
An Analysis of Vocal Features for Parkinson’s Disease Classification Using Evolutionary Algorithms

 ,
,
Abstract
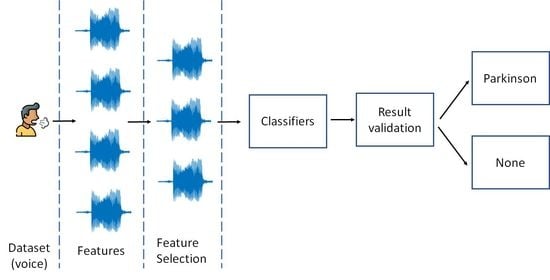
:
1. Introduction
2. Literature Review
2.1. Related Works
2.2. Feature Selection
2.3. Classification Algorithms
2.3.1. Support Vector Machine (SVM)
2.3.2. Nearest Neighbor (KNN)
2.3.3. Decision Tree (DT)
2.3.4. LightGBM (LGBM)
3. Methodology
3.1. Parkinson’s Disease Dataset
3.2. Preprocessing Data
3.3. Grey Wolf Optimization
- First, the wolves follow, observe, chase, and get close to the prey.
- Next, they approach, encircle around the prey, and harass it until the prey stops moving around.
- Finally, they attack the stationary prey and finish it.
4. Result Analysis
4.1. Performance Metrics
- True positives (TP): the model predicted true, and the actual value is true, meaning the PWP is diagnosed with Parkinson’s disease.
- True negative (TN): the model predicted false, and the actual value is false, meaning the healthy control is predicted to be healthy.
- False positive (FP): the model predicted true, and the actual value is false/TypeI error, meaning the healthy control is inaccurately diagnosed as PWP
- False negative (FN): the model predicted false, and the actual value is false/Type II error, meaning the PWP is inaccurately predicted as healthy control.
4.2. Model Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jankovic, J. Parkinson’s disease: Clinical features and diagnosis. J. Neurol. Neurosurg. Psychiatry 2008, 79, 368–376. [Google Scholar] [CrossRef] [PubMed]
- Cova, I.; Priori, A. Diagnostic biomarkers for Parkinson’s disease at a glance: Where are we? J. Neural Transm. 2018, 125, 1417–1432. [Google Scholar] [CrossRef] [PubMed]
- Gibb, W.R.; Lees, A.J. The relevance of the Lewy body to the pathogenesis of idiopathic Parkinson’s disease. J. Neurol. Neurosurg. Psychiatry 1988, 51, 745–752. [Google Scholar] [CrossRef] [PubMed]
- Postuma, R.B.; Berg, D.; Stern, M.; Poewe, W.; Olanow, C.W.; Oertel, W.; Obeso, J.; Marek, K.; Litvan, I.; Lang, A.E.; et al. MDS clinical diagnostic criteria for Parkinson’s disease. Mov. Disord. 2015, 30, 1591–1601. [Google Scholar] [CrossRef]
- Madetko, N.; Migda, B.; Alster, P.; Turski, P.; Koziorowski, D.; Friedman, A. Platelet-to-lymphocyte ratio and neutrophil-tolymphocyte ratio may reflect differences in PD and MSA-P neuroinflammation patterns. Neurol. Neurochir. Pol. 2022, 56, 148–155. [Google Scholar] [CrossRef]
- Alster, P.; Madetko, N.; Koziorowski, D.; Friedman, A. Progressive Supranuclear Palsy—Parkinsonism Predominant (PSP-P)—A Clinical Challenge at the Boundaries of PSP and Parkinson’s Disease (PD). Front. Neurol. 2020, 11, 108. [Google Scholar] [CrossRef]
- Antonio, S.; Giovanni, C.; Francesco, A.; Pietro, D.L.; Mohammad, A.-W.; Giulia, L.; Simona, S.; Antonio, P.; Giovanni, S. Frontiers|Voice in Parkinson’s Disease: A Machine Learning Study. Front. Neurol. 2022, 13, 831428. [Google Scholar] [CrossRef]
- Le, M.T.; Vo, M.T.; Pham, N.T.; Dao, S.V.T. Predicting heart failure using a wrapper-based feature selection. Indones. J. Electr. Eng. Comput. Sci. 2021, 21, 1530–1539. [Google Scholar] [CrossRef]
- Le, T.M.; Vo, T.M.; Pham, T.N.; Dao, S.V.T. A Novel Wrapper–Based Feature Selection for Early Diabetes Prediction Enhanced With a Metaheuristic. IEEE Access 2021, 9, 7869–7884. [Google Scholar] [CrossRef]
- Le, M.T.; Thanh Vo, M.; Mai, L.; Dao, S.V.T. Predicting heart failure using deep neural network. In Proceedings of the 2020 International Conference on Advanced Technologies for Communications (ATC), Nha Trang, Vietnam, 8–10 October 2020; pp. 221–225. [Google Scholar]
- Le, T.M.; Pham, T.N.; Dao, S.V.T. A Novel Wrapper-Based Feature Selection for Heart Failure Prediction Using an Adaptive Particle Swarm Grey Wolf Optimization. In Enhanced Telemedicine and e-Health: Advanced IoT Enabled Soft Computing Framework; Marques, G., Kumar Bhoi, A., de la Torre Díez, I., Garcia-Zapirain, B., Eds.; Studies in Fuzziness and Soft Computing; Springer International Publishing: Cham, Switzerland, 2021; pp. 315–336. ISBN 978-3-030-70111-6. [Google Scholar]
- Yana, Y.; Fary, W.; John, R.W.; Mary, L. Articulatory Movements During Vowels in Speakers With Dysarthria and Healthy Controls. J. Speech Lang. Hear. Res. 2008, 51, 596–611. [Google Scholar]
- Sakar, C.O.; Serbes, G.; Gunduz, A.; Tunc, H.C.; Nizam, H.; Sakar, B.E.; Tutuncu, M.; Aydin, T.; Isenkul, M.E.; Apaydin, H. A comparative analysis of speech signal processing algorithms for Parkinson’s disease classification and the use of the tunable Q-factor wavelet transform. Appl. Soft Comput. 2019, 74, 255–263. [Google Scholar] [CrossRef]
- Tuncer, T.; Dogan, S.; Acharya, U.R. Automated detection of Parkinson’s disease using minimum average maximum tree and singular value decomposition method with vowels. Biocybern. Biomed. Eng. 2020, 40, 211–220. [Google Scholar] [CrossRef]
- Polat, K. A Hybrid Approach to Parkinson Disease Classification Using Speech Signal: The Combination of SMOTE and Random Forests. In Proceedings of the 2019 Scientific Meeting on Electrical-Electronics & Biomedical Engineering and Computer Science (EBBT), Istanbul, Turkey, 24–26 April 2019; pp. 1–3. [Google Scholar]
- Solana-Lavalle, G.; Rosas-Romero, R. Analysis of voice as an assisting tool for detection of Parkinson’s disease and its subsequent clinical interpretation. Biomed. Signal Process. Control 2021, 66, 102415. [Google Scholar] [CrossRef]
- Gunduz, H. Deep Learning-Based Parkinson’s Disease Classification Using Vocal Feature Sets. IEEE Access 2019, 7, 115540–115551. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, H.; Liu, R.; Lv, W.; Wang, D. t-Test feature selection approach based on term frequency for text categorization. Pattern Recognit. Lett. 2014, 45, 1–10. [Google Scholar] [CrossRef]
- Kohli, S.; Kaushik, M.; Chugh, K.; Pandey, A.C. Levy inspired Enhanced Grey Wolf Optimizer. In Proceedings of the 2019 Fifth International Conference on Image Information Processing (ICIIP), Shimla, India, 15–17 November 2019; pp. 338–342. [Google Scholar]
- Ma, X.; Sha, J.; Wang, D.; Yu, Y.; Yang, Q.; Niu, X. Study on a prediction of P2P network loan default based on the machine learning LightGBM and XGboost algorithms according to different high dimensional data cleaning. Electron. Commer. Res. Appl. 2018, 31, 24–39. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finely, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4 December 2017. [Google Scholar]
- Tsanas, A.; Little, M.A.; McSharry, P.E.; Spielman, J.; Ramig, L.O. Novel Speech Signal Processing Algorithms for High-Accuracy Classification of Parkinson’s Disease. IEEE Trans. Biomed. Eng. 2012, 59, 1264–1271. [Google Scholar] [CrossRef]
- Tiwari, A.K. Machine Learning Based Approaches for Prediction of Parkinson’s Disease. Mach. Learn. Appl. Int. J. 2016, 3, 33–39. [Google Scholar] [CrossRef]
- Murty, K.S.R.; Yegnanarayana, B. Combining evidence from residual phase and MFCC features for speaker recognition. IEEE Signal Process. Lett. 2006, 13, 52–55. [Google Scholar] [CrossRef]
- Godino-Llorente, J.I.; Gomez-Vilda, P.; Blanco-Velasco, M. Dimensionality Reduction of a Pathological Voice Quality Assessment System Based on Gaussian Mixture Models and Short-Term Cepstral Parameters. IEEE Trans. Biomed. Eng. 2006, 53, 1943–1953. [Google Scholar] [CrossRef]
- Peker, M. A decision support system to improve medical diagnosis using a combination of k-medoids clustering based attribute weighting and SVM. J. Med. Syst. 2016, 40, 116. [Google Scholar] [CrossRef] [PubMed]
- Tufekci, Z.; Gowdy, J.N. Feature extraction using discrete wavelet transform for speech recognition. In Proceedings of the IEEE SoutheastCon 2000. “Preparing for The New Millennium” (Cat. No.00CH37105), Nashville, TN, USA, 7–9 April 2000; pp. 116–123. [Google Scholar]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Emary, E.; Zawbaa, H.M.; Hassanien, A. Binary grey wolf optimization approaches for feature selection. Neurocomputing 2016, 172, 371–381. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.-I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Title 1 | Measure | Explanation | # of Feature |
|---|---|---|---|
| Baseline features | Jitter variants | Capture instabilities of the oscillating pattern of the vocal folds & its subset quantify the cycle-to-cycle changes in the fundamental frequency. | 5 |
| Shimmer variants | Capture instabilities of the oscillating pattern of the vocal folds & its subset quantify the cycle-to-cycle changes in the fundamental amplitude. | 6 | |
| Fundamental frequency parameters | the frequency of focal folds vibration. Mean, median, standard deviation, minimum & maximum values were used | 5 | |
| Harmonicity parameters | Due to incomplete vocal fold closure, increased noise components occur in speech pathologies. Harmonics to Noise Ratio and Noise to Harmonics Ratio parameters quantify the ratio of signal information over noise, which were used as features. | 2 | |
| Recurrence Period density Entropy (RPDE) I | Provides information about the ability of the vocal fold oscillations and quantifies the deviation form F0 | 1 | |
| Detrended Fluctuation Analysis (DFA) | Quantifies the stochastic self-similarity of the turbulent noise. | 1 | |
| Pitch Period Entropy (PPE) | Measures the impaired control of fundamental frequency F0 by using a logarithmic scale | 1 | |
| Time-frequency features | Intensity Parameters | Related to the power of speech signal in dB. Mean, minimum and maximum intensity values were used | 3 |
| Formant Frequencies | Amplified by the vocal tract, the first four formants were used as features. | 4 | |
| Bandwidth | The frequency range between the formant frequencies. The first four bandwidths were used as features. | 4 | |
| Mel frequency cepstral coefficients (MFCCs) | MFCCs | Catch the PD effects in the vocal tract separately from the vocal folds | 84 |
| Wavelet Transform based Features | Wavelet Transform (WT) features related to F0 | Quantify the deviation in F0 | 182 |
| Vocal fold features | Glottis Quotient (GQ) | a measure of periodicity in glottis movements that provides information about the opening and closing duration of the glottis | 3 |
| Glottal to Noise Excitation (GNE) | Quantifies the extent of turbulent noise caused by incomplete vocal fold closure in the speech signal. | 6 | |
| Vocal Fold Excitation Ratio (VEER) | Quantities the amount of noise, produced due to the pathological vocal fold vibration using non-linear energy at entropy concepts. | 7 | |
| Empirical Mode Decomposition (EMD) | Decompose a speech signal into elementary signal components by using adaptive basis functions & | ||
| Energy/entropy values obtained from these components are used to quantify noise. | 6 | ||
| Tunable Q-factor Wavelet Transform (TQWT) | TQWT | A more extensive quantification method for fundamental frequency deviation as compared to WT I | 432 |
| Classifier | Accuracy | Precision | Recall | F1-Score | AUC | Computational Time | |
|---|---|---|---|---|---|---|---|
| k-NN | Baseline model | 0.862 | 0.857 | 0.979 | 0.914 | 0.75 | 0.443 |
| Proposed model | 0.878 | 0.869 | 0.986 | 0.923 | 0.316 | 0.878 | |
| SVM | Baseline model | 0.841 | 0.840 | 0.972 | 0.901 | 0.71 | 0.560 |
| Proposed model | 0.866 | 0.887 | 0.943 | 0.914 | 0.527 | 0.866 | |
| DT | Baseline model | 0.810 | 0.878 | 0.865 | 0.871 | 0.76 | 0.640 |
| Proposed model | 0.795 | 0.850 | 0.886 | 0.868 | 0.744 | 0.795 | |
| Proposed LGBM | Baseline model | 0.905 | 0.902 | 0.979 | 0.939 | 0.83 | 2.056 |
| Proposed model | 0.894 | 0.895 | 0.972 | 0.932 | 1.926 | 0.894 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dao, S.V.T.; Yu, Z.; Tran, L.V.; Phan, P.N.K.; Huynh, T.T.M.; Le, T.M. An Analysis of Vocal Features for Parkinson’s Disease Classification Using Evolutionary Algorithms. Diagnostics 2022, 12, 1980. https://doi.org/10.3390/diagnostics12081980
Dao SVT, Yu Z, Tran LV, Phan PNK, Huynh TTM, Le TM. An Analysis of Vocal Features for Parkinson’s Disease Classification Using Evolutionary Algorithms. Diagnostics. 2022; 12(8):1980. https://doi.org/10.3390/diagnostics12081980
Chicago/Turabian StyleDao, Son V. T., Zhiqiu Yu, Ly V. Tran, Phuc N. K. Phan, Tri T. M. Huynh, and Tuan M. Le. 2022. "An Analysis of Vocal Features for Parkinson’s Disease Classification Using Evolutionary Algorithms" Diagnostics 12, no. 8: 1980. https://doi.org/10.3390/diagnostics12081980