1. Introduction
Spelling errors and misspelled words are a big problem in idioms. For example, in Spanish, in street signs and social networks, among other contexts, this is very visible in expressions such as “Dios vendice a mi madre”, “solo Dios jusga”, “segidme”, “alturista”, instead of “altruista”, “objetibo”, and “la vida no es fasil” y “sonrrisa”. Currently, some systems perform an analysis, an extraction, an annotation, and a linguistic correction (based on dictionaries or in statistical analyses) to perform tasks as diverse as lemmatization [
1,
2], morphosyntactic labeling [
3,
4], syntactic analysis [
3], sentiment analysis (or opinion mining), and conceptual annotation [
2], among others.
Although there are some works on misspelled words in Spanish texts in order to recognize and correct them (see
Section 2), they are not yet efficient enough, particularly when the texts are large or the words have a certain complexity in their structure [
5,
6,
7]. A good example is the large number of word errors contained in millions of tweets and other massive data media [
3,
4]. Thus, efficient approaches based on a lexical analysis of the syntax of words in Spanish are interesting approaches that are not found in the literature to address this issue.
In this work, we present an automatic system for the orthographic revision of texts in Spanish, for the recognition of misspelled words, and for their automatic corrections, based on PRTM [
8]. This work presents a new method for the detection of misspelled words, in a way very similar to how the human brain solves misspellings (specifically, the neocortex), called Ar2p-Text, which reuses information to propose an efficient approach based on the lexical analysis of the syntax of the words in Spanish. Particularly, Ar2p-Text is based on Ar2p, a neural network model that represents the form just like the brain (neocortex) works using recognition modules of patterns [
9,
10,
11], according to the PRTM theory [
8]. Ar2p-Text uses strategies and modules of recognition and correction that allow for the carrying out of different processes of detection and correction of orthographic errors. In synthesis, the architecture of Ar2p-Text is characterized by having recognition module hierarchies, which increase the levels of complexity; i.e., the pattern recognition modules that constitute the lowest-level levels (or X
j−1), will always be of less complexity than the modules of the upper-level levels (or X
j, for j = 1,…, m). In addition, Ar2p-Text has a supervised definition of the weights assigned to the variables used for recognition based on adaptive mechanisms inspired by previous works [
10,
12,
13]. Therefore, the main contribution of this work is to propose a new system to recognize and correct misspelled words in Spanish texts based on AR2P (following the PRTM theory), which (i) is highly recursive and uniform; (ii) is based on a recognition process that uses a hierarchy of patterns that is self-associating; (iii) is adaptable because it can learn new patterns (words); (iv) can analyze large Spanish texts with words with a certain complexity in their structure; and (v) is a new spell-checking approach that follows the highly scalable and efficient human model that is very different from other spell-checking approaches that do not rely on atomic abstractions and recursive processes to generalize information. As far as we know, there is no previous work based on PRTM, and less applied to Spanish.
This paper is organized as follows:
Section 2 describes related works.
Section 3 describes the PRTM theory, which is the basis of AR2P text.
Section 4 makes a formal description of the general architecture of Ar2p-Text, its data structure (pattern recognition modules), and its computational model.
Section 5 shows the experiments for the treatment of digital texts, the database used, the quality metrics, and the performance evaluation. Finally,
Section 6 describes conclusions and future works.
2. Related Works
Currently, there are different approaches for lemmatization, morphosyntactic analysis, and sentiment analysis, among others. Particularly, we are interested in the spell-checking (auto-correction) problem.
Some works in this domain are STILUS [
14], which distinguishes four types of errors: grammatical, orthographic, semantic, and stylistic. The system has modules specifically dedicated to each one of them. In the case of orthographic revision, STILUS performs the correction of words in three stages: the generation of alternatives to the wrong word, the weighting of alternatives, and the arrangement of alternatives. Another system is ArText, which is a prototype of an automatic help system for writing texts in Spanish in specialized domains [
5]. The system has three modules: the first module handles aspects of structure, content, and phraseology. The second module is for format and linguistic revision. Finally, the last module allows the users to linguistically revise their text. XUXEN is a spell-checker/corrector [
6], which has been defined based on two morphological formalisms. It uses a highly flexed standardized language with a broad relationship between nouns and verbs and a lexicon that contains approximately 50,000 items, divided among verbs and other grammatical categories.
On the other hand, Valdehíta [
3] proposes a spell- and grammar-checker algorithm for texts where the possible mistakes are not detected by tagging and parsing, but by statistical analysis, comparing combinations of two words used in the text to a hundred-million-word corpus. Ferreira et al. [
1] propose a spell-checker where the text is processed according to two ways: word by word and as a chain in search of complex error patterns. In [
15], a corpus is presented called JHU FLuency-Extended GUG corpus (JFLEG), which can evaluate grammatical errors. It uses different levels of a language, with holistic fluency edits, both to correct grammatical errors and to make the original text more native-sounding. Also, Singh and Mahmood [
7] present a general approach to various uses of natural language processing (NLP) (translation and recognition) using modern techniques such as deep learning techniques. Finally, there are other books and papers in the literature like [
16], but there are few systems that deal with lexical or syntactical errors in Spanish, like [
3,
5,
14].
Li et al. [
17] developed a multi-round error correction method with ensemble enhancement for Chinese Spelling Check. Specifically, multi-round error correction follows an iterative correction pipeline, where a single error is corrected at each round, and the subsequent correction is conducted based on the previous results. Cheng et al. [
18] defined an English writing error correction model to carry out an automatic checking and correction of writing errors in English composition. This paper used a deep learning Seq2Seq_Attention algorithm and a transformer algorithm to eliminate errors. Then, the output of each algorithm is sent to an n-gram language algorithm for scoring, and the highest score is selected as the output. Ma et al. [
19] proposed a confusion set-guided decision network based on a long short-term memory model for spoken Chinese spell checking. The model can reasonably locate the wrong characters with a decision network, which ensures the bidirectional long short-term memory pays more attention to the characteristics of the wrong characters. This model has been used to detect and correct Chinese spelling errors. Finally, Hládek et al. [
20] presented a survey of selected papers about spelling correction indexed in Scopus and Web of Science from 1991 to 2019. The survey describes selected papers in a common theoretical framework based on Shannon’s noisy channel. They finish with summary tables showing the application area, language, string metrics, and context model for each system.
As we can see in the previous works, there are not many works related to Spanish. We confirmed that in the existing literature, the language where the most work has been performed on spelling correction is Chinese. Additionally, there are also no works that are based on a hierarchical approach to pattern recognition (in our case, words) as a basic mechanism that allows for the reuse of text (patterns) as an efficient way that allows for the recognition of many words, some of them complex. In our case, Ar2p-Text allows for it, because the Ar2p neural model on which it is inspired is based on the PRTM theory that emulates the behavior of the neocortex area of the brain that follows these principles (the next sections detail these theories/models).
3. PRTM Theory
This model has been described in several previous works; here, we present a short summary. The pattern recognition theory of mind (PRTM) describes the procedure followed by the neocortex, according to some of the aspects of the functioning of the human brain such as [
8,
21] wherein (i) our memory is handled as a hierarchy of patterns and (ii) if we only perceive a part of a pattern (through sight, hearing, or smell), we can recognize it. Also, PRTM presupposes several hypotheses on the structure of the biological neocortex such as (i) a uniform structure of the neocortex, called the cortical column, which is the module of recognition for PRTM, and (ii) the recognition modules are connected all the time to each other.
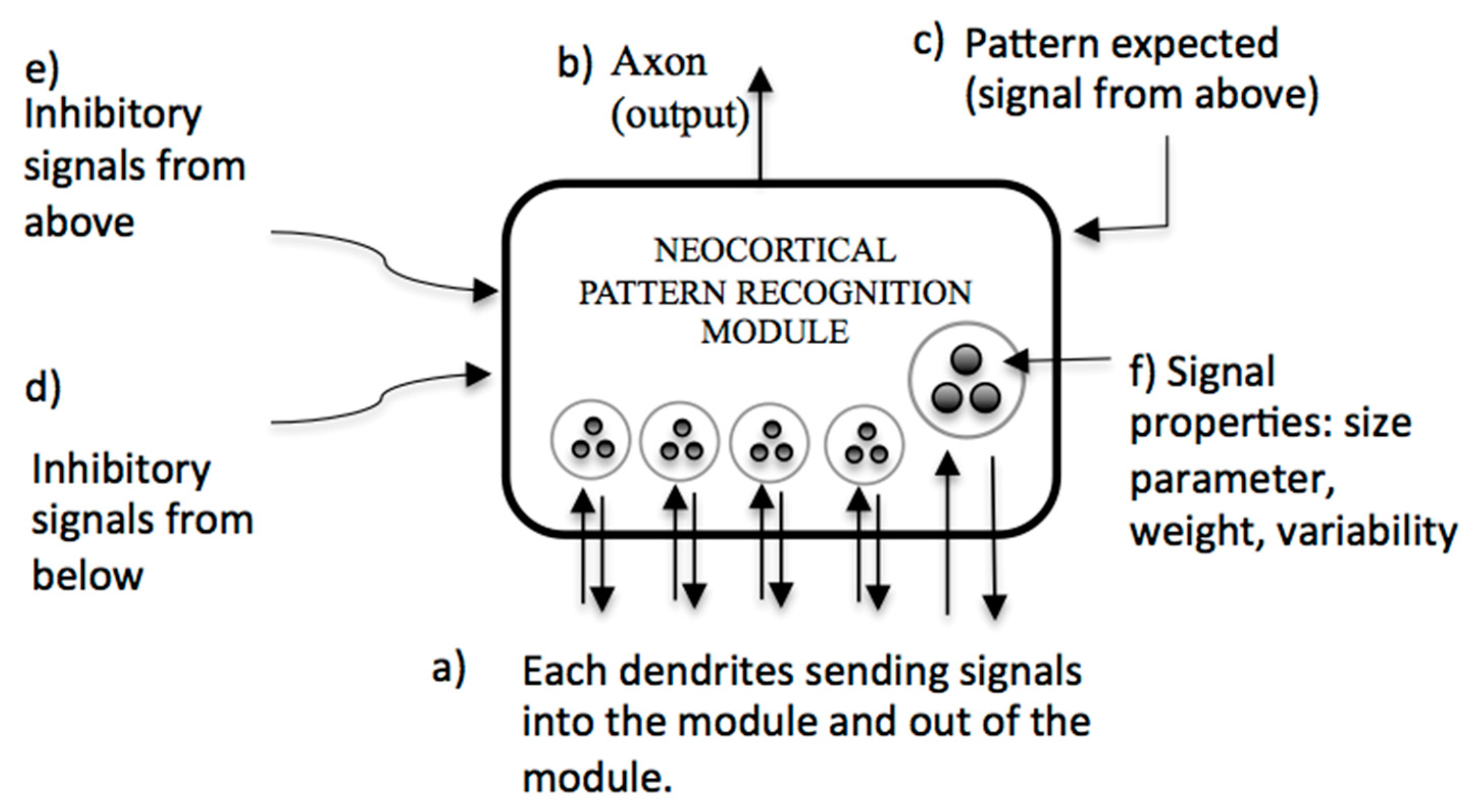
Figure 1 describes a pattern recognition module of PRTM.
In
Figure 1, (a) each of the dendrites sends information (parameters of size, importance, and variability) toward the interior of the module, indicating the presence of a pattern in the lower level or outside. (b) When there is recognition, an output is generated. On the other hand, (c) if a pattern recognizer of a higher level receives a signal coming from almost all the recognizers that make up its input, this recognizer is likely to send an exciting signal toward the lowest level of the missing pattern recognizers (via a dendrite) to indicate that it is expecting them. In addition, there are inhibitory signals from both (d) a lower-level recognition space and (e) a higher-level recognition space, which can inhibit the process of recognition of a pattern. They are the basis of Ar2p-Text, our system of recognition of texts.
4. Formalization of the Ar2p-Text Neural Model
In this section, we describe the design of the proposed Ar2p-Text. Ar2p-Text is an extension of the Ar2p neural model [
10,
16] for the context of Spanish text analysis. The Ar2p neural model has previously been successfully used in different contexts [
9,
11]. Next, we will describe the aspects of the Ar2p neural model, clarifying its extensions for the case of Ar2p-Text. Ar2p is a neural network model based on the PRTM theory [
8].
4.1. Formal Definition of Ar2p-Text
A pattern recognition module is defined in Ar2p by a 3-tuple, which is similarly used by Ar2p-Text [
9]. Γ
ρ notation is used to represent the module that recognizes the
ρ pattern (
ρ: shapes, letters, and words, etc.).
where
E is an array defined by the 2-tuple
E = <S, C> (see
Table 1),
S = <Signal, State> is another array of the set of signals of the pattern recognized by Γ with its states,
C is another array with information of the pattern described by the 3-tuple
C = <D, V, W>, and D are the descriptors of Γ, V is the vector with the possible values of each descriptor in D, and W is the relevance weight of the descriptors in the pattern
ρ. Additionally, there is a threshold vector U used by the module (Γ) to recognize the pattern.
Table 1 constitutes one artificial neuron, which is a neocortical pattern recognition module according to the PRTM theory. In the Ar2p neural model, each neuron/module can acknowledge and observe every aspect of the input pattern
s() and how the different parts of the data of the input pattern may or may not relate to each other.
Two types of thresholds were used: ΔU1 for the recognition using key signals and ΔU2 for the recognition using total or partial map**. The ΔU1 threshold is stricter than ΔU2 because the process based on key signals uses few signals. Finally, each module generates an acknowledgment signal or a request signal to the lower levels (So). So as a request signal is the input signal s() of the modules of the lower levels. So, as an acknowledgment signal, is sent to its higher levels to modify their states of the signal to “true”.
Thus, a pattern is represented as a set of lower-level sub-patterns that conform to it (N descriptors), and in turn, it also serves as a sub-pattern of a higher-level pattern. N depends on the descriptors of the pattern to recognize. W is normalized [0,1], and ΔU1 or ΔU2 are thresholds that must be overcome in order to recognize the pattern. These values are defined according to the domain of application.
The previous definitions have been defined for the neural model Ar2p [
10], but they are maintained for the case of Ar2p-Text. In the context of Ar2p-Text, the main patterns to recognize (
ρ) are letters, words, special signs, and numbers.
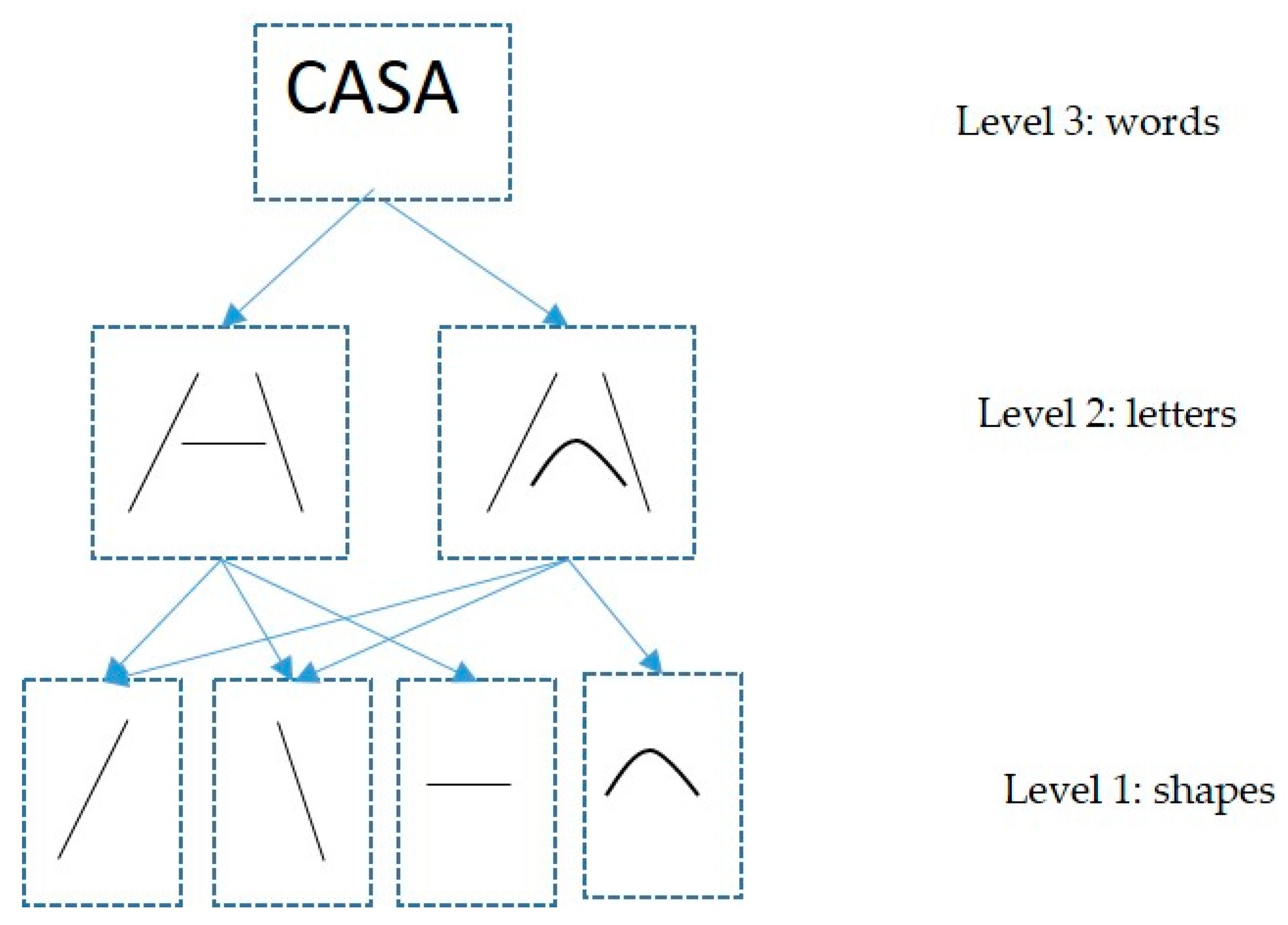
4.2. Text Analysis in Ar2p-Text
In this section, we describe the general model of Ar2p-Text. Again, Ar2p-Text follows the same formal description of the Ar2p model [
9], but it is instanced for the specific case of text analysis. Particularly, the hierarchical system describes the iterative and recursive processes for the recognition and correction of words with Ar2p-Text. Each layer is an interpretative space χ
i, from i = 1 to m, such that χ
1 is the first level to recognize atomic patterns (e.g., letters or letterforms) and χ
m is the last level to recognize complex patterns (e.g., words and compound words). Each level has Γ
ji recognition modules (for j = 1, 2, and 3… # of modules at level i). Finally, χ
ji is the pattern that is recognized at level i by module j.
Thus, Ar2p-Txt is a pattern recognition system based on the hierarchical architecture of a neural network. The multiple hidden layers are the recognition spaces of i-level or the levels of recognition of the complex patterns (χi). This is how Ar2p is capable of finding extremely complex patterns using bottom-up or top-down approaches.
4.3. Strategies of Checking/Correction/Recognition in Ar2p-Text
An important modification with respect to the Ar2p model is how signal thresholds are used in Ar2p-Text. Ar2p-Text uses two strategies for the correction process: the first one uses key signals; the other uses partial signals, and both use a threshold of satisfaction and the importance of the weights of signals. In this way, the recursive model allows for the decomposition of the problem of recognition of patterns into simpler patterns, which makes it possible to analyze very complex words.
Particularly, the first strategy, named
pattern matching by key signals is based on the relevance weights of the input signals identified as keys [
11,
22]. The
partial pattern matching strategy utilizes the total or partial presence of the signals. A signal is key when it represents information that allows a pattern to be recognized quickly. For example, the final letter “r” in infinitive verbs could be taken as a key.
Definition 1. key signal. is a key signal in the Γ module when its relevance weight has a greater or equal value to the mean weight of all the signals in Γ (see Equation (1)). Theorem 1. Strategy by key signals. A ρ pattern is recognized by key signals if the mean of the key signals recognized is superior to ΔU1. It utilizes the descriptors (signals or sub-patterns) with the greater relevance weight. The equation is: Theorem 2. Strategy by partial map**. This strategy validates if the signal number in Γ is superior to ΔU2. The equation is: This process is performed for each module of each level of recognition Xi during the recognition process.
4.4. Computational Model of Ar2p-Text
Again, Ar2p-Text follows the same general computational process of the Ar2p model [
9], but it introduces certain modifications for the specific case of text analysis. Next, the algorithm of Ar2p-Text is presented with these modifications. This algorithm has two processes: A first process, the bottom-up process, for the atomic patterns, such that the output signals of the recognized patterns go to the modules of which they are part of the top levels to activate them if they pass a recognition threshold [
9]. The other process is a top-down one for the input pattern by decomposition. The top-level module uses the modules of recognition of the lower level, and then they recursively do the same.
The algorithm works as follows: The input text is received (y = s(): sentences and word (s)). Then, this input is broken down into sub-patterns that are stored in L (e.g., if it is a sentence, then it is decomposed into words, and so on for the rest). The level of depth of decomposition depends on the level of detail and analysis with which the pattern is recognized. Once the pattern has been simplified, then the ** of 1.0. LLaMA was also subjected to corrupted Spanish texts according to
Table 3.
Table 13 shows the results in the different cases analyzed.
In this comparison, we can see that our algorithm, without a training phase or prior pre-training like deep learning techniques, achieves quality metrics very close to the two techniques. Furthermore, when we have a higher error rate, our technique surpasses the quality of the results obtained with the other metrics. Now, to validate the quality of our results, we carried out a statistical analysis of those results using the non-parametric Friedman test. In particular, the Friedman test was applied to the results, showing statistical differences in performance between the proposed models, according to the order of quality established in
Table 13, with
p < 0.001.
Finally, with respect to the previous techniques, it is good to note that Ar2p-Text is an approach with a lot of explainability because the tree that is built allows for the recognition process to be described clearly and it is highly scalable due to the recursion and reuse of the patterns at the different levels of the hierarchy.
5.5. A Final Discussion about the Characteristics of Ar2p-Text
Our Ar2p-Text pattern recognition model is highly uniform and recursive. It recognizes input patterns through a hierarchy process of self-associated patterns. Ar2p-Text allows for the decomposition of the pattern recognition problem into simpler patterns, allowing for the analysis of the patterns regardless of their level of complexity or nature (a line, a word, a sentence, a paragraph, etc.). Finally, our recognition model is adaptable due to the fact that it learns both new modules (patterns) or the possible changes in the pattern descriptors (such as their relevance weights), which is very useful in the context of a language for the self-learning of words and idiomatic sentences. Unlike other approaches, Ar2p-Text can recognize words with special characters just like the brain, such as @ = a, E = 3, S = 5, 9 = q, m@ma, and p3ra. Also, its novelty is the way it solves the problem. Although several NLP models have achieved very good performances, they have high computational costs.
In this work, different comparisons have been presented with other works that use other techniques, or are based on other assumptions. Because automatic spell-checking systems are currently of great interest in different languages [
32,
33,
34,
35], a challenge will be to test this approach on them.
6. Conclusions and Future Works
In this paper, we have presented an automatic recognition and correction system for misspelled words in Spanish texts. We compared the approach with previous works, demonstrating its superiority. Ar2p-Text detects more different types of orthographic errors and has fewer false positives. Regarding the limitations of the Ar2p-Text recognizer, it requires a supervised definition of the weights assigned to the variables used for the recognition.
The proposed algorithm improves upon the state of the art because our Ar2p-Text pattern recognition model is highly recursive and uniform. It recognizes input patterns through a process of self-association in a hierarchy of patterns. Ar2p-Text allows for the decomposition of the pattern recognition problem into simpler patterns, allowing us to analyze input patterns regardless of their level of complexity or nature (a line, a word, a sentence, a paragraph, etc.). In addition, the Ar2p-text model compared to other pattern recognition methods is easily parallelizable, because its calculations defined in the theorems are simpler and distributed on a hierarchy. Also, the computational cost can be improved with respect to other approaches, with more efficient use of memory, due to a single abstract data structure that can be instanced by various text patterns. Finally, our recognition model is adaptable because it learns both new modules and the possible changes in the pattern descriptors, which is very useful in the context of a language for the self-learning of words and idiomatic sentences.
In future work, the architecture of Ar2p-Text must be extended with unsupervised learning mechanisms, which will allow it to improve its functioning (learning new words). Also, it must be extended for use in other languages. Additionally, Ar2p-Text could simultaneously correct texts written in English and Spanish, which can be interesting in translation tasks. For that, Ar2p-Text must be extended with more recognition modules in different languages (its lexical basis).
Finally, a comparison with other approaches in the domain of NLP is not presented because in this case, we are only interested in the spell-checking (auto-correction) problem. Several NLP approaches exist for machine translation, cognitive dialogue systems, sentiment analysis, text classification, and text summarization, among others, using techniques of natural language understanding and natural language generation present in the state-of-the-art NLP. Thus, future work will be the analysis of the utilization of our approach in these contexts to compare with these techniques.








{kind=link}
{kind=link}
{kind=link}