1. Introduction
Language identification (LID) is the process of identifying the language type of a given speech segment [
1], and it is a classification task [
2]. The overall architecture includes a feature extraction task and a classification task. So, the system can be feature-intensive, as [
3] represented by training large-scale data, or it can be model-intensive, as obtained by better classifier models. Both the feature extraction and classification tasks are equally important, but a balance between them is optimal [
4], as described in this paper.
Language identification technology has developed considerably in the last decade. New deep learning frameworks provide new opportunities for the development of language identification research [
5]. Recently, people have become increasingly concerned about language identification in real and complex scenes. As the core front-end processing module for multilingual intelligent speech processing tasks, language identification can be used in multiple fields, such as automatic speech recognition, speech translation, and speech generation. In noisy multilingual overlap** speech, even the human ear may not be able to accurately identify contents, the clean single speech-based model is not efficient for overlapped voices. Therefore, it is necessary to separate overlapped speeches before identifying or understanding the contents.
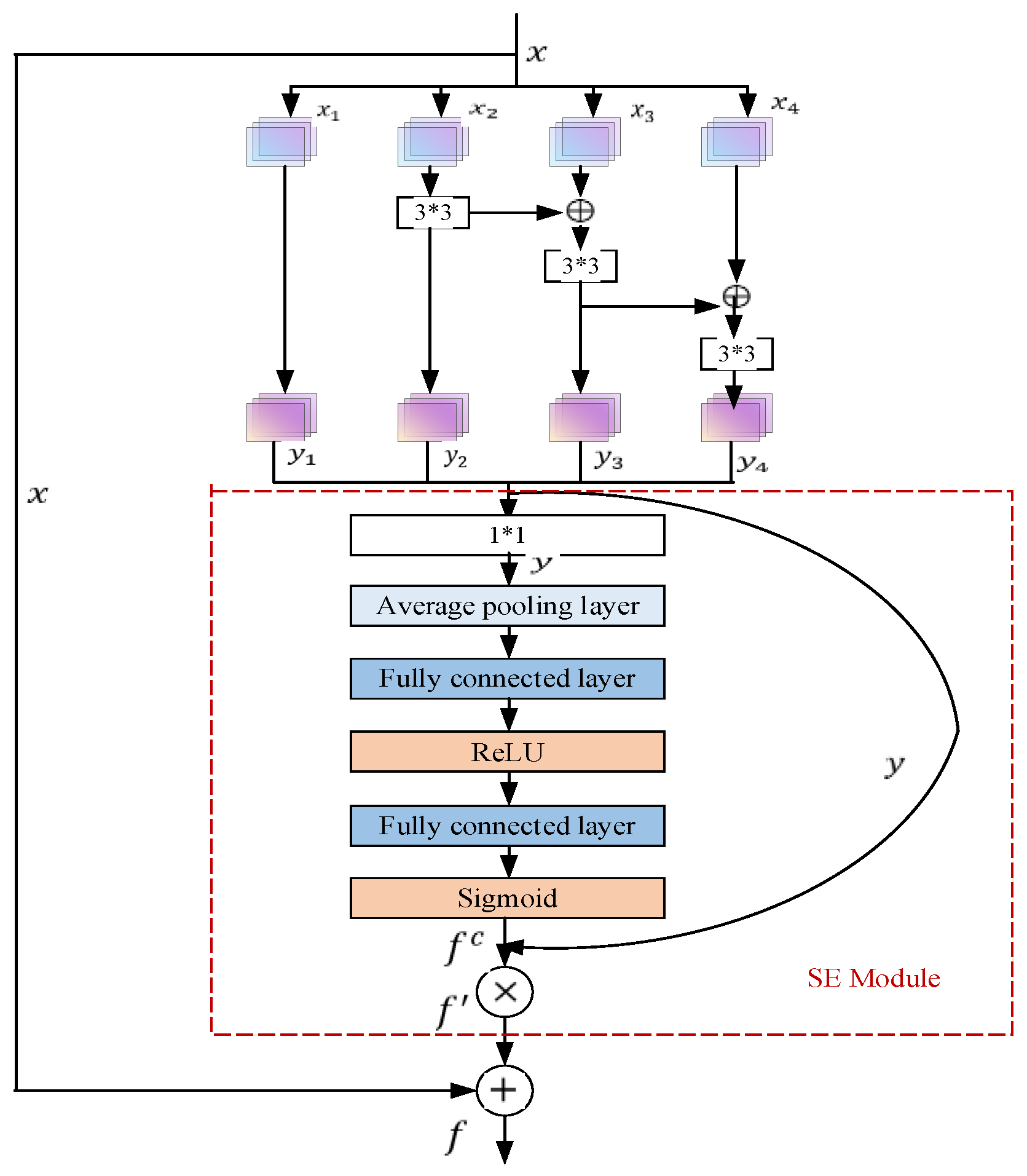
This study proposes language identification feature extraction technology based on a squeeze–excitation [
6] and multi-scale residual [
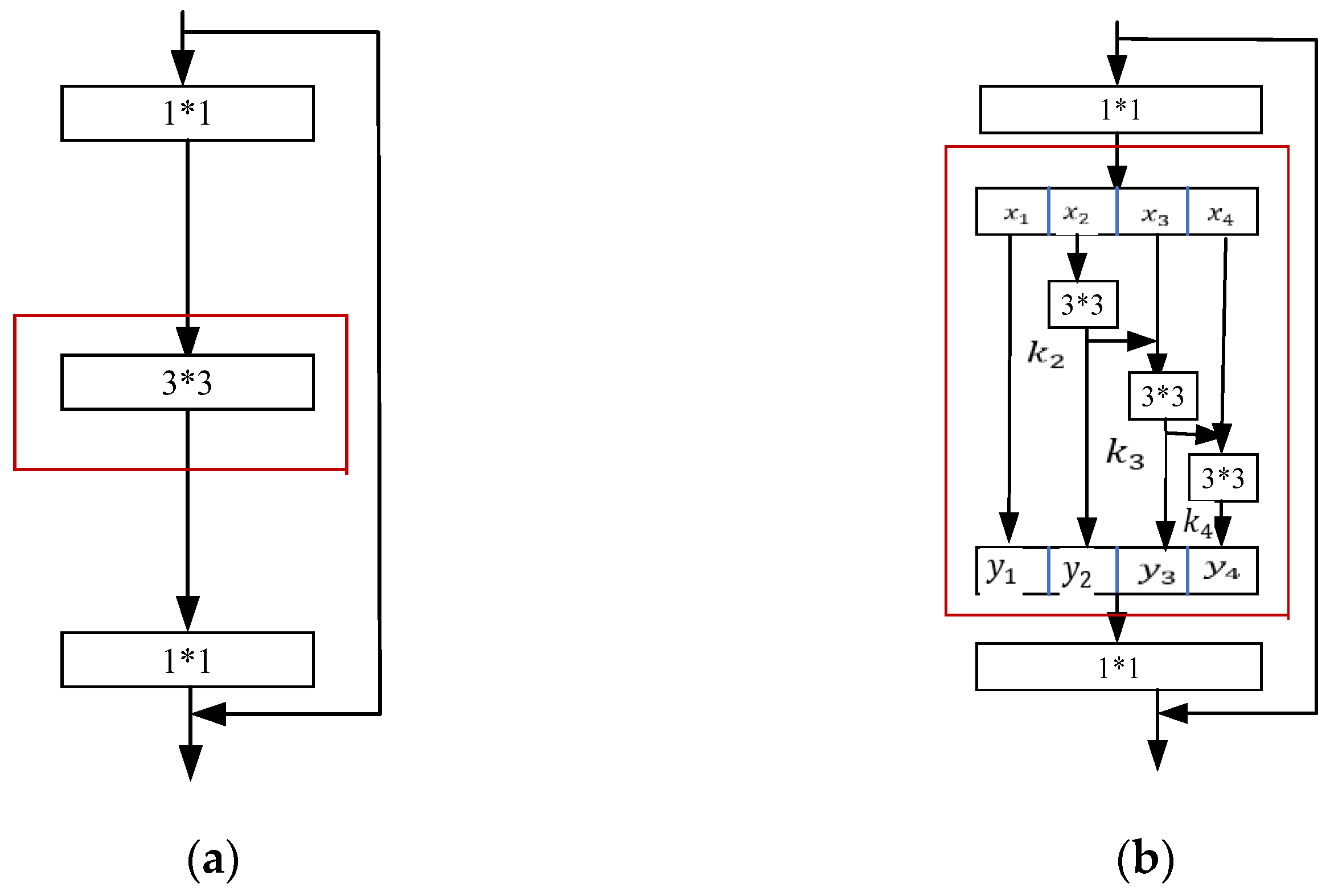
7] network (SE-Res2Net), which improves the feature extraction method of the baseline model and greatly improves the recognition performance of the original language identification algorithm. Experiments were conducted on the AP17-OLR [
8] dataset and a multilingual cocktail party dataset. The accuracy, recall, and F1 values were improved over the baseline model, and the robustness of the model was also improved compared to other models.
2. Related Work
As a front-end technology for speech signal processing, language identification plays a vital role in speech recognition and other related fields, mainly speech translation, public safety, and multilingual dialogue systems [
9]. Language identification is a typical classification problem, and different features can have different influences. As a result, the corresponding model for each language is trained and saved based on the appropriate algorithm [
10]. In the recognition process, the features are first extracted and fed into the classification model, and the language type of the speech signal is determined based on the similarities [
11]. Traditional acoustic models, such as the Gaussian mixture model–universal background model (GMM-UBM) [
12], the hidden Markov model (HMM), etc. [
13], were used for language identification, but these often require an extensive number of training parameters to capture the feature space’s complexity. To address this issue, Campbell et al. [
14] employed the SVM algorithm to classify the GMM mean supervector of speech (GMM-SVM). Language scholars also developed a language identification method that utilizes i-vectors [
15]. This approach involves obtaining i-vectors from speech and employing a back-end discrimination algorithm for language identification. By utilizing this method, the complexity of multilingual modeling can be reduced while still achieving exceptional performance.
In recent years, researchers used deep learning to extract the deep bottleneck features (DBF) [
16] of speech signals. This method used i-vectors instead of acoustic features and GMM-UBM to capture language information more effectively. However, it also increases the complexity of the model. Researchers have subsequently proposed end-to-end language identification systems based on different neural network architectures. Firstly, Lopez-Moreno et al. [
5] applied deep neural networks (DNNs) to short-time language identification. Gonzalez-Dominguez et al. [
17] proposed a long and short-term memory recurrent neural network (LSTM-RNN) for automatic language identification, which effectively solved the problem of gradient disappearance in RNNs. Still, the model was complex and time-consuming. Fernando et al. [
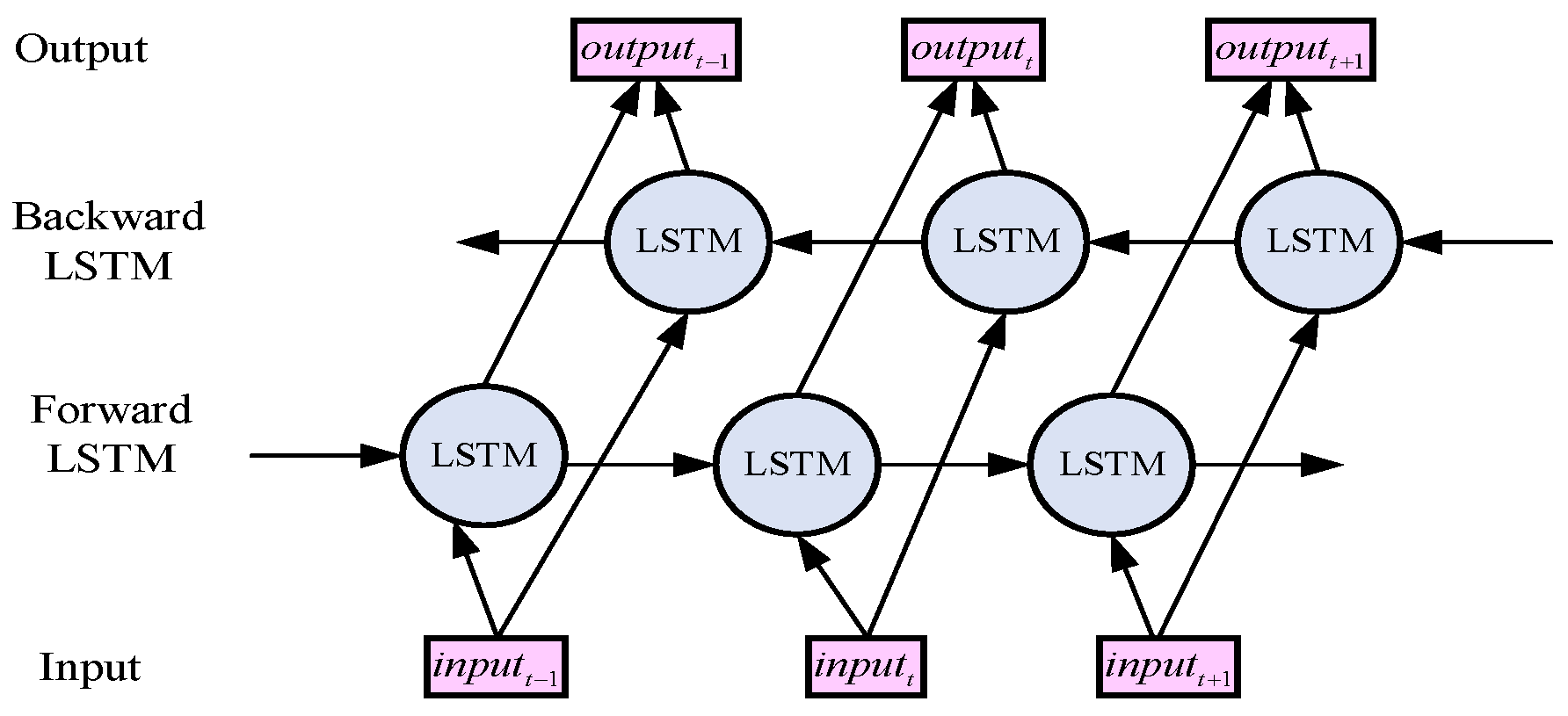
18] built an end-to-end language identification system based on bidirectional LSTM (BiLSTM), which effectively takes into account the past and future information of speech. Padi et al. [
19] used a bidirectional gated recurrent unit (GRU) network for multi-categorical language identification, which has a more straightforward structure and improved recognition rate compared to the Bi-LSTM network. Another popular approach for language identification is a convolutional neural network (CNN) [
20], which extracts local features from speech signals and enhances language identification. CNNs are trained on the spectral map of the raw audio signal. This method involves end-to-end learning with minimal pre-processing, as the neural network can directly map the original data to the final output without relying on the traditional machine learning pipeline.
In 2016, Wang et al. [
21] applied an attention mechanism model to language identification systems. This mechanism selects the most relevant speech features for language identification and improves the recognition performance of the network. In 2017, Bartz et al. [
22] combined a convolutional network with a recurrent neural network (CRNN) for language identification and proposed a CNN-BiLSTM network [
23], which achieved higher accuracy. Although BiLSTM does improve the recognition accuracy, it has some problems, such as an inability to parallelize operations and poor modeling of the effects of hierarchical information. To address these issues, Romero et al. in 2021 [
24] proposed an encoder approach based on the “transformer architecture” applied to the language identification task using speech-directed information. In the same year, H Yu et al. applied the unsupervised learning speech pre-training method [
25] to the language identification system. In 2022 [
26], Nie Y et al. proposed a BERT-based language identification system (BERT-LID) to improve language identification performance, especially on short speech segments. Recently, target language extraction has been introduced as a new task [
27], which treats the cocktail party problem as a multilingual scenario that separates all of the voices of people speaking in the target language from the rest of the voices at once. A recent study [
28] extended this task to multiple target languages and extracted all the speech signals as one specific language. Based on previous research, another study [
29] proposed the blind language separation task, which separates overlap** speech by language. These methods can be clearly seen in
Table 1 below.
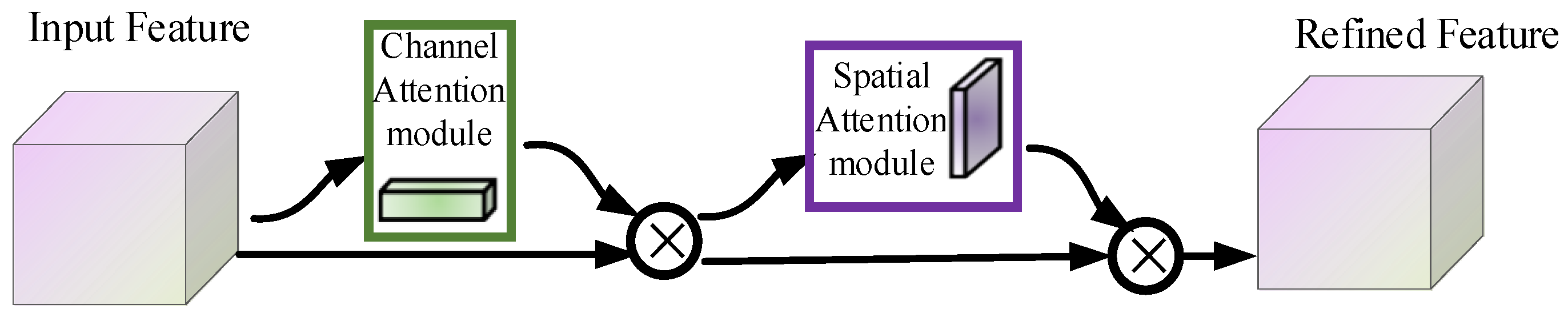
In this study, we took the CNN-CBAM-BiLSTM [
30] network based on the dual attention mechanism convolutional block attention module (CBAM) as the baseline model and improved it with the SE-Res2Net network by proposing a multi-scale language identification method. This study constructed a multilingual cocktail party dataset to simulate a multilingual cocktail party scene considering the complex acoustic scenarios in real life, and comparative experiments were also conducted on this dataset with different models.
4. Experiments and Discussion
4.1. Dataset
① The Oriental language dataset used in this paper was provided by the AP17-OLR competition [
8]. In this paper, we used the following five languages for our experiments: Mandarin (zh-cn), Vietnamese (vi-vn), Indonesian (id-id), Japanese (ja-jp), and Korean (ko-kr). For each language, 1800 speech data were extracted and divided into a dataset with a ratio of 7:2:1 (training set/validation set/test set), and the structure of the dataset is listed in
Table 2.
② Multilingual cocktail party dataset: We created a multilingual cocktail party dataset based on the Oriental language dataset to simulate a real multilingual overlap** speech scene. The process was as follows: First, we cut the original data into 4s segments. Second, we randomly selected some speech for each language and split it into target and non-target speakers. Third, we mixed them with different overlap rates according to the scenario needs. The result was a multilingual cocktail party dataset. For the language identification task, we assigned numerical labels to each language, such as “0” for “id-id”, “1” for “ja-jp”, and so on.
4.2. Network Parameters
The experiments in this study were conducted in a Linux environment using Python as the programming language, Pytorch as the deep learning framework, and CUDA version 11.4 on an NVIDIA GeForce GTX 3090 GPU and Intel(R) Xeon(R) Gold 6128 CPU @ 3.40 GHz.
During the training and validation phases, the language identification network model had a 224 × 224 spectral map as the input, a batch size of 32 × 32, and a learning rate of 0.0001, and we used the Adam optimizer and cross-entropy loss function. In each convolutional layer, the sizes and numbers of convolutional kernels were (7 × 7.16), (5 × 5.32), (3 × 3.32), and (3 × 3.32), respectively. The span of the convolution kernels was 1 and the padding was 0. The size of the convolution kernels in the pooling layer was 3, the span was 2, and the padding was 0.
4.3. Performance Evaluation
The performance evaluation metrics used in the experiments were the accuracy, precision, recall, and F1 score values. When predicting a piece of speech, four statistical results will appear, namely, the target language is judged as the target language (TP), the target language is judged as the non-target language (FN), the non-target language is judged as the target language (TN), and the non-target language is judged as the non-target language (TN), as shown in
Table 3.
According to
Table 3, the calculation formulas of the accuracy, precision, recall, and F1 values can be obtained, as shown below.
4.4. Experimental Results and Analysis
In this section, we used the SE-Res2-Net-CBAM-BiLSTM language identification model proposed in this paper to carry out experiments on the Oriental Corpus and our own multilingual cocktail party corpus. There were three experimental tasks.
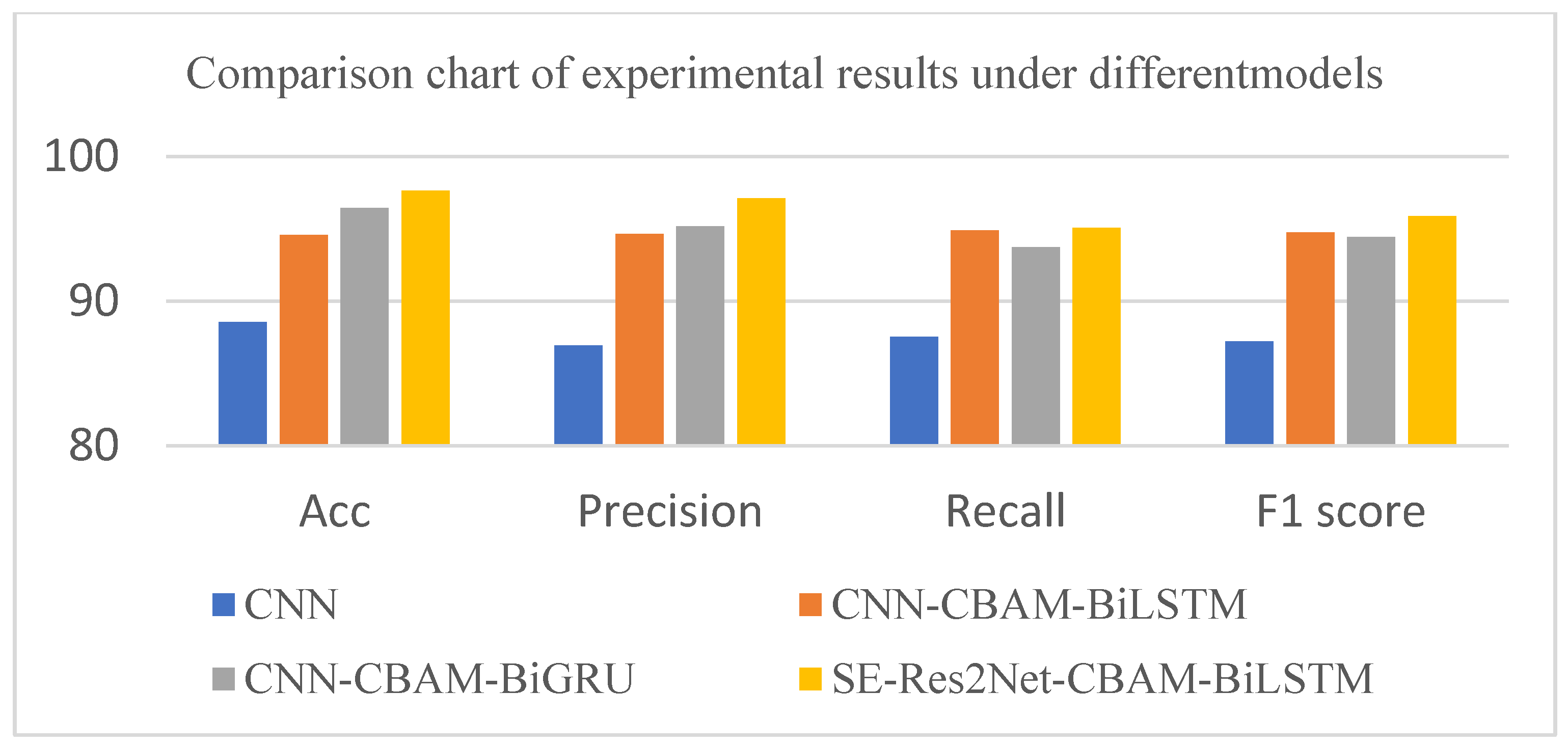
Task 1: Three different models were selected and compared using the language spectrogram as input features, and their experimental results are shown in
Figure 9.
As can be seen in
Figure 9, for the four different models, the SE-Res2Net-CBAM-BiLSTM model had higher values than the other three models for the evaluation metrics corresponding to the AP17-OLR dataset, with an accuracy of 97.64%. The results in this paper show an accuracy improvement of about 3% compared to the baseline model CNN- CBAM-BiLSTM. This is because we replaced the CNN network with the SE-Res2Net network module in the baseline model. The SE-Res2Net network is a new multi-scale backbone network structure that can represent multi-scale features at a fine-grained level and increase the receptive field range of each network layer. These advantages can help SE-Res2Net-CBAM-BiLSTM networks to better understand and extract features so as to achieve better performance in language identification tasks.
We conducted experiments on the CNN-CBAM-BiLSTM model and the SE-Res2Net-CBAM-BiLSTM model using an Oriental language dataset.
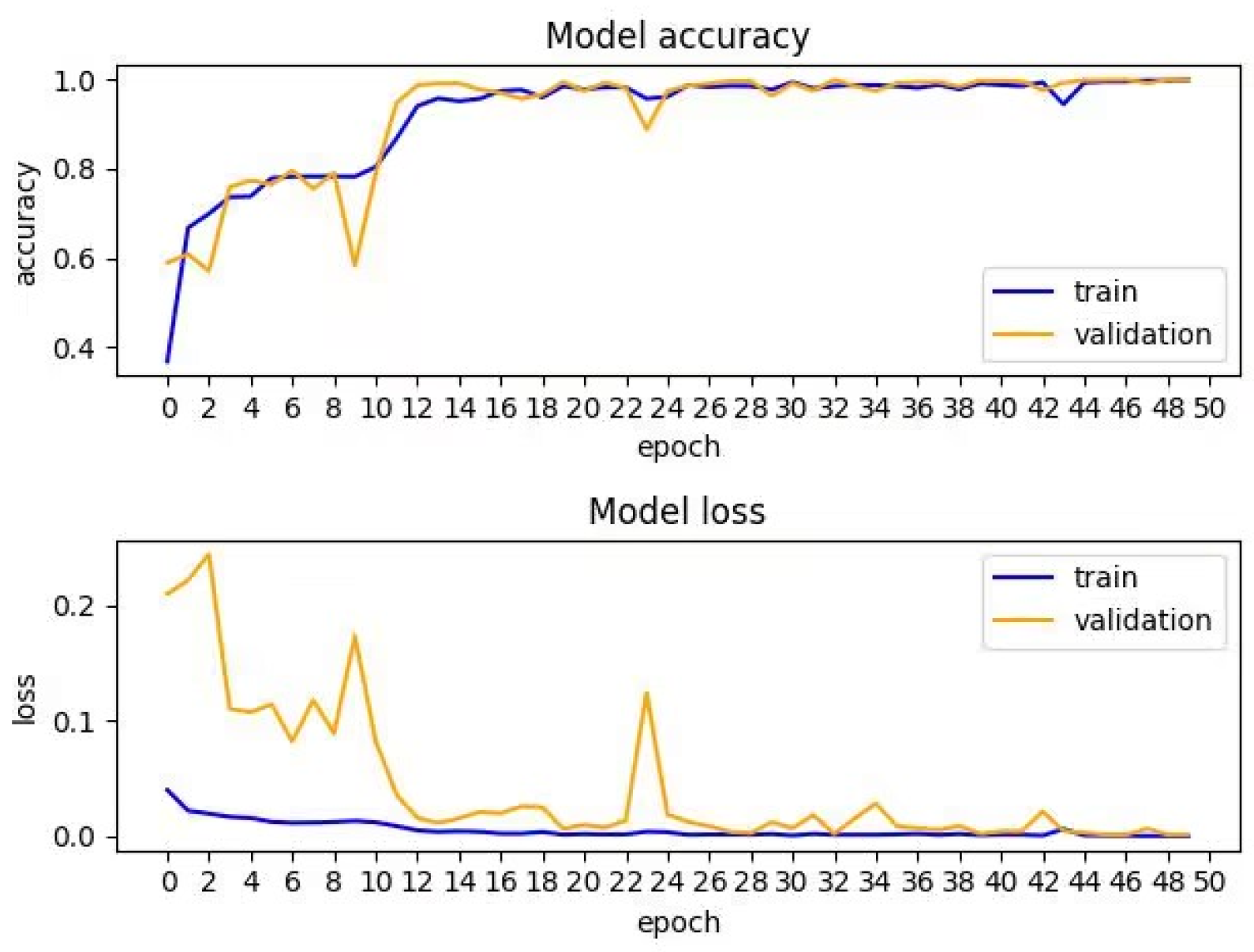
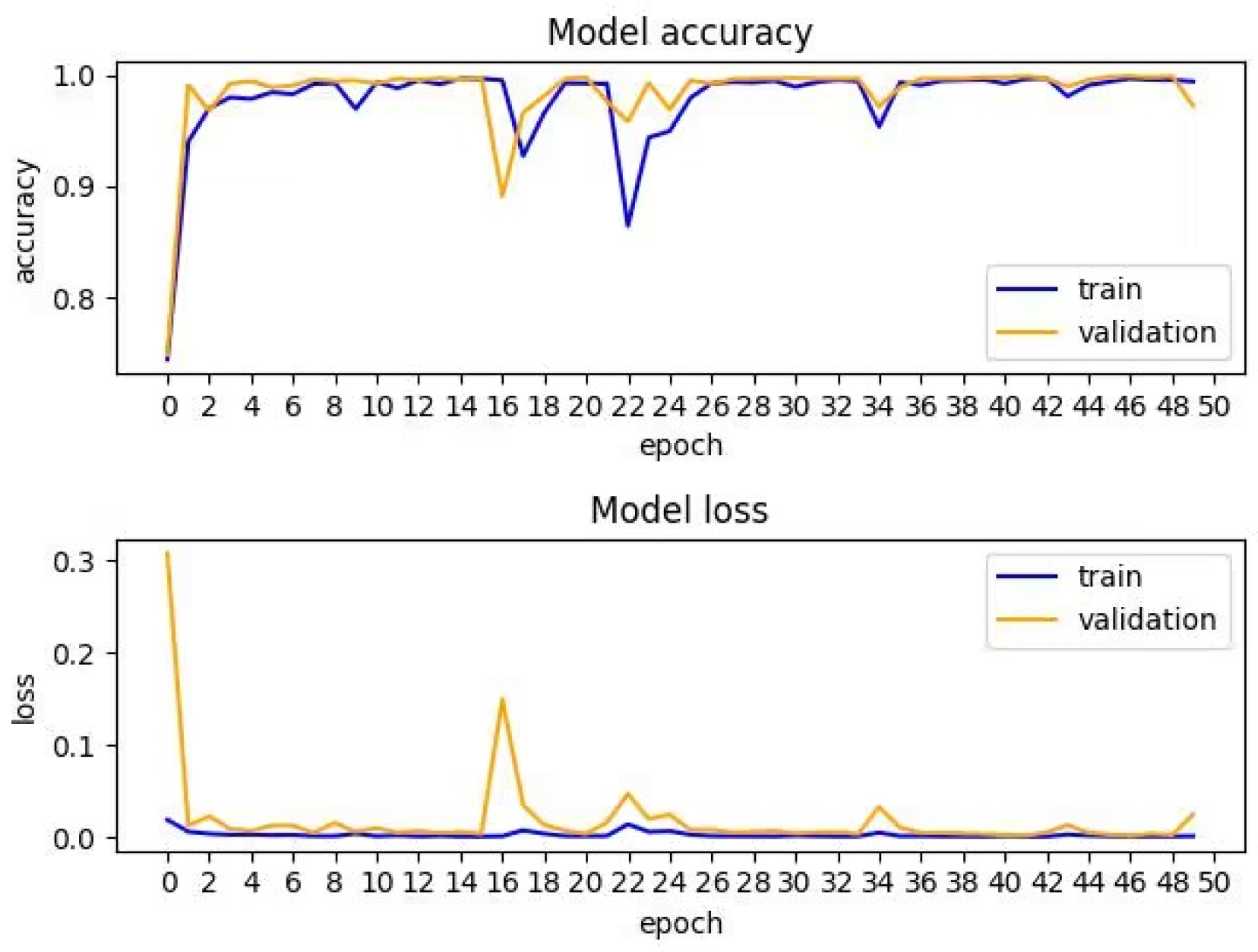
Figure 10 and
Figure 11 show the accuracy and loss changes in the training and validation sets.
Figure 10 shows the CNN-CBAM-BiLSTM model’s curves, and
Figure 11 shows the SE-Res2Net-CBAM-BiLSTM model’s curves. The blue curves are for the training set, and the yellow curves are for the validation set.
Figure 10 and
Figure 11 show that on the CNN-CBAM-BiLSTM model, the accuracy and loss curves fluctuate, and thus, affect the stability of the model. In contrast, on the SE-Res2Net-CBAM-BiLSTM model, the accuracy and loss curve fluctuations were relatively minor and more stable.
Task 2: In this section, a comparative test on the multilingual cocktail dataset with a 100% overlap rate was carried out on the baseline model and the improved model. The accuracy of the baseline model CNN-CBAM-BiLSTM was 64%, and the specific results are shown in
Table 4.
The improved SE-Res2Net-CBAM-BiLSTM model was used on a multilingual cocktail party scenario in which the target language weight was 1.2 and the non-target language weight was 1. When the overlap was set to 100%, the accuracy of the model was 75%, as shown in
Table 5.
As seen in
Table 4 and
Table 5, after using the model proposed in this article, the accuracy of the model on the multilingual cocktail party dataset was significantly improved by 11% compared to the baseline model. Thus, this also validates the effectiveness of the improved model proposed in this paper.
Task 3: Comparison of loss functions. In the previous language identification model, cross-entropy loss was used for classification, but it needed to take into account the problems of unbalanced data and confusion of languages. We used focal loss [
36] to solve this problem effectively and improved the model performance. The results of language identification under different loss functions are shown in
Table 6 below.
As can be seen in
Table 6, the model with the focal loss function performed better when experimenting with both loss functions under the unified model. Compared to the cross-entropy loss, the recognition accuracy under the focal loss was improved by about 1%. Therefore, the experimental results show that the performance of the language identification network using the focal loss function was better than that using the cross-entropy loss function.
4.5. Limitation
This paper proposes a SE-Res2Net-CBAM-BiLSTM model, a language identification method based on a multi-scale feature extraction network. This model improves the recognition performance compared to the baseline, but it still faces some difficulties in dealing with multilingual overlap** speech scenarios. One of the reasons is that this study only used public datasets and our synthesized multilingual cocktail dataset, which simulated the situation of different energy ratios with only two speakers. However, actual multilingual overlap** speech scenes are more complex and may involve three or more speakers and languages. Therefore, future research can explore more realistic and diverse datasets, as well as more advanced feature extraction and recognition techniques. The aim of this paper was to propose a novel language identification method that can handle multilingual overlap** speech effectively. We will continue to improve the performance of the model while studying more complex multilingual cocktail party scenarios.
5. Conclusions and Future Work
In this paper, we propose an improved SE-Res2Net-CBAM-BiLSTM method that can extract multi-scale features from speech signals. We evaluated our method on two datasets: AP17-OLR, a public Oriental language dataset, and a multilingual cocktail party dataset that we constructed with different energy ratios and speaker numbers. The experimental results show that the language identification accuracy of the improved SE-Res2-Net-CBAM-BiLSTM network on the AP17-OLR dataset was improved by about 3% compared to the baseline model CNN-CBAM-BiLSTM. On a multilingual cocktail party dataset of a 100% overlapped scenario, with a target language weight of 1.2 over the non-target language weight of 1, the accuracy of the proposed model was improved by 11% compared to the baseline model. In addition, the comparative experiments show that the accuracy, recall, and F1 values of the model in this paper were improved over the other three models, and the stable model performance indicates better robustness. Finally, different loss functions were also compared, and the focal loss method produced better results.
In the future, we will design new model frameworks to improve the performance of language identification networks. In addition, we will variously simulate multi-language cocktail party scenarios and conduct joint training experiments on source separation and language identification tasks.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
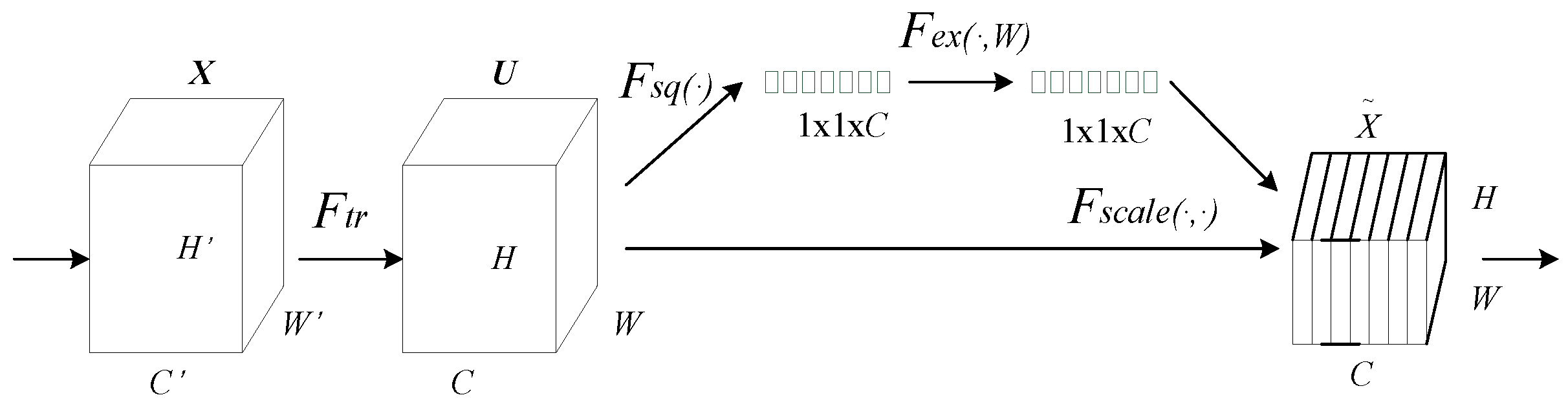{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}