprehensive Overview of Deepfake: Generation, Detection, Datasets, and Opportunities. Neurocomputing 2022, 513, 351–371. [Google Scholar] [CrossRef]
- Rana, M.S.; Nobi, M.N.; Murali, B.; Sung, A.H. Deepfake Detection: A Systematic Literature Review. IEEE Access 2022, 10, 25494–25513. [Google Scholar] [CrossRef]
- Akhtar, Z. Deepfakes Generation and Detection: A Short Survey. J. Imaging 2023, 9, 18. [Google Scholar] [CrossRef]
- Ahmed, S.R.; Sonuç, E.; Ahmed, M.R.; Duru, A.D. Analysis Survey on Deepfake Detection and Recognition with Convolutional Neural Networks. In Proceedings of the 2022 International Congress on Human-Computer Interaction, Optimization and Robotic Applications (HORA), Ankara, Turkey, 9–11 June 2022; pp. 1–7. [Google Scholar]
- Malik, A.; Kuribayashi, M.; Abdullahi, S.M.; Khan, A.N. DeepFake Detection for Human Face Images and Videos: A Survey. IEEE Access 2022, 10, 18757–18775. [Google Scholar] [CrossRef]
- Yu, P.; **. ar**&author=Li,+L.&author=Bao,+J.&author=Yang,+H.&author=Chen,+D.&author=Wen,+F.&publication_year=2020&journal=ar** Based on Face Segmentation and CANDIDE-3. Available online: https://www.springerprofessional.de/robust-and-real-time-face-swap**-based-on-face-segmentation-an/15986368 (accessed on 18 July 2023).
- Ferrara, M.; Franco, A.; Maltoni, D. The Magic Passport. In Proceedings of the IEEE International Joint Conference on Biometrics, Clearwater, FL, USA, 29 September–2 October 2014; pp. 1–7. [Google Scholar]
- Thies, J.; Zollhöfer, M.; Stamminger, M.; Theobalt, C.; Nießner, M. Face2Face: Real-Time Face Capture and Reenactment of RGB Videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhang, J.; Zeng, X.; Wang, M.; Pan, Y.; Liu, L.; Liu, Y.; Ding, Y.; Fan, C. FReeNet: Multi-Identity Face Reenactment. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Seattle, WA, USA, 2020; pp. 5325–5334. [Google Scholar]
- Wang, Y.; Song, L.; Wu, W.; Qian, C.; He, R.; Loy, C.C. Talking Faces: Audio-to-Video Face Generation. In Handbook of Digital Face Manipulation and Detection: From DeepFakes to Morphing Attacks; Rathgeb, C., Tolosana, R., Vera-Rodriguez, R., Busch, C., Eds.; Advances in Computer Vision and Pattern Recognition; Springer International Publishing: Cham, Switzerland, 2022; pp. 163–188. ISBN 978-3-030-87664-7. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar]
- He, Z.; Zuo, W.; Kan, M.; Shan, S.; Chen, X. AttGAN: Facial Attribute Editing by Only Changing What You Want. IEEE Trans. Image Process. 2019, 28, 5464–5478. [Google Scholar] [CrossRef] [PubMed]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019. [Google Scholar]
- Choi, Y.; Uh, Y.; Yoo, J.; Ha, J.-W. StarGAN v2: Diverse Image Synthesis for Multiple Domains. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Seattle, WA, USA, 2020; pp. 8185–8194. [Google Scholar]
- Choi, Y.; Uh, Y.; Yoo, J.; Ha, J.-W. StarGAN v2: Diverse Image Synthesis for Multiple Domains. Available online: https://arxiv.org/abs/1912.01865v2 (accessed on 8 October 2023).
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Natsume, R.; Yatagawa, T.; Morishima, S. RSGAN: Face Swap** and Editing Using Face and Hair Representation in Latent Spaces. In Proceedings of the ACM SIGGRAPH 2018 Posters, Vancouver, BC, Canada, 12 August 2018; pp. 1–2. [Google Scholar]
- Prajwal, K.R.; Mukhopadhyay, R.; Philip, J.; Jha, A.; Namboodiri, V.; Jawahar, C.V. Towards Automatic Face-to-Face Translation. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 15 October 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1428–1436. [Google Scholar]
- FaceApp: Face Editor. Available online: https://www.faceapp.com/ (accessed on 5 October 2023).
- Reface—AI Face Swap App & Video Face Swaps. Available online: https://reface.ai/ (accessed on 5 October 2023).
- DeepBrain AI—Best AI Video Generator. Available online: https://www.deepbrain.io/ (accessed on 5 October 2023).
- Perov, I.; Gao, D.; Chervoniy, N.; Liu, K.; Marangonda, S.; Umé, C.; Dpfks, M.; Facenheim, C.S.; RP, L.; Jiang, J.; et al. DeepFaceLab: Integrated, Flexible and Extensible Face-Swap** Framework. ar**+Framework&author=Perov,+I.&author=Gao,+D.&author=Chervoniy,+N.&author=Liu,+K.&author=Marangonda,+S.&author=Um%C3%A9,+C.&author=Dpfks,+M.&author=Facenheim,+C.S.&author=RP,+L.&author=Jiang,+J.&publication_year=2021&journal=ar** for Improved Accuracy. In Proceedings of the 2023 5th International Conference on Computer Communication and the Internet (ICCCI), Fujisawa, Japan, 23–25 June 2023; IEEE: Fujisawa, Japan, 2023; pp. 9–14. [Google Scholar]
- Xu, Y.; Raja, K.; Pedersen, M. Supervised Contrastive Learning for Generalizable and Explainable DeepFakes Detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision Workshops, WACVW, Waikoloa, HI, USA, 4–8 January 2022; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2022; pp. 379–389. [Google Scholar]
- ** Implemented in Python. Available online: https://github.com/MarekKowalski/FaceSwap/ (accessed on 10 October 2023).
- Thies, J.; Zollhöfer, M.; Nießner, M. Deferred Neural Rendering: Image Synthesis Using Neural Textures. Available online: https://arxiv.org/abs/1904.12356v1 (accessed on 10 October 2023).
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-DF: A Large-Scale Challenging Dataset for DeepFake Forensics. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3204–3213. [Google Scholar]
- Dolhansky, B.; Bitton, J.; Pflaum, B.; Lu, J.; Howes, R.; Wang, M.; Ferrer, C.C. The DeepFake Detection Challenge (DFDC) Dataset. ar** and Reenactment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Jiang, L.; Li, R.; Wu, W.; Qian, C.; Loy, C.C. DeeperForensics-1.0: A Large-Scale Dataset for Real-World Face Forgery Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zi, B.; Chang, M.; Chen, J.; Ma, X.; Jiang, Y.-G. WildDeepfake: A Challenging Real-World Dataset for Deepfake Detection. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2382–2390. [Google Scholar] [CrossRef]
- Le, T.-N.; Nguyen, H.H.; Yamagishi, J.; Echizen, I. OpenForensics: Large-Scale Challenging Dataset for Multi-Face Forgery Detection and Segmentation In-the-Wild. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 10097–10107. [Google Scholar]
- Kwon, P.; You, J.; Nam, G.; Park, S.; Chae, G. KoDF: A Large-Scale Korean DeepFake Detection Dataset. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 10724–10733. [Google Scholar]
- Siarohin, A.; Lathuilière, S.; Tulyakov, S.; Ricci, E.; Sebe, N. First Order Motion Model for Image Animation. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Yi, R.; Ye, Z.; Zhang, J.; Bao, H.; Liu, Y.-J. Audio-Driven Talking Face Video Generation with Learning-Based Personalized Head Pose. ar**. ar**&author=Wang,+Y.&author=Chen,+X.&author=Zhu,+J.&author=Chu,+W.&author=Tai,+Y.&author=Wang,+C.&author=Li,+J.&author=Wu,+Y.&author=Huang,+F.&author=Ji,+R.&publication_year=2021&journal=ar**v" class='google-scholar' target='_blank' rel='noopener noreferrer'>Google Scholar]
- He, Y.; Gan, B.; Chen, S.; Zhou, Y.; Yin, G.; Song, L.; Sheng, L.; Shao, J.; Liu, Z. ForgeryNet: A Versatile Benchmark for Comprehensive Forgery Analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 21–25 June 2021; IEEE Computer Society: Washington, DC, USA, 2021; pp. 4358–4367. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Title | Covered | Not Covered |
|---|---|---|---|
| Sudhakar and Shanthi [21] | Deepfake: An Endanger to Cyber Security | Deepfake generation | Deepfake types |
| Deepfake detection | Datasets | ||
| Salman et al. [22] | Deepfake Generation and Detection: Issues, Challenges, and Solutions | Audio–visual Deepfake generation | Datasets |
| Deepfake detection | |||
| Khder et al. [23] | Artificial Intelligence into Multimedia Deepfakes Creation and Detection | Deepfake types | Datasets |
| Deepfake generation | |||
| Deepfake detection | |||
| Kandari et al. [24] | A Comprehensive Review of Media Forensics and Deepfake Detection Technique | Forensic-based deepfake detection methods | Deepfake types |
| Deepfake generation | |||
| Datasets | |||
| Boutad**e et al. [25] | A comprehensive study on multimedia Deepfakes | Deepfake generation | Deepfake types |
| Deepfake detection | |||
| Datasets | |||
| Threats and limitations | |||
| Mallet et al. [26] | Using Deep Learning to Detecting Deepfakes | Deepfake detection | Deepfake generation |
| Datasets | Deepfake types | ||
| Limitations | |||
| Das et al. [15] | A Survey on Deepfake Video-Detection Techniques Using Deep Learning | Deep learning-based detection models | Deepfake types |
| Deepfake generation | |||
| Datasets | |||
| Alanazi [27] | Comparative Analysis of Deepfake Detection Techniques | Deepfake creation | Datasets |
| Deepfake detection | |||
| **nwei et al. [28] | An Overview of Face Deep Forgery | Deepfake generation | Deepfake detection |
| Deepfake types | |||
| Datasets | |||
| Weerawardana and Fernando [29] | Deepfakes Detection Methods: A Literature Survey | Deepfake detection | Deepfake types |
| Limitations | Deepfake generation | ||
| P and Sk [30] | Deepfake Creation and Detection: A Survey | Deepfake generation | Deepfake types |
| Deepfake detection | Datasets | ||
| Lin et al. [16] | A Survey of Deepfakes Generation and Detection | Deepfake types | Future trends |
| Deepfake generation | |||
| Deepfake detection | |||
| Datasets | |||
| Khichi and Kumar Yadav [18] | A Threat of Deepfakes as a Weapon on Digital Platforms and their Detection Methods | Deepfake generation | Datasets |
| Deepfake detection | |||
| Limitations and future trends | |||
| Chaudhary et al. [19] | A Comparative Analysis of Deepfake Techniques | Deepfake creation | Deepfake types |
| Deepfake detection | |||
| Future directions | |||
| Datasets | |||
| Zhang et al. [31] | Deep Learning in Face Synthesis: A Survey on Deepfakes | Deepfake types | Datasets |
| Deepfake generation | Deepfake detection | ||
| Younus and Hasan [20] | Abbreviated View of Deepfake Videos Detection Techniques | Deepfake generation | Deepfake types |
| Deepfake detection | Datasets |
| Author | Features | Technique | Intra-Dataset Performance (%) | Dataset |
|---|---|---|---|---|
| Zhao et al. [97] | Spatial temporal | Xception, Video Transformer | ACC (DF = 98.9 F2F = 96.1 FS = 97.5 NT = 92.1) | FF++(LQ) |
| ACC (DF = 99.6 F2F = 99.6 FS = 100 NT = 96.8) | FF++(HQ) | |||
| ACC = 99.8 | Celeb-DF | |||
| ACC = 92.1 | DFDC | |||
| Yu et al. [98] | Spatial temporal | Global Inconsistency View, Multi-timescale Local Inconsistency View | ACC = 98.86 AUC = 99.89 | FF++ |
| ACC = 98.78 AUC = 99.81 | DFD | |||
| ACC = 95.93 AUC = 98.96 | DFDC | |||
| ACC = 99.64 AUC = 99.78 | Celeb-DF | |||
| ACC = 98.94 AUC = 99.27 | DFR1.0 | |||
| Yang, Z. et al. [99] | Attentional features from facial regions | 3D-CNN, TGCN, Spatial-temporal Attention, Masked Relation Learner | ACC = 91.81 | FF++(LQ) |
| ACC = 93.82 | FF++(HQ) | |||
| AUC = 99.96 | Celeb-DF | |||
| AUC = 99.11 | DFDC | |||
| Yang, W. et al. [62] | Audio-Visual Features | Temporal-Spatial Encoder, Multi-Modal Joint-Decoder | ACC = 95.3 AUC = 97.6 | DefakeAVMiT |
| ACC = 83.7 AUC = 89.2 | FakeAVCeleb | |||
| ACC = 91.4 AUC = 94.8 | DFDC | |||
| Shang et al. [100] | Spatial temporal | Temporal convolutional network, Spatial Relation Graph Convolution Units, Temporal Attention Convolution Units | ACC (DF = 99.29 F2F = 97.14 FS = 100 NT = 95.36) | FF++(HQ), Celeb-DF, DFDC |
| Rajalaxmi et al. [101] | Spatial inconsistencies | Inception-ResNet-V2 | ACC = 98.37 | DFDC |
| Korshunov et al. [102] | Spatial temporal | Xception | ACC = 100.00 | Celeb-DF |
| ACC = 99.14 | FF++ | |||
| AUC = 99.93 | DFR1.0 | |||
| AUC = 96.57 | HifiFace | |||
| Patel et al. [103] | Temporal inconsistencies | Dense CNN | ACC = 97.2 | CelebA, FFHQ, GDWCT, AttGAN, STARGAN, StyleGAN, StyleGAN2 |
| Pang et al. [104] | Spatial temporal | Bipartite Group Sampling, Inconsistency Excitation, Longstanding Inconsistency Excitation, | ACC = 85.61 AUC = 91.23 | WildDeepfake |
| ACC = 97.76 AUC = 99.57 | FF++(HQ) | |||
| ACC = 91.60 AUC = 96.55 | FF++(LQ) | |||
| ACC = 97.35 AUC = 99.75 | DFDC | |||
| Mehra et al. [105] | Spatial temporal | 3D-Residual-in-Dense Net | ACC (DF = 98.57 F2F = 97.84 FS = 94.62 NT = 96.05) | FF++ |
| AUC= 92.93 | Celeb-DF | |||
| Lu et al. [81] | Spatial temporal | VGG Capsule Networks | ACC = 94.07 | Celeb-DF, FF++ |
| Liu et al. [73] | Identity information | Encoder, RNN | AUC (FF++ = 99.95) | FF++, DFD, DFR1.0, Celeb-DF |
| Lin et al. [106] | Face semantic information | EfficientNet-b4 ViT | AUC = 99.80 | Celeb-DF |
| AUC = 88.47 | DFDC | |||
| ACC = 90.74 AUC = 94.86 | FF++(LQ) | |||
| ACC = 82.63 | WildDeepfake | |||
| Liang et al. [53] | Facial geometry features | Facial geometry prior module, CNN-LSTM | ACC = 99.60 | FF++ |
| ACC = 97.00 | DFR1.0 | |||
| ACC = 82.84 | Celeb-DF | |||
| ACC = 94.68 | DFD | |||
| Khalid et al. [107] | Spatial inconsistencies | Swin Y-Net Transformers | ACC (DF = 97.12 F2F = 95.73 FS = 92.10 NT = 79.90) | FF++ |
| AUC (DF = 97.00 F2F = 97.00 FS = 93.00 NT = 83.00) | ||||
| ACC = 97.91 AUC = 98.00 | Celeb-DF | |||
| Chen et al. [65] | Bi-granularity artifacts | ResNet-18decoder | Celeb-DF AUC = 99.80 FF++ AUC = 99.39 | Celeb-DF, FF++ DFD, DFDC-P, UADFV, DFTIMIT, WildDeepfake |
| Agarwal et al. [70] | Identity information | Action Units | AUC = 97.00 | World Leaders Dataset, Wav2Lip, FaceSwap YouTube |
| Cai et al. [61] | Audio-visual inconsistencies | 3DCNN 2DCNN | ACC = 99.00 | LAV-DF |
| ACC = 84.60 | DFDC | |||
| Zhuang et al. [108] | Spatial inconsistencies | Vision Transformer | FF++ AUC = 99.33 | FF++, Celeb-DF, DFD, DFDC |
| Yan et al. [109] | Spatial temporal frequency features | GNN | AUC = 91.90 ACC = 89.70 | FF++(LQ) |
| AUC = 99.50 ACC = 97.80 | F++(HQ) | |||
| Saealal et al. [110] | Spatial temporal | VGG11 | AUC = 0.9446 | OpenForensics |
| Xu et al. [111] | Spatial inconsistencies | Supervised contrastive model, Xception | ACC = 93.47 | FF++ |
| **a et al. [112] | Image texture | MesoNet | ACC = 94.10 AUC = 97.40 | FF++ |
| ACC = 94.90 AUC = 94.30 | Celeb-DF | |||
| AUC = 96.50 | UADFV | |||
| AUC = 84.30 | DFD | |||
| Wu, N. et al. [113] | Semantic features | Multisemantic path neural network | ACC = 76.31 | FF++(LQ) |
| ACC = 94.21 | F++(HQ) | |||
| AUC = 99.52 | TIMIT(LQ) | |||
| AUC = 99.12 | TIMIT(HQ) | |||
| Wu, H. et al. [114] | Spatial inconsistencies | Multistream Vision Transformer Network | ACC = 89.04 | FF++(LQ) |
| ACC = 99.31 | FF++(HQ) | |||
| Waseem et al. [82] | Spatial temporal | XceptionNet and 3DCNN | FF++ ACC (DF = 95.55 F2F = 77.05 NT = 75.35) | FF++, DFTIMIT, DFD |
| Cozzolino et al. [115] | Audio-visual inconsistencies | ResNet-50 | Avg AUC = 94.6 | DFDC, DFTIMIT, FakeAVCeleb, KoDF |
| Wang, J. et al. [57] | Spatial-frequency domain | Multi-modal Multi-scale Transformers | ACC = 92.89 AUC = 95.31 | FF++(LQ) |
| ACC = 97.93 AUC = 99.51 | FF++(HQ) | |||
| AUC = 99.80 | Celeb-DF | |||
| AUC = 91.20 | SR-DF | |||
| Wang, B. et al. [116] | Image grey space features | CNN Siamese network | ACC (DF = 84.14 F2F = 98.62 FS = 99.49 NT = 98.90) | FF++(LQ) |
| ACC (DF = 95.79 F2F = 97.12 FS = 97.37 NT = 84.71) | FF++(HQ) | |||
| Saealal et al. [117] | Biological signals (Eye blinking) | Cascade CNN-LSTM-FCNs | ACC (DF = 94.65 F2F = 90.37 FS = 91.54 NT = 86.76) | FF++ |
| Dataset | Year Released | Real Content | Fake Content | Generation Method | Modality |
|---|---|---|---|---|---|
| FaceForensics ++ [118] | 2019 | 1000 | 4000 | DeepFakes [119], Face2Face2 [37], FaceSwap [120], NeuralTextures [121], FaceShifter [34] | Visual |
| Celeb-DF (v2) [122] | 2020 | 590 | 5639 | DeepFake [122] | Visual |
| DFDC [123] | 2020 | 23,654 | 104,500 | DFAE, MM/NN, FaceSwap [120], NTH [124], FSGAN [125] | Audio/Visual |
| DeeperForensics-1.0 [126] | 2020 | 48,475 | 11,000 | DF-VAE [126] | Visual |
| WildDeepfake [127] | 2020 | 3805 | 3509 | Curated online | Visual |
| OpenForensics [128] | 2021 | 45,473 | 70,325 | GAN based | Visual |
| KoDF [129] | 2021 | 62,166 | 175,776 | FaceSwap [120], DeepFaceLab [51], FSGAN [125], FOMM [130], ATFHP [131], Wav2Lip [132] | Visual |
| FakeAVCeleb [133] | 2021 | 500 | 19,500 | FaceSwap [120], FSGAN [125], SV2TTS [134], Wav2Lip [132] | Audio/Visual |
| DeepfakeTIMIT [135] | 2018 | 640 | 320 | GAN based | Audio/Visual |
| UADFV [136] | 2018 | 49 | 49 | DeepFakes [119] | Visual |
| DFD [137] | 2019 | 360 | 3000 | DeepFakes [119] | Visual |
| HiFiFace [138] | 2021 | - | 1000 | HifiFace [138] | Visual |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naitali, A.; Ridouani, M.; Salahdine, F.; Kaabouch, N. Deepfake Attacks: Generation, Detection, Datasets, Challenges, and Research Directions. Computers 2023, 12, 216. https://doi.org/10.3390/computers12100216
Naitali A, Ridouani M, Salahdine F, Kaabouch N. Deepfake Attacks: Generation, Detection, Datasets, Challenges, and Research Directions. Computers. 2023; 12(10):216. https://doi.org/10.3390/computers12100216
Chicago/Turabian StyleNaitali, Amal, Mohammed Ridouani, Fatima Salahdine, and Naima Kaabouch. 2023. "Deepfake Attacks: Generation, Detection, Datasets, Challenges, and Research Directions" Computers 12, no. 10: 216. https://doi.org/10.3390/computers12100216