2.1. Reliable Multicast in IP and ICN
Reliable multicast (RM) means that all multicast data is eventually delivered correctly to each receiver. The common reliability assurance technology is ARQ, FEC, HARQ, network coding, etc. Retransmission is key for the ARQ-based recovery scheme to achieve RM. In this paper, we focus on a retransmission-based RM scheme, which provides a simple and robust solution to ensure that each multicast member receives all multicast packets [
9]. Retransmission ways are usually based on a unicast [
19], multicast [
20], and unicast-multicast hybrid [
21].
The feedback implosion problem easily occurs when there are many receivers and poor link quality, which limits the scalability of reliable multicast protocols. There are three main approaches to solve the problem. First, tree-based feedback [
22,
23,
24,
25] forms a tree-based hierarchical structure for sources and receivers, which can prevent receivers from directly contacting the source to maintain the scalability of large receiver sets. RMTP is a representative work in this type of approach, which is a receiver-driven reliable transmission scheme for non-real-time multicast content delivery [
24]. In order to avoid the acknowledgment (ACK) explosion, a group of receivers called designated receivers (DRs) aggregate the ACK status in the local area network and forward it upstream to a higher-level DR or source. When the number of receivers with packet losses exceeds a certain threshold, retransmission is in the form of multicast. Second, router-assisted feedback [
26,
27] uses special routers to aggregate NACK messages. For instance, Cisco has proposed a classic RM solution called Pragmatic General Multicast (PGM) [
26], in which a hierarchy of routers supporting PGM (called network elements (NEs)) is deployed throughout the multicast tree to aggregate feedback from receivers to source. Receivers wait for a time randomly chosen from an interval before unicasting a NACK message to the nearest upstream router, which in turn responds with multicast NACK confirmation (NCF). The process is repeated in a hop-by-hop manner until the source receives the NACK in a reliable manner, and the random delay along with suppression is intended to prevent implosion [
26]. However, in practical application, too much traffic is incurred due to multicast NCFs. Third, feedback suppression [
20,
28]. The receivers wait a random time before multicasting retransmission requests to the entire group. If a receiver receives the same retransmission request from the others, it will refuse to send this request.
Bit-Indexed Explicit Replication (BIER) [
29] is a new multicast protocol that removes the need for flow-state in intermediate routers, with each destination explicitly indicated by the source. Intermediate routers replicate and forward packets over the interfaces providing shortest paths (according to unicast routes) to the specified destinations. The authors proposed BIER-based reliable multicast [
30] to efficiently retransmit missing packets to the requesting destinations. Source collects NACKs for a certain lost packet for a small amount of time and records the destinations requesting retransmission. When that time expired, source uses BIER to send the retransmission to exactly the set of destinations that have sent the NACK. However, it relies on source to retransmit the recovery packets. To solve this problem, the reliable BIER mechanism was extended to support recovery from peers in [
31]. Rather than being directly sent to the source, NACKs can be first transmitted through an ordered set of peers, each of which may provide retransmission if they have a cached copy of the lost packet.
Several packet loss recovery solutions (e.g., [
32,
33]) combined multicast technologies with other enabling technologies to enhance their reliability. For instance, Zhang et al. [
32] presented an OpenFlow enabled elastic loss recovery solution, called ECast, which acquires packet loss state according to tree-based NACK feedback and calculates packet retransmission method based on elastic area multicast (EAM). It can reduce the recovery redundancy because it does not use irrelevant communication links and does not produce duplicate recovery packets. Mahajan et al. [
33] designed and implemented a platform called ATHENA to implement multicast in SDN-based data centers, providing high reliability and congestion control mechanisms to ensure fairness.
Furthermore, several reliable multicast schemes have been proposed for ICN. In [
34], proposed is a retransmission-based Reliable Multicast Transport for the Publish/Subscribe Internet (PSI) architecture (RMTPSI) by map** the ideas of PGM to PSI architecture. It uses selected routers on the multicast tree (as opposed to DR in RMTP) to aggregate feedback and control the propagation of retransmissions. However, the recovery phase and the original content distribution phase are performed separately, and the former must be executed after completion of the latter, resulting in an increase in content distribution completion time. A lightweight enhancement to Content-Oriented Publish/Subscribe System (R-COPSS) was proposed for flow and congestion control as well as for reliability [
35]. It adjusts sending rate to accommodate the ACKer that is selected according to the loss rate and throughput periodically fed back by all the subscribers. The slower subscribers obtain the lost packets via local repair. Moreover, [
36] proposed a Network Coding-based Real-time Data Retransmission (NC-RDR) algorithm for ICN multicast to dynamically combine the missing packets by using random linear coding.
In addition, with regard to the unreliability of data transmission or service caused by network failures, some strategies related to the redundancy of network components (e.g., virtual machines, router, etc.) [
37,
38,
39] have been proposed to protect network components from network failures.
2.2. Cache Strategy in Reliable Multicast
Several cache strategies have been proposed in IP reliable multicast. Active reliable multicast (ARM) is a new loss recovery scheme for large-scale reliable multicast, which emphasizes the active role of the router [
40]. The active routers follow configuring hierarchical multicast tree, and support caching, NACK consolidation, and scoped retransmission. However, ARM did not consider cache utilization efficiency and had difficulty caching the packets efficiently with limited cache size. In [
41], the authors studied and compared the combinations of three cache policies, namely, the timer-based, simple FIFO (S-FIFO), and probabilistic FIFO (P-FIFO); and three cache allocation schemes, equal sharing, least requirement first (LRF), and proportional allocation, and found that P-FIFO with proportional cache allocation performs the best in most cases. ** any of the incoming packets. But it increased the complexity of router operation.
ICN enables rapid data retrieval due to its native in-network caching mechanism, thus shares properties with cache-based reliable multicast protocols, by enabling data recovery from nearby routers [
31]. In [
44], the authors found that using ICN in-network packet-level cache for retransmission can reduce the expected retransmission latency and is a valuable error control method. However, they did not study the impact of different cache strategies on error recovery in unicast or multicast scenarios.
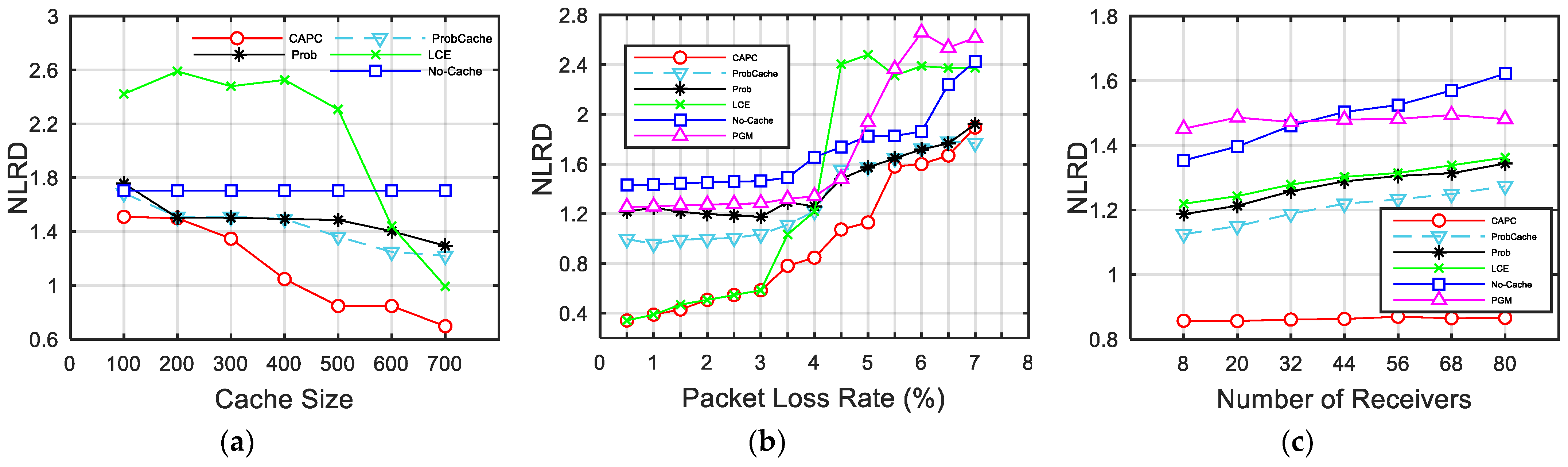
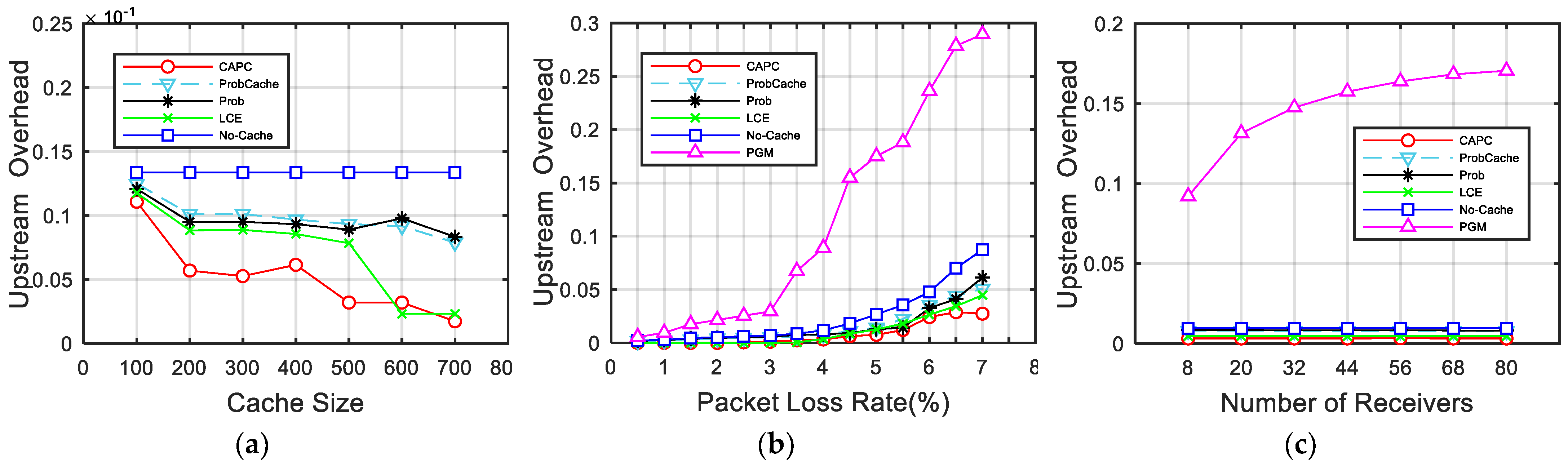
Finally, as shown in
Table 1, we present a summary of the reliable multicast approaches in the literature.















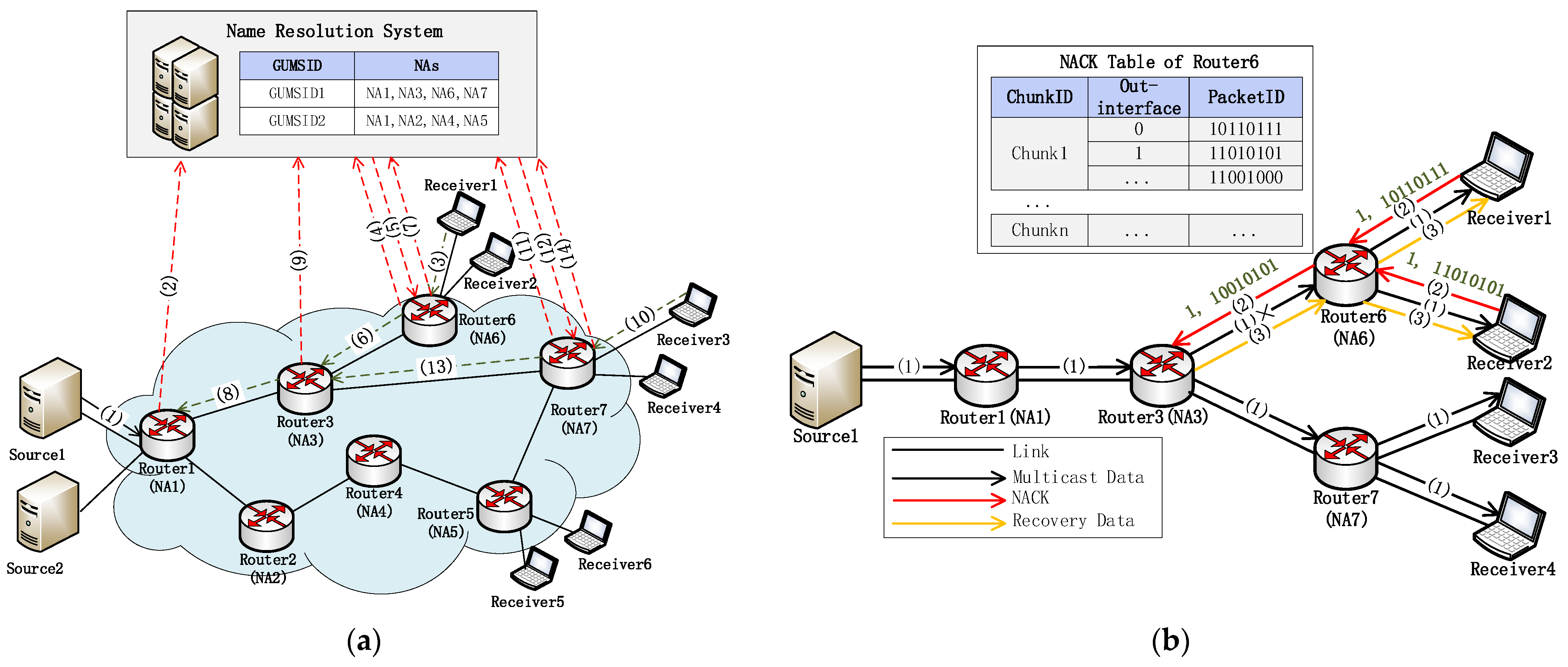{kind=link}
{kind=link}
{kind=link}
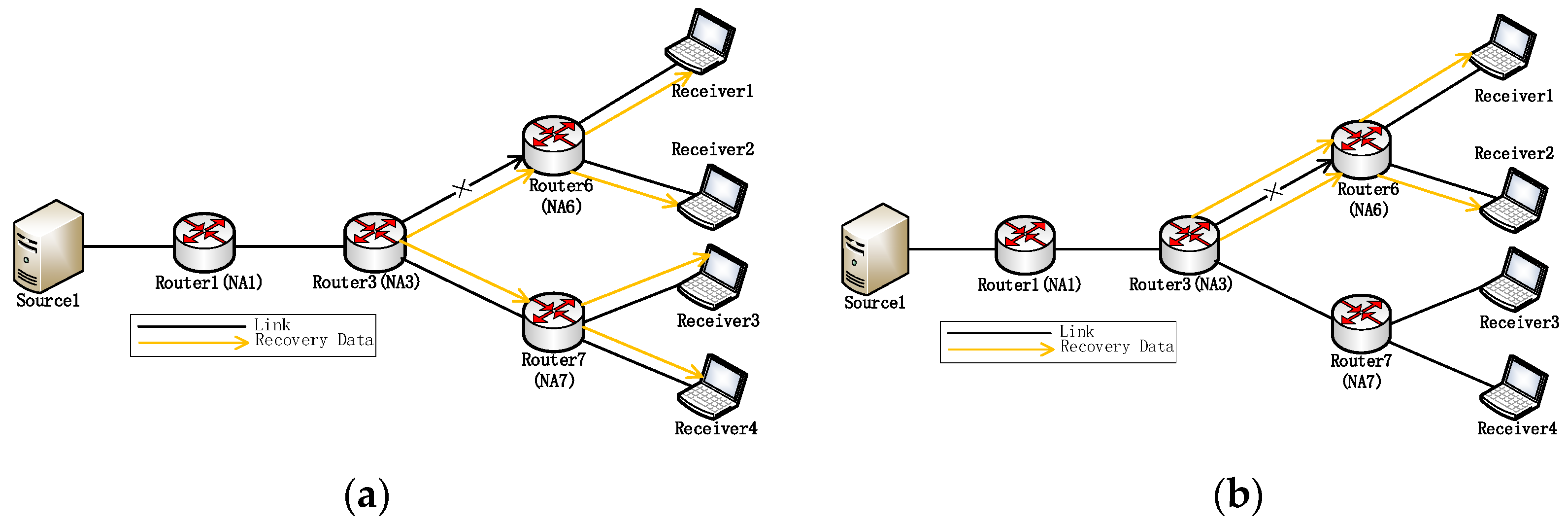{kind=link}
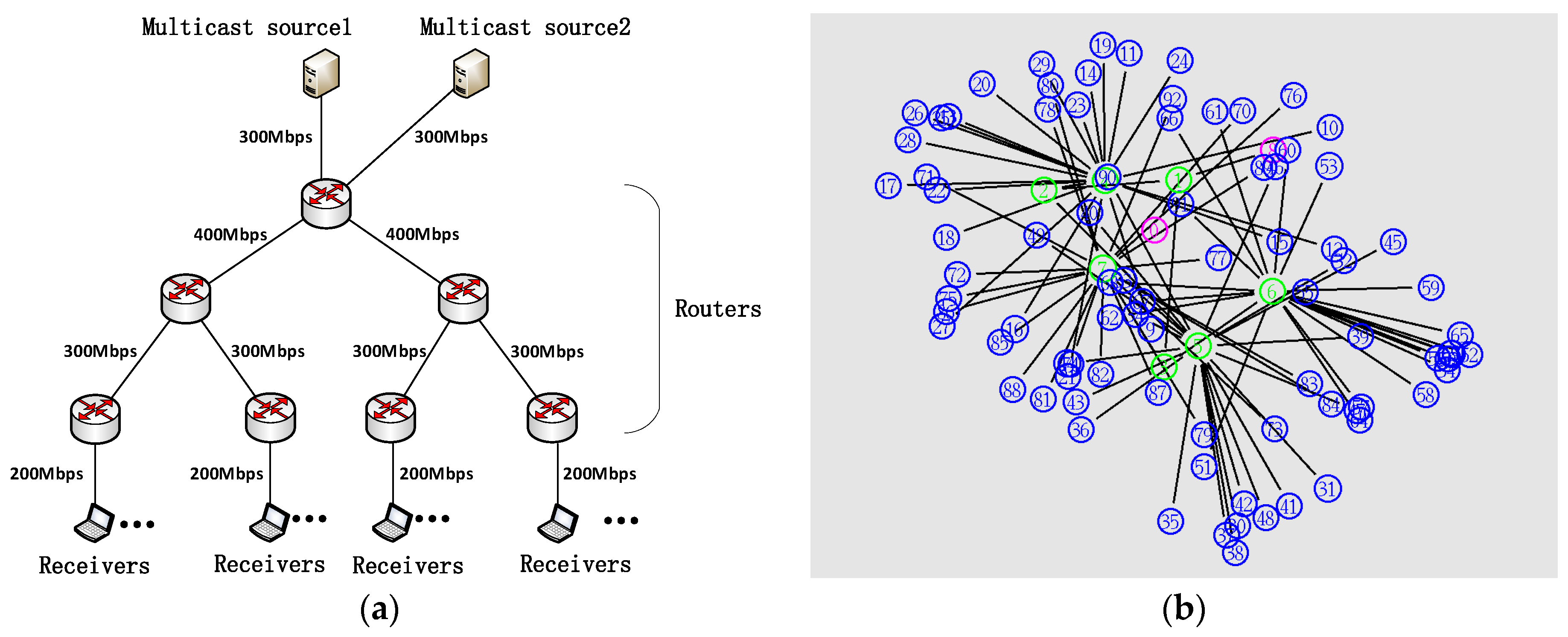{kind=link}
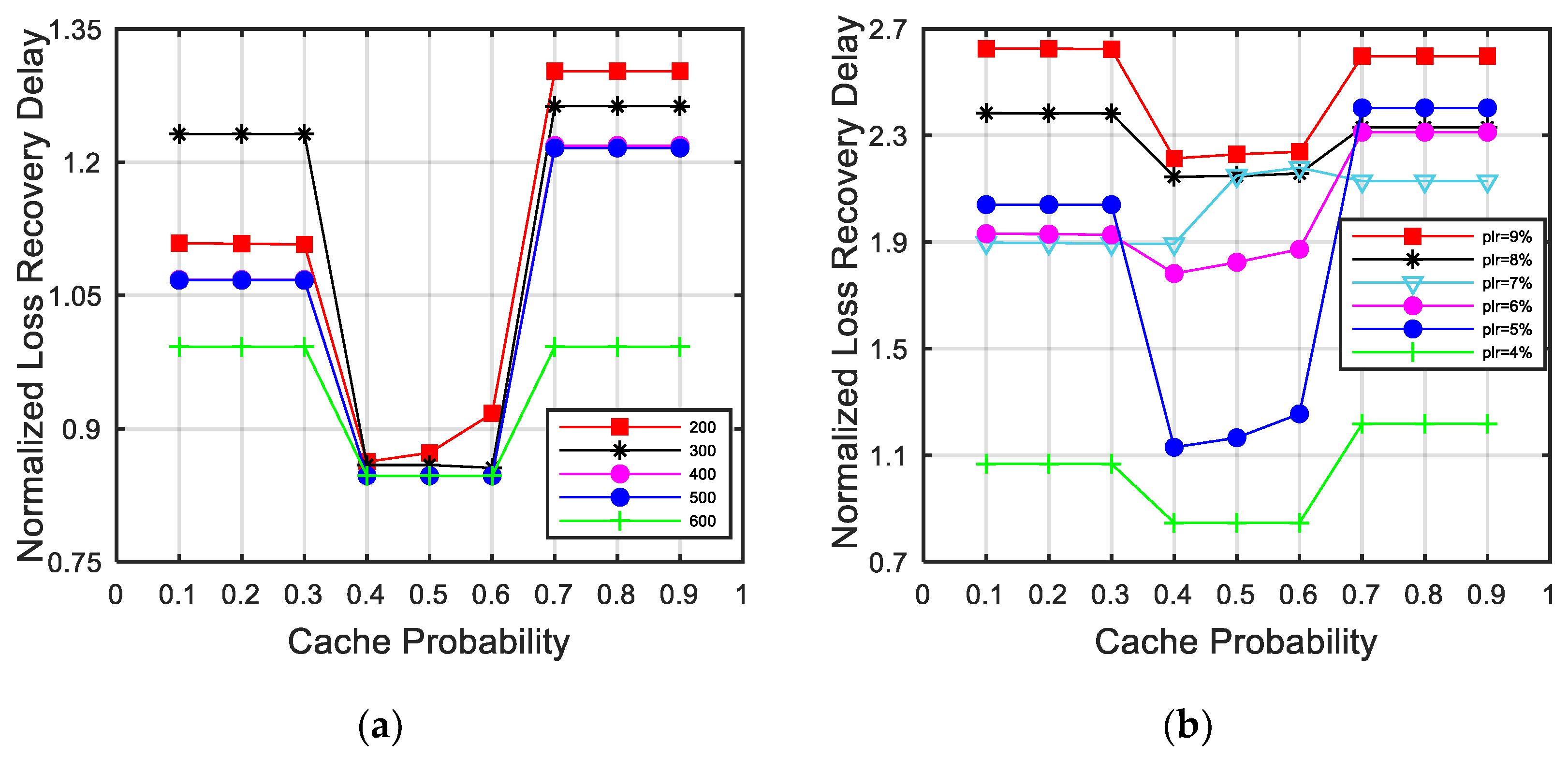{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}