1. Introduction
With the emergence of Internet of Thing (IoT) and the Machine-to-Machine (M2M) networks, designing efficient protocols for connecting such networks with the Internet has become more pertinent. In this context, IPv6 and Low Power over Personal Area Network (6LoWPAN) have recently been introduced to fully integrate low-power networks such as Wireless Sensor Network (WSN) with the Internet. However, this integration, coupled with the exponential growth of applications that require mobility support, has generated the need for develo** mobility management protocols. Hence, the main aim of mobility management is to maintain the connectivity of mobile node when roaming among different networks. To address such an issue, several mobility management protocols have come into existence with the ultimate goal of providing an efficient and seamless movement of nodes among networks. In general, the mobility management protocols are categorised into two classes: host-based protocols and network-based protocols. In the host-based protocols [
1,
2,
3,
4,
5], the MN is required to be involved in the mobility process even when the Network Mobility (NEMO) is supported for the MNs that move in a group by the Mobile Router entity (MR). This involvement leads to increasing the handoff and the MN complexity, which in turn lower the system performance [
6].
To solve this issue, network-based protocols have been proposed [
7,
8,
9,
10,
11,
12]. In these protocols, the handoff signalling burden is transferred to new entities called Local Mobility Anchor (LMA) and Mobile Access Gateway (MAG) and therefore the Mobile Node (MN) is shielded from the mobility related signalling when it moves between different networks. Although being efficient in terms of power consumption, the network-based protocols do not show the same level of efficiency in terms of handover latency and signalling cost as they usually induce long handover latency and high signalling cost due to the individual processing of the MNs handoff operations. Consequently, group-based technique have been considered by several solutions in order to overcome the issues of signalling cost and handover latency associated with the previous studies, especially when the handover is triggered frequently in a short time for a group of MNs [
13,
14,
15,
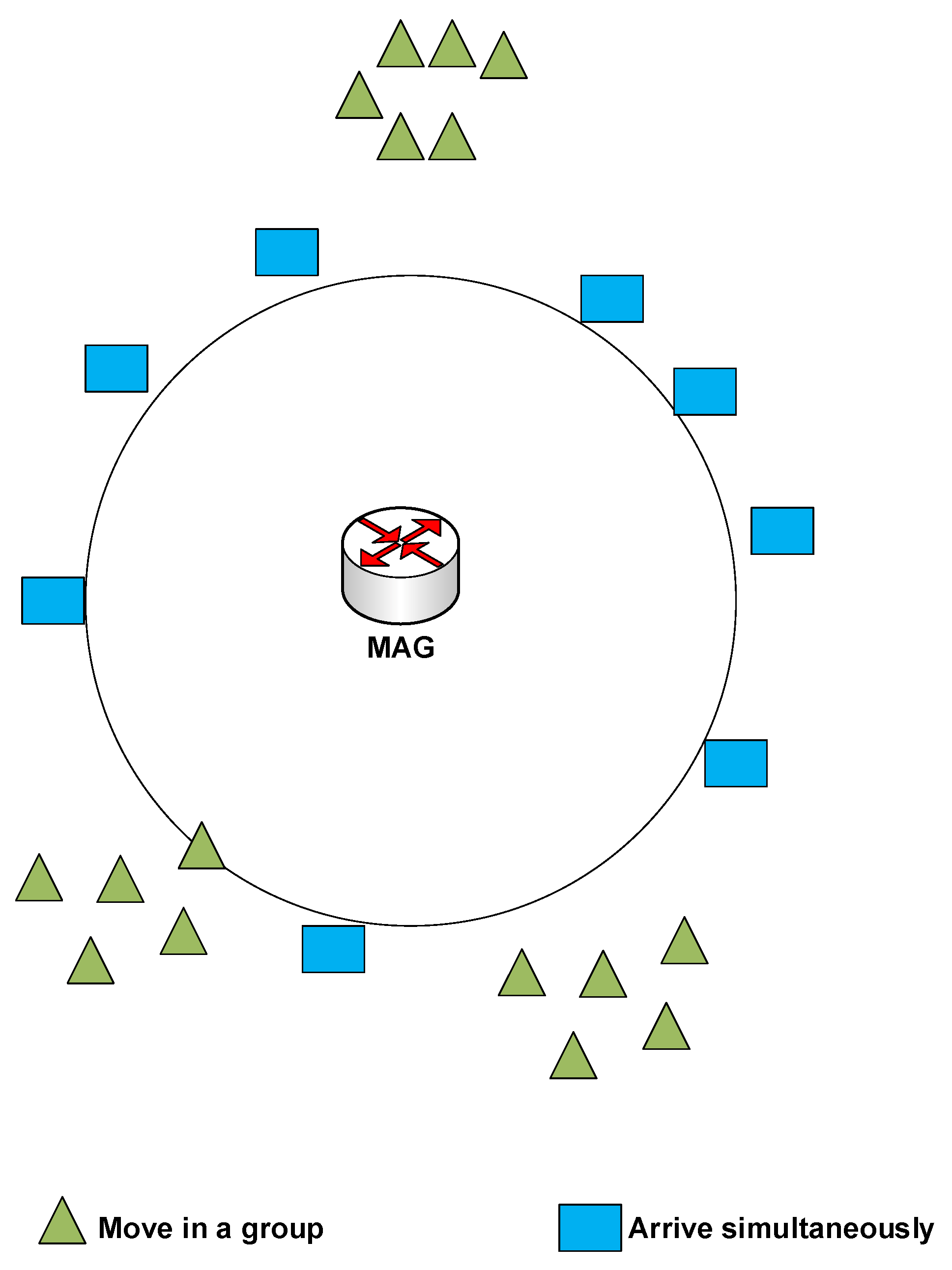
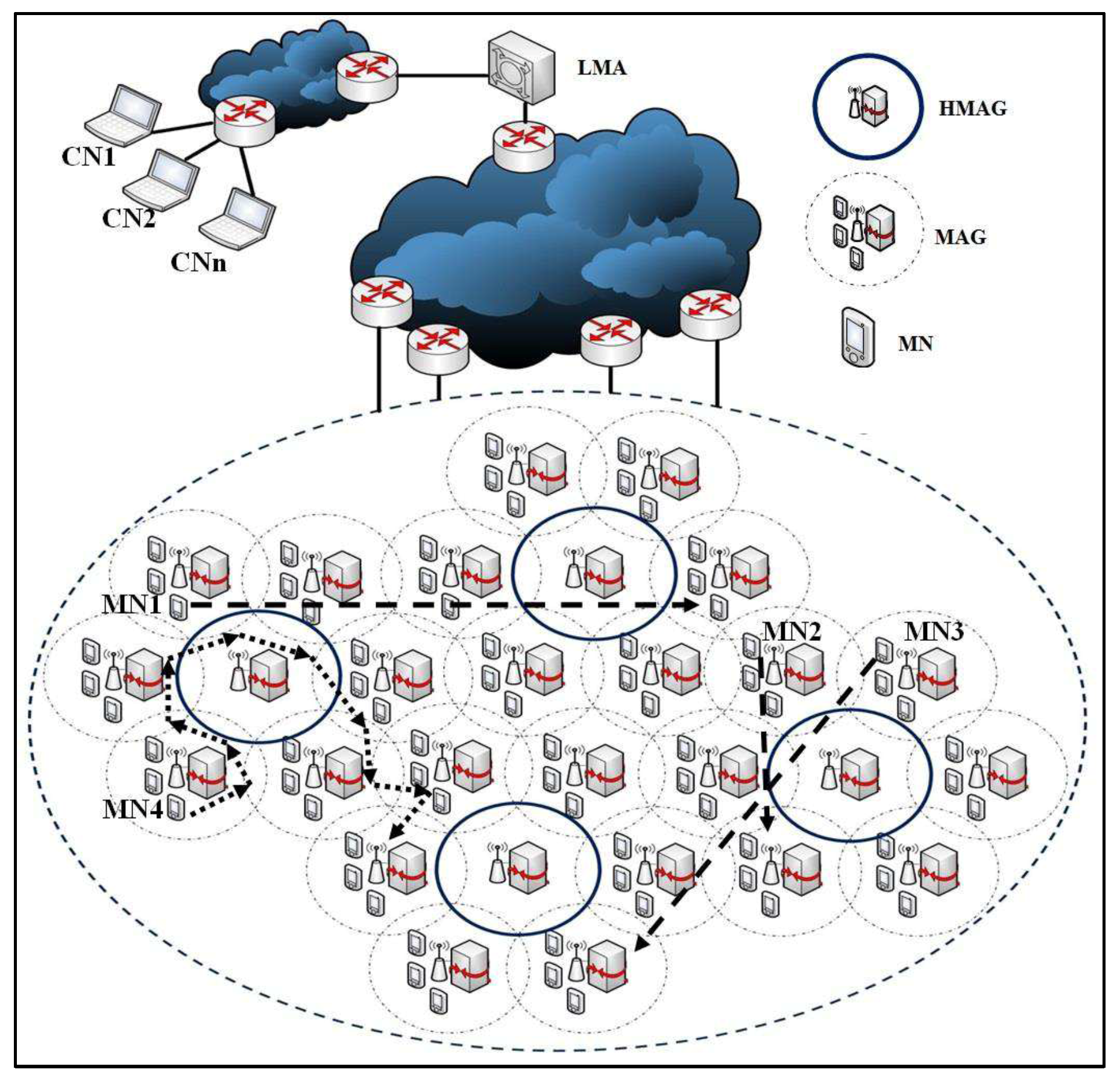
16]. The proposed studies aim at grou** the MNs’ control messages to minimise the handoff latency and signalling cost through utilising the similarity in the MNs’ movement patterns. Received Signal Strength (RSS) is utilised by most of these studies to discover the MNs’ movement similarity during their roaming. According to the above explanation, the main issue that should be considered during the MNs’ handoff process is: designing an efficient scheme that has the ability to process the MNs’ handoff simultaneously without any service disruption. Thus, the aim of this paper is to propose an efficient scheme for simultaneously moving MNs or MNs having their handoff simultaneously triggered, as shown in
Figure 1. The proposed Enhanced Cluster Proxy Mobile IPv6 (E-CPMIPv6) scheme achieves this by utilising the Signal-to-Noise Ratio (SNR) of MNs in order to group the MNs’ mobility-related signalling and to discover the MNs that will perform the handoff at the same time.
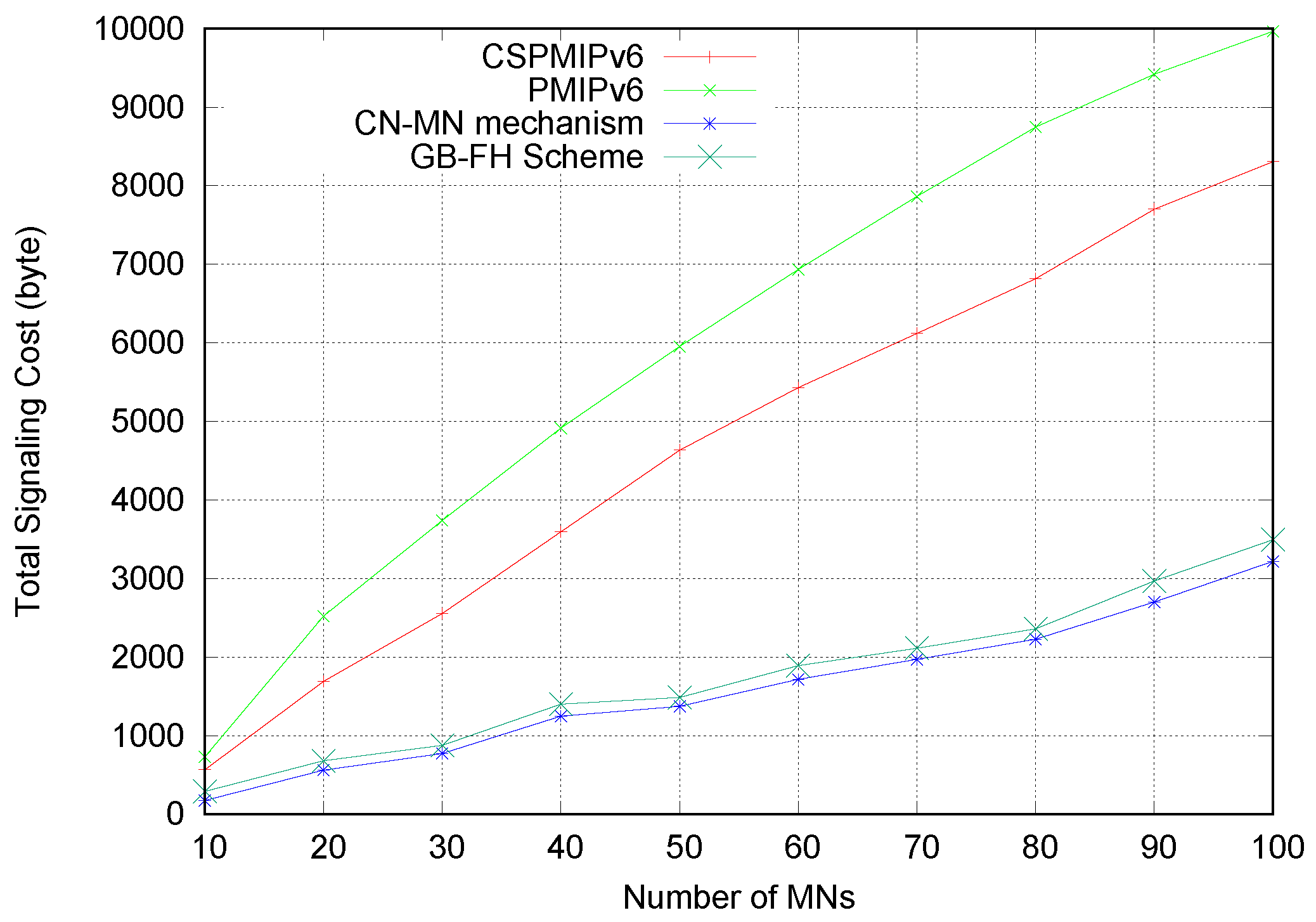
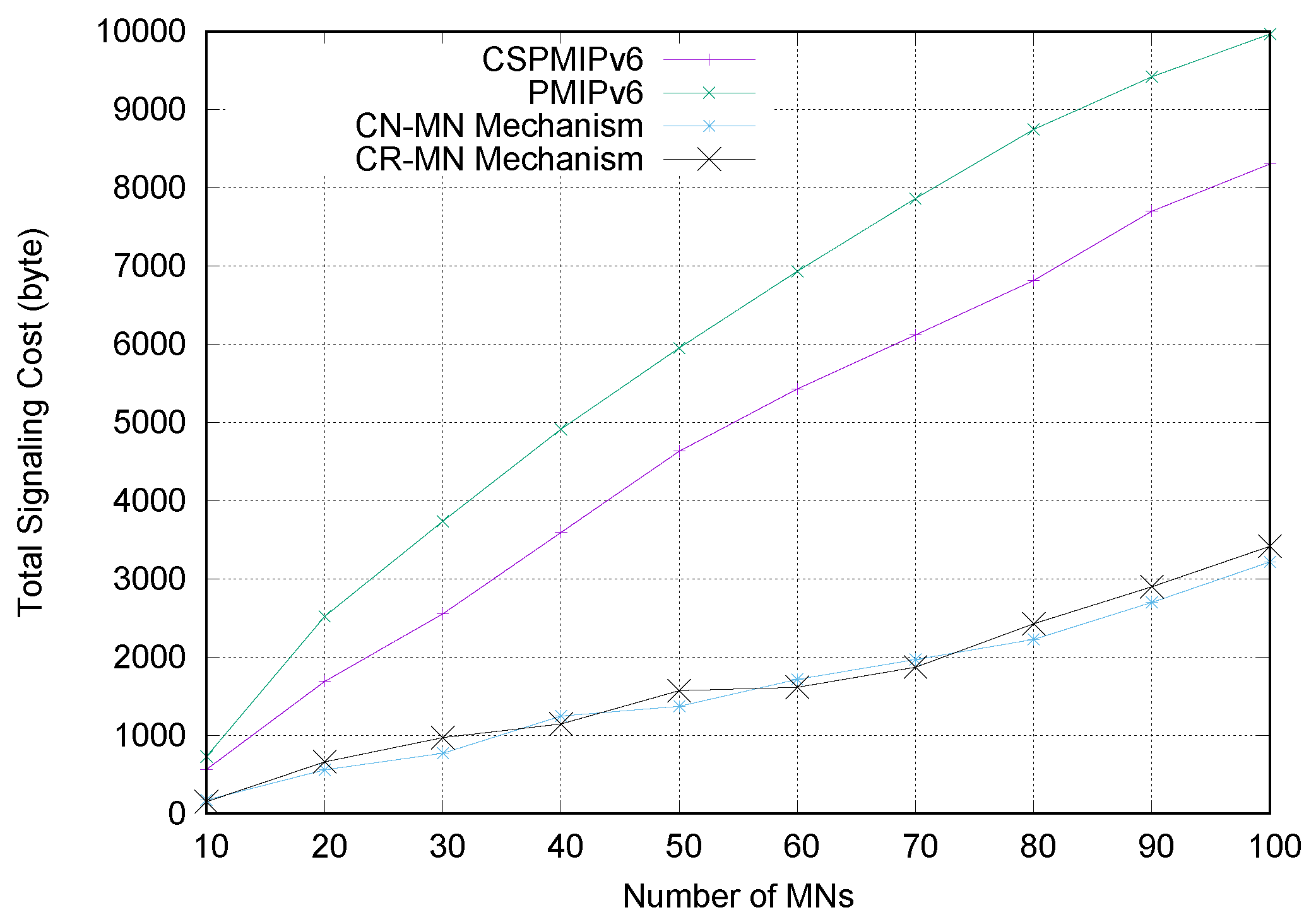
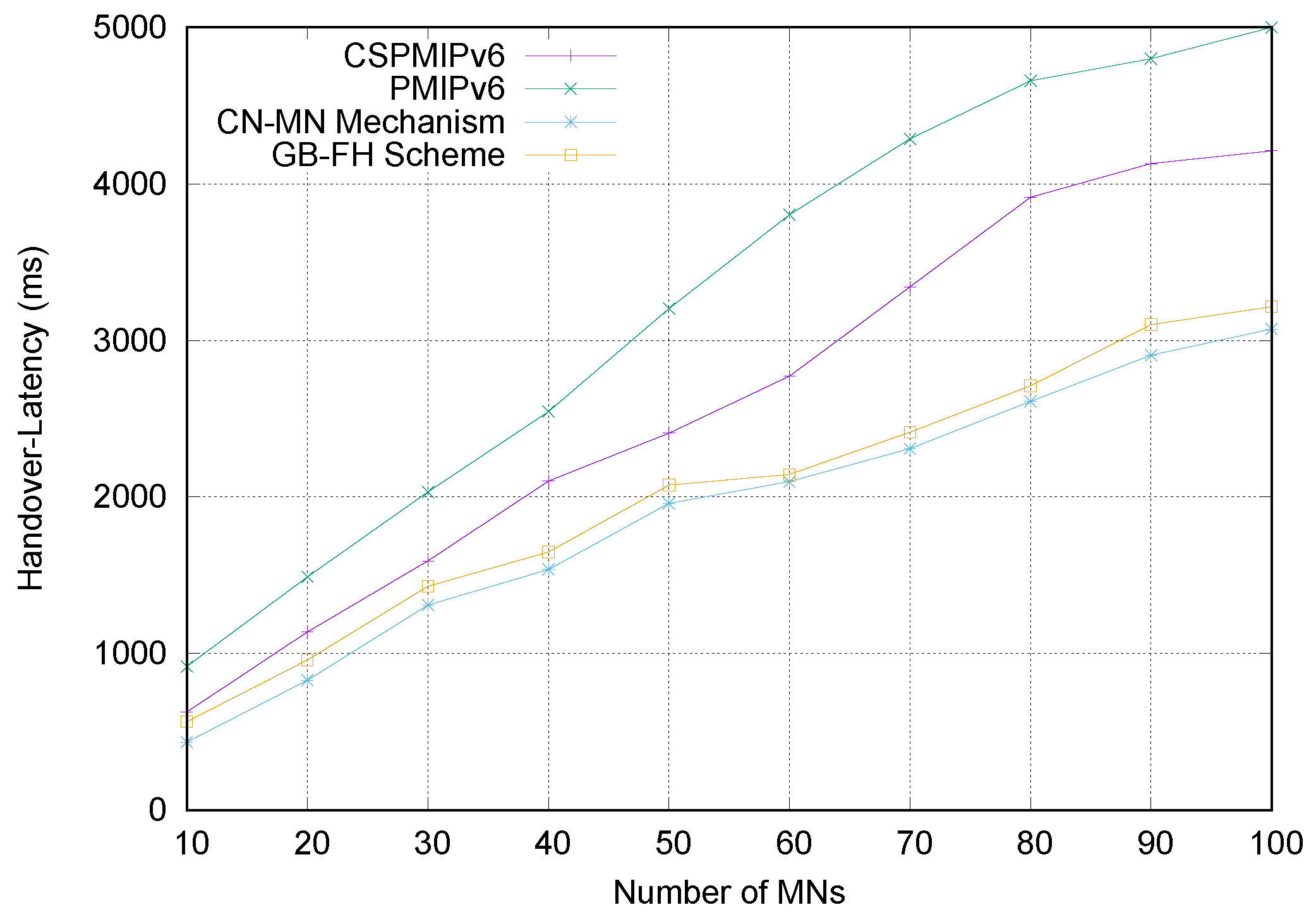
To validate the proposed E-CPMIPv6 scheme, we compared the proposed E-CSPMIPv6 scheme with the recent Group-based Fast Handover (GB-FH) scheme [
16]. Furthermore, the proposed scheme was also evaluated by comparison to the standard Proxy Mobile IPv6 (PMIPv6) protocol [
7] and Cluster-based Proxy Mobile IPv6 (CSPMIPv6) protocol [
12] mobility management protocols using numerical analysis and simulation experiments to show the superiority of the proposed E-CPMIPv6 scheme in terms of signalling cost, handover latency and end-to-end delay.
The contributions of this study are summarised as follows:
A novel efficient clustering mechanism is introduced for grou** MNs moving simultaneously before processing their handoffs.
A new mechanism is proposed for simultaneously manipulating the mobility-related signalling for a group of MNs that are triggering their handoff at the same time.
A numerical analysis was performed to test the performance of E-CPMIPv6 in terms of the handoff latency, the analysis was validated by extensive simulations.
The remainder of this article is organised as follows:
Section 2 presents an extensive overview of mobility management protocols highlighting their advantages and disadvantages. In
Section 3, we propose the system model that is used as the environment for the E-CPMIPv6 scheme.
Section 4 presents in detail the E-CPMIPv6 Scheme. In
Section 5, we explain in detail the proposed E-CSPMIPv6 methodology within the localised mobility protocol environment.
Section 6 discusses the performance evaluation of the E-CPMIPv6 Scheme. Finally, the study contributions are summarised in
Section 7.
2. Mobility-Related Study
Several protocols have been proposed to perform handover process for several MNs in a concurrent manner.
The protocol in [
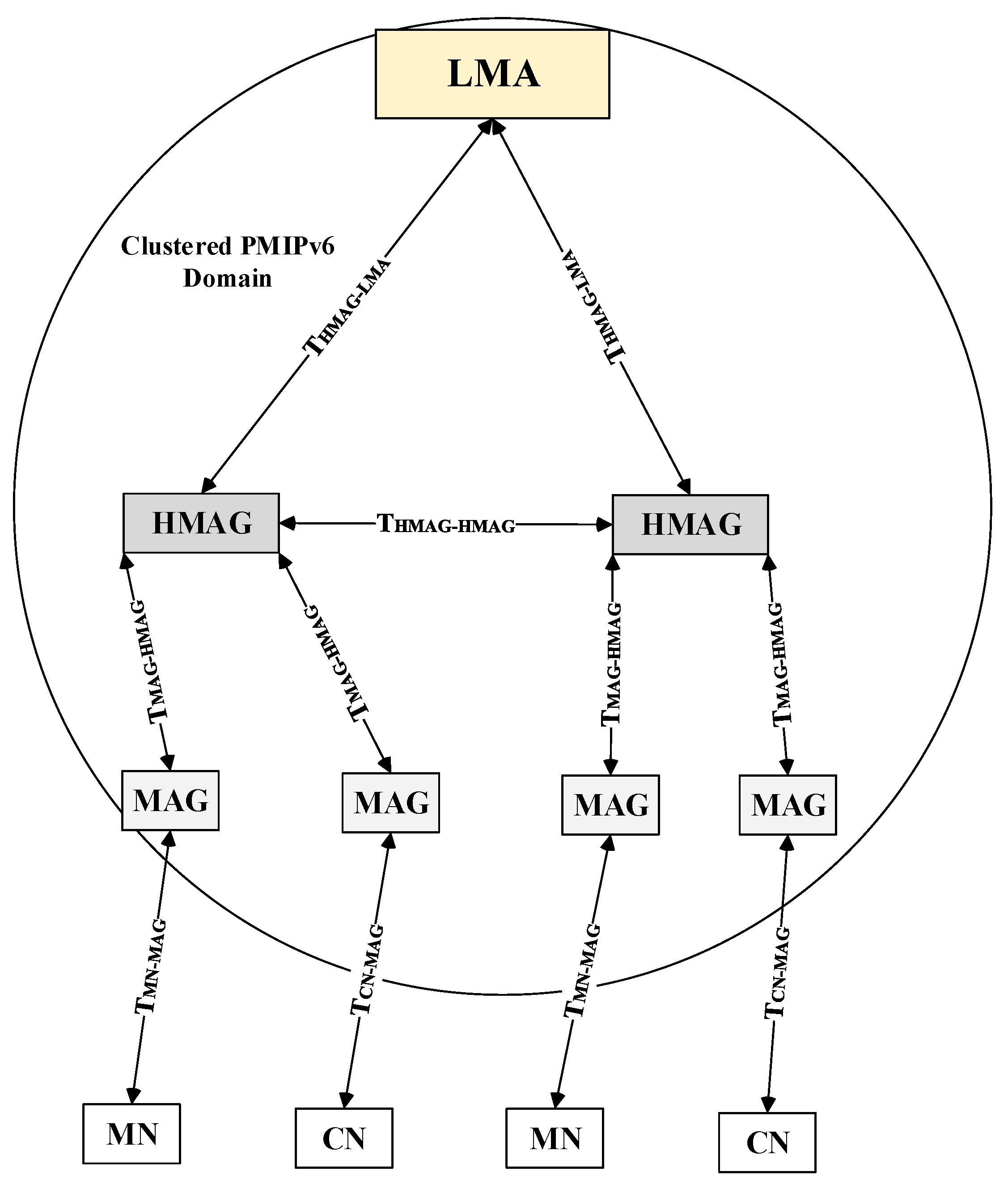
12] presents an enhanced architecture to PMIPv6 named, Cluster Sensor PMIPv6 (CSPMIPv6) architecture. This enhancement attempts to tackle the bottleneck issues in PMIPv6 protocol by dividing the proxy mobile domain into sub-local domains. Each sub-domain groups MAGs into clusters, with each cluster being managed and controlled by a cluster head. In the CSPMIPv6 architecture, the LMA and MAG functionalities are similar to LMA and MAG in PMIPv6 protocol. The key characteristic of the Head MAG (HMAG) is to relieve the LMA from any local mobility management. In addition, the HMAGs reduces the handoff latency and provides a route-optimised path in intra-communication mobility. Nevertheless, the mobility in this protocol is performed individually for each MN that enters the CSPMIPv6 domain, which leads to an increasing in the signalling cost and handoff latency. Accordingly, an efficient mobility management scheme has to consider this issue in its original design. Thus, this research originally is designed to make a group of MNs act as a single MN when they are changing their point of attachment from one network to another network in order to reduce the signalling cost and the time needed for the handoff.
To enhance the efficiency of mobility management, a group-based technique is utilised in [
16]. This solution introduces a new scheme, named the Group-based Fast Handover (GB-FH) control scheme. To perform a grou**, this scheme selects one MN to act as a guide for several neighbouring nodes during the handoff process. The main idea of GB-FH is to re-register the MNs that are predicted to move together. The MN guide prepares itself for the handover before the actual handover processes are performed. According to their analytical analysis and simulation results obtained, the GB-FH scheme measurably reduces the time needed for handover initiation, messages signalling and handover latency compared to the Fast Mobile Internet Protocol Version 6 (FMIPv6). The GB-FH scheme signalling, including the process of its MN registration are illustrated in detail in [
16]. Despite all achievements recorded, the GB-FH still has several limitations: the number of the predictable handover MNs is restricted due to only grou** the MNs that belong to the same network. Furthermore, The MN does not consider the de-registration messages that might occur before registering the MN in the new network, which might increase the handover latency time. In addition, the GB-FH scheme was originally designed according to the principle of the host-based protocols that require the MN to participate in the mobility-related signalling, which surely leads to system performance degradation.
The Correlated MNs Detection Algorithm (CMDA) is used to group MNs based on their Signal-to-Noise Ratio (SNR) and the history of MNs handoff information according to the network-based printable [
17]. This algorithm is developed to reduce the handover and the signalling cost. The idea beyond this work is to group the MNs that approximately reside in the same physical area with the same SNR. The MAG always scans and sends the MN SNR periodically to the LMA in order to group them according to their SNR. Thus, when a MN from the grouped MNs starts its mobility signalling, the MAG sends a Proxy Binding Update (PBU) message to the LMA. The LMA then looks for that MN in its associated group of MNs. If the respective MN has been found, a Proxy Binding Acknowledgment (PBA) message is then sent to the MAG including the Home Network Prefix (HNP) for all the group members in order to accelerate their registration. Subsequently, when a MN movements belongs to this group is detected by a MAG, the MN exchanges a Router Solicitation (RS) message with the MAG. The MAG then directly delivers the HNP created earlier to the MN. Despite the landmark achievement with respect to the signalling cost and the handover latency, this work might group the MNs from different networks but with the same SNR, which increase the false MNs handoff predictions.
The work proposed in [
18] introduces a fast handover through the group-based mechanism. The main goal of this scheme is to group the control messages of sensors that are distributed in the human body. The coordinator is responsible for carrying out the mobility for all the sensors by including sensor IDs within its RS message that is sent to the MAG. The MAG, upon receiving the RS message, starts authenticating each MN with an Authentication, Authorisation, and Accounting (AAA) server. When the authentication is performed successfully, the MAG sends one PBU with the sensor-IDs to the LMA to register the new connected sensors. Once this registration process is completed by the LMA by locating HNPs, a PBA reply message is then sent to the requesting MAG. From the simulation results obtained, this scheme greatly reduces the signalling cost and handover latency. However, This work does not consider the wireless area network, thus heavy signalling is still experienced in this work due to the periodic scanning performed by individual sensors to scan their activity. This work is dedicated to the sensors that reside in one physical area, which always move together.
A new group-based scheme, named a bulk Fast Handover for Proxy Mobile IPv6 (bFP-NEMO), is proposed in [
19] to mitigate the signalling cost in the vehicular networks. This scheme is introduced to establish a tunnel for a group of vehicles instead of each single vehicle. The idea of this work is grou** the MRs when their link layer is detected by the MAG. Then, the MAG delivers an HI message to all the neighbouring MAGs listed in the neighbouring list to establish a pre-tunnel with these MAGs. The results from this simulation demonstrate an enhanced system performance which outperformed the counterpart protocols. However, this work is dedicated to the networks that are equipped with MRs. Furthermore, performing a tunnelling with all neighbours leads to an increase in the tunnelling overhead, especially in the false prediction situation that might occur when the MRs return back to its network. In addition, this work is limited by NEMO that may effect on supporting an efficient mobility for the MNs [
15].
Another PMIPv6-based group mobility management protocol for IoT device is proposed in [
15]. In this protocol, the authors enhanced the operation of PMIPv6 by introducing a multi-node handover method for IoT devices over PMIPv6. This is achieved by using the bulk binding update standard that defines multiple connections’ handoff and revocation operations for a group of mobility sessions [
14]. This solution groups the binding messages using some metrics such as movement similarity [
13] in order to perform a binding for a group of IoT devices. As a result, the performance in terms of scalability and bandwidth is enhanced.
Another work, named Constrained Application Protocol based Group Mobility Management Protocol (CoAP-G), is proposed in [
20] to support mobility management in a web-based Internet-of-Things environment. In this scheme, one sensor is responsible for transmitting the control messages of the body sensors to the web-of-things mobility management system (WMMS). The sensors’ information is maintained by the WMMS. Two tiers of IP addresses are utilised: one for the sensor IP, which is the permanent address, and the other one for the Access Router (AR) address, which is a temporary address. According to the numerical analysis obtained, the CoAP-G has better system performance compared to CoAP protocol. This is due to the incorporation of sensors within the CoAP protocol, which decrease the cost of signalling and the handoff delay [
21].
** the MNs’ binding messages with a special consideration for minimising handover latency and signalling cost. In the proposed scheme, two mechanisms, named Clustered neighbouring MNs (CN-MN) and the Clustered Remote MNs (CR-MN) are introduced to efficiently enhance the mobility management process in the IP-WSNs. In the CN-MN mechanism, a clustering technique is used to group the neighbouring MNs which move simultaneously as a group between two different networks within the CSPMIPv6 domain, as shown in Algorithm 1. In this mechanism, every MN has to continually calculate the RSS value () and compare it with the pre-configuration threshold (), as shown in Algorithm 1. If the MN’s RSS value exceeds the threshold, this MN becomes a Head Cluster (HMN) with an ability to group the neighbouring MNs using the Request Joining (Req-join) and Accept Joining (Acc-join) messages. This is performed to register/de-register them in advance. The HMN, after becoming a head cluster, sends a broadcast message to its neighbouring MNs to form a cluster. Finally, the HMN classifies the successfully joined MNs based on their serving MAG into lists to send their requests to the related MAG to process connections/de-connections a priori.
| Algorithm 1: HMN functionalities. |
![Computers 08 00075 i001]() |
At the MAG side, when the RS is received by the related MAG, the MAG updates its Binding Update List (BUL) and sends a PBU message to the related HMAG, which in turn sends this request to the associated LMA after performing the on side processing, as shown in Algorithm 2. The LMA updates its Binding Cash Entry (BCE). It further creates new prefixes for the HMN and its neighbouring MNs upon successfully receiving the LPBU message sent by the HMAG. Finally, the LMA forwards the created prefixes by sending an LPBA message to the related HMAG. The HMAG now sends it to the related MAG to deliver these new addresses to the connected MNs when they announce their presence. This mechanism is meant to overcome the issues associated with the GB-FH scheme mentioned earlier.
| Algorithm 2: MAG, HMAG and LMA functionalities based on the CN-MN mechanism. |
![Computers 08 00075 i002]() |
With the CR-MN mechanism, the MNs that arrive simultaneously to the same MAG are processed together to reduce the signalling cost, as shown in Algorithm 3. In this mechanism, the MAG simultaneously processes the mobility-related signalling of the MNs that request a new link at the same time. This is done by using one PBU message for all the connected MNs and sending this message to the related HMAG. All subsequent messages and their processing between the HMAG-LMA and LMA-HMAG are similar to the CN-MN mechanism. After the MAG receives the PBA sent by the HMAG, it sends the created HNPs to the new connected MNs using broadcast message (e.g., Media Access Control Address (MAC)) or individual RA message for each connected MN. E-CSPMIPv6 considers the CSPMIPv6’s entities (e.g., LMA, HMAG, or MAG) without any modification to both mechanisms.
| Algorithm 3: MAG, HMAG and LMA functionalities based on the CR-MN mechanism. |
![Computers 08 00075 i003]() |
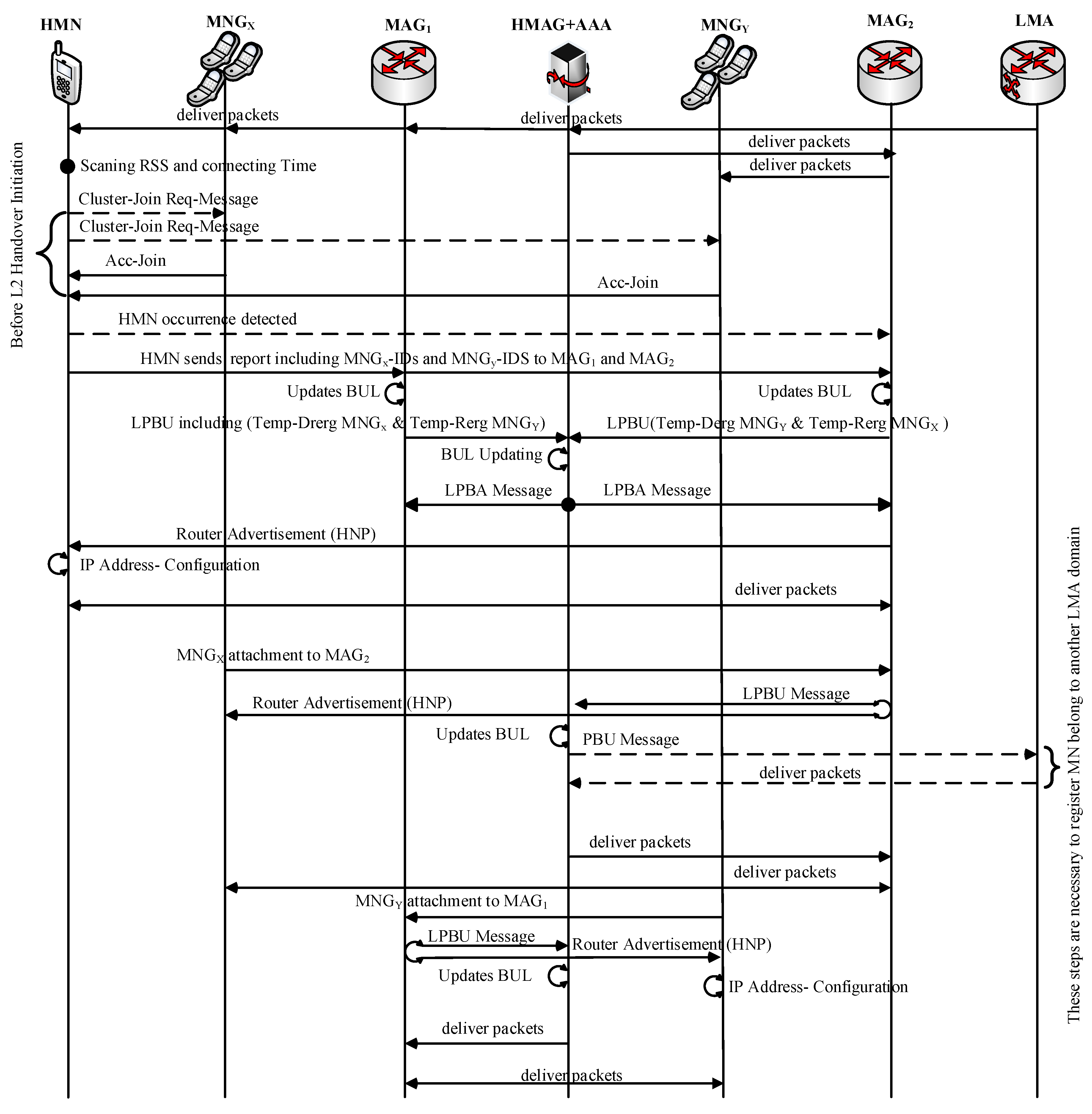
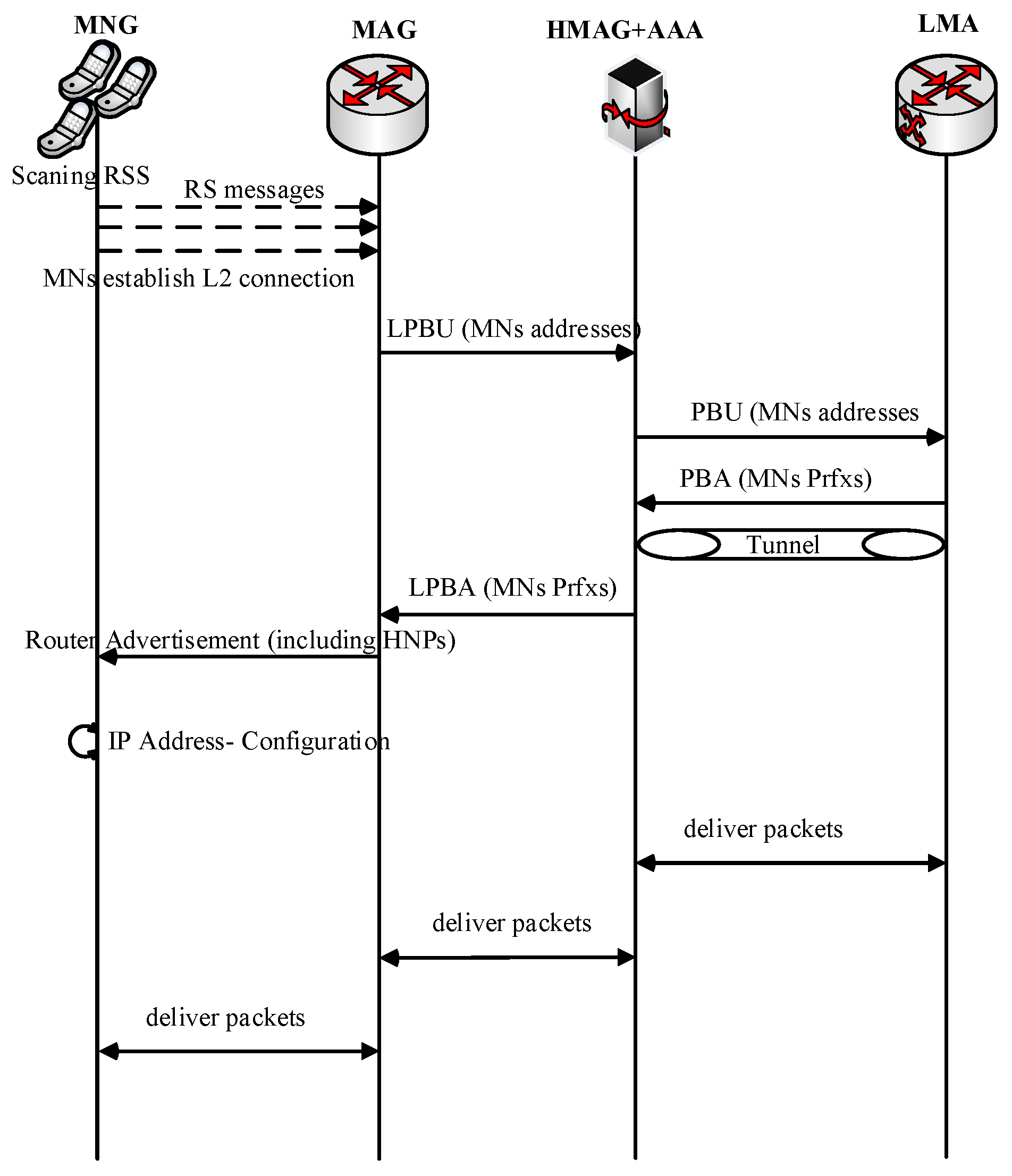
The Flow Diagram of the E-CSPMIPv6 Scheme
Figure 2 and
Figure 3 show the message flow diagram for the proposed E-CSPMIPv6 scheme according to the functions of the CN-MN and CR-MN mechanisms, respectively.
In the proposed E-CSPMIPv6 scheme, the MNs have to exchange some messages before the handover takes place in order to reduce the handover latency. This pre-exchange of messages is initiated to handle the control signalling of a group of MNs. This consequently shortens the handover latency and signalling cost.
The introduction of MNs in this study is very pertinent, as it improves the overall system performance in terms of handover latency and signalling cost. It thus makes the system suitable and deployable for critical real-time applications. Several studies (e.g., [
23,
24,
25]) added extra functions (e.g., IEEE 802.21 Media Independent Handover (MIH)) to improve the system efficiency [
26].
In
Figure 2, each MN continuously monitor its RRS for any change. When the RSS value surpasses the
threshold, the MN sends Req-join to neighbouring MNs requesting them to form a cluster in which it acts as the cluster Head (HMN). The neighbouring MNs that join the cluster successfully become members of the cluster. To enhance the system performance in terms of handover latency and signalling cost, the proposed scheme reduces the cluster size (i.e., clustering the nearest neighbouring nodes) by minimising the Req-join coverage area. Moreover, the mechanism for grou** the MNs is performed at an appropriate time to reduce false prediction. This is achieved by setting
threshold to measure the MNs’ RSS from their old MAG and timing threshold value to measure their connected period time in order to prevent the recently connected MNs from being grouped, as depicted in Algorithm 1. This leads to minimal handover latency and signalling cost. After that, the MNs associated with same serving MAG, together with those associated with the target MAG respond by sending an Acc-join message to their HMN. Upon receiving the Acc-join messages, the HMN stores the senders’ addresses (e.g., MAC addresses) in its database for future use (pre-registration/de-registration). Since the HMN receives Acc-join messages from MNs belonging to different networks, it keeps them in different lists based on their network. All the aforementioned messages are exchanged before the handover takes place. Thus, there is no preparatory stage for the handover process (handover initiation and handover execution).
When the HMN reaches
threshold value, the HMN sends an RS message to the new MAG requesting to be registered. The RS message also carries information about the created list of the cluster members into its database, which is to be included in the registration process. The RS message is modified to carry the addresses stored in the HMN database lists. Moreover, the HMN sends a report message to the serving MAG and its new MAG, as in [
27], to inform them to pre-register/de-register their members. In addition, the HMN keeps receiving new Req-join messages from new neighbouring MNs as long as these messages are coming from MNs that are still connected to their old MAG. This is performed in order to increase the opportunity to pre-register/de-register MNs, especially when the MNs come in a sequential order (sparse network).
Thereafter, the new MAG registers the HMN and temporarily registers the neighbouring MNs that belong to the serving MAG. It also temporary de-registers the neighbouring MNs that are near to leave its coverage area. This is done by sending a modified Local Proxy Binding Update (LPBU) message that is compatible with the proposed E-CSPMIPv6 scheme to the related Head MAG (HMAG). Similarly, the serving MAG temporarily registers/de-registers the MNs based on their CoAs. This temporary pre-register/de-register process increases the prediction accuracy.
After the HMAG receives the LPBU messages from serving MAG, the new MAG looks up the information of the HMN together with its associated members (i.e., its neighbouring MNs) and updates this information accordingly inside its database based on the request of the HMN and its neighbouring MNs.The HMAG sends a PBU message to its related LMA requesting that its HMN be registered, and the neighbouring MNs be temporarily registered/de-registered.
Once the LMA receives the request message, it updates its BCE for each MN based on the type of their registration. A new flag, named S, is used for the mobility-related signalling messages to distinguish between the temporary registration and the actual registration. In addition, the LMA sends a PBA message carrying the HNPs to the corresponding HMAG. Fields such as number of HNP options and the HNP options in the PBU and PBA messages are utilised to determine the requested number of HNP. Then, the corresponding HMAG sends a Local Proxy Binding Acknowledgment (LPBA) message, which carries the HNPs of the MNs, to the requesting MAGs after updating its Binding Update table (BUL) table. When the MAGs successfully receive the LPBA message from the corresponding HMAG, the new MAG registers the HMN together with the neighbouring MNs that joined for temporary registrations/de-registrations. This registration is performed by the serving MAG and the new MAG updates its BUL tables according to the neighbouring CoAs. Subsequently, the new MAG sends a Router Advertisement (RA) message including the HMN’s HNP and the addresses of the MNs that wish to join its network in a broadcast manner. The aim of the broadcasted RA message is to deliver the HNP to the HMN and to inform the neighbouring MNs about their successful joining. To group the MNs’ signalling efficiently, the control messages are either extended such as RA and RS or the existing fields such as HNP are utilised. The original RS and RA control message that are used by the standard PMIPv6 protocol can be represented as Header, ICMP, MN-ID and Link-ID, where the Header contains the source and destination addresses, ICMP is a TCP/IP layer and MN-ID and Link-ID refer to MN-identifier and link-layer identifier, respectively. The Link-ID identifier contains a Header, ICMP and HNP, where HNP contains the MN’s home network prefix. These messages are extended to carry several MNs’ addresses and the new format become: Header, ICMP, MN-No, MN-ID1, Link-ID1, MN-ID2, Link-ID2, MN-IDn, Link-IDn, etc. The Reg-join and Acc-join messages are the same for RS and RA except that the link layer identifier represents the serving network address only. Similarly, there are multiple HNP options in the PBU message, and the number of HNP options indicates the amount of requested prefixes. The Prefix field of each HNP option is set to ZERO.
The HMN completes its registration processes by configuring its IP address when it receives the RA message from the new MAG successfully. Subsequently, any other neighbouring MN that has been temporarily pre-registered by the new MAG, sends an RS message to the new MAG to inform it of its presence. The new MAG sends an RA message to a specific neighbouring MN including the HNP. Similarly, it sends an LPBU message to the corresponding HMAG to activate the HNP of this MN. The HMAG activates the HNP of this neighbouring MN and then redirects the packets to the new CoA if the neighbouring MN belongs to this HMAG. Otherwise, the HMAG sends PBU to the LMA to activate the HNP of this neighbouring MN, as depicted in Algorithms 1 and 2. Therefore, the time required by the MN to configure its IP address is performed concurrently with the last two steps. Note that the time of the last two steps is negligible.
The proposed E-CSPMIPv6 scheme has several benefits with respect to its CN-MN mechanism, as illustrated below.
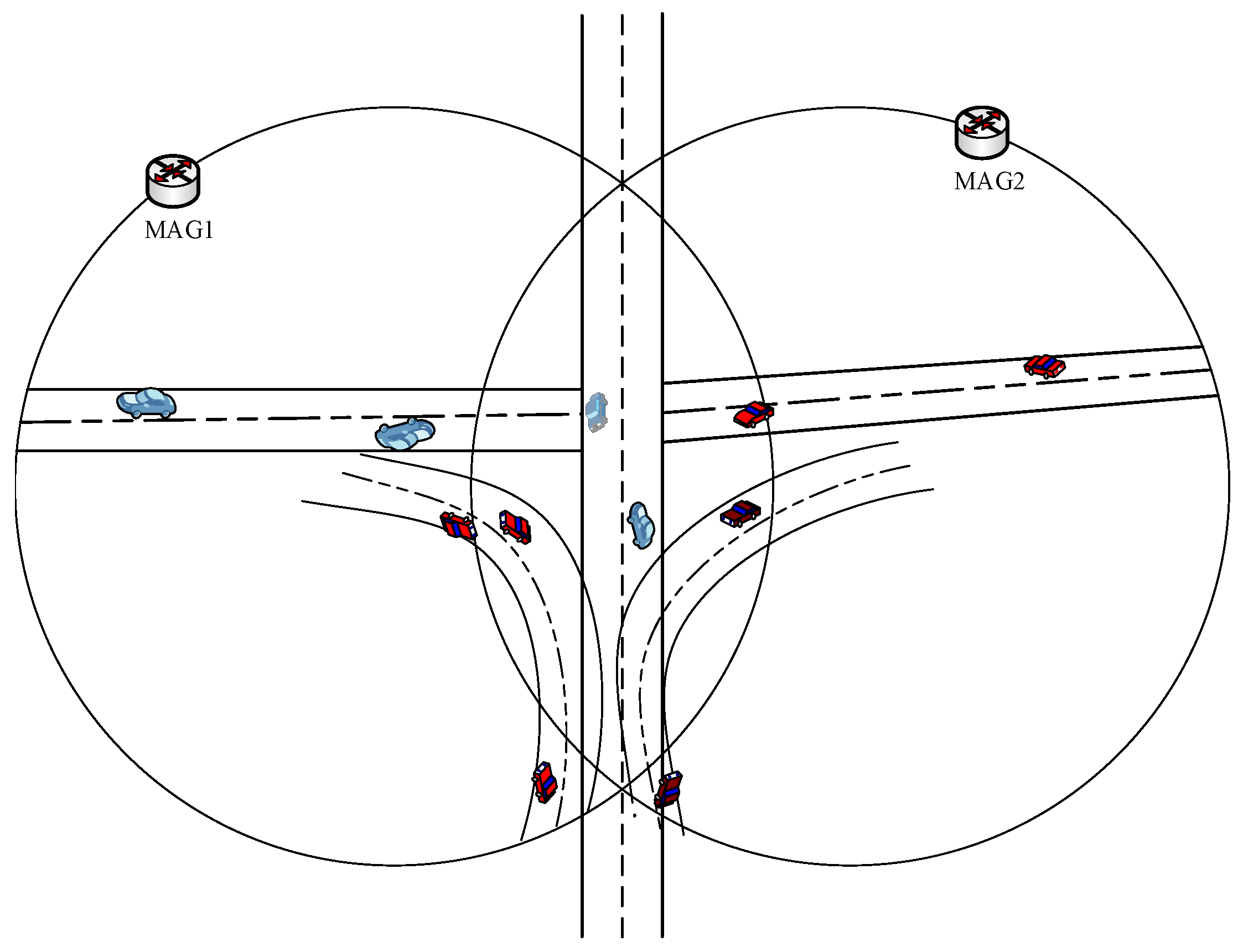
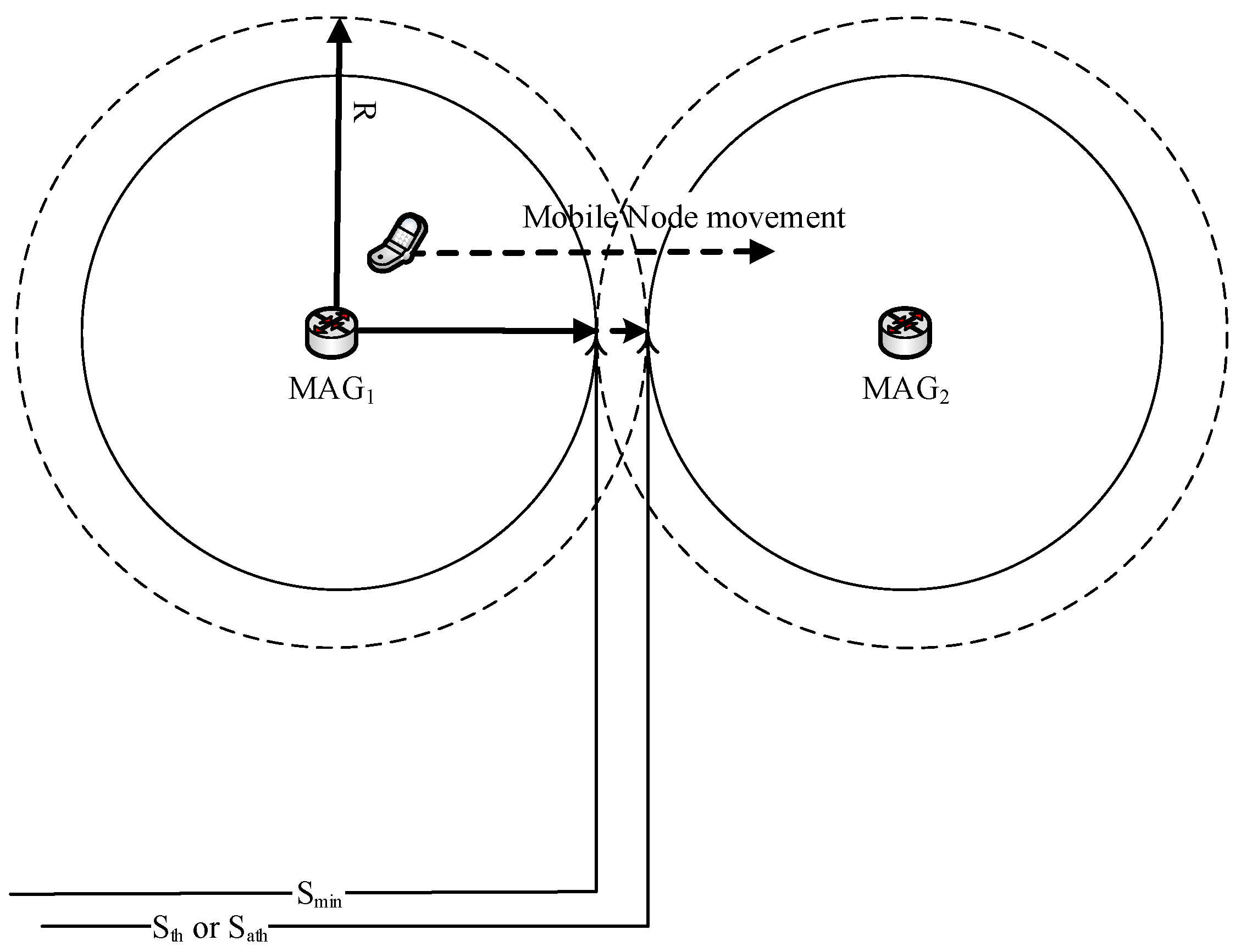
The CN-MN greatly reduces the false prediction of MNs movement by clearly preventing newer MNs connected to the serving MAG from joining the cluster. This advantage can be justified by carefully observing
Figure 4. As shown in
Figure 4, the issue of the diamond interchange in the overlap** area that is covered by multiple MAGs is taken into consideration in the proposed E-CSPMIPv6 scheme. This is done by applying a time threshold value that prevents an MN from sending an Acc-join message if this MN has been connected to its serving MAG for a period less than the threshold value.
The handover latency is reduced by eliminating the de-registration step from the handover process. Instead, the list created earlier by the HMN is sent to both MAGs (i.e., the serving and the new MAG) during the HMN handoff. The prior de-registration increases the system prediction accuracy by increasing the number of handoff MNs in the list prediction, which invariably reduces the handover latency and the signalling cost, and minimises bandwidth waste.
The HMN keeps receiving the request joining messages after completing its registration processes until a predefined threshold is reached. This is applied to increase the pre-registration of the MNs as much as possible, especially in the sparse networks.
In the second mechanism of the proposed protocol (i.e., CR-MN), the MNs that arrive at the same time at the same MAG are considered, as shown in
Figure 3. In the reviewed protocols in
Section 2, the mobility-related signalling is performed for each MN, even if the MNs arrive simultaneously to the covering area of the same MAG. This increases both signalling cost and bandwidth waste. To address this issue, the proposed CR-MN mechanism allows simultaneous registration of several MNs that arrive at the same time, as illustrated next.
When the movements of several MNs are detected by the MAG at the same time, the MAG has two options for registering these MNs. In the first option, after the MAG detects the MNs movements, it immediately sends an LBPU message together with the MNs information to pre-register the detected MNs. In the second option, the MAG must wait for a while to collect the RS messages sent by the MNs that are detected by the MAG. The waiting time should be very short to avoid degradation in system performance. In the proposed mechanism, a prediction technique is used to alleviate the delay that could occur in the second option (i.e., timer). The scenario of this mechanism is implemented as follows:
In this mechanism, the threshold is employed by the MAGs to measure the RSS. When MNs are detected by the new MAG and the RSS threshold is reached, the MAG expects that the MNs will soon change their link layer. Subsequently, the MAG adds the addresses of these MNs to a list that has been created to group the MNs that are expected to perform handoff simultaneously. The MAG has to wait until one of these expected MNs, which is already added to the list, requires an actual handover. At this time, the MAG sends an LPBU including all the MAC addresses of the MNs within the list to the related HMAG to register them.
The HMAG, LMA and MAG behave similarly to CSPMIPv6 protocol with regards to registering the MNs by exchanging LPBU, PBU, PBA, LPBA and RA messages, as shown in
Figure 3. Finally, the MNs receive the RA message, which is sent in a broadcast manner by the MAG to inform the MNs about their successful joining. When detected by the New MAG (NMAG), each MN informs the NMAG of its presence by the exchange of RS and RA messages. Accordingly, the NMAG sends the MN’s HNP to the present MN to complete its registration (i.e., configures the new CoA).
In the CR-MN mechanism, it is clearly observed that the signalling cost and the burden on the bandwidth are reduced as a result of processing the mobility signalling for several MNs simultaneously.
7. Conclusions
In this article, an efficient E-CSPMIPv6 scheme is introduced to provide a seamless handoff within the PMIPv6 domain. This is done by manipulating the handoff operations for several MNs simultaneously based on the CN-MN and CR-MN mechanisms.
In the CN-MN mechanism, pre-registration/de-registration processes are performed for the MNs that move in proximity with each other. The MN, which violates the pre-defined threshold requirements clustering with its neighbouring MNs, eventually becomes the cluster head. Thereafter, the cluster head takes the responsibility of performing the initial binding registration processes for its members. The mobility-related signalling messages such as RS and RA have been extended to carry multiple addresses. The HNP and a number of HNP options fields in PBU, LPBU, PBA and LPBA messages are used. The grou** of MNs into clusters ensures low signalling, reduced end-to-end delay and low handover latency.
In the CR-MN mechanism, the mobility-related signalling messages are processed simultaneously for several MNs, which perform the L2 handover at the same time as the new MAG. This is done by grou** the MNs’ L2 request messages by the new MAG and sending these requests as one message to the other CSPMIPv6 network entities. The bandwidth overhead is reduced by utilising the HNP and number of HNP option fields during the exchange of binding messages between the network entities.
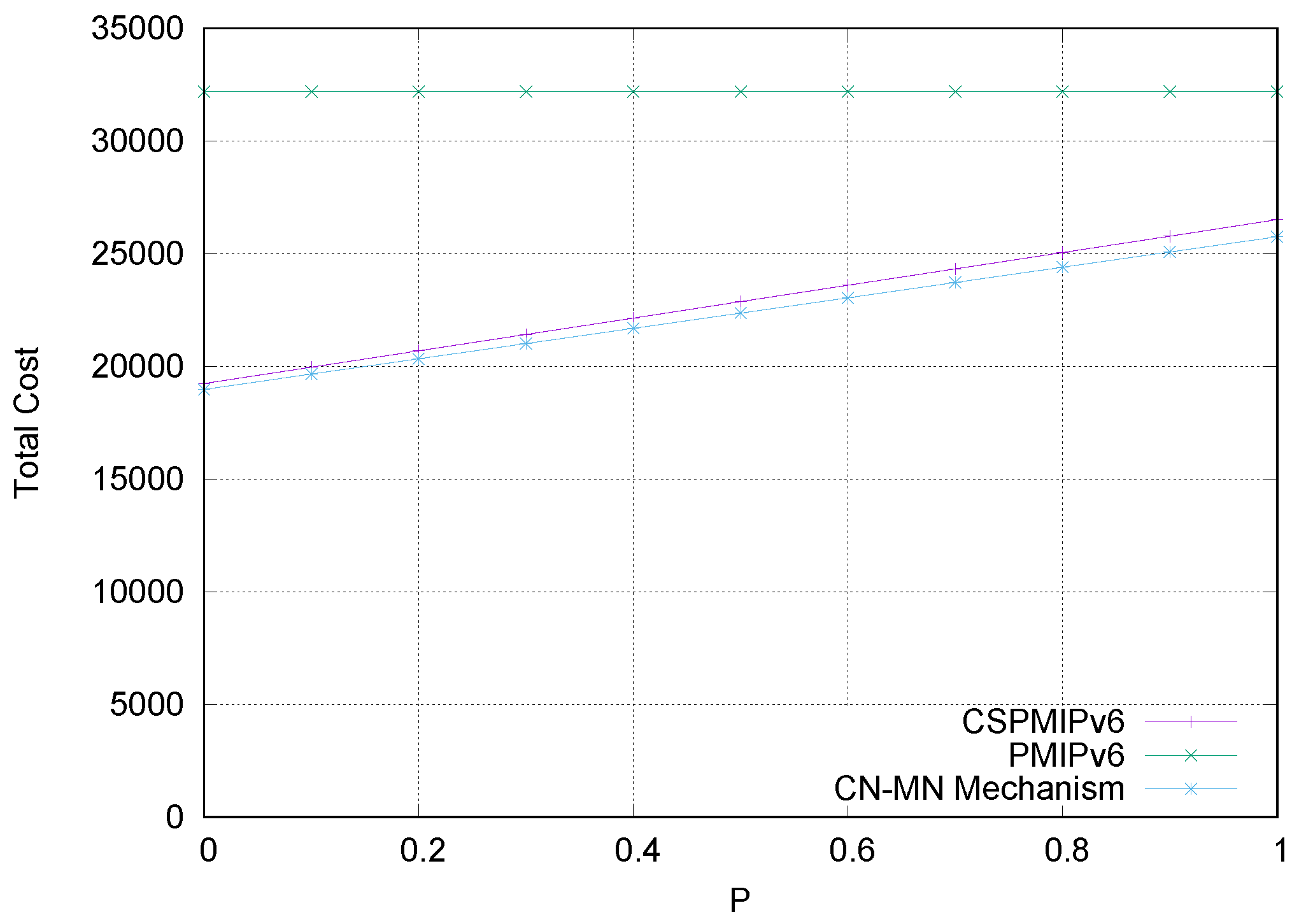
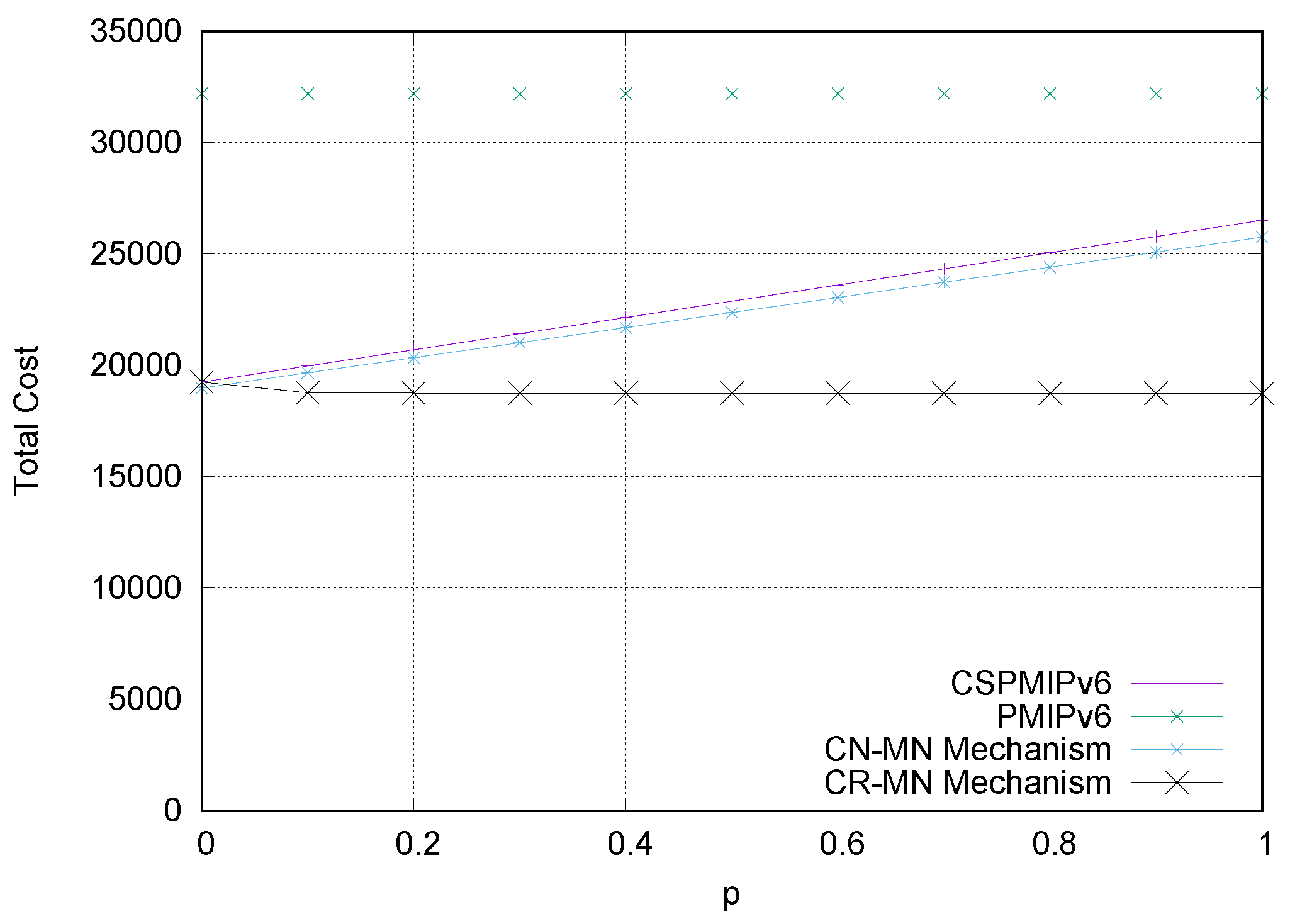
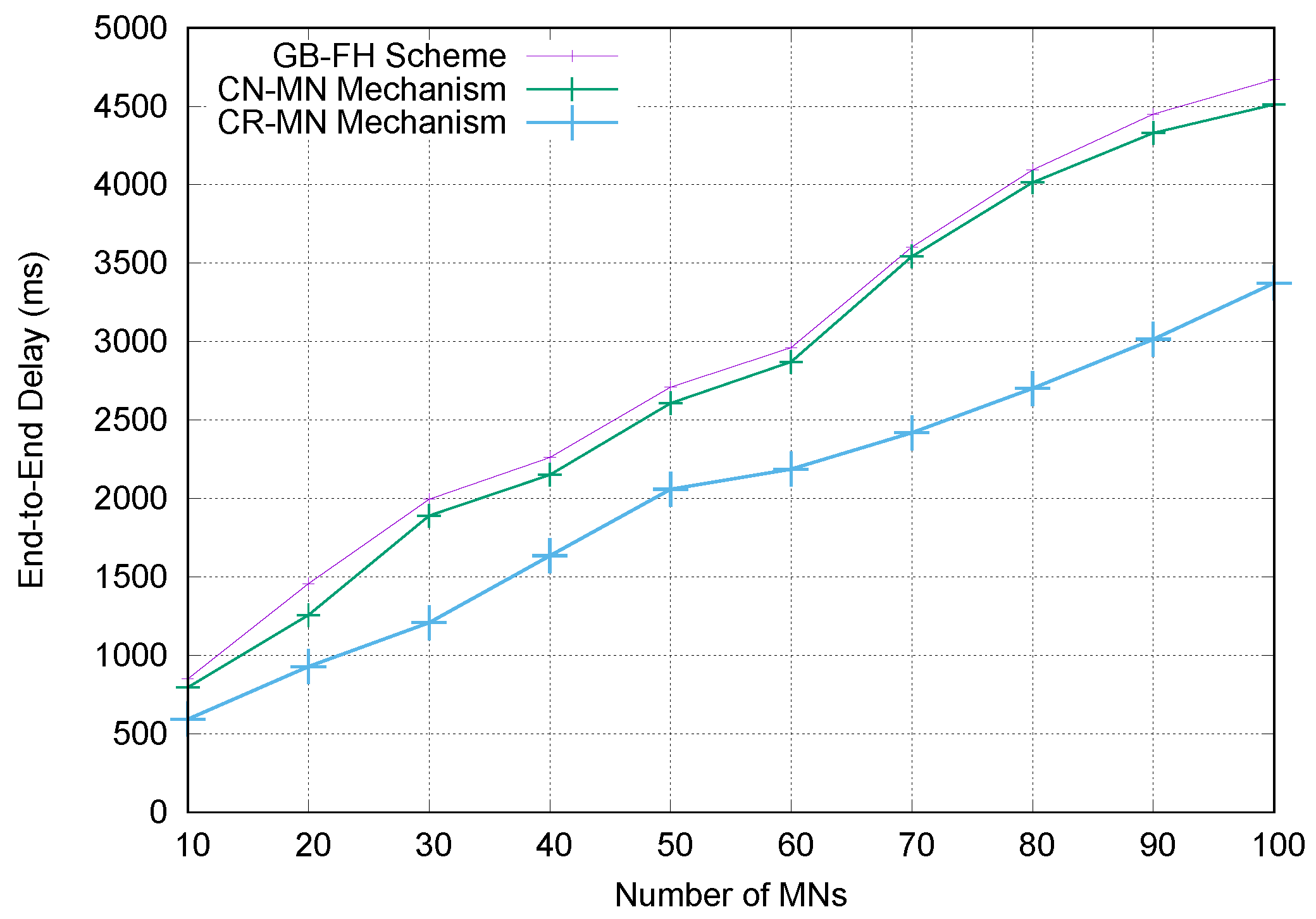
Finally, numerical analysis and simulation results demonstrate that the proposed E-CSPMIPv6 scheme produces better performance in terms of handoff latency and signalling cost in comparison with the PMIPv6 standard protocol, CSPMIPv6 protocol and GB-FH scheme.

 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}