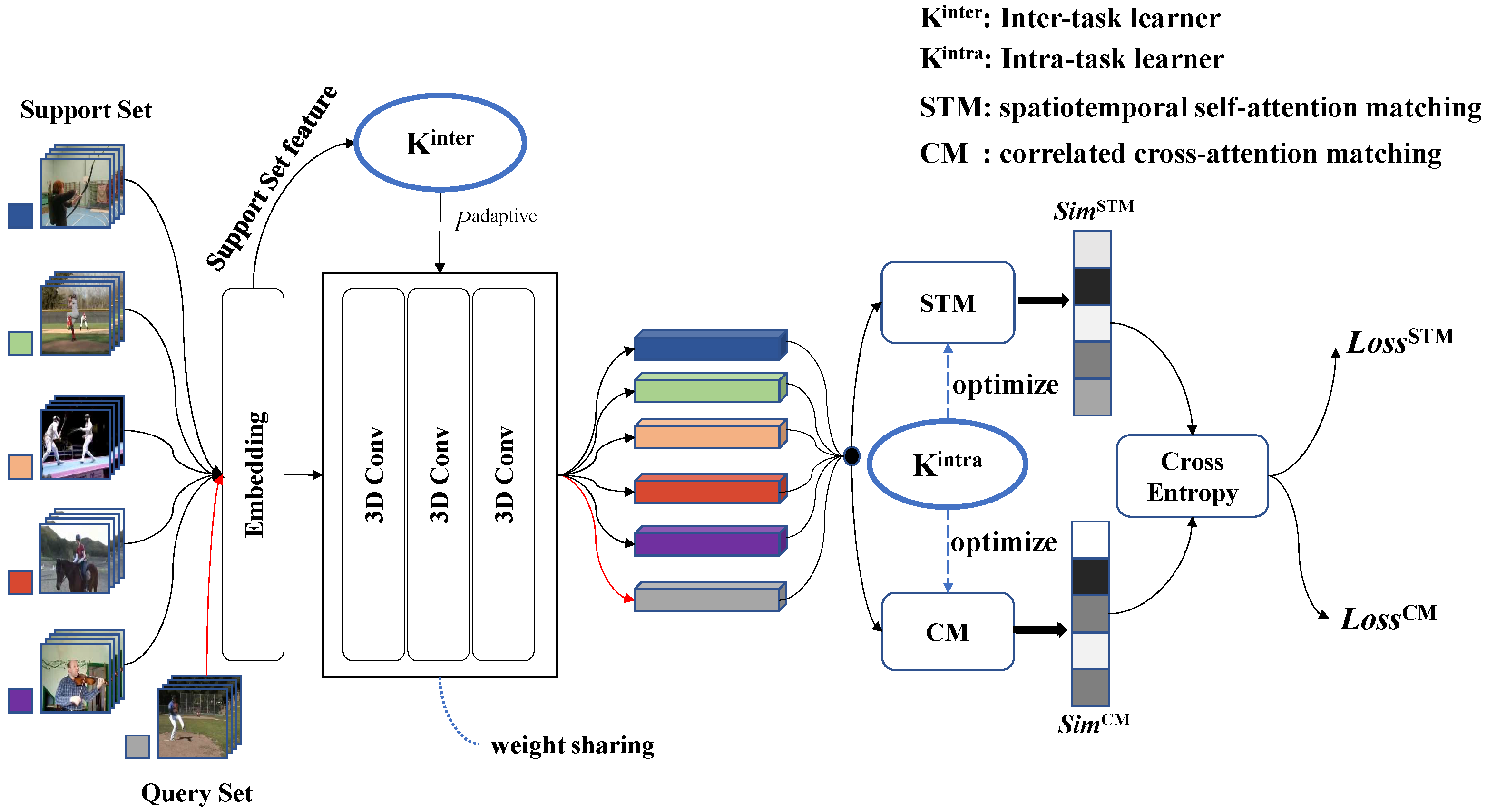
To investigate the effectiveness of
and
, we introduced a comparative model called HiTIM*. The model is based on HiTIM, but with
and
removed, while the inputs and outputs remain the same, as shown in
Table 4. In
, D3D is replaced with 3D convolution.
The results of the ablation study of
and
are shown in
Table 4. Results for
, compared to HiTIM*, HiTIM*+
achieved a recognition-accuracy improvement of 1.41% and 1.11% for HMDB51 and UCF101, respectively. The additional parameters introduced by
implicitly capture the knowledge of inter-task differences in the few-shot scenario. As shown in
Figure 8, in the task-related feature space established by
, the intra-class distance of video features from five random categories was reduced, while the inter-class distance was increased. The experimental results demonstrated that
could construct task-related feature space and increase recognition accuracy, confirming its effectiveness. Results for
, compared with HiTIM*, HiTIM*+
achieved recognition-accuracy improvement of 0.67% and 0.86% for HMDB51 and UCF101, respectively. The parameters of
contain implicit feature information, which can be used to mine the key parts of the attention matrix. The experimental results indicated that the attention mechanism had a limited feature enhancement effect, and
enhanced the distribution of key feature information and the correlation between features, thereby reducing the degree of redundancy of task-specific features and aligning them. Results for
+
, compared to HiTIM* +
and HiTIM* +
, HiTIM achieved recognition-accuracy improvements of 0.90% and 1.64% in recognition accuracy for HMDB51, and improvements of 0.48% and 0.73% for UCF101, respectively.
extracts task-related features by exploring the differences between tasks, whereas
enhances the self-information and mutual information of features within the task. The experimental results indicated that the combination of
and
led to significantly better performance than the use of
or
alone. This is attributed to the fact that
generates task-specific features, and
enhances them. The joint use of these two modules resulted in the extraction of more discriminative features, improving the recognition performance. Results for D3D, compared with HiTIM* +
+
, HiTIM achieved recognition-accuracy improvements of 0.74% and 0.99% for the HMDB51 and UCF101, respectively. The D3D, with added offsets for each sampling point in the convolution kernel, increases the convolution receptive field and enhances the modeling capability. The experimental results demonstrate that the use of D3D helps
to mine task-related knowledge, further demonstrating the effectiveness of
.
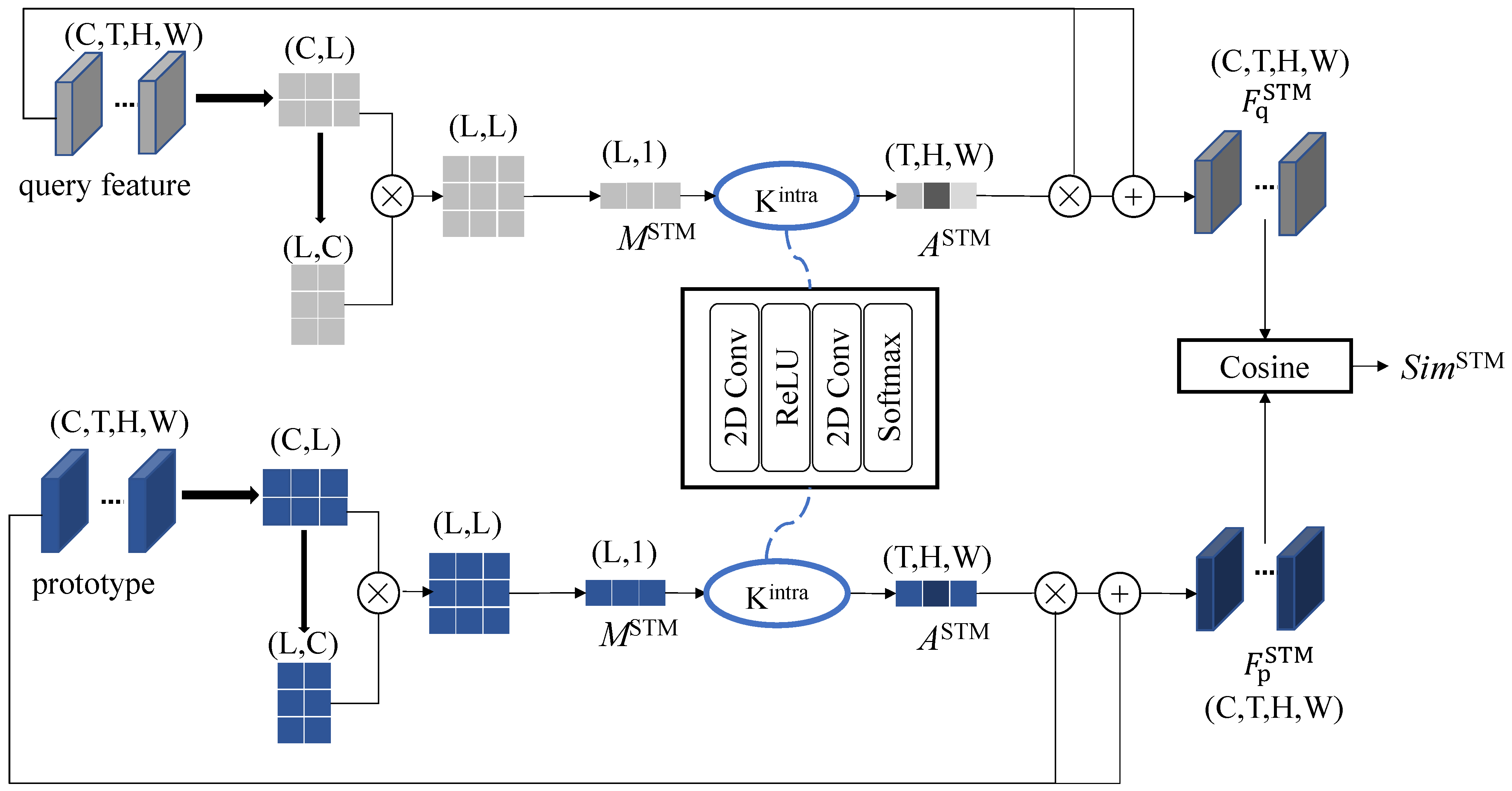
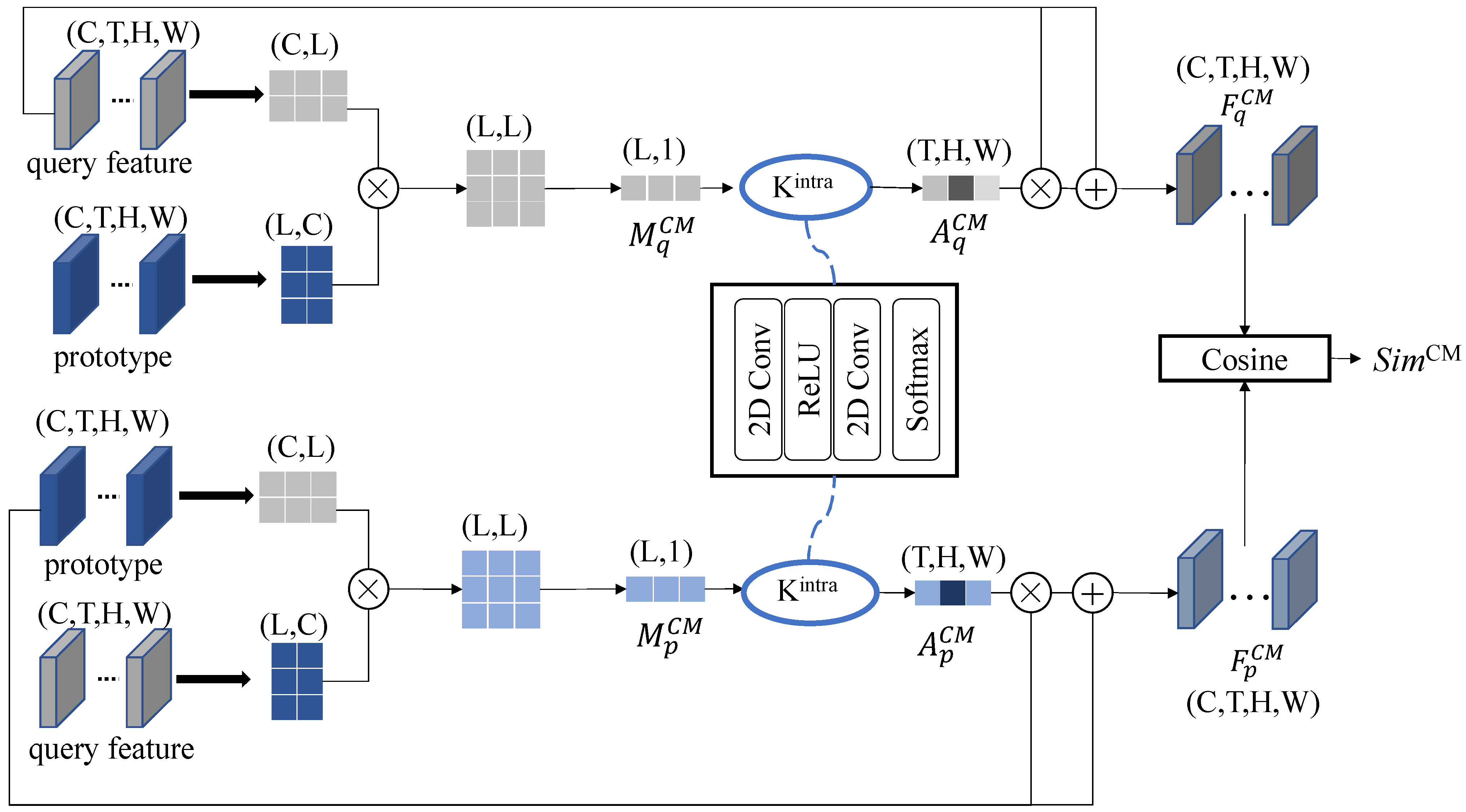
To investigate the effects of the proposed metric module and its two branches (STM and CM) on the results, we conducted ablation experiments on the matching module.
The results of the ablation study of STM and CM are shown in
Table 5. Results for STM, compared with the cosine distance, the recognition accuracy of STM was 5.45% and 6.54% higher for the HMDB51 and UCF101, respectively. STM enhances the importance of key regions by exploring the correlation between spatiotemporal feature points inside the features. The experimental results indicated that the STM significantly increased recognition accuracy, suggesting that key regions of features largely determine the accuracy of matching. Results for CM, compared with the cosine distance, the recognition accuracy of CM was 5.13% and 6.14% higher for the HMDB51 and UCF101, respectively. The CM explores the correlation between the query-set and support-set features, assigning lager weights to the key parts that are correlated. The experimental results indicated that CM significantly increased recognition accuracy, suggesting that the mutual information between features influences the accuracy of matching. Results for STM and CM, the experimental results indicated that using both STM and CM increased the recognition accuracy compared with using STM or CM alone, confirming the effectiveness of the proposed matching module.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}