
A Systematic Review of Transformer-Based Pre-Trained Language Models through Self-Supervised Learning

Abstract
:1. Introduction
- An overview of the transformer network architecture and its core concepts.
- Self-supervised learning based on unlabeled datasets for transformer-based pretrained models.
- Explains the fundamental principles of pre-training techniques and activities for downstream adaption.
- Future trends for pretrained transformer-based language models.
2. Materials and Methods
2.1. Review Planning
Objectives and Research Questions
- RQ1: What are the various transformer-based pretrained models available for NLP processing?
- RQ2: What are the various pretraining techniques available?
- RQ3: What datasets or corpora are used for pretraining language models?
- RQ4: What are the challenges associated with transformer-based language model pretraining based on self-supervised learning?
- RQ5: How and when to choose a pretraining model for an NLP task?
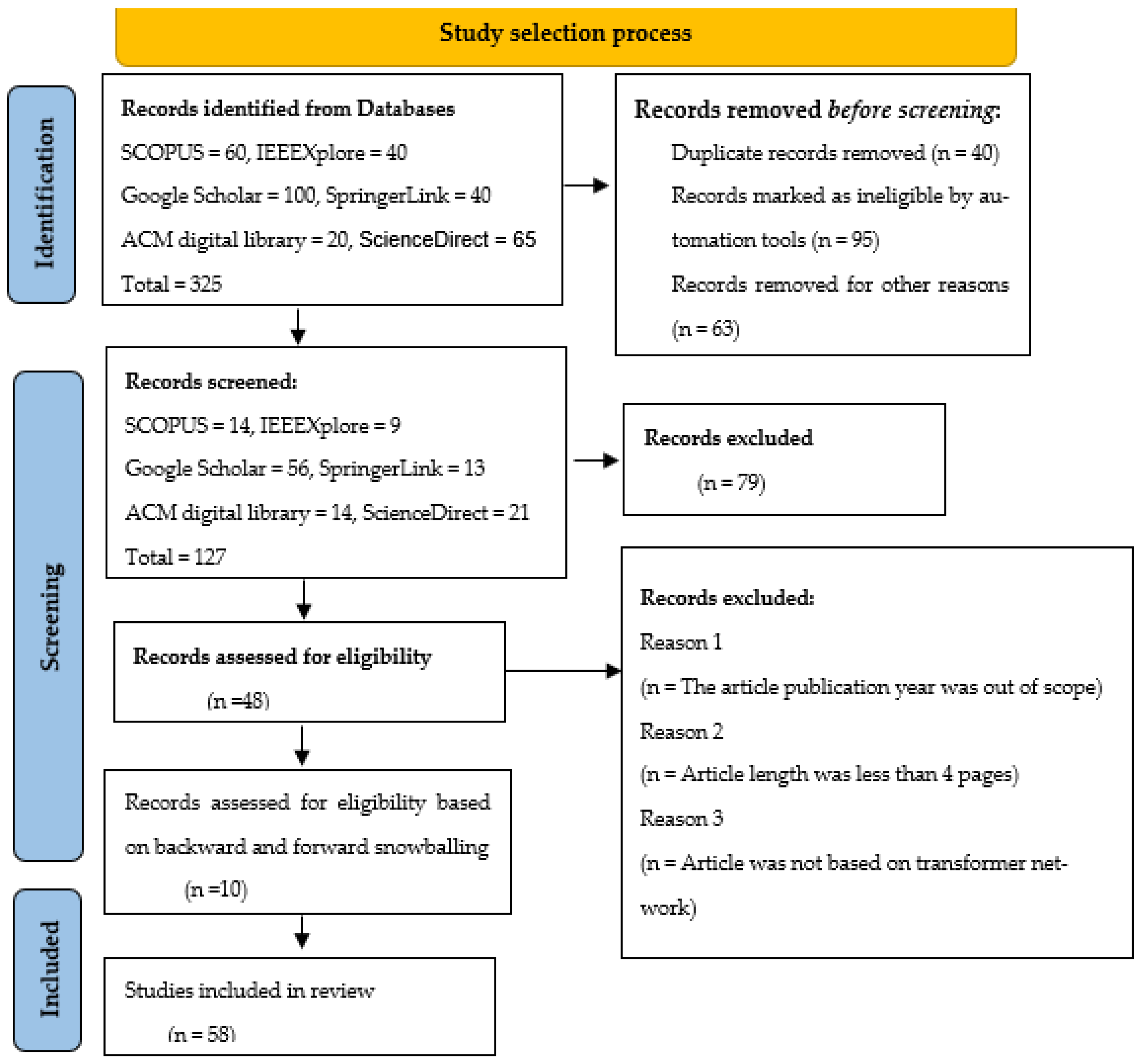
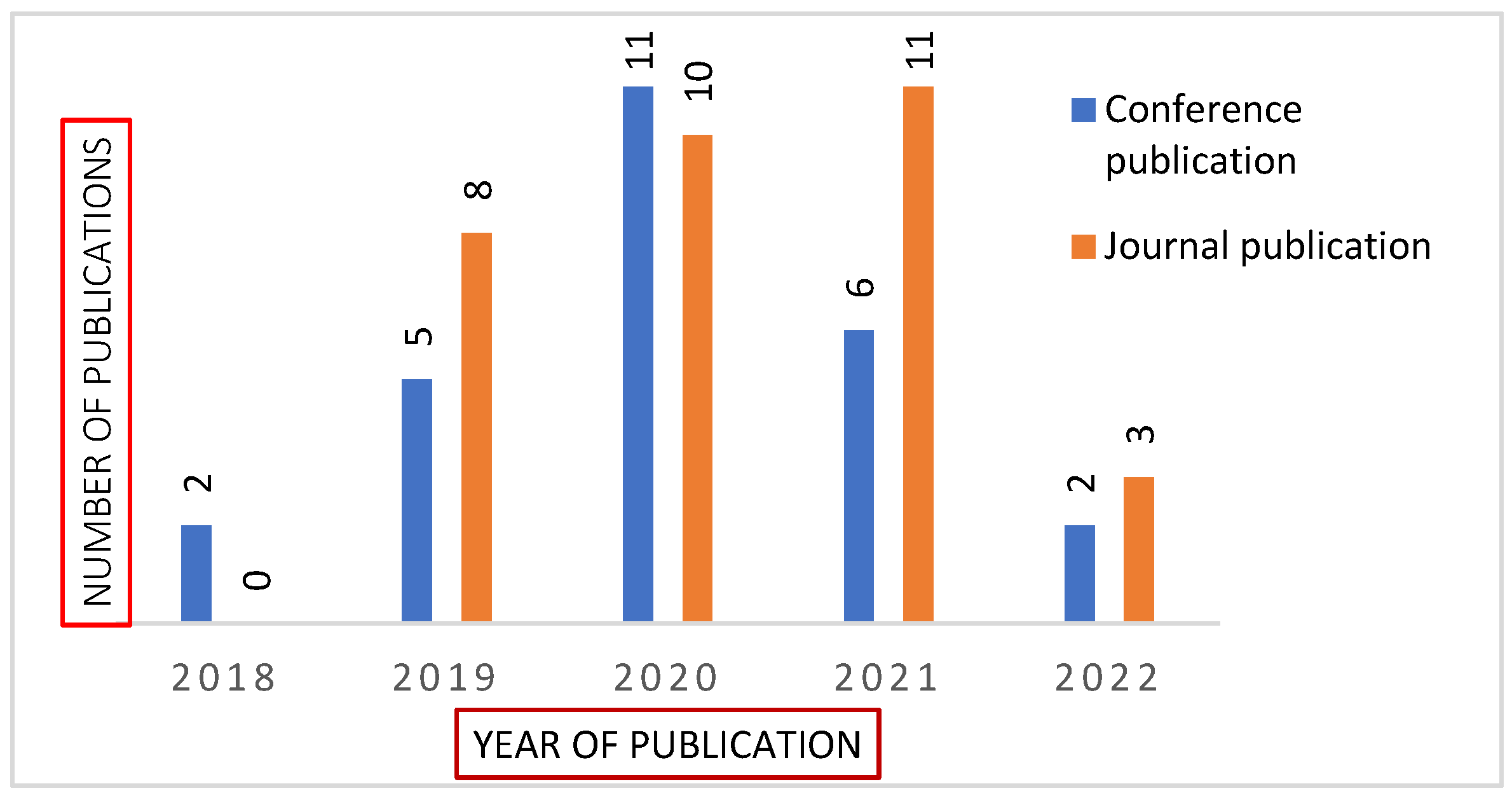
2.2. Search Strategy
2.2.1. Snowballing Approach
2.2.2. Screening Criteria
2.2.3. Exclusion Criteria
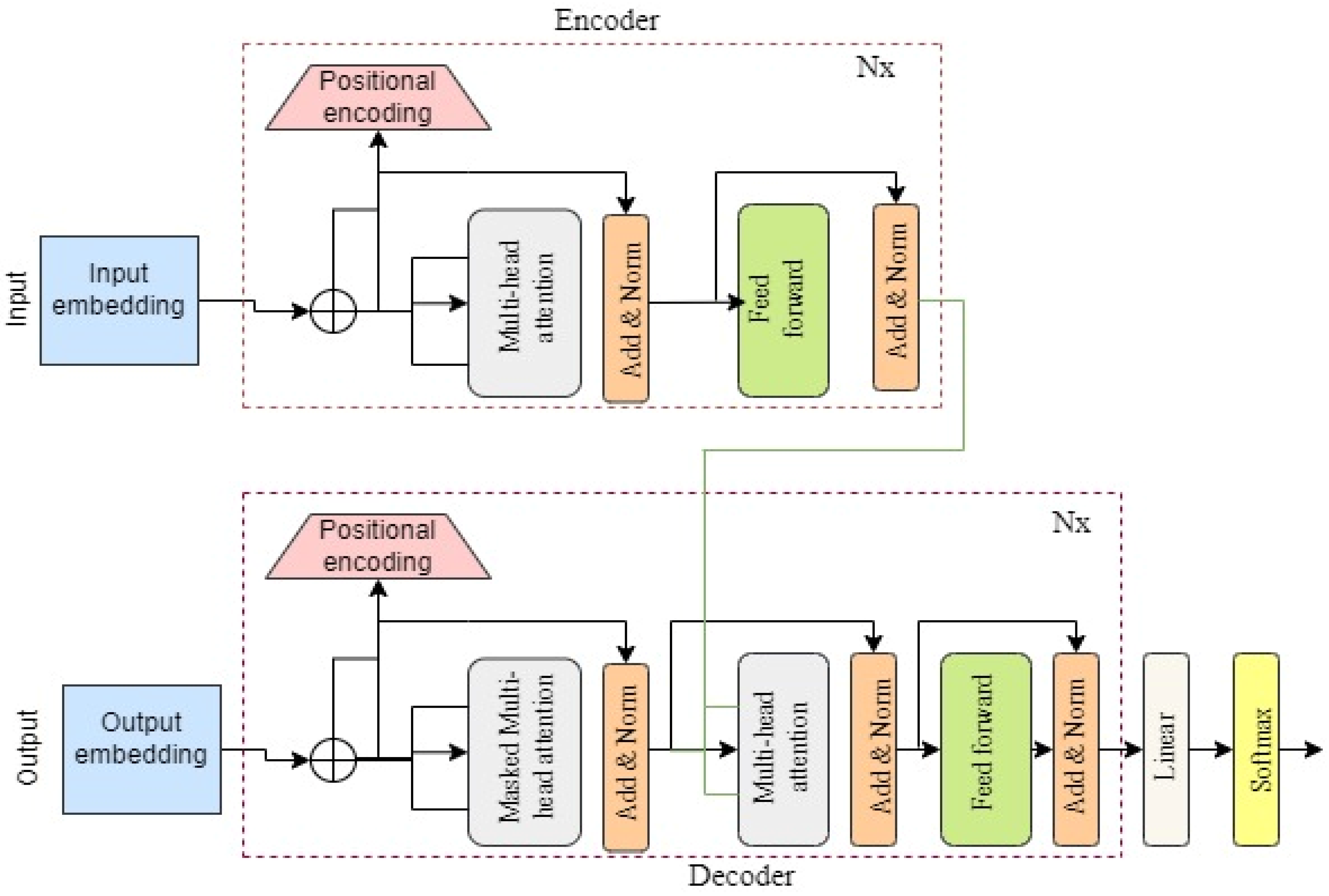
3. Transformer Network
3.1. Encoder and Decoder Stacks
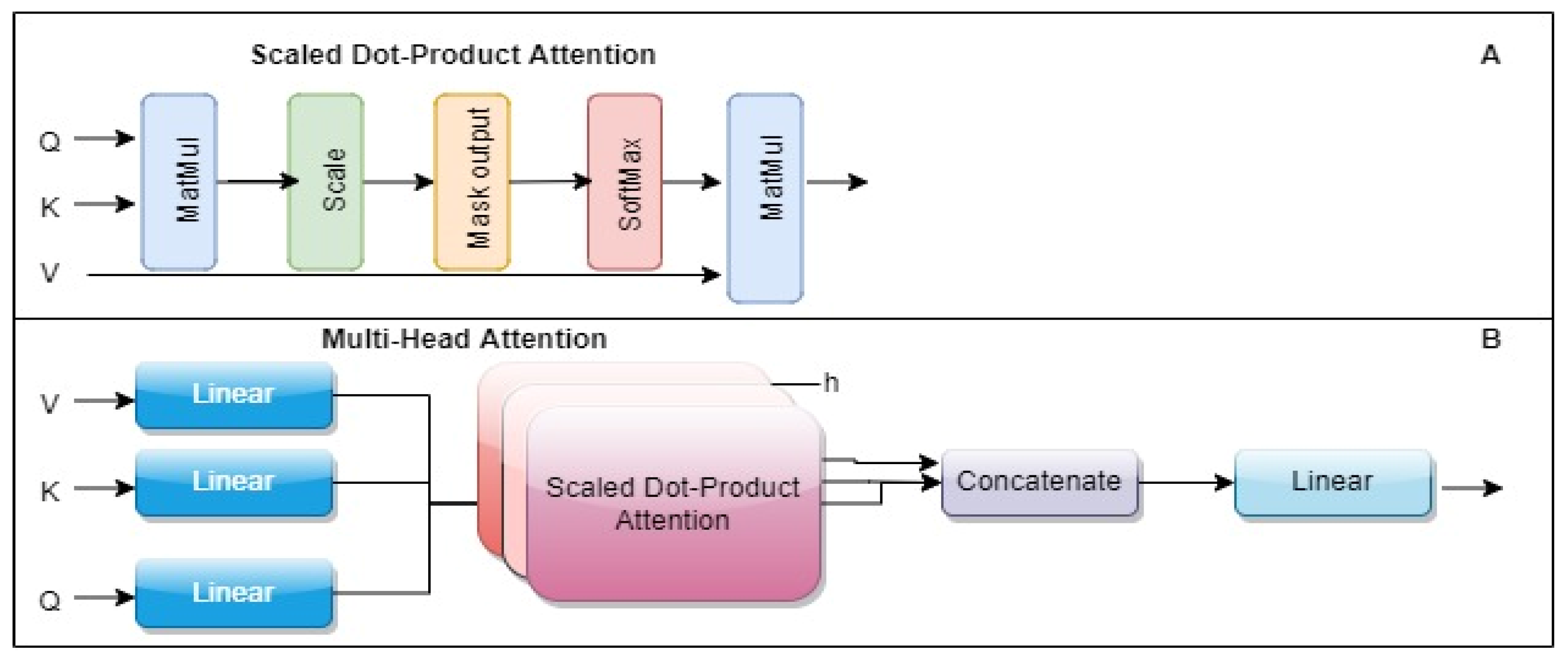
3.2. Attention
4. Self-Supervised Learning (SSL)
4.1. Why Self-Supervised Learning?
- Supervised learning requires a human-annotated dataset, which is expensive to generate, especially a domain-specific dataset.
- Poor generalization because the model tries to memorize the training data and suffers from unseen data during classification.
- Limitation of deep learning applications in domains where labelled data are less example, in the medical health sector.
4.2. Self-Supervised Learning—Explained
4.3. Self-Supervised Applications in NLP Applications
5. Pretrained Language Models Based on Transformer Network
- Pretrained models extract low-level information from unlabeled text datasets to enhance downstream tasks for performance optimization.
- The disadvantages of building models from scratch with minimal data sets are eliminated via transfer learning.
- Fast convergence with optimized performance even on smaller datasets.
- Transfer learning mitigates the overfitting problem in deep learning applications due to limited training datasets [54].
5.1. Transformer-Based Language Model Pretraining Process
5.2. Dataset
5.3. Transformer-Based Language Model Pretraining Techniques
5.3.1. Pretraining from Scratch
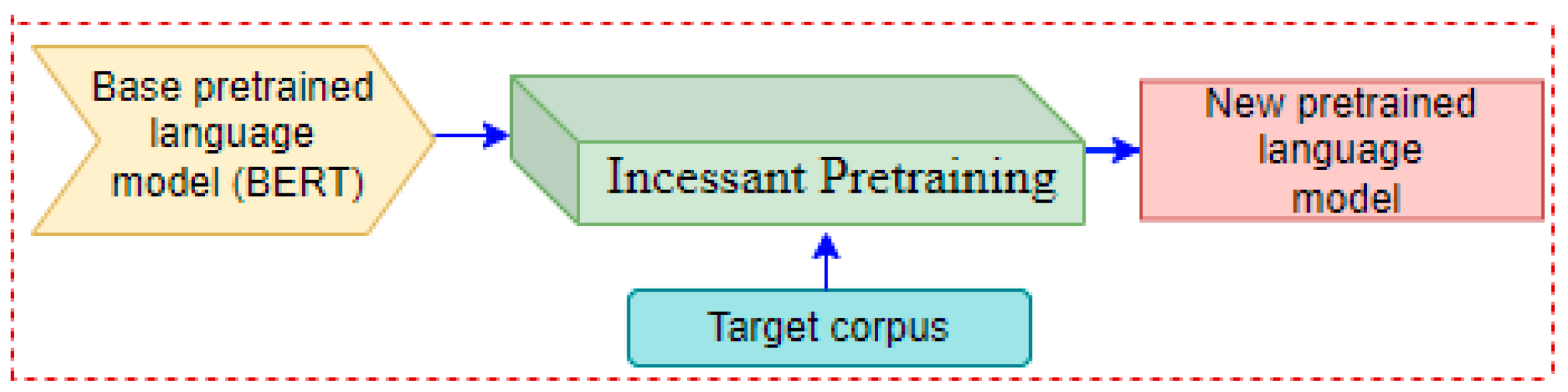
5.3.2. Incessant Pretraining
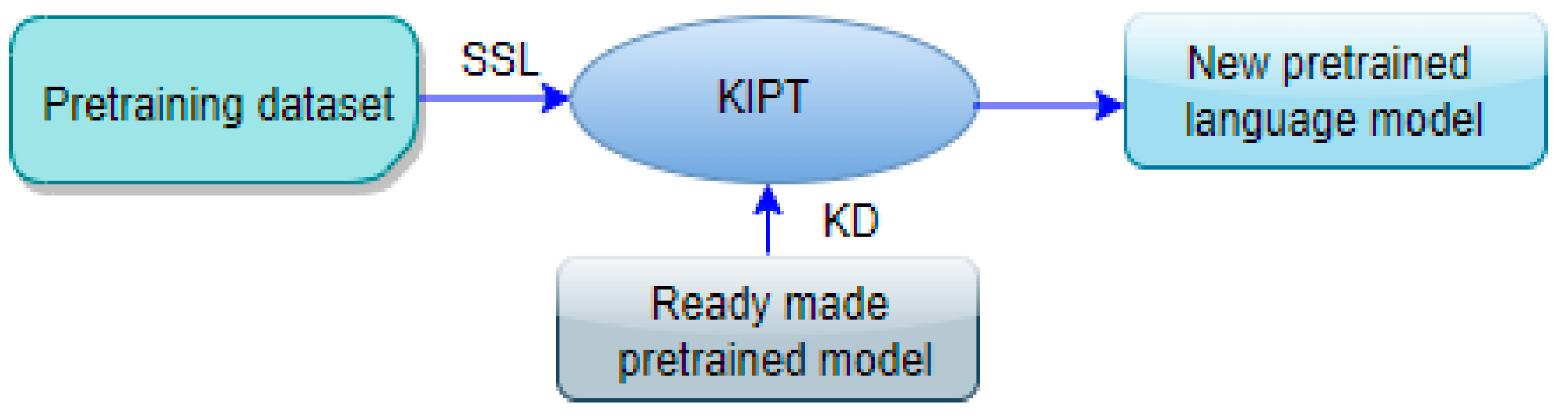
5.3.3. Pretraining Based on Knowledge Inheritance
5.3.4. Multi-Task Pre-Training
5.4. Word Embedding Types in Transformer-Based Pretraining Models
5.4.1. Text/Character Embeddings
5.4.2. Code Embeddings
5.4.3. Sub-Word Embeddings
5.5. Secondary Embeddings
5.5.1. Positional Embeddings
5.5.2. Sectional Embeddings
5.5.3. Language Embeddings
6. Knowledge Transfer Techniques for Downstream Tasks
6.1. Word Feature Transfer
6.2. Fine-Tuning
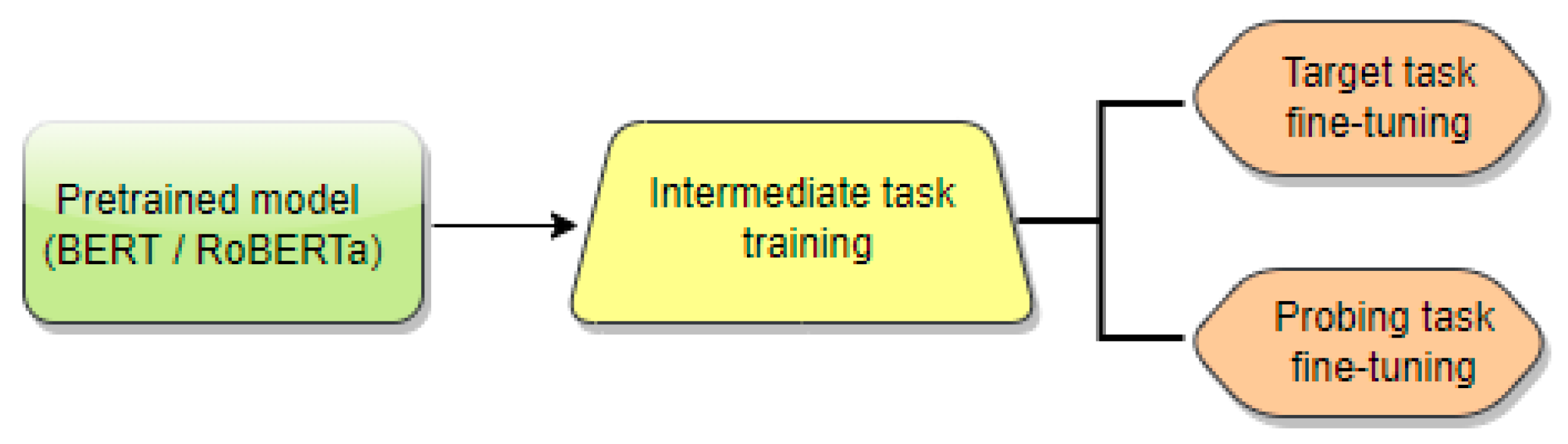
6.3. Intermediate-Task Transfer Learning
7. Discussion, Open Challenges, and Future Directions
7.1. Optimized Pretraining Techniques
7.2. Domain Specific Pretraining
7.3. Dataset/Corpus
7.4. Model Efficacy
7.5. Model Adaptation
7.6. Benchmarks
7.7. Security Concerns
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A Convolutional Neural Network for Modelling Sentences. ar**v 2014. [Google Scholar] [CrossRef] [Green Version]
- Liu, P.; Qiu, X.; Xuan**g, H. Recurrent neural network for text classification with multi-task learning. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 2873–2879. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A lite BERT for self-supervised learning of language representations. ar**v 2019, ar**v:1909.11942v6. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL HLT 2019—2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A robustly optimized BERT pretraining approach. ar**v 2019, ar**v:1907.11692v1. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32, 1–11. [Google Scholar]
- Fausk, H.; Isaksen, D.C. t-model structures. Homol. Homotopy Appl. 2007, 9, 399–438. [Google Scholar] [CrossRef] [Green Version]
- Clark, K.; Luong, M.-T.; Le, Q.V.; Manning, C.D. ELECTRA: Pre-training text encoders as discriminators rather than generators. In Proceedings of the ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020; pp. 1–18. [Google Scholar]
- Zhang, J.; Zhao, Y.; Saleh, M.; Liu, P.J. PEGASUS: Pre-training with extracted gap-sentences for abstractive summarization. In Proceedings of the 37th International Conference on Machine Learning (ICML 2020), Virtual Event, 13–18 July 2020; Volume PartF16814, pp. 11265–11276. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Kotei, E.; Thirunavukarasu, R. Ensemble Technique Coupled with Deep Transfer Learning Framework for Automatic Detection of Tuberculosis from Chest X-ray Radiographs. Healthcare 2022, 10, 2335. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, Y.; Ma, L.; Li, J.; Zheng, W.-S. Spectral–Spatial Transformer Network for Hyperspectral Image Classification: A Factorized Architecture Search Framework. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High Quality Object Detection and Instance Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable transformers for end-to-end object detection. In Proceedings of the ICLR 2021, Virtual Event, 3–7 May 2021; pp. 1–16. [Google Scholar]
- Balakrishnan, G.; Zhao, A.; Sabuncu, M.R.; Guttag, J.; Dalca, A.V. VoxelMorph: A Learning Framework for Deformable Medical Image Registration. IEEE Trans. Med. Imaging 2019, 38, 1788–1800. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- **e, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 15, 12077–12090. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015-Conference Track Proceedings), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Chouhan, V.; Singh, S.K.; Khamparia, A.; Gupta, D.; Tiwari, P.; Moreira, C.; Damaševičius, R.; de Albuquerque, V.H.C. A Novel Transfer Learning Based Approach for Pneumonia Detection in Chest X-ray Images. Appl. Sci. 2020, 10, 559. [Google Scholar] [CrossRef] [Green Version]
- Coccia, M. Deep learning technology for improving cancer care in society: New directions in cancer imaging driven by artificial intelligence. Technol. Soc. 2019, 60, 101198. [Google Scholar] [CrossRef]
- Fang, X.; Liu, Z.; Xu, M. Ensemble of deep convolutional neural networks based multi-modality images for Alzheimer’s disease diagnosis. IET Image Process. 2020, 14, 318–326. [Google Scholar] [CrossRef]
- Apostolopoulos, I.D.; Mpesiana, T.A. COVID-19: Automatic detection from X-ray images utilizing transfer learning with convolutional neural networks. Phys. Eng. Sci. Med. 2020, 43, 635–640. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5999–6009. [Google Scholar]
- Yang, Y.; Uy, M.C.S.; Huang, A. FinBERT: A Pretrained language model for financial communications. ar**v 2020, ar**v:2006.08097v2. [Google Scholar]
- Leivaditi, S.; Rossi, J.; Kanoulas, E. A Benchmark for lease contract review. ar**v 2020, ar**v:2010.10386v1. [Google Scholar]
- Chalkidis, I.; Fergadiotis, M.; Malakasiotis, P.; Aletras, N.; Androutsopoulos, I. LEGAL-BERT: The muppets straight out of law school. ar**v 2020, ar**v:2010.02559v1, 2898–2904. [Google Scholar] [CrossRef]
- Wu, C.-S.; Hoi, S.; Socher, R.; **ong, C. TOD-BERT: Pre-trained Natural Language Understanding for. In Proceedings of the Emnlp2020, Online, 16–20 November 2020; pp. 917–929. [Google Scholar]
- Liu, X.; Yin, D.; Zheng, J.; Zhang, X.; Zhang, P.; Yang, H.; Dong, Y.; Tang, J. OAG-BERT: Towards a Unified Backbone Language Model for Academic Knowledge Services. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining 2022, Washington, DC, USA, 14–18 August 2022. [Google Scholar] [CrossRef]
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: Pretrained contextualized embeddings for scientific text. ar**v 2019, ar**v:1903.10676. [Google Scholar]
- Peng, S.; Yuan, K.; Gao, L.; Tang, Z. MathBERT: A pre-trained model for mathematical formula understanding. ar**v 2021, ar**v:2105.00377v1. [Google Scholar]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2019, 36, 1234–1240. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alsentzer, E.; Murphy, J.; Boag, W.; Weng, W.-H.; **di, D.; Naumann, T.; McDermott, M. Publicly available clinical BERT embeddings. In Proceedings of the 2nd Clinical Natural Language Processing Workshop, Minneapolis, MN, USA, 6–7 June 2019. [Google Scholar] [CrossRef] [Green Version]
- Yuxian, G.; Robert Tinn, R.; Hao Cheng, H.; Lucas, M.; Usuyama, N.; Liu, X.; Naumann, T.; Gao, J.; Poon, H. Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing. ar**v 2020, ar**v:abs/2007.15779. [Google Scholar]
- Badampudi, D.; Petersen, K. Experiences from using snowballing and database searches in systematic literature studies Categories and Subject Descriptors. In Proceedings of the 19th International Conference on Evaluation and Assessment in Software Engineering, Nan**g, China, 27–29 April 2015; pp. 1–10. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 4, 3104–3112. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Bahdanau, D.; Cho, K.H.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Britz, D.; Goldie, A.; Luong, M.-T.; Le, Q. Massive Exploration of Neural Machine Translation Architectures. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017. [Google Scholar] [CrossRef] [Green Version]
- Cheng, J.; Dong, L.; Lapata, M. Long Short-Term Memory-Networks for Machine Reading. ar**v 2016, ar**v:1601.06733. [Google Scholar]
- Lin, Z.; Feng, M.; Santos, C.N.; Yu, M.; **ang, B.; Zhou, B.; Bengio, Y. A structured self-attentive sentence embedding. In Proceedings of the 5th International Conference on Learning Representations (ICLR 2017), Toulon, France, 24–26 April 2017; pp. 1–15. [Google Scholar]
- Lewis, J.C.; Floyd, I.J. Reorientation effects in vitreous carbon and pyrolytic graphite. J. Mater. Sci. 1966, 1, 154–159. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, F.; Hou, Z.; Mian, L.; Wang, Z.; Zhang, J.; Tang, J. Self-supervised Learning: Generative or Contrastive. IEEE Trans. Knowl. Data Eng. 2021, 35, 857–876. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, H.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Liu, Q.; Kusner, M.J.; Blunsom, P. A Survey on contextual embeddings. ar**v 2020, ar**v:2003.07278v2. [Google Scholar]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in Vision: A Survey. ACM Comput. Surv. 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Yang, J.; Li, C.; Zhang, P.; Dai, X.; **ao, B.; Yuan, L.; Gao, J. Focal Self-attention for Local-Global Interactions in Vision Transformers. ar**v 2021, ar**v:2107.00641. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 16–18 June 2020; pp. 9759–9768. [Google Scholar]
- Park, D.; Chun, S.Y. Classification based grasp detection using spatial transformer network. ar**v 2018, ar**v:1803.01356v1. [Google Scholar]
- Kirillov, A.; He, K.; Girshick, R.; Rother, C.; Dollár, P. Panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9404–9413. [Google Scholar]
- Prangemeier, T.; Reich, C.; Koeppl, H. Attention-Based Transformers for Instance Segmentation of Cells in Microstructures. In Proceedings of the 2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Seoul, Republic of Korea, 16–19 December 2020; pp. 700–707. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. In Proceedings of the 1st International Conference on Learning Representations (ICLR 2013), Scottsdale, AZ, USA, 2–4 May 2013; pp. 1–12. [Google Scholar]
- Erhan, D.; Courville, A.; Bengio, Y.; Vincent, P. Why does unsupervised pre-training help deep learning? J. Mach. Learn. Res. 2010, 9, 201–208. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. ar**v 2016, ar**v:1609.08144v2. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural machine translation of rare words with subword units. ar**v 2016, ar**v:1508.07909. [Google Scholar]
- Kudo, T.; Richardson, J. SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Y.; Kiros, R.; Zemel, R.; Salakhutdinov, R.; Urtasun, R.; Torralba, A.; Fidler, S. Aligning Books and Movies: Towards Story-Like Visual Explanations by Watching Movies and Reading Books. In Proceedings of the IEEE International Conference on Computer Vision 2015, Washington, DC, USA, 7–13 December 2015; pp. 19–27. [Google Scholar] [CrossRef] [Green Version]
- Conneau, A.; Lample, G. Cross-lingual language model pretraining. ar**v 2019, ar**v:1901.07291v1. [Google Scholar]
- Tiedemann, J. Parallel data, tools and interfaces in OPUS. In Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC 2012), Istanbul, Turkey, 23–25 May 2012; pp. 2214–2218. [Google Scholar]
- Liu, Y.; Gu, J.; Goyal, N.; Li, X.; Edunov, S.; Ghazvininejad, M.; Lewis, M.; Zettlemoyer, L. Multilingual Denoising Pre-training for Neural Machine Translation. Trans. Assoc. Comput. Linguist. 2020, 8, 726–742. [Google Scholar] [CrossRef]
- Wenzek, G.; Lachaux, M.A.; Conneau, A.; Chaudhary, V.; Guzmán, F.; Joulin, A.; Grave, E. CCNet: Extracting high quality monolingual datasets from web crawl data. In Proceedings of the 12th International Conference on Language Resources and Evaluation (LREC 2020), Marseille, France, 11–16 May 2020; pp. 4003–4012. [Google Scholar]
- Wang, W.; Bi, B.; Yan, M.; Wu, C.; Bao, Z.; **a, J.; Peng, L.; Si, L. StructBERT: Incorporating language structures into pre-training for deep language understanding. ar**v 2019, ar**v:1908.04577v3. [Google Scholar]
- Joshi, M.; Chen, D.; Liu, Y.; Weld, D.S.; Zettlemoyer, L.; Levy, O. SpanBERT: Improving Pre-training by Representing and Predicting Spans. Trans. Assoc. Comput. Linguist. 2020, 8, 64–77. [Google Scholar] [CrossRef]
- El Boukkouri, H.; Ferret, O.; Lavergne, T.; Noji, H.; Zweigenbaum, P.; Tsujii, J. CharacterBERT: Reconciling ELMo and BERT for Word-Level Open-Vocabulary Representations From Characters. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 6903–6915. [Google Scholar] [CrossRef]
- Clark, J.H.; Garrette, D.; Turc, I.; Wieting, J. Canine: Pre-training an Efficient Tokenization-Free Encoder for Language Representation. Trans. Assoc. Comput. Linguist. 2022, 10, 73–91. [Google Scholar] [CrossRef]
- Xue, L.; Barua, A.; Constant, N.; Al-Rfou, R.; Narang, S.; Kale, M.; Roberts, A.; Raffel, C. ByT5: Towards a Token-Free Future with Pre-trained Byte-to-Byte Models. Trans. Assoc. Comput. Linguist. 2022, 10, 291–306. [Google Scholar] [CrossRef]
- Tay, Y.; Tran, V.Q.; Ruder, S.; Gupta, J.; Chung, H.W.; Bahri, D.; Qin, Z.; Baumgartner, S.; Yu, C.; Metzler, D. Charformer: Fast character transformers via gradient-based subword tokenization. ar**v 2021, ar**v:2106.12672v3. [Google Scholar]
- Di Liello, L.; Gabburo, M.; Moschitti, A. Efficient pre-training objectives for Transformers. ar**v 2021, ar**v:2104.09694v1. [Google Scholar]
- Qin, Y.; Lin, Y.; Yi, J.; Zhang, J.; Han, X.; Zhang, Z.; Su, Y.; Liu, Z.; Li, P.; Sun, M.; et al. Knowledge Inheritance for Pre-trained Language Models. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 10–15 July 2022; pp. 3921–3937. [Google Scholar] [CrossRef]
- Zhang, Z.; Gu, Y.; Han, X.; Chen, S.; **ao, C.; Sun, Z.; Yao, Z.S.Y.; Qi, F.; Guan, J.; Ke, P.; et al. CPM-2: Large-scale cost-effective pre-trained language models. AI Open 2021, 2, 216–224. [Google Scholar] [CrossRef]
- You, Y.; Li, J.; Reddi, S.; Hseu, J.; Kumar, S.; Bhojanapalli, S.; Song, X.; Demmel, J.; Keutzer, K.; Hsieh, C.J. Large batch optimization for deep learning: Training BERT in 76 minutes. ar**v 2019, ar**v:1904.00962v5. [Google Scholar]
- Peng, Y.; Yan, S.; Lu, Z. Transfer Learning in Biomedical Natural Language Processing: An Evaluation of BERT and ELMo on Ten Benchmarking Datasets. In Proceedings of the 18th BioNLP Workshop and Shared Task, Florence, Italy, 1 August 2019. [Google Scholar] [CrossRef] [Green Version]
- Gururangan; Marasovi, A.; Lo, K.; Beltagy, I.; Downey, D.; Smith, N.A. Don’t stop pretraining: Adapt language models to domains and tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8342–8360. [Google Scholar]
- Suárez, P.J.O.; Sagot, B.; Romary, L. Asynchronous pipeline for processing huge corpora on medium to low resource infrastructures. In Proceedings of the 7th Workshop on the Challenges in the Management of Large Corpora (CMLC-7), Cardiff, UK, 22 July 2019. [Google Scholar]
- Cahyawijaya, S.; Winata, G.I.; Wilie, B.; Vincentio, K.; Li, X.; Kuncoro, A.; Ruder, S.; Lim, Z.Y.; Bahar, S.; Khodra, M.; et al. IndoNLG: Benchmark and Resources for Evaluating Indonesian Natural Language Generation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Virtual Event, 7–11 November 2021; pp. 8875–8898. [Google Scholar] [CrossRef]
- Khanuja, S.; Bansal, D.; Mehtani, S.; Khosla, S.; Dey, A.; Gopalan, B.; Margam, D.K.; Aggarwal, P.; Nagipogu, R.T.; Dave, S.; et al. MuRIL: Multilingual representations for Indian languages. ar**v 2021, ar**v:2103.10730v2. [Google Scholar]
- Kakwani, D.; Kunchukuttan, A.; Golla, S.; Gokul, N.C. IndicNLPSuite: Monolingual corpora, evaluation benchmarks and Pre-trained multilingual language models for Indian languages. In Findings of the Association for Computational Linguistics: EMNLP 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 4948–4961. [Google Scholar] [CrossRef]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 483–498. [Google Scholar]
- Chi, Z.; Dong, L.; Ma, S.; Huang, S.; Singhal, S.; Mao, X.-L.; Huang, H.-Y.; Song, X.; Wei, F. mT6: Multilingual Pretrained Text-to-Text Transformer with Translation Pairs. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Virtual Event, 7–11 November 2021; pp. 1671–1683. [Google Scholar] [CrossRef]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8440–8451. [Google Scholar] [CrossRef]
- Chi, Z.; Huang, S.; Dong, L.; Ma, S.; Zheng, B.; Singhal, S.; Bajaj, P.; Song, X.; Mao, X.-L.; Huang, H.-Y.; et al. XLM-E: Cross-lingual Language Model Pre-training via ELECTRA. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 6170–6182. [Google Scholar] [CrossRef]
- Chi, Z.; Dong, L.; Wei, F.; Yang, N.; Singhal, S.; Wang, W.; Song, X.; Mao, X.-L.; Huang, H.-Y.; Zhou, M. InfoXLM: An Information-Theoretic Framework for Cross-Lingual Language Model Pre-Training. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 3576–3588. [Google Scholar] [CrossRef]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Brussels, Belgium, 1 November 2018. [Google Scholar] [CrossRef] [Green Version]
- Caselli, T.; Basile, V.; Mitrović, J.; Granitzer, M. HateBERT: Retraining BERT for Abusive Language Detection in English. In Proceedings of the 5th Workshop on Online Abuse and Harms (WOAH 2021), Online, 6 August 2021; pp. 17–25. [Google Scholar] [CrossRef]
- Zhou, J.; Tian, J.; Wang, R.; Wu, Y.; **ao, W.; He, L.S. ENTI X: A Sentiment-aware pre-trained model for cross-domain sentiment analysis. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 568–579. [Google Scholar]
- Ni, J.; Li, J.; McAuley, J. Justifying Recommendations using Distantly-Labeled Reviews and Fine-Grained Aspects. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 188–197. [Google Scholar]
- Johnson, A.E.W.; Pollard, T.J.; Shen, L.; Lehman, L.-W.H.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Celi, L.A.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef] [Green Version]
- Zellers, Y.C.R.; Holtzman, A.; Rashkin, H.; Farhadi, Y.B.A.; Roesner, F. Defending against neural fake news. ar**v 2020, ar**v:1905.12616v3. [Google Scholar]
- Idrissi-Yaghir, A.; Schäfer, H.; Bauer, N.; Friedrich, C.M. Domain Adaptation of Transformer-Based Models Using Unlabeled Data for Relevance and Polarity Classification of German Customer Feedback. SN Comput. Sci. 2023, 4, 1–13. [Google Scholar] [CrossRef]
- Carmo, D.; Piau, M.; Campiotti, I.; Nogueira, R.; Lotufo, R. PTT5: Pretraining and validating the T5 model on Brazilian Portuguese data. ar**v 2020, ar**v:2008.09144v2. [Google Scholar]
- Filho, J.A.W.; Wilkens, R.; Idiart, M.; Villavicencio, A. The BRWAC corpus: A new open resource for Brazilian Portuguese. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018; pp. 4339–4344. [Google Scholar]
- Gonçalo Oliveira, H.; Real, L.; Fonseca, E. (Eds.) Organizing the ASSIN 2 Shared Task. In Proceedings of the ASSIN 2 Shared Task: Evaluating Semantic Textual Similarity and Textual Entailment in Portuguese, Salvador, BA, Brazil, 15 October 2019; Volume 2583. [Google Scholar]
- Xu, L.; Zhang, X.; Dong, Q. CLUECorpus2020: A large-scale Chinese corpus for pre-training language model. ar**v 2020, ar**v:2003.01355v2. [Google Scholar]
- Yuan, S.; Zhao, H.; Du, Z.; Ding, M.; Liu, X.; Cen, Y.; Zou, X.; Yang, Z.; Tang, J. WuDaoCorpora: A super large-scale Chinese corpora for pre-training language models. AI Open 2021, 2, 65–68. [Google Scholar] [CrossRef]
- Liu, X.; He, P.; Chen, W.; Gao, J. Multi-Task Deep Neural Networks for Natural Language Understanding. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar] [CrossRef] [Green Version]
- Khan, M.R.; Ziyadi, M.; AbdelHady, M. MT-BioNER: Multi-task learning for biomedical named entity recognition using deep bidirectional transformers. ar**v 2020, ar**v:2001.08904v1. [Google Scholar]
- Mulyar, A.; Uzuner, O.; McInnes, B. MT-clinical BERT: Scaling clinical information extraction with multitask learning. J. Am. Med. Inform. Assoc. 2021, 28, 2108–2115. [Google Scholar] [CrossRef]
- Wang, Y.; Fu, S.; Shen, F.; Henry, S.; Uzuner, O.; Liu, H. The 2019 n2c2/OHNLP Track on Clinical Semantic Textual Similarity: Overview. JMIR Public Health Surveill. 2020, 8, e23375. [Google Scholar] [CrossRef]
- Peng, Y.; Chen, Q.; Lu, Z. An Empirical Study of Multi-Task Learning on BERT for Biomedical Text Mining. In Proceedings of the 19th SIGBioMed Workshop on Biomedical Language Processing, Online, 9 July 2020. [Google Scholar] [CrossRef]
- Ganesh, P.; Chen, Y.; Lou, X.; Khan, M.A.; Yang, Y.; Sajjad, H.; Nakov, P.; Chen, D.; Winslett, M. Compressing Large-Scale Transformer-Based Models: A Case Study on BERT. Trans. Assoc. Comput. Linguist. 2021, 9, 1061–1080. [Google Scholar] [CrossRef]
- Chen, Y.-P.; Chen, Y.-Y.; Lin, J.-J.; Huang, C.-H.; Lai, F. Modified Bidirectional Encoder Representations From Transformers Extractive Summarization Model for Hospital Information Systems Based on Character-Level Tokens (AlphaBERT): Development and Performance Evaluation. JMIR Public Health Surveill. 2020, 8, e17787. [Google Scholar] [CrossRef] [PubMed]
- Meng, Y.; Speier, W.; Ong, M.K.; Arnold, C.W. Bidirectional Representation Learning From Transformers Using Multimodal Electronic Health Record Data to Predict Depression. IEEE J. Biomed. Health Inform. 2021, 25, 3121–3129. [Google Scholar] [CrossRef]
- Rasmy, L.; **ang, Y.; **e, Z.; Tao, C.; Zhi, D. Med-BERT: Pretrained contextualized embeddings on large-scale structured electronic health records for disease prediction. NPJ Digit. Med. 2021, 4, 86. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Rao, S.; Solares, J.R.A.; Hassaine, A.; Ramakrishnan, R.; Canoy, D.; Zhu, Y.; Rahimi, K.; Salimi-Khorshidi, G. BEHRT: Transformer for Electronic Health Records. Sci. Rep. 2020, 10, 7155. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.; Liang, Y.; Duan, N.; Gong, M.; Shou, L.; Jiang, D.; Zhou, M. Unicoder: A Universal Language Encoder by Pre-training with Multiple Cross-lingual Tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 2485–2494. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Ma, S.; Zhang, D.; Wu, S.; Li, Z.; Zhou, M. Alternating Language Modeling for Cross-Lingual Pre-Training. Proc. Conf. AAAI Artif. Intell. 2020, 34, 9386–9393. [Google Scholar] [CrossRef]
- He, P.; Liu, X.; Gao, J.; Chen, W. DeBERTa: Decoding-enhanced BERT with Disentangled Attention. ar**v 2020, ar**v:2006.03654v6. [Google Scholar]
- Phang, J.; Févry, T.; Bowman, S.R. Sentence Encoders on STILTs: Supplementary training on intermediate labeled-data tasks. ar**v 2019, ar**v:1811.01088v2. [Google Scholar]
- Howard, J.; Sebastian, R. Universal Language Model Fine-tuning for Text Classificatio. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 328–339. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Srikumar, V. A Closer Look at How Fine-tuning Changes BERT. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; pp. 1046–1061. [Google Scholar] [CrossRef]
- Merchant, A.; Rahimtoroghi, E.; Pavlick, E.; Tenney, I. What Happens To BERT Embeddings During Fine-tuning? In Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP, Online, 20 November 2020; pp. 33–44. [Google Scholar] [CrossRef]
- Mosbach, M.; Khokhlova, A.; Hedderich, M.A.; Klakow, D. On the Interplay Between Fine-tuning and Sentence-Level Probing for Linguistic Knowledge in Pre-Trained Transformers. In Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP, Online, 20 November 2020; pp. 68–82. [Google Scholar] [CrossRef]
- Hao, Y.; Dong, L.; Wei, F.; Xu, K. Investigating learning dynamics of BERT fine-tuning. In Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing, Suzhou, China, 4–7 December 2020; pp. 87–92. [Google Scholar]
- Raghu, M.; Gilmer, J.; Yosinski, J.; Sohl-Dickstein, J. SVCCA: Singular vector canonical correlation analysis for deep learning dynamics and interpretability. Adv. Neural Inf. Process. Syst. 2017, 30, 6077–6086. [Google Scholar]
- Pruksachatkun, Y.; Phang, J.; Liu, H.; Htut, P.M.; Zhang, X.; Pang, R.Y.; Vania, C.; Kann, K.; Bowman, S.R. Intermediate-Task Transfer Learning with Pretrained Language Models: When and Why Does It Work? In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 5231–5247. [Google Scholar] [CrossRef]
- Mccreery, C.H.; Chablani, M.; Amatriain, X. For Medical Question Similarity. In Proceedings of the Machine Learning for Health (ML4H) at NeurIPS 2019, Vancouver, BC, Canada, 13 December 2019; pp. 1–6. [Google Scholar]
- Cengiz, C.; Sert, U.; Yuret, D. KU_ai at MEDIQA 2019: Domain-specific Pre-training and Transfer Learning for Medical NLI. In Proceedings of the 18th BioNLP Workshop and Shared Task, Florence, Italy, 1 August 2019. [Google Scholar] [CrossRef]
- Jeong, M.; Sung, M.; Kim, G.; Kim, D. Transferability of natural language inference to biomedical question answering. ar**v 2021, ar**v:2007.00217v4. [Google Scholar]
- Williams, A.; Nangia, N.; Bowman, S. A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018. [Google Scholar] [CrossRef] [Green Version]
- Bowman, S.R.; Angeli, G.; Potts, C.; Manning, C. A large annotated corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015. [Google Scholar] [CrossRef]
- Sun, C.; Yang, Z.; Wang, L.; Zhang, Y.; Lin, H.; Wang, J. Biomedical named entity recognition using BERT in the machine reading comprehension framework. J. Biomed. Inform. 2021, 118, 103799. [Google Scholar] [CrossRef]
- Wang, Y.; Verspoor, K.; Baldwin, T. Learning from Unlabelled Data for Clinical Semantic Textual Similarity. In Proceedings of the 3rd Clinical Natural Language Processing Workshop, Online, 19 November 2020; pp. 227–233. [Google Scholar] [CrossRef]
- Jiang, Z.; Yu, W.; Zhou, D.; Chen, Y.; Feng, J.; Yan, S. ConvBERT: Improving BERT with span-based dynamic convolution. Adv. Neural Inf. Process. Syst. 2020, 33, 12837–12848. [Google Scholar]
- Carlini, N.; Tramer, F.; Wallace, E.; Jagielski, M.; Herbert-Voss, A.; Lee, K.; Roberts, A.; Brown, T.B.; Song, D.; Erlingsson, U.; et al. Extracting training data from large language models. In Proceedings of the 30th USENIX Security Symposium, Online, 11–13 August 2021; pp. 2633–2650. [Google Scholar]
- Nakamura, Y.; Hanaoka, S.; Nomura, Y.; Hayashi, N.; Abe, O.; Yada, S.; Wakamiya, S.; Aramaki, E. KART: Privacy leakage framework of anguage models pre-trained with clinical records. ar**v 2022, ar**v:2101.00036v2. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Keyword |
|---|---|
| Transformer-based natural language processing | Transformer network for NLP application, natural language processing, attention-based NLP models, representation learning from transformers |
| Pretrained language models | BERT models for natural language processing, intermediate fine tuning on language models, pretraining text models. |
| Transfer learning approaches for NLP | NLP-based self-supervised learning, transfer learning for language tasks, deep transfer learning for NLP |
| Reference | Model | Dataset (Corpus) | Vocabulary | Vocabulary Size | Tokenizer |
|---|---|---|---|---|---|
| Lan et al., [3] | ALBERT | English Wikipedia and Books Corpus [58] | WordPiece | 30,000 | SentencePiece [57] |
| Devlin et al., [5] | BERT | English Wikipedia and Books Corpus [58] | WordPiece | 30,000 | SentencePiece [57] |
| Liu et al., [6] | RoBERTa | Books Corpus [58], English Wikipedia, CC-news, Open webtext | Byte-Pair Encoding (BPE) | 50,000 | - |
| Conneau and Lample [59] | Cross-lingual XLMs | Wikipedia, EUbookshop corpus, OpenSubtitles, GlobalVoices [60] | BPE | 95,000 | Kytea4 and PyThaiNLP5 |
| Liu et al., [61] | mBART | CCNet Datasets [62] | bi-texts | 250,000 | SentencePiece |
| Wang et al., [63] | StuctBERT | English Wikipedia and Books Corpus | WordPiece | 30,000 | WordPiece |
| Joshi et al., [64] | SpanBERT | English Wikipedia and Books Corpus | WordPiece | 30,000 | - |
| Category | Model | Dataset | Focus | Evaluation Metrics |
|---|---|---|---|---|
| General | ||||
| RoBERTa [6] | Books Corpus [58], English Wikipedia, Open webtext, and Stories | Pretrain a model on a larger dataset with bigger batch sizes for optimal performance. | GLUE [84], RACE, and SQuAD | |
| T2T Transformer [11] | Colossal Clean Crawled Corpus (C4) [11] | Developed a common framework to convert a variety of text-based language problems into a text-to-text format | GLUE and SQuAD | |
| Social media | ||||
| HateBERT [85] | RAL-E | Developed to analyze offensive language singularities in English | Macro F1 Class—F1 | |
| SentiX [86] | Amazon review [87] and Yelp 2020 dataset | Analysis of consumer sentiments from different domains | Accuracy | |
| Domain Specific | ||||
| Biomedical | BioBERT [33] | BooksCorpus PMC articles and PubMedAbstracts | Question and answering model for the biomedical field | F1 score, MRR |
| BLUE [73] | BC5CDR, MedSTS, and BIOSSES [73] | Developed the BLUE evaluation framework to access the performance of biomedical pretrained models | Pearson, Accuracy, and micro F1 | |
| ClinicalBERT [34] | MIMIC-III v1.4 database [88] | Demonstrate that clinical-specific contextual embeddings improve domain results | Accuracy, Exact F1 | |
| News and academia | DAPT [74] | Amazon review [87] and RealNews [89] | Developed an efficient model to analyze small corpus with improved performance | F1-Score |
| Language based | ||||
| Monolingual | IndoNLG [76] | Indo4B [76] | Developed the IndoNLU model for complex sentence classification | F1-Score |
| DATM [90] | GermEval 2017 data [90] | Developed a transformer-based model to explore model efficiency on German customers | F1-Score | |
| PTT5 [91] | BrWac [92] and ASSIN 2 [93] | Improved the T5 model to translate the Portuguese language to Brazilian Portuguese | Precision, Pearson, Recall, and F1 | |
| RoBERTa-tiny-clue [94] | CLUECorpus2020 [94] | Developed the Chinese CLUECorpus2020 to pretrain Chinese language models | Accuracy | |
| Chinese-Transformer-XL [95] | WuDaoCorpora [95] | Developed a 3 TB Chinese Corpora for word embedding model pre-training | Per-word perplexity (ppl) | |
| Multi-lingual | IndoNLG [76] | Indo4B-Plus | Introduced the IndoNLG model to translate multiple languages (Indonesian, Sundanese, and Javanese) | BLEU, ROUGE, and F1 score |
| MuRIL [77] | OSCAR [75] and Wikipedia | Introduced the MuRIL multilingual LM for Indian languages translation | Accuracy | |
| IndicNLPSuite [78] | IndicGLUE benchmark | Developed a large-scale, dataset for Indian language translation | Accuracy | |
| mT5 [79] | mC4 derived from Common Crawl corpus [75] | Introduced the mT5 multilingual variant of the T5 model pretrained on the Common Crawl dataset, which covers 101 languages | Accuracy and F1 score | |
| mT6 [80] | CCNet [62] | The proposed MT6 is an improved version of MT5 for corruption analysis | Accuracy and F1 score | |
| XLM-R [81] | CommonCrawl Corpus [75] | Developed a multilingual model for a wide range of cross- lingual transfer tasks | Accuracy and F1 score | |
| XLM-E [82] | CommonCrawl Corpus [75] | Developed two techniques for token recognition and replacement for cross-lingual pre-training | Accuracy and F1 score | |
| INFOXLM [83] | CommonCrawl Corpus [75] | Proposed an info-theoretic model for cross-lingual language modelling to maximize the mutual information between multi-granularity texts | Accuracy | |
| Method | Model | Focus | Pros | Limitations | Model Evaluation |
|---|---|---|---|---|---|
| Pretraining from scratch | BERT [5] | Designed to pretrain deep bidirectional representations from unlabeled text. | It is a straightforward model to generate cutting-edge models for a variety of tasks, including QA and language inference, with minimal architectural adjustments. | The BERT model was severely undertrained and may match or outperform some models published after it. | GLUE score = 80.5%, accuracy 86.7, F1 score = 93.2 |
| RoBERTa [6] | Improvements to the original BERT architectural design combined with alternatives and training methods that improve downstream task performance. | The architectural and training advancements demonstrate a competitive advantage of masked language model pretraining, with all other state-of-the-art models. | Model is computationally expensive since the training dataset is large (160 GB data). | SQuAD = 94.6/89.4, MNLI-m = 90.2, SST-2 = 96.4, QNLI = 98.9% | |
| ELECTRA [9] | Introduces discriminative and generator models for prediction. | Outstanding performance on downstream tasks with less computing power. | Requires high computer power for training | MNLI = 90.7, CoLA = 68.1 | |
| Incessant pretraining | ALeaseBERT [27] | Introduced a new benchmark dataset, trained on the ALeaseBERT language model, and generated ground-breaking outcomes. | The suggested model detects two elements (entities and red flags), crucial in a contract review with excellent performance. | The precision at high recall for the red flag detection requires improvement for end-user and professional satisfaction. | MAP = 0.5733, Precision = 0.62, Recall = 0.48, F1 = 0.54 |
| BioBERT [33] | Introduced model for pre-trained language representation for biomedical text mining. | The first domain-specific BERT-based model pretrained on biomedical corpora with improved performance. | It is expensive to generate domain-specific corpora because of specific vocabulary not found in general corpora. | NER = (0.62% F1 score = 2.80%, MRR = 12.24% | |
| TOD-BERT [29] | Introduced a task–conversation model, trained on nine human and multi-turn task-oriented datasets, spanning more than 60 domains. | Four tasks involving dialogue that TOD-BERT performs better than BERT are answer selection, dialogue act prediction, dialogue state tracking, and intention categorization. | Implementation can be computationally expensive. | MWOZ = 65.8% 1-to-100 accuracy and 87.0% 3-to-100 accuracy | |
| infoXLM [83] | Presents a framework that defines a cross-linguistic language model to maximize multilingual and multi-granularity texts. | A cross-lingual comparative learning task and a single cross-lingual pretraining are successful with the model from an information-theoretic perspective | Due to specialized vocabulary that is absent from broad corpora, creating domain-specific corpora is costly. | XNLI = 76.45, MLQA = 67.87/49.58 | |
| Multi-task pretraining | MT-DNN [97] | To integrate multi-task learning with language model pretraining for language representation learning. | MT-DNN has remarkable generalization capabilities, archiving outstanding results on 10 NLU tasks using three well-known benchmarks: GLUE, SNLI, and SciTail. | The model requires improvement to include the linguistic structure of the text more clearly and understandably. | MNLI = 87.1/86.7, CoLa = 63.5, Accuracy = 91.6% |
| MT-BioNER [98] | Present a slot tagging neural architecture based on a multi-task transformer network for the biomedical field. | The suggested strategy outperforms the most recent cutting-edge techniques for slot tagging on several benchmark biomedical datasets. | Investigate the effects of dataset overlap on the model’s performance on larger unlabeled datasets | Recall = 90.52, Precision = 88.46, F1 = 89.5 | |
| MT-Clinical BERT [99] | Developed the Multitask-Clinical BERT, which uses shared representations to carry out eight clinical tasks. | The suggested approach is resilient enough to incorporate new activities while concurrently supporting future information extraction. | Adding larger tasks may need rigorous ablation tests to determine the overall benefits of each such work. | Micro-F1 = 84.1 (+0.2) | |
| Multi-task learning [100] | Developed a multi-task learning model with decoders for a variety of biological and clinical NLP tasks. | The MT-BERT-Fine-Tuned model proposed eight tasks from various text genres that displayed outstanding performance. | Further investigation is required on task relationship characterization on data qualities. | Accuracy = 83.6% | |
| Knowledge inheritance pretraining | KIPM [70] | Present the KI pretraining architecture to effectively learn bigger pretrained language models. | The proposed architecture uses already trained larger models to teach smaller ones by transferring information across several language models. | Selecting an appropriate teacher model for KI can be difficult sometimes, limiting model performance. | F1 = 84.5% |
| CPM-2 [71] | A cost-effective pipeline for large-scale pre-trained language models based on KI. | The framework is memory-efficient for quick tuning, achieving outstanding performance on full-model tuning. | The model needs further optimization. | Accuracy = 91.6% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kotei, E.; Thirunavukarasu, R. A Systematic Review of Transformer-Based Pre-Trained Language Models through Self-Supervised Learning. Information 2023, 14, 187. https://doi.org/10.3390/info14030187
Kotei E, Thirunavukarasu R. A Systematic Review of Transformer-Based Pre-Trained Language Models through Self-Supervised Learning. Information. 2023; 14(3):187. https://doi.org/10.3390/info14030187
Chicago/Turabian StyleKotei, Evans, and Ramkumar Thirunavukarasu. 2023. "A Systematic Review of Transformer-Based Pre-Trained Language Models through Self-Supervised Learning" Information 14, no. 3: 187. https://doi.org/10.3390/info14030187