1. Introduction
Online handwriting recognition has been the subject of research for a long time, and part of the technology has found commercial application. However, the limited number of success stories from the market suggests that more research on the pen interface and the recognition methods is still necessary [
1].
Currently, it is common to find wearable devices with a wide range of embedded sensors, which can be used in human activity and behavior studies. Such devices have contributed to the development of new smart applications to use that kind of data. The number of wearables with 3D accelerometer sensors available in the market, and their low cost makes it possible to develop new friendly and non-invasive human–computer interfaces. Such technology allows users to write customarily and freely on smartphones, smartwatches, smart TVs, computers, etc. In order to attract the user’s attention to the pen interface, fast and accurate handwriting recognition interfaces are highly required.
Some systems using 3D accelerometer data for human activity, handwriting and sign language recognition have been developed [
2,
3,
4,
5,
6,
7,
8]. Online handwriting recognition is still challenging due to the variability of stroke order, shape and style of handwriting [
1]. Some approaches recover the trajectory of the handwritten character to convert it to image. In this case, to cope with variability, robust feature extraction methods can be employed [
9,
10]. Another option is to perform feature extraction directly in the time domain using a Convolutional Neural Network [
11].
This paper proposes a novel deep learning approach to online handwriting character recognition. The method is focused on efficient feature extraction, classification, and evaluation modules using 3D accelerometer data. The recognition system is based on combining the CNN and LSTM architectures. CNN architecture was used for feature extraction, which allows transforming 3D raw accelerometer data into a feature vector sequence. Finally, an LSTM architecture is trained to recognize the patterns delivered by the CNN. In this way, the classical ad hoc techniques in feature extraction and classification are avoided, permitting artificial intelligence (AI) to make these tasks.
The main contributions reported in this paper comprise:
A proprietary dataset of 3D accelerometer data corresponding to multi-stroke freestyle handwritten lowercase letters and digits. Unlike previous approaches, we do not impose restrictions on handwriting style and number and order of the strokes.
Three neural network architectures (CNN, LSTM, and CNN-LSTM) were proposed. In the last architecture, a CNN was used for feature extraction to encode the global characteristics of raw 3D accelerometer data together with an LSTM for sequence processing and classification.
The remainder of this paper is organized as follows.
Section 2 provides a summary of representative works on online handwritten character recognition.
Section 3 includes a detailed description of the proposed method.
Section 4 presents the designed experiments and numerical results. Finally,
Section 5 announces the conclusions derived from this study.
2. Related Work
Motion sensor data, such as accelerometer and gyroscope data, have been used recently for different tasks such as sign language recognition [
2], and online handwritten character recognition [
12]. To successfully carry out handwriting recognition, it is necessary to synchronize two main steps, the data acquisition, and identification processes. In the former, some works perform data acquisition by using a specially designed device [
12,
13,
14,
15]. Nevertheless, nowadays, many wearable devices such as smartphones or smartwatches are equipped with accelerometers, gyroscopes, magnetometers, and other wearables such as the shimmer3 IMU or the MYO armband. In the latter, handwriting recognition takes charge of processing collected data from the motion sensors to recognize handwritten characters correctly.
One clue problem found in online handwriting recognition is related to the length of the sequences for characters of the same class, even those produced by the same person. These variations are related to the writing speed of a character, which simultaneously changes the acceleration of the hand movement. On these grounds, to expect sequences with the same length for the same character class is difficult.
However, to eliminate unnecessary data in the sequences for each letter, it is convenient to extract or segment only the part of the signal during which the handwriting process is carried out. A segmentation approach was proposed in [
15] and tested in [
4,
16]. In this process, only the samples belonging to the handwriting should be considered; otherwise, samples not belonging to the written character will be included.
Another approach to only collect the signal during the handwriting process is to consider the information of pen-up and pen-down movements. In some approaches, this task has been addressed using a camera to track hand movements. Afterward, the segmentation is conducted by hand or a specialized writing device (e.g., glove, pen, marker). In this regard, Roy et al. [
17] presented a solution to handwriting recognition by develo** a user interface to compute numeral recognition in air writing by using a Convolutional Neural Network (CNN). First, they used a fixed-color marker to write in front of a camera, which was followed by a color-based segmentation to identify and track the trajectory of the pen-marker. Next, the classification was carried out by a trained CNN.
An accelerometer-based digital pen for handwritten digits and gesture trajectory recognition applications was proposed by Wang and Chuang [
14]. This pen is based on a triaxial accelerometer to collect the acceleration motion data of the hand; time and frequency domain features are extracted from the obtained acceleration signals. Next, most discriminant features were selected using a hybrid method; kernel-based class separability was applied to select significant features, and Linear Discriminant Analysis (LDA) was used to reduce the dimensionality. Both algorithms were dedicated to training a probabilistic neural network for recognition.
Amma et al. [
15] proposed a wearable input system for handwriting recognition using an accelerometer and a gyroscope to capture the handwriting gestures. Later, these data were processed using Support Vector Machines (SVM) to identify which data segments contain handwriting. Subsequently, Hidden Markov Models (HMMs) were used for recognition.
Kim et al. [
4] classified 26 lowercase letters of the English alphabet using 3D gyroscope data instead of 3D accelerometer data, and the Dynamic Time-War** (DTW) algorithm was used for recognition.
Agrawal et al. [
18] proposed a PhonePoint Pen system that uses the built-in accelerometers found in mobile phones to recognize handwritten English characters.
Additionally, Li et al. [
19] presented a hand gesture recognition based on mobile devices using the accelerometer and gyroscope sensors. Here, the authors applied a filtering process as preprocessing. They also proposed two deep models: a Bidirectional Long-Short Term Memory (BiLSTM) and a Bidirectional Gated Recurrent Unit (BiGRU) using the Fisher criterion, termed F-BiLSTM and F-BiGRU, respectively.
Ardüser et al. [
20] transformed the accelerometer and gyroscope signals of a smartwatch into a particular coordinate system on a whiteboard and used the DTW algorithm for recognition.
In the same context, Kwon et al. [
21] classified ten hand gestures using a CNN model with six convolutional layers. Lin et al. [
22] proposed the system SHOW (Smart Handwriting on Watches), where the users write on horizontal surfaces. Unfortunately, the users need to use the elbow as a support point; due to such inconvenient, this process is not recognized as freestyle handwriting.
Additionally, to show the possibility of motion sensor based eavesdrop** on handwriting, **a et al. [
23] introduced a MotionHacker system using a smartwatch application to record the evolution in hand movement. The system requires a preprocessing stage to proceed with the feature extraction, which allows recognizing each letter by training a random forest classifier.
Concerning technologies, some authors have preferred to use the MYO armband [
2,
7,
24]. Meanwhile, others use the shimmer device [
25,
26,
27]. Our study used an MYO armband to capture the acceleration motion of real dynamic handwriting.
Table 1 presents a summary of representative state-of-the-art works related to the proposed framework.
LSTM networks have been applied successfully to sequence classification in other domains. For instance, Ojagh et al. [
28] proposed a method for air quality prediction using data from air quality sensors distributed in Calgary, Canada. An edge-based component exploiting both temporal and spatial information was used to clean raw data and fill in missing sensor values. Then, an LSTM network was used for prediction. In another work, Sa-nguannarm et al. [
29] proposed a human activity detector based on accelerometer data and an LSTM network. Livieris et al. [
30] proposed a CNN-LSTM model for gold price time-series forecasting. Elmaz et al. [
31] proposed a method for the prediction of indoor temperature by using a CNN-LSTM architecture.
Table 1.
Summary of related approaches.
Table 1.
Summary of related approaches.
| Algorithm | Methodology | Limitations |
|---|
| Digital Pen [12] | 3D accelerometer signals are converted to image which is recognized by a neural network | Ten digits written in a special single stroke font |
| WIMU-Based Hand Motion Analysis [13] | Movement and attitude features are extracted from motion sensor and magnetometer signals and recognition is completed by DTW | English lowercase letters and digits written in a special single stroke font |
| Accelerometer-Based Digital Pen [14] | 3D accelerometer signals are recognized by a PNN | Ten digits written in a special single stroke font |
| Air writing [15] | 3D accelerometer and gyroscope signals are recognized by HMMs | English uppercase letters and words |
| Gyroscope-equipped smartphone [4] | 3D gyroscope signals are recognized by stepwise lower-bounded dynamic time war** | English lowercase letters written with a smartphone grabbed as a pen |
| Marker-based Air writing [17] | Handwriting is captured from motion of a marker in a video and recognition is completed by a CNN | Ten digits written in a single stroke |
| PhonePoint Pen [18] | Basic strokes are detected from 3D accelerometer signals by correlation with templates and handwritten characters are recognized by juxtaposition of basic strokes | English letters and digits written using basic strokes, smartphone grabbed as a pen |
| Deep Fisher Discriminant Learning [19] | 3D accelerometer and gyroscope signals are recognized as hand gestures by an F-BiGRU | Six uppercase English letters and six digits written in a predefined stroke ordering |
| Motion data from smartwatch [20] | Features are extracted from accelerometer and gyroscope signals and letter recognition is done by DTW | English uppercase letters written on a whiteboard |
| SHOW [22] | Features are extracted from accelerometer and gyroscope signals and recognition was tested with seven machine learning algorithms | English letters and digits written on a horizontal surface with the elbow as support point |
| MotionHacker [23] | After preprocessing and segmentation, features are extracted from accelerometer and gyroscope signals and letter recognition is performed by random forest classifier | Demonstration of motion sensors-based eavesdrop** on handwriting |
| AirScript [7] | Recognition is completed by a fusion of a CNN, and two GRU networks using as input an image derived from 2-DifViz features, post-processed 2-DifViz features and standardized raw data, respectively | Ten digits written in the air |
| Finger Writing with Smartwatch [25] | Energy, posture, motion shape and motion variation features are extracted from accelerometer and gyroscope signals, and three classifiers are tested for recognition (Naive Bayes, linear regression and decision trees) | English lowercase letters written on a surface |
| Trajectory-Based Air Writing [32] | Trajectory of handwriting with fingertip using a video camera and recognition was completed by a CNN and an LSTM | Ten digits written with a predefined stroke ordering |
| Air Writing with Interpolation [33] | Motion sensor data are interpolated and then recognized by a 2D-CNN | Uses datasets of others |
3. CNN and LSTM for Sequence Recognition
In the following, we elaborate on the justification for using CNN and LSTM networks for sequence recognition. First, one of the advantages of Convolutional Neural Networks (CNN) is that they can perform feature extraction directly from raw data. They perform adaptive feature extraction because they learn to extract the features that are more suitable for the task at hand. Another advantage is that they are able to tolerate a moderate amount of distortion and noise. Another advantage is that they present a good generalization ability because of the use of shared weights, which allows them to incorporate prior knowledge of the problem to be solved [
34]. Long Short-Term Memory (LSTM) networks are one of the best architectures for sequence processing. This is because LSTM networks have the ability to extract long-range dependencies. In fact, these networks were proposed to solve the vanishing gradient problem faced by Recurrent Neural Networks (RNN) [
35].
The combination of spatial and temporal feature learning is crucial to reliably performing motion sequence recognition. A hybrid CNN-LSTM network is used in this work to extract and exploit these two types of features. The convolutional part obtains spatial features, while the LSTM modules extract short-term temporal information.
In this section, the CNN and LSTM architectures are presented and described in detail.
3.1. Convolutional Neural Networks
Convolutional Neural Networks (CNN) are a special kind of neural network whose structure was inspired by the biological visual perception system [
36]. These neural networks are specialized for feature extraction in 2D systems (e.g., matrix systems); however, their use also has been extended to 1D systems (e.g., sequences). Unlike traditional pattern recognition methods, it is unnecessary to implement or design a feature extractor to gather discriminant information, discarding irrelevant features, and categorize the selected feature vectors into classes for training a supervised classifier. In this scheme, a CNN could be trained with almost raw data; that is, a CNN is a set of layers that transforms the input data into the output class or prediction.
However, the CNN input data in a 2D or 1D system must be nearly normalized in magnitude and centered. CNNs are characterized by the use of several layers, such that a model with depth
d can be defined as:
where each
L represents a convolutional, a pooling or a fully connected layer. The lower and upper indices represent the input and output size of the layer, respectively. Typically, the output of the convolution operators is passed through an activation function
f to form the feature map for the next layer.
3.1.1. Convolutional Layer
Convolutional layers are the core of CNN architectures; the convolution is an operation between two functions, which is mathematically denoted by
where ∗ represents the convolution operator. The first argument
is the measured input data and the second
is the kernel or the convolutional filter. The output
is the feature maps.
2 represents the convolution defined in continuous-time terms; however, the data obtained from all sensors must be discretized to be processed on a computer.
In practice, the convolution operator in discrete-time is defined as
The inputs are the multidimensional data, and the kernel contains the multidimensional parameters. Such parameters are adapted according to the processed data. In this paper, the data sequences are taken as a bidimensional data array.
3.1.2. Activation Function
A convolutional layer is commonly followed by a nonlinear activation function to increase the capacity of the neural network. Such an activation function helps the neuron to react or not through a nonlinear transformation acting over the input signal. Many activation functions are defined in neural networks, but the most commonly used are the Gaussian, Sigmoid, Maxout, Hyperbolic Tangent, Leaky ReLU, and ReLU.
The ReLU function is probably the most recurrent in the literature. It is computationally efficient because all neurons are not activated at the same time, converting the negative inputs to zero. Consequently, the neurons are not all activated, allowing the network to converge faster than for other activation functions.
3.1.3. Pooling Layer
This layer can reduce the dimensionality of the input data and usually comes after a convolutional layer. The dimensionality reduction can be of two forms, the average (average pooling) and the maximum within a rectangular neighborhood (Max Pooling). In both cases, the pooling layer helps to have an almost invariant representation of the input data after a small coordinate translation, which is very helpful if it is wanted to know whether some feature is prevailing or not. Pooling is implemented by an algorithm that compresses or generalizes the information, and generally, this layer can reduce the overfitting in the training stage.
3.1.4. Fully Connected Layer (Dense)
After the feature extraction performed by convolutional and pooling layers, it is necessary to recognize such features, which takes place at the last operative block of the CNN architecture using one or more fully connected layers. In 1D systems, the output of the previous layers coming to a fully connected layer is flattened into a vector that will be used to classify the input data into predefined classes. A Soft-Max layer at the top of the network computes the probabilities of each class.
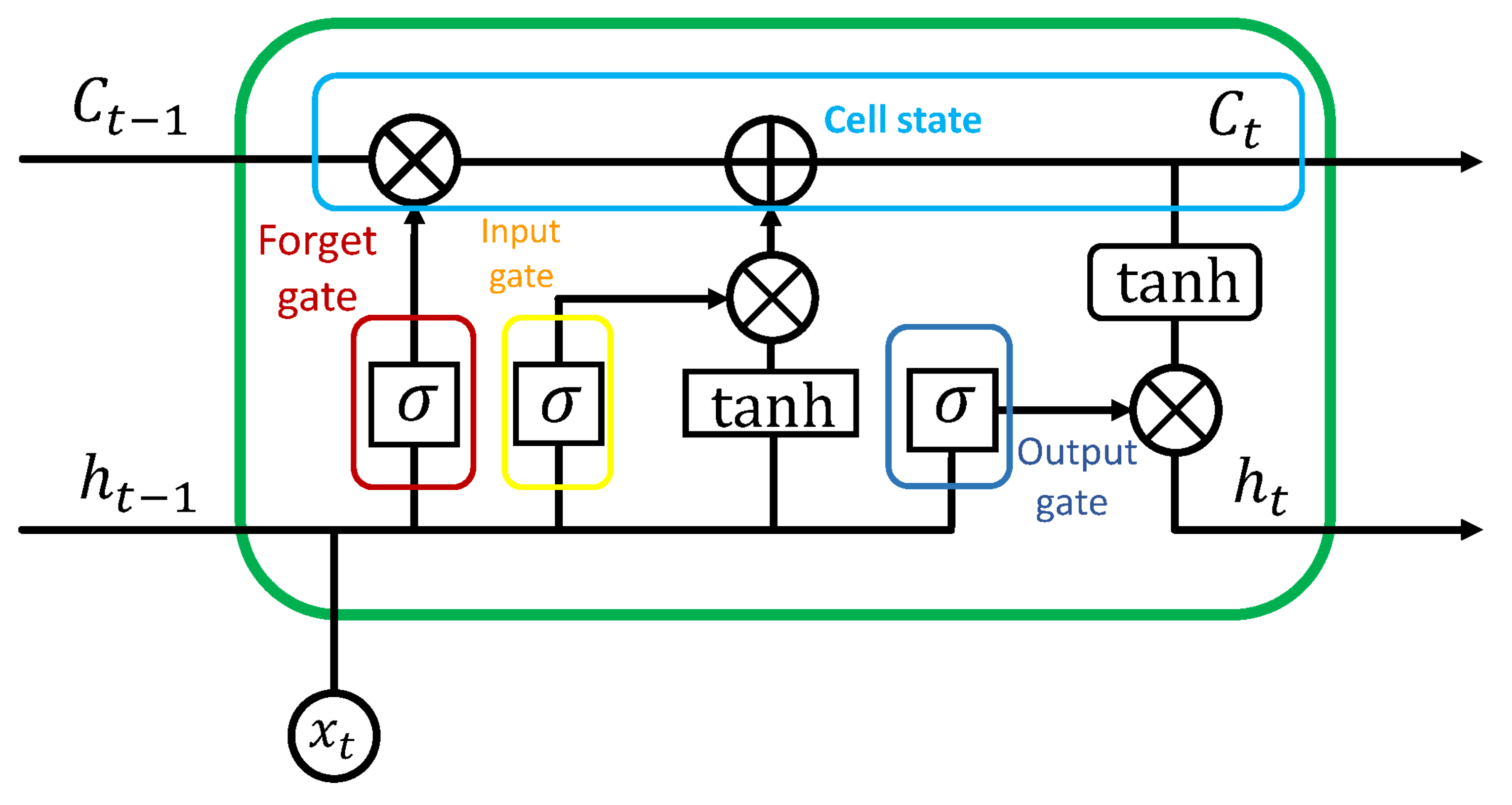
3.2. Long Short-Term Memory Neural Networks
Long Short-Term Memory Neural Networks (LSTM) are a special kind of recurrent neural network (RNN), specialized in processing sequential data. LSTMs have recurrent connections, allowing the learning of long-term dependencies and, consequently, remembering information for long periods of time. The LSTM network core is based on a special unit known as the memory block [
35], which is controlled by three structures (or gates): the forget gate
, input gate
, and output gate
.
Each memory block has two sources of information at each unit time t, the current sample , and the previous memory block state . This information is processed by the forget gate (a sigmoid layer) to decide what information is ignored from the previous cell state . The next step is deciding which new information will be stored in the current cell state. This process is performed at the input gate using the previous state and new data.
Subsequently, the information passes through two functions: the sigmoid activation function
and the
function
. These two partial results are next multiplied. Currently, the previous state
is updated to a new state or cell state
. Finally, the output of the LSTM network
is composed of the product of the output gate
and the cell state
that passes through the
activation function. The overall process in a memory block is summarized as follows:
where
,
, and
denote the weight matrices and bias terms, respectively.
3.3. Implemented Architecture
In this study, to perform handwriting recognition using accelerometer data, three different architectures were implemented and evaluated: a CNN, an LSTM, and an hybrid CNN-LSTM.
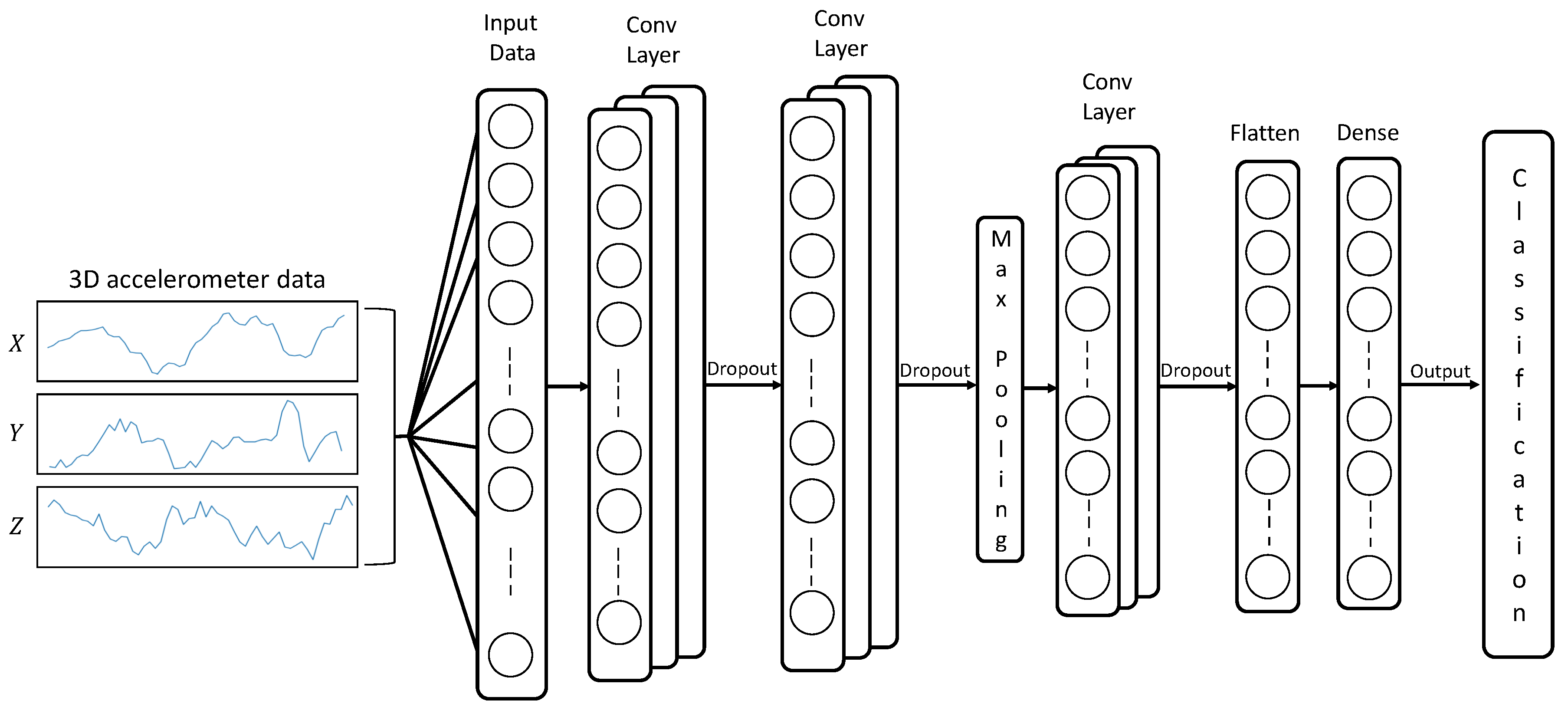
The CNN architecture (
Figure 2) basically consists of three convolutional layers followed by
activation functions. Indeed, in the first and second layers, 16 convolutional filters are used to extract the same number of features from data, where the size of the filters is
, and the stride is set to one. After the first two convolutional layers, max-pooling is applied to reduce the dimensionality by half. Additionally, a third convolutional layer was implemented using 32 convolutional filters with the same size and stride as in previous layers, applying the ReLU activation function. A dropout technique with a dropout rate of
was used in each convolutional layer to prevent overfitting. Finally, a fully connected (Dense) layer is used with a Soft-Max activation function to compute the probability distribution over 36 classes. The proposed LSTM architecture employs 250 memory blocks (
Figure 1). This is followed by a fully connected layer with a Soft-Max activation function to compute the probability distribution over all classes. In the hybrid CNN-LSTM model (
Figure 3), the output of the last convolutional layer of the CNN is connected to the LSTM for recognition and classification.
The input data for the networks consist of the 3D accelerometer data represented in (x, y, z) Cartesian coordinates.
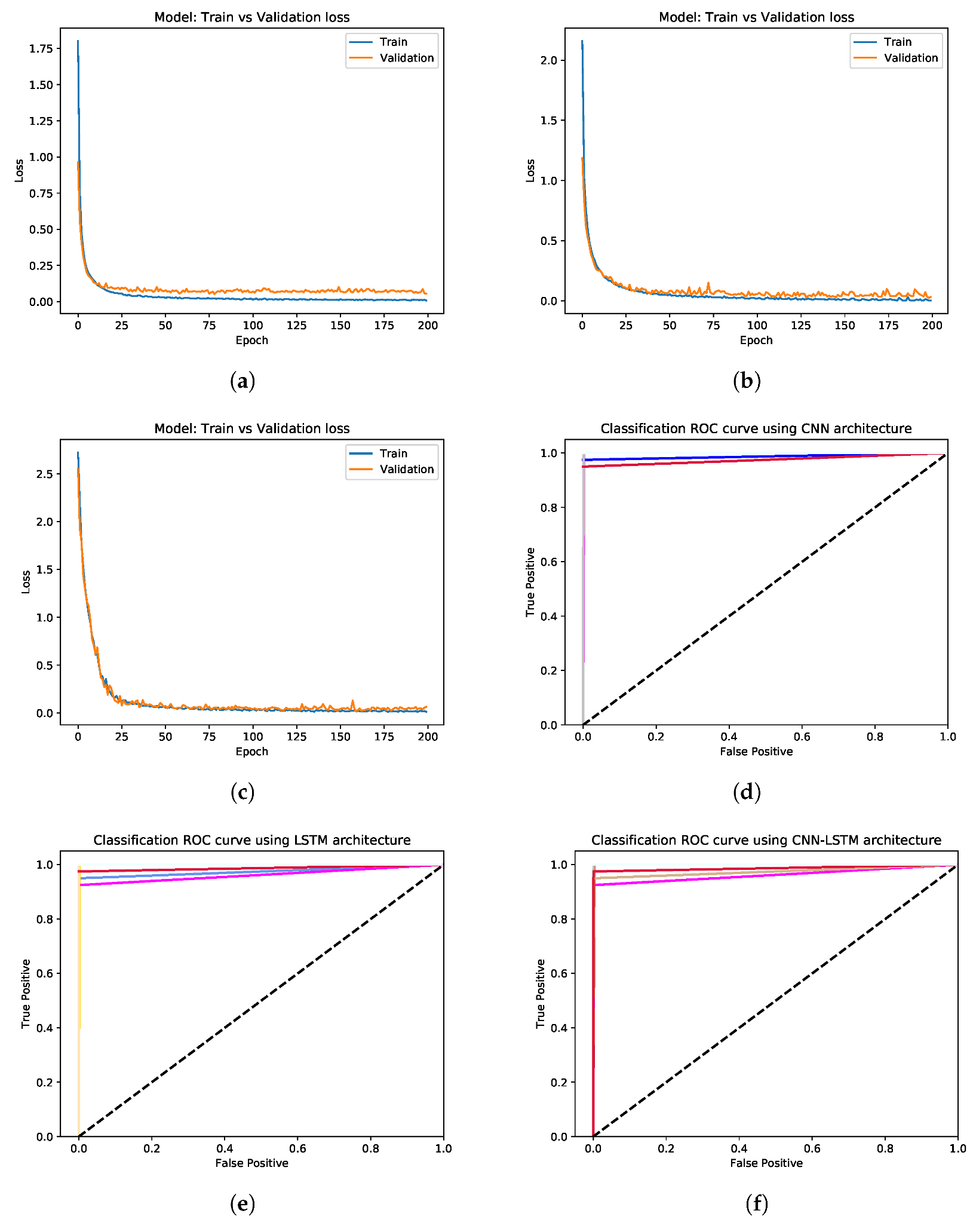
The evaluated architectures were trained using the Adam optimization algorithm to find the minimum of the proposed stochastic objective function, and the network parameters were updated using the backpropagation algorithm.
5. Conclusions and Future Works
In this paper, three neural networks were proposed (CNN, LSTM, and the hybrid CNN-LSTM) to solve the online handwritten character recognition problem efficiently.
Our proposals were evaluated using a proprietary dataset constituted of accelerometer data corresponding to multiple-stroke freestyle handwritten characters: 36 classes (26 lowercase letters from the English alphabet and ten Arabic digits). In addition, the dataset was built using a MYO armband to capture the 3D acceleration data of real-time handwriting. The LSTM architecture achieved the best mean accuracy (99.68%). Although the three proposed methodologies have obtained equivalent results, their processing speed is very dissimilar, being CNN the fastest method.
Our dataset is constituted of 399 samples per class obtained by individual users under uncontrolled conditions only supported by the touchscreen laptop to visualize acquired data. The system was only tested on isolated letters and digits. Thus, it is planned to export it to words or phrases to obtain a fluent handwriting recognition system. One limitation of the proposed system is that it depends on a tablet or touchpad for capturing handwritten characters. Another limitation is that it uses the Myo armband, which is not as common as Android devices. Therefore, future work will address other ways of capturing handwritten strokes. In addition, an extension to allow users to write freely in the air would be desirable.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






