Visual Analytics for Dimension Reduction and Cluster Analysis of High Dimensional Electronic Health Records



Abstract
:1. Introduction
2. Background
2.1. Visual Analytics
2.2. Dimension Reduction (DR)
2.3. Cluster Analysis
2.4. Healthcare Stakeholders
3. Related Work
3.1. DR-Based Visual Analytics Systems
3.2. CA-Based Visual Analytics Systems
3.3. DR and CA-Based Visual Analytics Systems
3.4. EHR-Based Visual Analytics Systems
4. Methods
4.1. Design Process and Participants
4.2. Task Analysis and Design Criteria
4.2.1. Displaying an Overview of the Data
4.2.2. Allowing Iteration over DR Techniques
4.2.3. Allowing Iteration over CA Techniques
4.2.4. Facilitating Reasoning about DR and CA
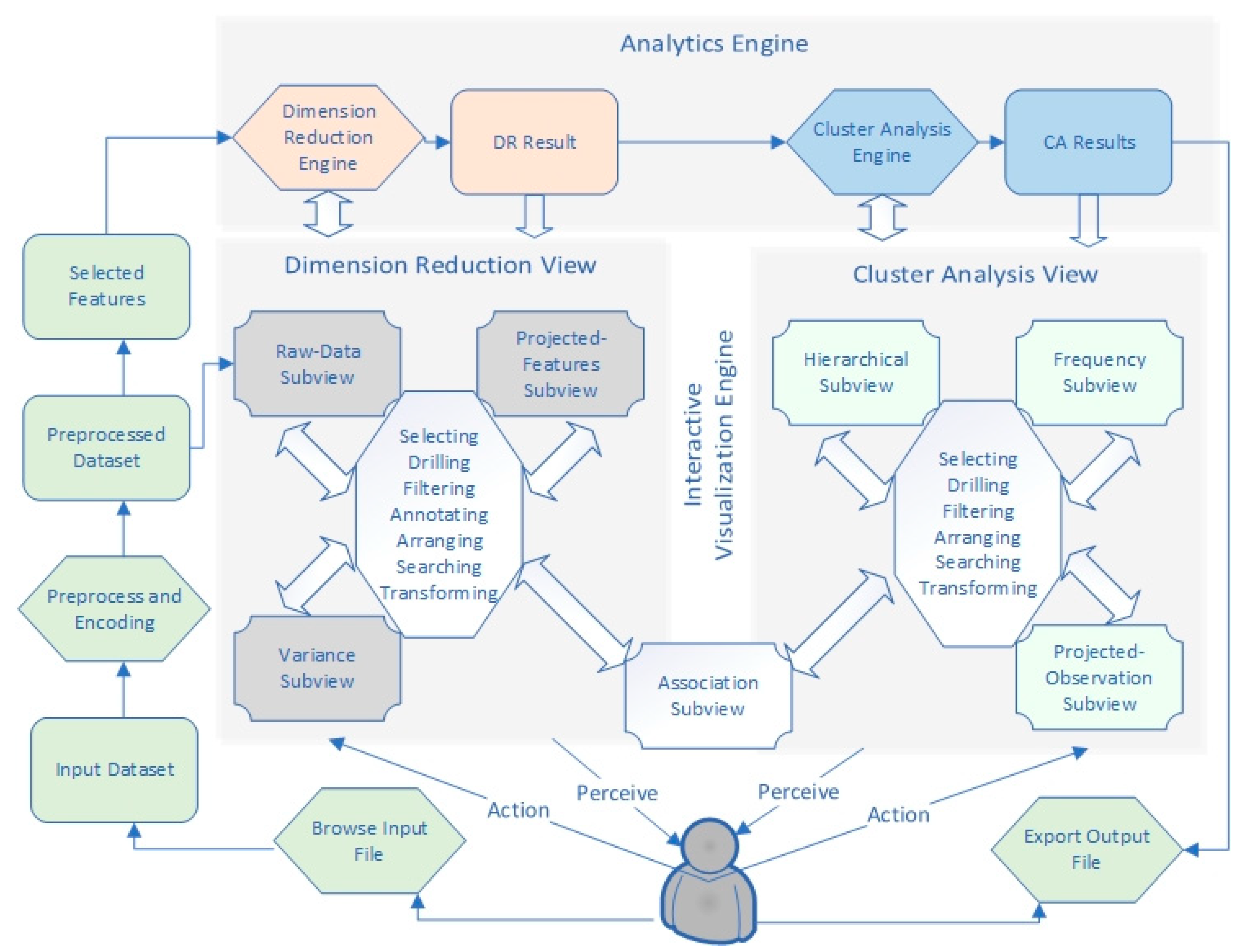
4.3. Workflow
4.4. Encoding and Preprocessing
4.5. Analytics Engine
4.5.1. DR Engine
4.5.2. CA Engine
4.6. Interactive Visualization Engine
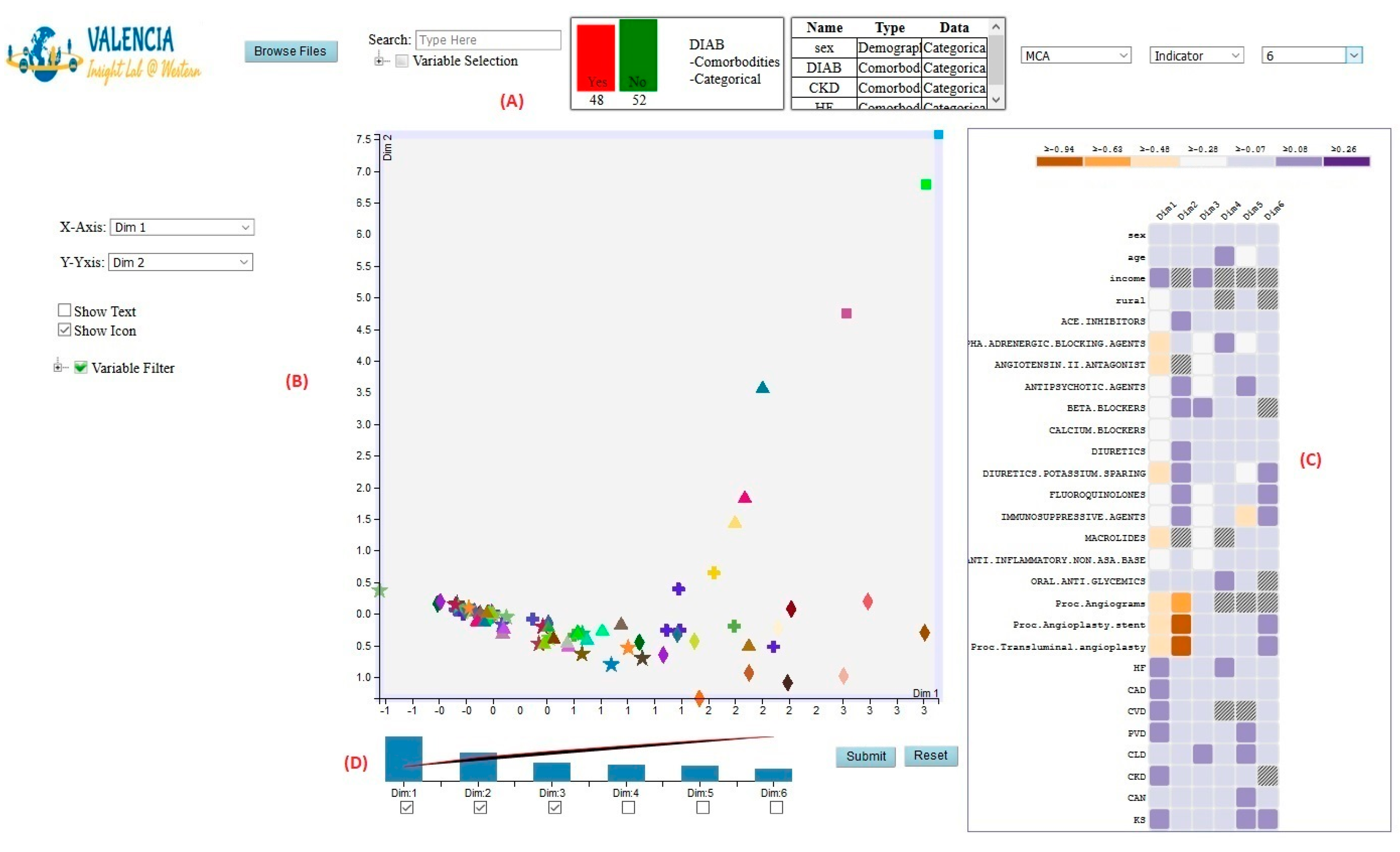
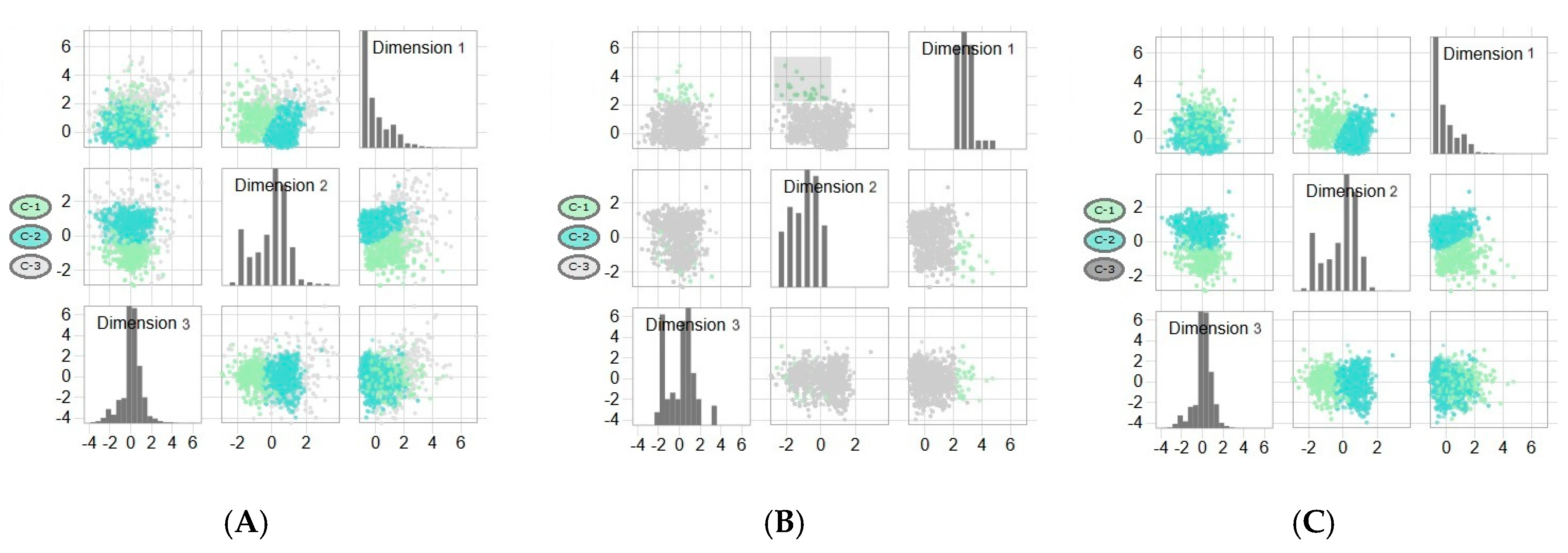
4.6.1. DR View
Raw-Data Subview
Projected-Features Subview
Association Subview
Variance Subview
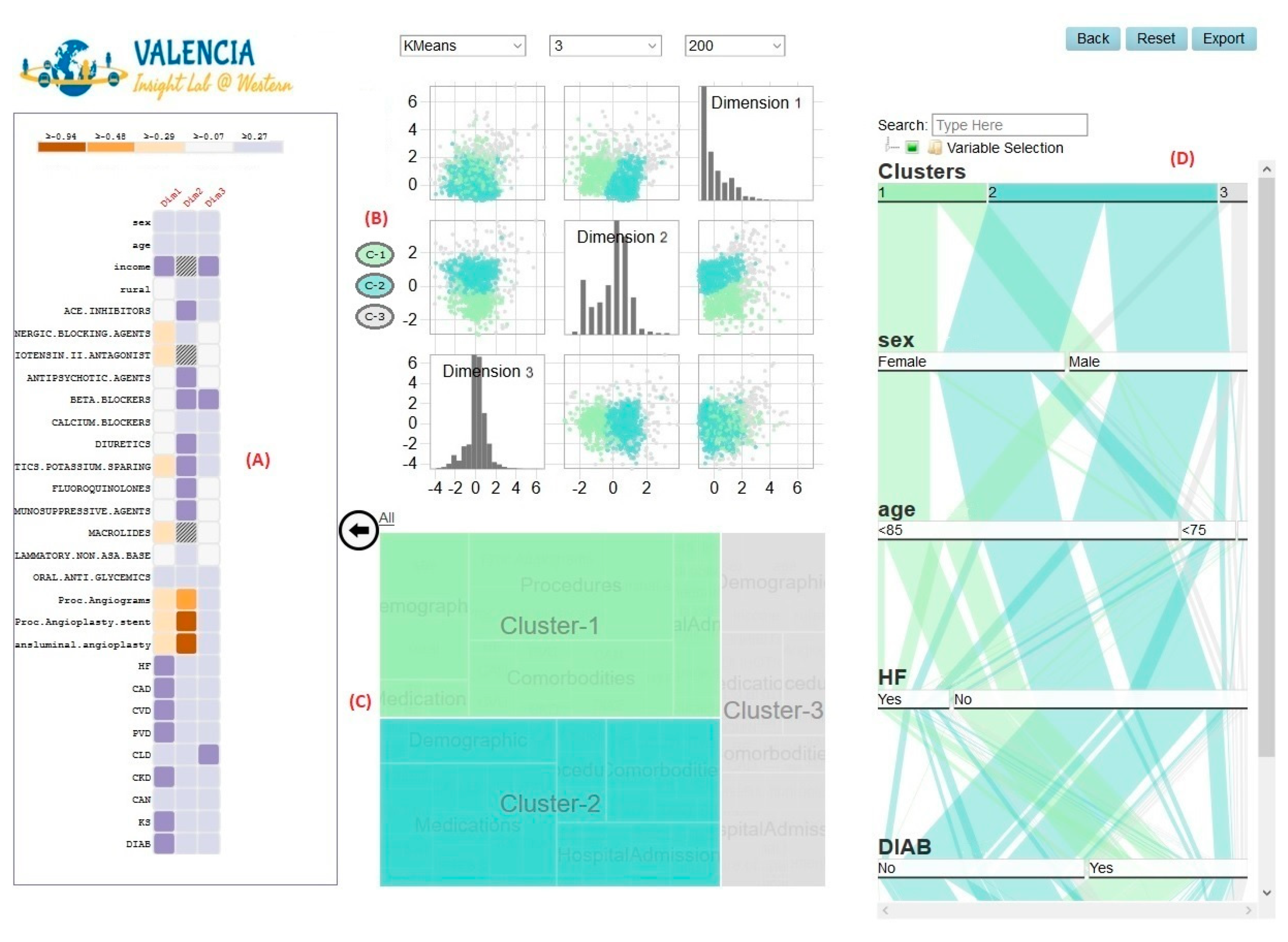
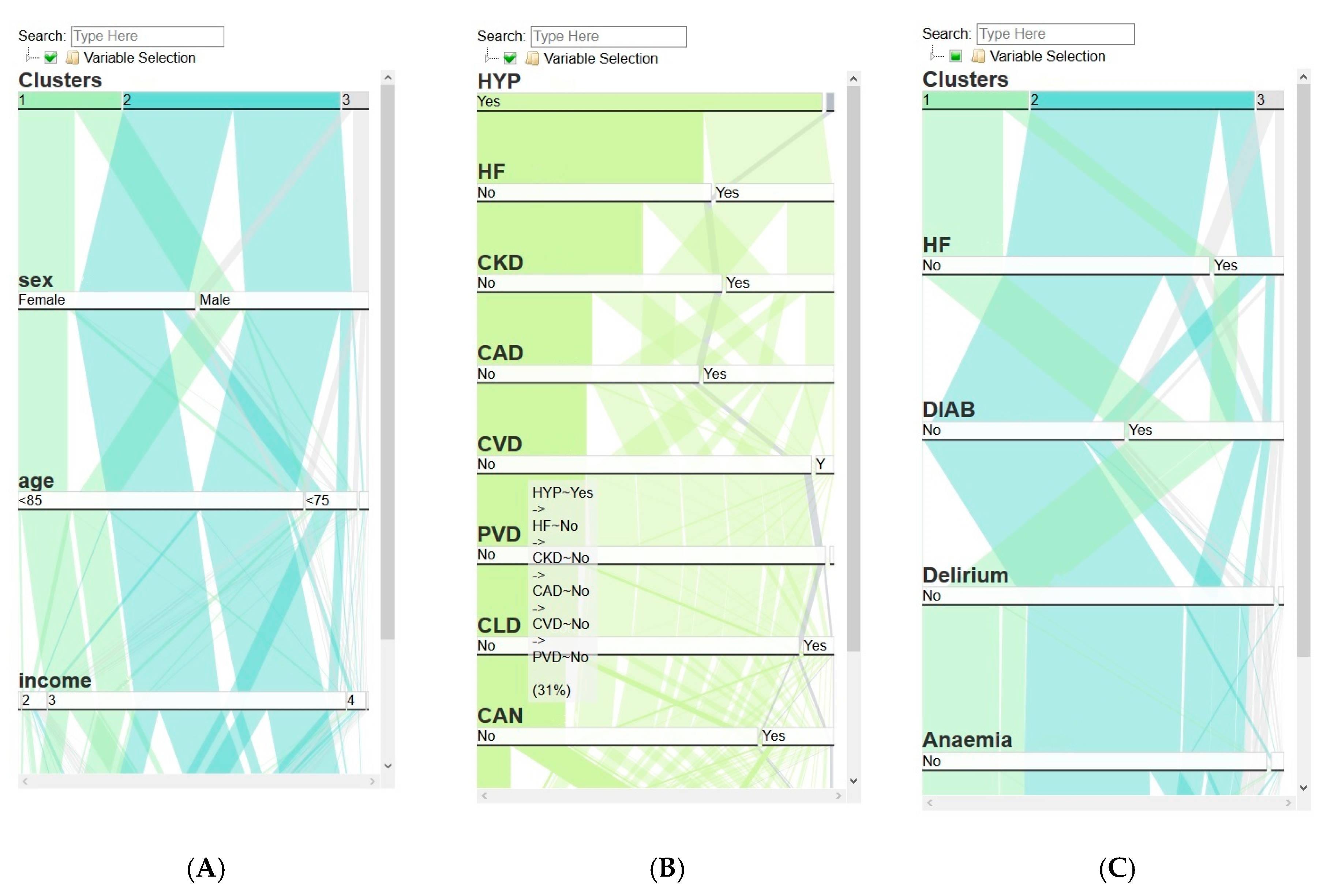
4.6.2. CA View
Hierarchical Subview
Frequency Subview
Projected-Observations Subview
4.7. Implementation Details
5. Usage Scenario
5.1. Data Sources
5.2. Cohort Creation
5.3. Cohort Description
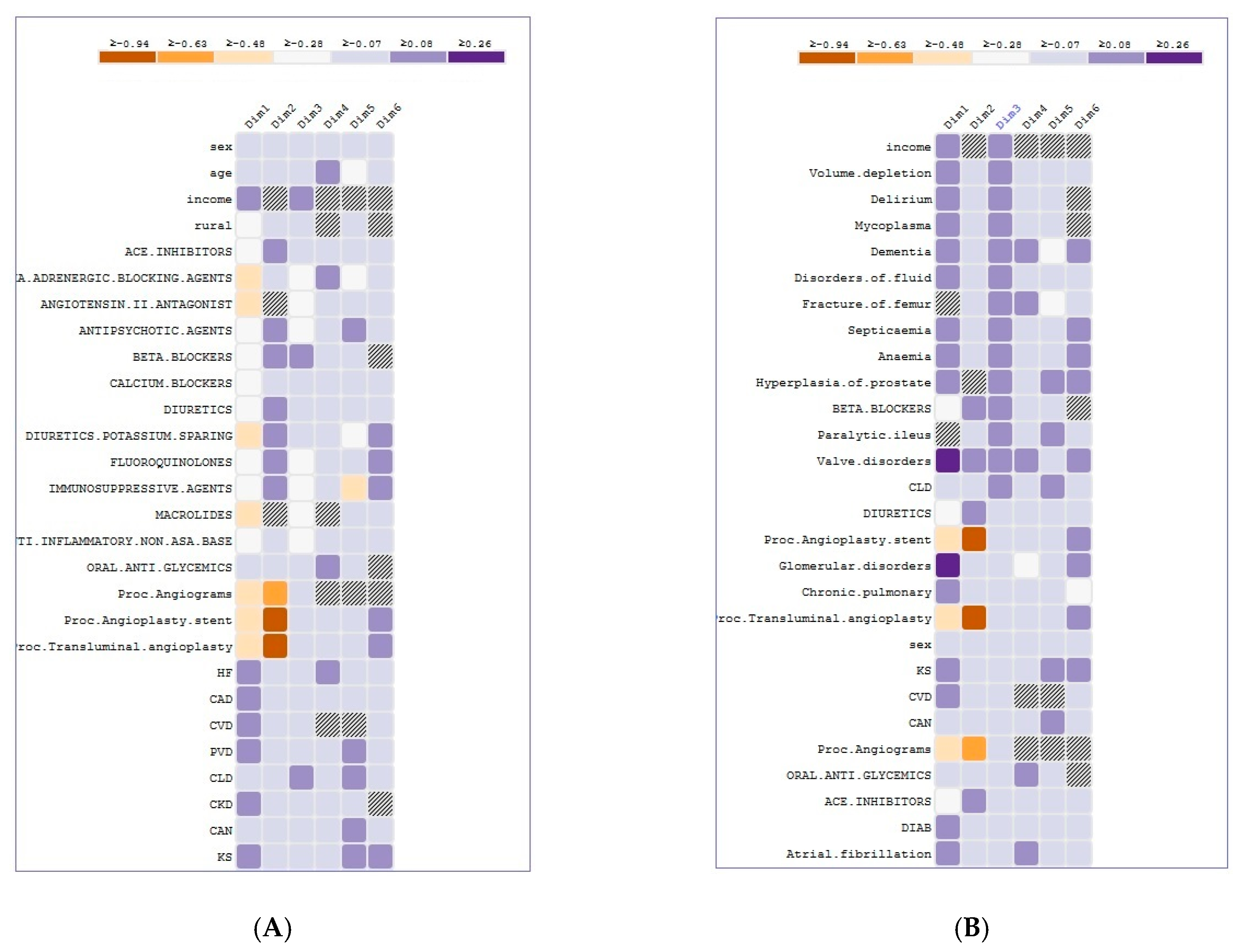
5.4. Case Study
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Caban, J.J.; Gotz, D. Visual analytics in healthcare-opportunities and research challenges. J. Am. Med. Inform. Assoc. 2015, 22, 260–262. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Murdoch, T.B.; Detsky, A.S. The inevitable application of big data to health care. Jama J. Am. Med. Assoc. 2013, 309, 1351–1352. [Google Scholar] [CrossRef] [PubMed]
- Cowie, M.R.; Blomster, J.I.; Curtis, L.H.; Duclaux, S.; Ford, I.; Fritz, F.; Goldman, S.; Janmohamed, S.; Kreuzer, J.; Leenay, M.; et al. Electronic health records to facilitate clinical research. Clin. Res. Cardiol. 2017, 106, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kamal, N. Big Data and Visual Analytics in Health and Medicine: From Pipe Dream to Reality. J. Health Med. Inform. 2014, 5. [Google Scholar] [CrossRef]
- Rind, A.; Wagner, M.; Aigner, W. Towards a Structural Framework for Explicit Domain Knowledge in Visual Analytics. In Proceedings of the 2019 IEEE Workshop on Visual Analytics in Healthcare (VAHC), Vancouver, BC, Canada, 20–20 October 2019; pp. 33–40. [Google Scholar] [CrossRef] [Green Version]
- Marlin, B.M.; Kale, D.C.; Khemani, R.G.; Wetzel, R.C. Unsupervised pattern discovery in electronic health care data using probabilistic clustering models. In Proceedings of the 2nd ACM SIGHIT Symposium on International Health Informatics—IHI ’12, Miami, FL, USA, 28–30 January 2012; ACM Press: Miami, FL, USA, 2012; p. 389. [Google Scholar]
- Wetzel, R.C. The virtual pediatric intensive care unit: Practice in the new millennium. Pediatric Clin. 2001, 48, 795–814. [Google Scholar]
- Haraty, R.A.; Dimishkieh, M.; Masud, M. An Enhanced k-Means Clustering Algorithm for Pattern Discovery in Healthcare Data. Int. J. Distrib. Sens. Netw. 2015, 11, 615740. [Google Scholar] [CrossRef]
- Khalid, S.; Judge, A.; Pinedo-Villanueva, R. An Unsupervised Learning Model for Pattern Recognition in Routinely Collected Healthcare Data. In Proceedings of the 11th International Joint Conference on Biomedical Engineering Systems and Technologies, Funchal, Portugal, 19–21 January 2018; SCITEPRESS—Science and Technology Publications: Funchal, Portugal, 2018; pp. 266–273. [Google Scholar]
- Liao, M.; Li, Y.; Kianifard, F.; Obi, E.; Arcona, S. Cluster analysis and its application to healthcare claims data: A study of end-stage renal disease patients who initiated hemodialysis. BMC Nephrol. 2016, 17, 25. [Google Scholar] [CrossRef] [Green Version]
- Foguet-Boreu, Q.; Violán, C.; Rodriguez-Blanco, T.; Roso-Llorach, A.; Pons-Vigués, M.; Pujol-Ribera, E.; Cossio Gil, Y.; Valderas, J.M. Multimorbidity Patterns in Elderly Primary Health Care Patients in a South Mediterranean European Region: A Cluster Analysis. PLoS ONE 2015, 10, 0141155. [Google Scholar] [CrossRef] [Green Version]
- Estiri, H.; Klann, J.G.; Murphy, S.N. A clustering approach for detecting implausible observation values in electronic health records data. BMC Med. Inform. Decis. Mak. 2019, 19, 142. [Google Scholar] [CrossRef] [Green Version]
- Dilts, D.; Khamalah, J.; Plotkin, A. Using cluster analysis for medical resource decision making. Med. Decis. Mak. 1995, 15, 333–346. [Google Scholar] [CrossRef]
- McLachlan, G.J. Cluster analysis and related techniques in medical research. Stat. Methods Med. Res. 1992, 1, 27–48. [Google Scholar] [CrossRef] [PubMed]
- Doust, D.; Walsh, Z. Data Mining Clustering: A Healthcare Application. In Proceedings of the Mediterranean Conference on Information Systems (MCIS), Limassol, Cyprus, 3–5 September 2011. [Google Scholar]
- Ruan, T.; Lei, L.; Zhou, Y.; Zhai, J.; Zhang, L.; He, P.; Gao, J. Representation learning for clinical time series prediction tasks in electronic health records. BMC Med. Inform. Decis. Mak. 2019, 19, 259. [Google Scholar] [CrossRef] [PubMed]
- Adachi, S. Rigid geometry solves “curse of dimensionality” effects in clustering methods: An application to omics data. PLoS ONE 2017, 12. [Google Scholar] [CrossRef] [Green Version]
- Ronan, T.; Qi, Z.; Naegle, K.M. Avoiding common pitfalls when clustering biological data. Sci. Signal 2016, 9, re6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mitsuhiro, M.; Yadohisa, H. Reduced k-means clustering with MCA in a low-dimensional space. Comput. Stat. 2015, 30, 463–475. [Google Scholar] [CrossRef]
- Siwek, K.; Osowski, S.; Markiewicz, T.; Korytkowski, J. Analysis of medical data using dimensionality reduction techniques. Przegląd Elektrotechniczny 2013, 89, 279–281. [Google Scholar]
- Wilke, C.O. Fundamentals of Data Visualization: A Primer on Making Informative and Compelling Figures, 1st ed.; O’Reilly Media: Sebastopol, CA, USA, 2019; ISBN 978-1-4920-3108-6. [Google Scholar]
- Wenskovitch, J.; Crandell, I.; Ramakrishnan, N.; House, L.; Leman, S.; North, C. Towards a Systematic Combination of Dimension Reduction and Clustering in Visual Analytics. IEEE Trans. Vis. Comput. Graph. 2018, 24, 131–141. [Google Scholar] [CrossRef]
- Sembiring, R.W.; Zain, J.M.; Embong, A. Dimension Reduction of Health Data Clustering. ar** from Large-Scale Electronic Health Records. IEEE Trans. Multimed. 2016, 18, 2257–2270. [Google Scholar] [CrossRef]
- Abdullah, S.S.; Rostamzadeh, N.; Sedig, K.; Garg, A.X.; McArthur, E. Multiple Regression Analysis and Frequent Itemset Mining of Electronic Medical Records: A Visual Analytics Approach Using VISA_M3R3. Data 2020, 5, 33. [Google Scholar] [CrossRef] [Green Version]
- Varga, M.; Varga, C. Visual Analytics: Data, Analytical and Reasoning Provenance. In Building Trust in Information. Springer: Cham, Switzerland, 2016; pp. 141–150. [Google Scholar]
- Leighton, J.P. (Ed.) Defining and Describing Reason. In The Nature of Reasoning; Cambridge University Press: Cambridge, UK, 2004; pp. 3–11. ISBN 0-521-81090-6. [Google Scholar]
- Arabie, P. Cluster analysis in marketing research. Adv. Methods Mark. Res. 1994, 160–189. [Google Scholar]
- De Soete, G.; Carroll, J.D. K-means clustering in a low-dimensional Euclidean space. In New Approaches in Classification and Data Analysis; Springer: Berlin/Heidelberg, Germany, 1994; pp. 212–219. [Google Scholar]
- Vichi, M.; Kiers, H.A. Factorial k-means analysis for two-way data. Comput. Stat. Data Anal. 2001, 37, 49–64. [Google Scholar] [CrossRef]
- Timmerman, M.E.; Ceulemans, E.; Kiers, H.A.; Vichi, M. Factorial and reduced K-means reconsidered. Comput. Stat. Data Anal. 2010, 54, 1858–1871. [Google Scholar] [CrossRef]
- Rocci, R.; Gattone, S.A.; Vichi, M. A new dimension reduction method: Factor discriminant k-means. J. Classif. 2011, 28, 210–226. [Google Scholar] [CrossRef]
- Hirschfeld, H.O. A Connection between Correlation and Contingency. Math. Proc. Camb. Philos. Soc. 1935, 31, 520–524. [Google Scholar] [CrossRef]
- Torgerson, W.S. Theory and Methods of Scaling; Wiley: Oxford, UK, 1958. [Google Scholar]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417–441. [Google Scholar] [CrossRef]
- Pearson, K., LIII. On lines and planes of closest fit to systems of points in space. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef] [Green Version]
- Greenacre, M.; Blasius, J. Multiple Correspondence Analysis and Related Methods; CRC press: Boca Raton, FL, USA, 2006. [Google Scholar]
- Escofier, B.; Pagès, J. Multiple factor analysis (AFMULT package). Comput. Stat. Data Anal. 1994, 18, 121–140. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Shepard, R.N. The analysis of proximities: Multidimensional scaling with an unknown distance function. II. Psychometrika 1962, 27, 219–246. [Google Scholar] [CrossRef]
- Kruskal, J.B. Nonmetric multidimensional scaling: A numerical method. Psychometrika 1964, 29, 115–129. [Google Scholar] [CrossRef]
- Leeuw, J.D. Multivariate Analysis with Optimal Scaling. In Proceedings of the International Conference on Advances in Multivariate Statistical Analysis, Calcutta, India; Indian Statistical Institute: Calcutta, Indian, 1988; pp. 127–160. [Google Scholar]
- Gifi, A. Nonlinear Multivariate Analysis; Wiley: Hoboken, NJ, USA, 1990. [Google Scholar]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A K-Means Clustering Algorithm. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Nielsen, F. Hierarchical Clustering. In Introduction to HPC with MPI for Data Science; Nielsen, F., Ed.; Undergraduate Topics in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; pp. 195–211. ISBN 978-3-31-921903-5. [Google Scholar]
- Rokach, L.; Maimon, O. Clustering Methods. In Data Mining and Knowledge Discovery Handbook; Maimon, O., Rokach, L., Eds.; Springer: Boston, MA, USA, 2005; pp. 321–352. ISBN 978-0-38-725465-4. [Google Scholar]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. Kdd 1996, 96, 226–231. [Google Scholar]
- Fraley, C.; Raftery, A.E. Model-Based Clustering, Discriminant Analysis, and Density Estimation. J. Am. Stat. Assoc. 2002, 97, 611–631. [Google Scholar] [CrossRef]
- Feldman, R.; Sanger, J. The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data; Cambridge University Press: Cambridge, UK, 2007; ISBN 978-0-52-183657-9. [Google Scholar]
- Kosara, R. Turning a table into a tree: Growing parallel sets into a purposeful project. In Beautiful Visualization: Looking at Data through the Eyes of Experts; Steele, J., Iliinsky, N., Eds.; O’Reilly: Sebastopol, CA, USA, 2010; pp. 193–204. [Google Scholar]
- Levy, A.R.; O’Brien, B.J.; Sellors, C.; Grootendorst, P.; Willison, D. Coding accuracy of administrative drug claims in the Ontario Drug Benefit database. Can. J. Clin. Pharmacol. 2003, 10, 67–71. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Require: Raw dataset with cluster labels | (1) | |
| compute the number of features in each group in number_of_groupfeatures [] | (2) | |
| compute max_groupfeatures = maximum value in number_of_groupfeatures [] | (3) | |
| compute frequency of each feature in the dataset | (4) | |
| divide the dataset based on each cluster | (5) | |
| for each cluster C in the dataset | (6) | |
| for each feature F in the dataset | (7) | |
| compute relative frequencies of feature F in cluster C | (8) | |
| feature_weight = (relative frequencies/frequency [F]) × 100 | (9) | |
| adjusted_feature_weight [C,F] = (max_groupfeatures/number_of_groupfeatures [F]) × feature_weight | (10) | |
| return adjusted_feature_weight [][] | (11) | |
| Group | Shape |
|---|---|
| Demographics | + (Plus) |
| Comorbidities | ★ (Star) |
| Hospital admission codes | ▲ (Triangle) |
| Procedures | ■ (Rectangle) |
| Medications | ♦ (Diamond) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdullah, S.S.; Rostamzadeh, N.; Sedig, K.; Garg, A.X.; McArthur, E. Visual Analytics for Dimension Reduction and Cluster Analysis of High Dimensional Electronic Health Records. Informatics 2020, 7, 17. https://doi.org/10.3390/informatics7020017
Abdullah SS, Rostamzadeh N, Sedig K, Garg AX, McArthur E. Visual Analytics for Dimension Reduction and Cluster Analysis of High Dimensional Electronic Health Records. Informatics. 2020; 7(2):17. https://doi.org/10.3390/informatics7020017
Chicago/Turabian StyleAbdullah, Sheikh S., Neda Rostamzadeh, Kamran Sedig, Amit X. Garg, and Eric McArthur. 2020. "Visual Analytics for Dimension Reduction and Cluster Analysis of High Dimensional Electronic Health Records" Informatics 7, no. 2: 17. https://doi.org/10.3390/informatics7020017