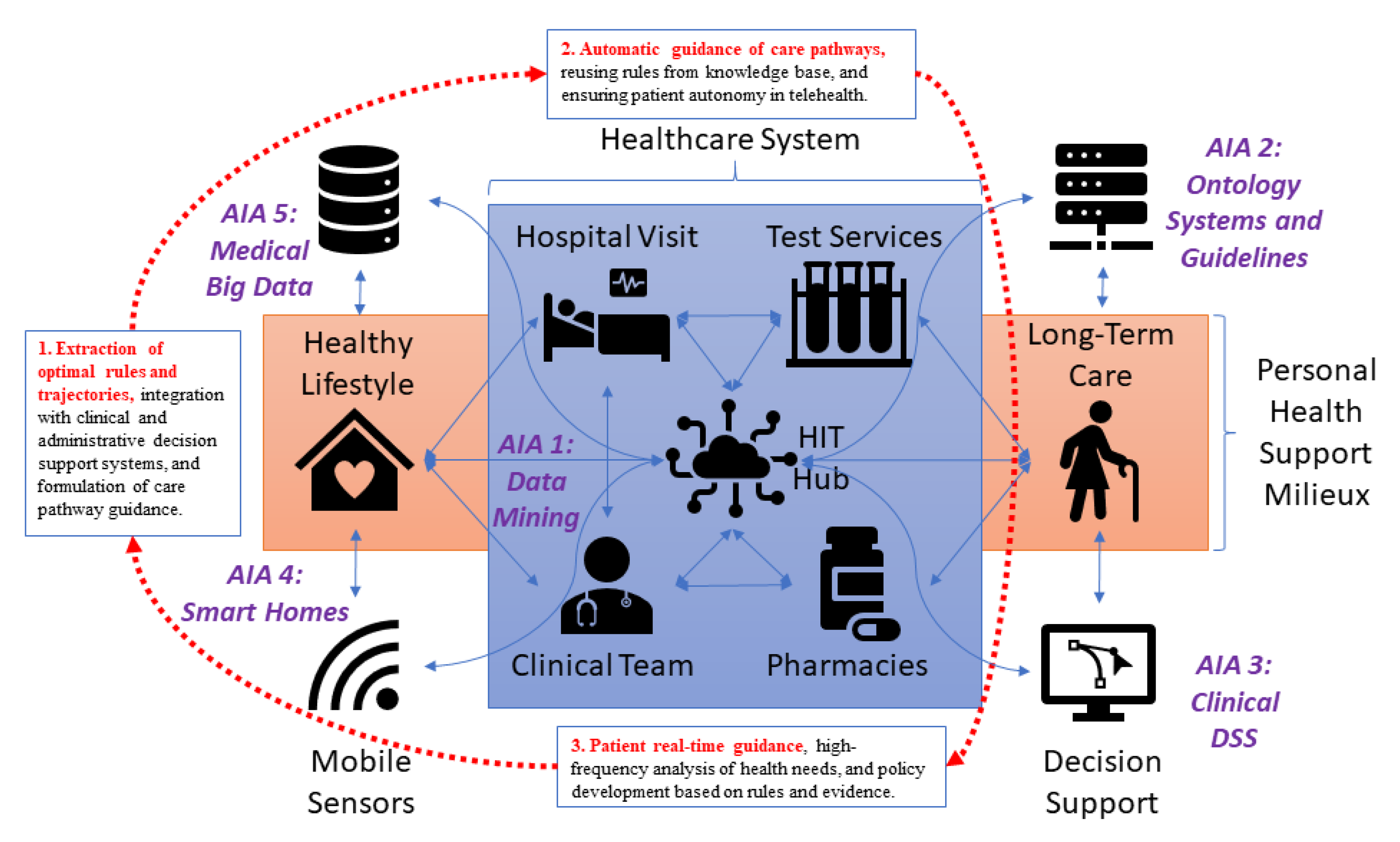
3.1. Data Mining
Data mining is the process of extraction of knowledge and features from data using automatic or semiautomatic methods, it combines machine learning and data science. Indeed, data mining describes, discovers relevant patterns, associations, and knowledge to make predictions, according to pre-established criteria. In healthcare, data mining is becoming increasingly popular and essential. There is large potential for use of data mining in healthcare. These can be grouped as the management of healthcare, evaluation of diagnosis and treatment effectiveness; customer relationship management; detection of fraud and abuse.
Applications of data mining techniques in breast cancer diagnosis, treatment, and prognosis was the subject of a study provided in [
3]. Generally, two phases for making the decisions are distinguished in the medical world: differential diagnosis (DD) and final or provisional diagnosis (FD). In the first phase the medical history of the patients, the symptoms of disease, the results of different laboratory tests (blood testing, etc.) are perceived by physicians as the input data. The latter are handled by physicians based on their medical knowledge for disease diagnosis. In the second stage and given the identified disease, first recommendations and treatments would start. Until now, one of the important challenges in cancer treatment is to determine the most common symptoms that can help in cancer diagnosis. There were many research studies conducted to identify the patterns of cancers and create a smart method for diagnosis of tumors in the early stages. The method also suggests the best treatments. To identify kinds of cancers (benign breast tumors from malignant ones), most of physicians undertake surgical biopsy. However, most of them believed that biopsy is a critical task and should be prevented when possible. Consequently, proposing a smart system that can help physicians to determine the type of cancer and avoid surgical biopsy would be helpful for patients as well as for physicians. In [
3], the authors attempted to cover research works related to diagnosis of breast cancers, when applying various techniques of data mining along with their results. Most of the reviewed research works (on diagnosis, treatment, or prognosis of breast cancers) are concerned with comparing the accuracy rate of data mining various algorithms or techniques. There is not yet a tool to automatically diagnose or predict breast cancer. Further, there is no research work that applies customized features to offer the best treatments to patients.
In [
4] Lashari et al. reviewed and analyzed the current medical data classification practices, advancements, and prospects using data mining. They highlighted the main approaches used to enhance classification accuracy. There is a wide literature which suggests that data mining is very effective for the classification task.
Among the algorithms of data mining used in healthcare applications are the following: decision trees [
5,
6,
7,
8,
9], neural networks [
10,
11,
12,
13,
14,
15], SVM [
16,
17,
18,
19], k-means [
20,
21,
22], logical regression [
23], KNN (K-nearest neighbors) [
24], and naïve Bayes classifier [
25,
26,
27]. These algorithms can be combined to improve the data analysis process as it is done in [
28] where the authors combined random forest, decision trees, neural network, SVM, logistic regression, and KNN algorithms to find out the health and anticipate the mortality risks of patients contaminated with COVID-19. The purpose of the application is to help hospitals to decide on the patient priority order when the system is submerged and avoid delays in dispensing to patients the needed care.
COVID-19 has had a lot of interest from the medical informatics community since its emergence. Deep learning algorithms are widely used as in [
29] where they are combined with CT images to screen for COVID-19. The authors proposed a deep learning algorithm framework to extract specific graphical features from CT images and propose a clinical diagnosis in front of the pathogenic test. The ultimate objective is saving critical time for disease control. To estimate and predict mortality caused by COVID-19 in real time, a new methodology is reported in [
29]. This methodology consists of the Patient Information Based Algorithm (PIBA), using available data gathered during an epidemic. To evaluate the methodology, the authors used preliminary data from China, the algorithm was successfully applied to estimate the death rate and predict the death numbers in the Korean population. According to the authors the algorithm can be used to estimate the death rate of a new infectious disease in real-time and to predict future deaths. Another interesting work proposed an automatic detection system as a fast alternative diagnosis option to prevent the spread of COVID-19 [
30]. The approach consists of using three different convolutional neural network-based models (ResNet50, InceptionV3, and InceptionResNetV2) for the detection of a coronavirus pneumonia infected patient using chest X-ray radiographs. Among the results of this work is that chest X-ray images are a very good tool for the detection of COVID-19.
3.2. Ontologies and Semantic Reasoning
An ontology as defined by Gruber is an explicit specification of a conceptualization [
31]. It refers to an engineering artifact made up of a specific vocabulary describing a certain reality using a set of explicit assumptions regarding the intended meaning of the vocabulary words. With the explosion of data, the number of sources, and their heterogeneity, the concept of ontology has become a very important field of research.
Medicine has been one of the preferred fields of experimentation for ontologies due to the tremendous progress in this domain. The interoperability and reusability are two of the main criteria that these ontologies must satisfy. They are designed and shared by the scientific community through four main resources: (i) the OBOFoundry (
http://www.obofoundry.org/) whose objective is to develop a family of interoperable ontologies that are both well-formed and scientifically accurate. It holds 175 ontologies (as of May 2020) covering, among others, diseases, diagnosis, treatment, anatomy, etc.; (ii) the BioPortal [
32], that aims to create software and support services for the application of ontologies in biomedical science. It holds 1016 (as of May 2020) ontologies and is run by the NIH National Center for Biomedical Ontology; (iii) the Ontology Look-up Service (
https://www.ebi.ac.uk/ols/index) that is a repository of biomedical ontologies. It holds 237 (as of September 2019) ontologies and aims to provide means to find, query, and navigate biomedical ontologies and controlled vocabularies; (iv) UMLS (
https://www.nlm.nih.gov/research/umls/index.html). The developed ontologies cover diagnosis and treatment of multiple diseases such as diabetes, breast cancer, Alzheimer’s, hypertension, asthma, etc. They also represent drug, cell, phenotype, radiology, anatomy, chemical, infectious diseases, clinical search, psychology, nursing, laboratory, units of measurement, mass spectrometry, epigenetic, biology system, etc. Very recently, COVID-19 was integrated in Infectious Disease Ontology (IDO) that provides all aspects of the infectious disease domain [
33].
In [
34], the authors devised the role of ontologies in bioresearch in general, either biological or biomedical. They showed interesting results from a functional perspective. The interest of the article resides in the description of different aspects of ontologies in biological and biomedical domains. Four main features are generally present in almost all ontologies, and when combined they play an important role in the success of ontologies: provision of standard identifiers for classes and relations that represent the phenomena within a domain; provision of a vocabulary for a domain; provision of metadata that describes the intended meaning of the classes and relations in ontologies; provision of machine-readable axioms and definitions that enable computational access to some aspects of the meaning of classes and relations. A functional perspective on ontologies in biology and biomedicine is provided by the authors with a special focus on what ontologies can do and describing how they can be used in support of integrative research. They also outlined perspectives for using ontologies in data-driven science, their application in structured data mining and machine learning applications.
According to [
35], in the past decade in some east Asian countries, air pollution became a serious threat to public health. In Taiwan, pollution and related illnesses became a serious problem, where sore throat, asthma, bronchitis, sinusitis, laryngitis, etc., are some of the common symptoms and illnesses. An ontology-based herb therapy recommendation web for respiration system health was proposed by the authors. The aim was to sort out the knowledge and build an easy-access web system. The latter provides reliable and comprehensive knowledge of herbs to improve respiration system wellness. The feedback from users confirm the practicality and usefulness of the designed system. The use of herbs in daily diet and as alternative treatments is not new, but it still needs great promotion and education as many people have gone to hospitals to get quick and easy pills to feel better. Promoting this knowledge remains a long and great challenge.
On the other hand Saleha Asad et al. [
36] were interested in the use of an ontology to detect drug abuse epidemiology. The authors improved an existing ontology-based system (PREDOSE for PREscription Drug abuse Online Surveillance and Epidemiology) in which the objective was to extract the relevant knowledge from websites and blogs on illicit drug usage. PREDOSE does not cover the brand names and slang terms of drugs, nor the risk factors related to the illicit drugs. It does not provide the information on drugs that are prohibited in different countries. The proposed system aims to compensate for any lack of PREDOSE by providing useful information related to drug addiction and its prohibited information. Thanks to this new approach, users can query the knowledge base for information such as street names or slang terms for drugs. Users can also obtain information on the different company names for a single chemical formulation of a drug, as well as their side effects. Some information is updated and expanded in the approach as the number of classes has increased from 43 to 114. In addition, the model gains efficiency by defining semantic rules.
In [
37] the authors used a Semantic-Based Knowledge Management System (SKMS) that supports knowledge acquisition and integrates various approaches to provide a systematic practical platform to knowledge practitioners. The aim of SKMS is to identify roles of healthcare professionals, duties that can be performed according to personnel competencies, and projects that are conducted as a part of tasks to complete defined goals of clinical processes. In this work, the authors proposed an ontology-based approach to investigate implicit knowledge acquisition and information flow issues. SKMS is useful to assist providing the right information to right users as needed in different tasks to carry out activities in processes of healthcare units. This framework supports tacit and explicit knowledge acquisition management. It provides a systematic way to acquire implicit knowledge from subject matter experts or knowledge mentors, model it formally, and transform it into a machine-readable form to develop a health information system (HIS) that provides a variety of health services that can better meet the needs of health care professionals and users. The goal of the ontological-based modelling method is inviting the organization to move towards patient-centered systems, enlarge opportunities, and simplify reuse of existing healthcare practices for new reform initiatives. Using an ontology gives new vision to manage knowledge and provides help to develop HIS with different and new implementation strategies.
The work in [
38] focused on the evaluation of the ability of crowdsourcing methods to detect errors in SNOMED CT (Systematized Nomenclature of Medicine Clinical Terms) and to investigate the demanding challenges of upgradable ontology verification. The authors presented a methodology to crowdsource ontology verification that uses micro tasking combined with a Bayesian classifier. The results of the study showed that the crowd can indeed identify errors in SNOMED CT that experts also find, which suggests that the proposed method will likely perform well on similar ontologies. When experts are unavailable, added to limitation of budget, or width of the ontology which makes it difficult to evaluate it manually, we can use the crowd which can be particularly useful. It can address the challenges of scalable ontology verification, completing not only intuitive, common-sense tasks, but also expert-level, knowledge-intensive tasks. According to the results of this study, crowdsourcing may help to solve problems that require considerable biomedical expertise.
The research [
39] published in Transcultural Psychiatry is a profound critic of care in American eating disorders treatment. The author gave the example of a patient and developed all the ideas regarding ontology, recognition, and elusiveness of care in the defined context. Clinical management of eating disorders is both central and elusive, both an organizing principle and an ever-receding horizon. The care for people with eating disorders is the clinic’s responsibility, which is meant to work on meeting their medical, social, and psychological needs. The problem is that the resources needed to provide that care are not ultimately held by the clinic itself but are gate kept by managed care companies. Those companies manage care, and they have the ultimate decision on who will receive care or not, they also fix the conditions, and of what that care will consist of. In the managed care framework, the fewer resources one needs, the better a patient one is seen to be, a stance that perilously mirrors eating disorders themselves. The concept of ‘‘care’’ operates across several domains simultaneously, sometimes folding back on itself to produce oblique expressions or even cause harm. Managed care companies reviewed the treatment progress of the patients on a semiweekly basis, assessing the degree to which they were proceeding along expected recovery trajectories. Satisfactory progress is assessed, and the treatment coverage could be terminated at the wish of the companies. A patient can be judged to be chronically manipulative, and could be forced to go out of treatment, either by the termination of insurance benefits or by the clinic asking her to leave. The logic of care in this context thus perpetuates a paradoxical tearing apart of the client’s agency, which in turn makes care an ever-changing, mutable, and elusive goal.
Additionally, many ontologies were developed to diagnose and treat diseases such as diabetes mellitus [
40,
41,
42], liver cancer [
43], myocardial infarction [
44], dermatosis [
45], hypertension [
46], Ebola virus infection [
47], fibrotic interstitial lung disease [
48], breast cancer [
49,
50], pneumonia [
51,
52,
53], and Alzheimer’s [
54]. Some ontologies are for differential diagnosis [
55,
56,
57] and others for drugs [
58,
59,
60].
Finally, one of the key areas of semantic applications in healthcare is Ontology-Extended Clinical Guidelines. OpenClinical.net knowledge sharing project [
61] provides a sharable knowledge base for open access and open source repository. Its operationalization is governed by four principles such as supporting community to build, document and share models of clinical expertise, providing open access to the content for clinical and research use, ensuring fairness in recognition of efforts and value created by the users of the tool, and empowering them to disseminate their expert knowledge. The solutions offered by the tool are ontology driven and they help understanding, capturing, and organizing knowledge that concerns medical item management used in hospitals.
3.3. Clinical Decision Support Systems
The medical informatics community is very interested in develo** methods and tools to support clinical processes, varying from reminders, recommendations, and messaging systems, to decision support, treatment planning, and clinical workflow services. Clinical decision support systems (CDSS) that aim to help healthcare providers to make better decisions and improve patient care were proposed more than a half-century ago. This help concerns both diagnosis and treatment [
62]. According to several studies, if used effectively, this aid could improve the quality, safety, and high performance of health care [
63,
64,
65,
66]. The lynchpin of CDSS success is well defined in [
67] “The goal of CDSS is to provide the right information, to the right person, in the right format, through the right channel, at the right point in workflow to improve health and health care decisions and outcomes”.
An interesting article [
68] discusses the use of fuzzy decision support systems for diabetes diagnosis. The authors presented an ontology-based system and implemented a new semantically interpretable FRBS (Fuzzy Rule-Based Systems) framework to diagnose diabetes. To provide a more intuitive and accurate design, the authors used in their framework multiple aspects of knowledge-fuzzy inference, ontology reasoning, and a fuzzy analytical hierarchy process (FAHP). The proposed system offers numerous unique and essential enhancements to the implementation of an accurate, dynamic, semantically intelligent, and interpretable CDSS. In the fuzzy rules evaluation process the ontology semantic similarity of diabetes complications are considered, as well as symptoms concepts. The proposed system helps physicians and patients to accurately diagnose diabetes mellitus as it was shown in the testing of the framework using a real data set. The authors worked on a hospital in Egypt, they combined the proposed FRBS using JAVA APIs and produced the hierarchical FRBS (H-FRBS). In an actual hospital environment, although all features are required, certain features are more critical than others. For example, diabetes symptoms are more important than lipid profile. Moreover, in some cases, not all features are known for a given patient, and physicians must decide with the available information. The resulting system can make decisions with different combinations of data sources and with different confidence levels. According to the authors the framework is smart and can provide more accurate results than existing studies. Further improvements can be made to extend its functionality as it was built within an open architecture. The system can even be applied to any other medical field in a simple and easy way. Its current limitations are that it does not yet allow full interoperability with the HER (Electronic Health Records) system and does not consider data regarding patients from social media.
The paper [
69] presents a type-2 fuzzy ontology-aided recommendation system. The system monitors the patient’s body by recommending diets with specific foods and drugs. The system begins first by extracting the values of patient risk factors. Then, it determines the patient’s health condition via wearable sensors. At last, it delivers recommendations consisting of diabetes-specific prescriptions for a smart medicine box and food for a smart refrigerator. Protégé Web Ontology Language (OWL)-2 tools are used in this ontology, the aim is to deliver decision-making knowledge based on patient information. The recommendation process uses Semantic Web Rule Language (SWRL) rules and fuzzy logic. The performance of the proposed ontology was evaluated after the development of each phase to measure the improvement level. This system can effectively overcome the load of chronic patients on hospitals, help physicians to automatically retrieve patient physiological information for diagnoses, and can assist old patients with chronic diseases for long-term care without continuous visits to physicians.
In the context of the patient’s infectious illness and comorbidities, the authors in [
70] proposed an approach to the problem of inflammatory syndrome identification. It consists of implementing a computerized early warning tool for sepsis in which they researched to determine clinical metric performance of a cloud-based computerized sepsis clinical decision support system (CDSS), understand the epidemiology of sepsis, and identify opportunities for quality improvement. The study was conducted in several hospitals in different regions of the United States. According to the authors the cloud-based sepsis CDSS integrated with enterprise EHR systems is an approach toward early recognition of sepsis in a hospital setting.
Middleton et al. undertook a retrospective study over 25 years of use of CDSS since 1990 [
71], which was designed to provide clinicians, staff, and patients with knowledge and person-specific information. Those system filters filter information and present it at convenient times, to enhance health and health care. The authors subscribe to the belief that, as a component of a Learning Health System CDSS is essential where a cycle of information is created from data generation, to aggregation, analysis, knowledge creation, knowledge dissemination and use, and ongoing measurement for continuous feedback and refinement. Over time, evolution of the techniques and approaches made it more and more efficient for practitioners and CDSS became fundamental. CDSS is evolving in important ways: increasing in availability of electronic data and knowledge bases for CDSS from industry to support traditional evidence-based medicine. Electronic health records provide data that are being aggregated in efficient ways to support the notion of ‘practice-based’ evidence. They help to support develo** new forms of inference for CDSS. Middleton et al. reflected on the number of main dimensions of CDSS which adversely impact the effective implementation and use of CDSS in clinical practice, and certain developments which may accelerate its use. In summary, the authors suggested that the evolution and increased use of CDSS in practice is inevitable given the explosion of biomedical knowledge, and the pressure to improve quality and lower costs in value-based care.
In [
72], the interest in develo** a CDSS for pediatric abdominal pain in an Emergency Department is related to an important demand for organizing the process. Emergencies are under heavy pressure on a regular basis. The authors were interested in abdominal pain with focus on appendicitis of children. Diagnosis of appendicitis in children is challenging. The CDSS was designed to help guide management of pediatric patients with acute abdominal pain within the Health Care Systems Research Network (HCSRN). The system uses, when available, prior diagnoses, medicines, laboratory, and other clinical data. At intervention sites, “risk for appendicitis” is defined and assigned in exact terms. The system provides targeted recommendations regarding management and a summary that can be pasted into the clinical note. At this stage, the system is ongoing at two large health care systems in the HCSRN which each have histories of successfully develo**, implementing, and evaluating CDSS systems. Experience from HCSRN sites was of great importance and helped the study team. Using the collaborative approach to problem solving may have been difficult to achieve with organizations outside of the network. The challenge remains in finding the balance between achieving target enrolment and enrolling the appropriate target population.
Fuzzy sets can be defined from statistical information and rules for constructing CDSSs are, in this case, based on fuzzy logic. In [
73], an approach is proposed to make use of statistical information describing dependence between input variables and output classes. The approach is based on possibility theory. The goal was to obtain fuzzy partitions particularly useful for classification purposes and suitable for medical applications. Here we are in the presence of a technical paper in which the authors conducted field studies to calibrate their model. CDSSs are applied to single patients, therefore conclusions are better described by the membership of patient’s characteristics to different classes, which can be encoded by possibility measures. Moreover, DSSs mostly give results in the form of a single, most reliable class.
Selection and implementation of a CDSS for imaging was a subject study proposed in [
74]. The tool presented as a procedure is intended to help radiologists ensure that they can understand and contribute to the process of implementing the CDSS for imaging. The efficacy of imaging CDSS was discussed in detail, the authors gave insightful discussion on the legislation and evidence of the system. They also showed number of considerations for selecting a CDSS vendor, tips for configuring CDSS in a fashion consistent with departmental goals, and pointers for implementation and change management. It was shown that number of studies have demonstrated a reduction in imaging utilization growth and improved appropriateness of advanced imaging requests after the implementation of imaging CDSS. The need for new CDSS is driven by different changes in legislation regarding healthcare. The study showed evidence that careful implementation of CDSS can have a significant impact on inappropriate imaging utilization. Careful planning is required when using CDSS, it can become an administrative obstacle to providing high-quality patient care. Radiologists should pay careful attention that CDSS is configured in a way that facilitates lasting, collaborative relationships with referring physicians and highlights the value of the radiologist as a clinical consultant rather than a clinical commodity.
Patient privacy preservation in clinical decision support systems was the focus of [
73]. Indeed, the protection of patient privacy when using clinical decision systems became an important subject with the exponentially increasing data used. The authors proposed a new privacy-preserving patient-oriented CDSS. The system helps clinician to complementarily diagnose the risk of patients’ disease by preserving their privacy. The past patients’ historical data are stored in cloud and can be used to train a Bayesian classifier algorithm. Information is preserved without leaking any patient medical data. The algorithm uses training data to classify and compute the disease risk for new patients.
The authors of [
75] were interested in how a CDSS can help in using Traumatic Brain Injury (TBI) Prediction Rules. The importance of prediction rules and guidelines lies in their ability to safely impact care. The primary aim of the authors was to determine whether implementing the two age based PECARN TBI (Pediatric Emergency Care Applied Research Network) clinical prediction rules by using a multifaceted intervention, centered around computerized CDSS, would decrease the rate of cranial CT (Computed Tomography) use for children with minor blunt head trauma at very low risk of TBIs, without increasing the rate of missed TBIs. In a second stage the aim of the authors was to determine whether CDSS that provided risk data for TBI for all children with minor blunt head trauma would decrease CT use. According to the authors, the implementation of TBI prediction rules and provision of risks of TBI by using computerized CDSS was associated with modest but variable decreases in rates of CT use for children at very low risk of TBI and for all children with minor blunt head trauma, without increasing the rate of missed injuries. However, decreased CT rates were inconsistent.
The overall goal for the study presented in [
76] is to identify decision complexity and its constituents in combination with cognitive strategies to inform the design of health information technology. It was important to provide valuable cognitive support to clinicians. The authors focused on the following research questions:
Several medical experts were interviewed for the study. A structured documentation process of coding within a systematic examination of individual interviews were included in the procedure, in which the ID experts have a long experience of on average 18.5 years. Out of 10 ID experts, two were female and eight were male. Identification of complexity factors in the procedure needed use of cognitive strategies which can be of help to the ID experts. It was shown from the study that a way to rework the paradigm of evidence-based medicine exists and can enhance the management of complex clinical tasks. It was typically assumed from the practice guidelines of the reviewers that leeway for clinical judgement is allowed as the experienced clinician is assessing the patient. However, clinicians are prompt to accept the rule-based recommendations as the guidelines are incorporated into the clinical decision support systems. ID experts deal with decision complexity using different mechanisms. Some cognitive factors contribute to this decision complexity, in which we can cite:
overall clinical picture does not match the pattern,
lack of comprehension of the situation, and
social and emotional pressures.
There are multiple facets and potentials of sentiments analysis; the authors of [
77] managed to describe them in the context of medicine and healthcare for several reasons. Various persons are involved in a treatment process; we can find physicians of different specialties, therapists, and nurses. The importance of identifying personal observations and attitudes of a physician is highly acknowledged as they play a role when appearing in medical records. They permit having a complete view of a patient’s health status, and other healthcare professionals will benefit from it. Observations or experiences in contrast to examinations results, are communicated in an unstructured way in reports and documents. Examination results on the other hand are often reported in a structured manner. That is why it is important to pay attention when extracting opinions from observations or examination results. They are very helpful in assessing clinical data and monitoring health status of patients. Automated decision support is made easier for practitioners. The medical conditions of a patient impact his life even though clinical documents are often written in an objective manner, for this reason sentiment analysis is of importance and helps to determine the impact from those written documents. Sentiment lexicons are usual in approaches that deal with sentiment analysis [
78,
79,
80].
The authors of [
77] provide an important basis for recognizing sentiment terms and patterns of sentiment expressions in natural language texts. Existing approaches to sentiment analysis from medical web data are either machine-learning based or rule-based. The authors worked on technical topics in which they expected a similarity to clinical narratives. The aim of their analysis is to examine the language and sentiment expressions in clinical narratives and medical social media. They used thousands of entries from different data sources to perform the experiment. Within a quantitative comparison, they analyzed and compared the word usage of the six text types: (1) nurse letter; (2) discharge summaries; (3) drug reviews; (4) Medblogs; and (5) Slashdot interviews. This analysis could be used for many purposes. Uncertainty, attitudes, and implicit sentiment could be collected and considered in clinical decision-making. Solutions for sentiment analysis lay in the construction of a domain-specific sentiment lexicon and the development of methods that allow sentiment to be judged depending on the context.
The IBM Watson [
81] is a CDSS that includes both machine learning and natural language processing modules, and has made promising progress in oncology. In a cancer, 99% of the treatment recommendations made from Watson are like the physician decisions. Moreover, Watson cooperated with Quest Diagnostics to offer the AI Genetic Diagnostic Analysis. Further work needs to be done on standardizing methods for knowledge and data representation, CDSS implementation in clinical care environments, and knowledge exchange.
A final example is the recommender system called DeepSurv [
82] uses a neural network to recommend personalized treatments according the patients’ covariates and predict the effect of treatment options on a patient’s risk.
Overall, CDSS technology remains one of the key areas of AIA applications in healthcare. Their degree of advancement is by far the most mature, but still offers opportunities for innovation.
3.4. Smart Homes
A smart home is the residence that uses a set of devices that connect via a network, most commonly a local LAN (Local Area Network) or the internet. These devices include sensors, RFID (Radio Frequency Identification), and other appliances connected to the Internet of Things (IoT) that can be remotely monitored and accessed. It is a new paradigm that aims to provide services that respond to the perceived needs of the users and enhance domestic comfort, convenience, security, and leisure. They play an important role for elderly persons and health care technologies. Smart homes are very seductive and attract a lot of researchers. Indeed, several works tackled human activity recognition in smart homes which plays an important role in people’s daily lives. Successful human activity recognition applications include activity recognition [
83,
84,
85,
86,
87,
88,
89,
90,
91,
92], gesture recognition [
93,
94], home behavior analysis [
95,
96], and emotion recognition [
97,
98]. Living assistance is another aspect of research in the smart home context. These systems are used to provide assistance, in particular to people with cognitive deficiencies such as dementia [
99]. The authors of [
100] reported a new protocol named Ergo to address smart homes for assisted living. The developed protocol has been used in an old home built in 1938 which was converted into a smart home with the use of sensing technologies. It predicts wellness of a resident through the monitoring of different appliances used by him/her and his/her movements.
In [
101], the authors were interested in assisting patients with sclerosis disease in a smart home and the authors of [
102] studied the influence of expressive speech on automatic speech recognition performances and applied their approach on elderly people assistance.
The authors of [
103] propose a system, for smart homes, which combines Internet of Things (IoT) and big data analytics technology with fog and cloud computing. The challenge is related to develo** fast solutions that can handle large volumes of unstructured smart home data. Fog computing is of importance as it provides fast near real-time analytics while the abundance of computing and storage resources in the cloud system is used to carry out computationally intensive applications.
An approach by combining knowledge-driven with data-driven reasoning to permit activity models to evolve and adapt automatically based on users’ particularities was proposed in [
104]. The reasoning is knowledge-driven in this case and the authors made it able to infer an initial activity model. At upper stage, the model will be trained using data to produce a dynamic activity model that learns users’ varying actions. The results of the study showed that the learned activity model yields significantly higher recognition rates than the initial activity model.
RUDO [
105] is a home ambient intelligence system that was designed to help blind people living with sighted people. This system helps blind people through a single user interface that helps by means of work on a computer, writing in Braille on a regular keyboard, etc. RUDO increases their independence of these people and creates conditions that allow them to become fully involved.
We notice that there are many patents about smart homes. The authors of [
106] developed a device telemetry circuit to detect electrical anomalies in a plurality of smart home devices. In [
107], systems and methods of providing status information in a smart home security detection system to a user are developed. Once the sensor has detected and received identifying information from an electronic device, a controller device determines whether this detected identifying information is from the electronic device of an authorized user and provides an operational status message to the electronic device.
It is important to mention that smart homes are concerned with big data [
103]. This is what makes the use of the data mining and machine learning interesting in predicting, detecting, and assisting in smart home contexts.
Smart homes that are becoming more and more popular within the scientific community and end user are facing five barriers [
108]: (1) the fit with users’ current and changing lifestyles; (2) the ease with which smart home technologies can be administered; (3) interoperability between systems; (4) reliability; (5) privacy and security. Other barriers in their adoption are high cost, poor usability, inflexibility, and a lack of general user involvement.
Despite the progress within the scientific community on researching innovative solutions for smart homes, their adoption still falls short of end-user needs, prompting search for new strategies.
3.5. Medical Big Data
Big data refers to large and varied sets of information that are growing at a very rapid rate. It is characterized by the 10 V: volume, velocity, variety, veracity, value, validity, variability, virality, and visualization [
109]. Medical big data are distinct from big data of other disciplines, and they are also different from traditional clinical epidemiology data. Big data technology is applied on predictive modeling and clinical decision support, research, safety surveillance, disease, and public health. We find medical big data in different circles: in clinical registries, electronic health records, biometric data, administrative claim records, patient reported data, medical imaging, biomarker data, prospective cohort studies, etc. As the sources of data are different, the dimensions of data evolve and become complex as large size, disparate sources, multiple scales, incongruences, incompleteness, and complexity are encountered.
In the literature, most of the published papers concern the usefulness of big data in the medical field, the dangers as well as the perspectives and challenges. Big data shows effectiveness across the entire range of public health disciplines. This ability ranges from “monitoring population health in real-time” to develop “definitive extents and databases on the occurrence of many diseases” [
110]. Indeed, the health areas that use of big data include public health [
111,
112,
113], environmental health research [
114], epidemiology [
112,
115,
116], infectious disease [
110,
113,
117], sleep science [
118], maternal and child health [
119,
120], safety and occupational health [
121,
122], healthy food and nutrition [
123,
124,
125], and smart homes [
103,
126,
127]. There is optimism and evidence for big data’s value in public health, both in research and in intervention.
The authors of [
117] studied the opportunities for using big data for global infectious disease surveillance. They estimate that the big data will massively improve the granularity and timeliness of available epidemiological information with hybrid systems enhancing traditional surveillance systems, and better prospects for accurate infectious disease models and forecasts.
Data mining is very used in the big data context, not to say that they are very connected. We know that the data mining algorithms are more performant when the volume of data is very large. As an example, the authors in [
128] introduce the modern plastic surgeon to machine learning and computational interpretation of big data.
Application of big data analytics in medical domain is promising. Therefore, it is critical to point out some of challenges for big data applications in healthcare [
129]: (1) the evidence of practical benefits of big data analytics is scarce; (2) there are many methodological issues, such as data quality, data inconsistency and instability, limitations of observational studies, validation, analytical issues, and legal issues.
Clinical practice needs to integrate big data analytics and take advantage from it. The authors of [
130] assume that big data research in health informatics has not yet gained popularity in cardiology, but there is great potential for its value in research and clinical cardiology.
Many studies such as [
131,
132,
133,
134,
135] demonstrated the positive [
136] impact of the big data on decision making quality. The authors of [
137] raised significant questions about patient privacy when using big data, especially in data collection methods.







{kind=link}