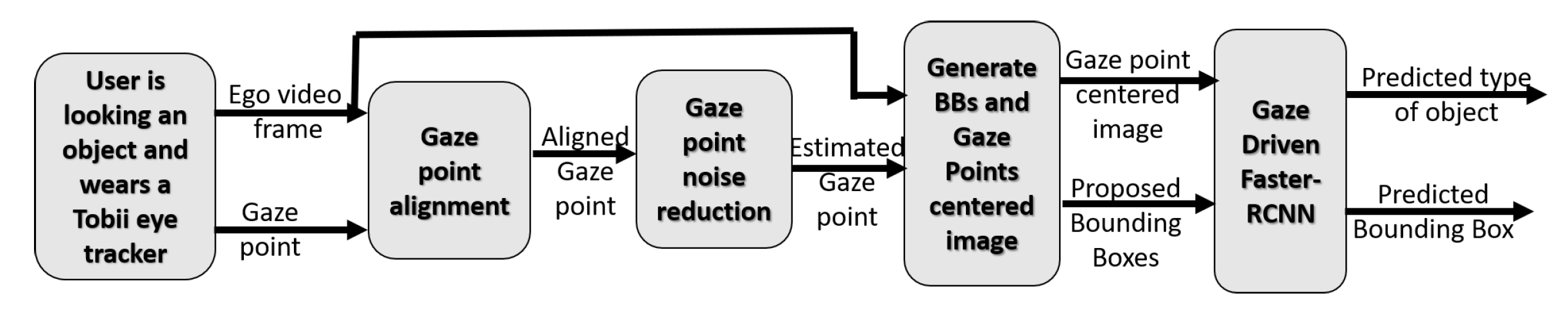
In this work, we propose a hybrid hardware/software (HW/SW) architecture for the analysis of a visual scene for the visual servoing of a neuroprosthetic arm using a glass-worn camera. The visual task here is to recognize the object the subject intends to grasp and localize it in the egocentric visual scene.
1.2. State-of-the-Art lightweight CNNs for Object Detection
In recent years, in the field of computer vision, the most popular algorithms for object detection are deep convolutional neural networks, such as faster regions with CNN (Fast R-CNN) [
10], you only look once (YOLO) [
11], and single shot detector (SSD) [
12]. These detectors are based on deep residual networks (Resnet) [
13], very deep convolutional networks (VGGnet) [
14], Alexnet [
15], MobileNet [
16], and GoogleNet [
17].
Resnet [
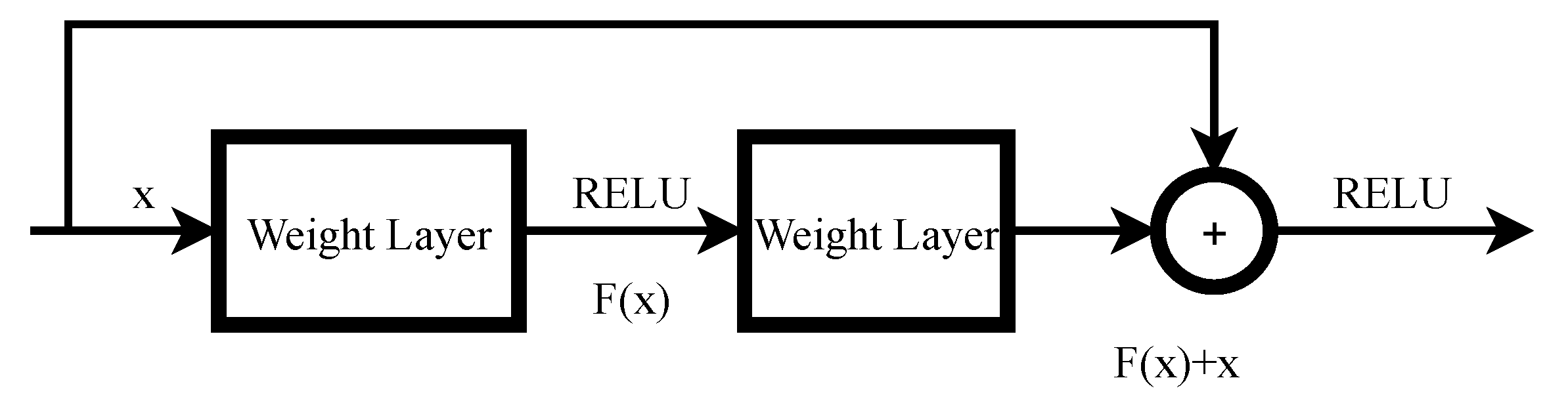
13] was proposed by He et al. and uses residual blocks, which are illustrated in
Figure 1.
Denoting the desired underlying map** as
.
where we let the stacked, nonlinear layer fit another map** of
. The original map** is recast into
. It is easier to optimize the residual map** than to optimize the original map**.
can be realized by feedforward neural networks with shortcut connections, as illustrated in
Figure 1. Shortcut connections can skip one or more layers. In Resnet [
13], the shortcut connections’ outputs are simply added to the outputs of the stacked layer.
The computational cost of the Resnet [
13] is high which makes real-time implementation difficult. However, there are methods that can accelerate the computational speed.
VGGNet [
14] is a simple deep convolutional neural network, where deep refers to the number of layers. The VGG-16 consists of 13 convolutional layers and 3 fully connected layers. The convolutional layers are simple because they use only 3 × 3 filters and pooling layers. This architecture has become popular in image classification problems.
Faster R-CNN [
10] was proposed by Ren et al. This architecture has gained popularity among object detection algorithms. Faster R-CNN [
10] is composed of the following four parts:
feature extraction module, this can be a VGGnet [
14], Mobilnet [
16], or Resnet [
13];
region proposal module to generate the bounding boxes around the object;
classification layer to detect the class of the object—for example, cat, dog, etc.;
regression layer to make the prediction more precise.
The computational speed of the network depends on the feature extraction module and the size of the region proposal module.
Both SSD [
12] and YOLO [
11] are single-stage detectors. They are significantly faster than two-stage detectors (region-based methods), such as Faster R-CNN [
10]. However, in cases when the objects have not so much variability, neither interclass nor intraclass Faster R-CNN [
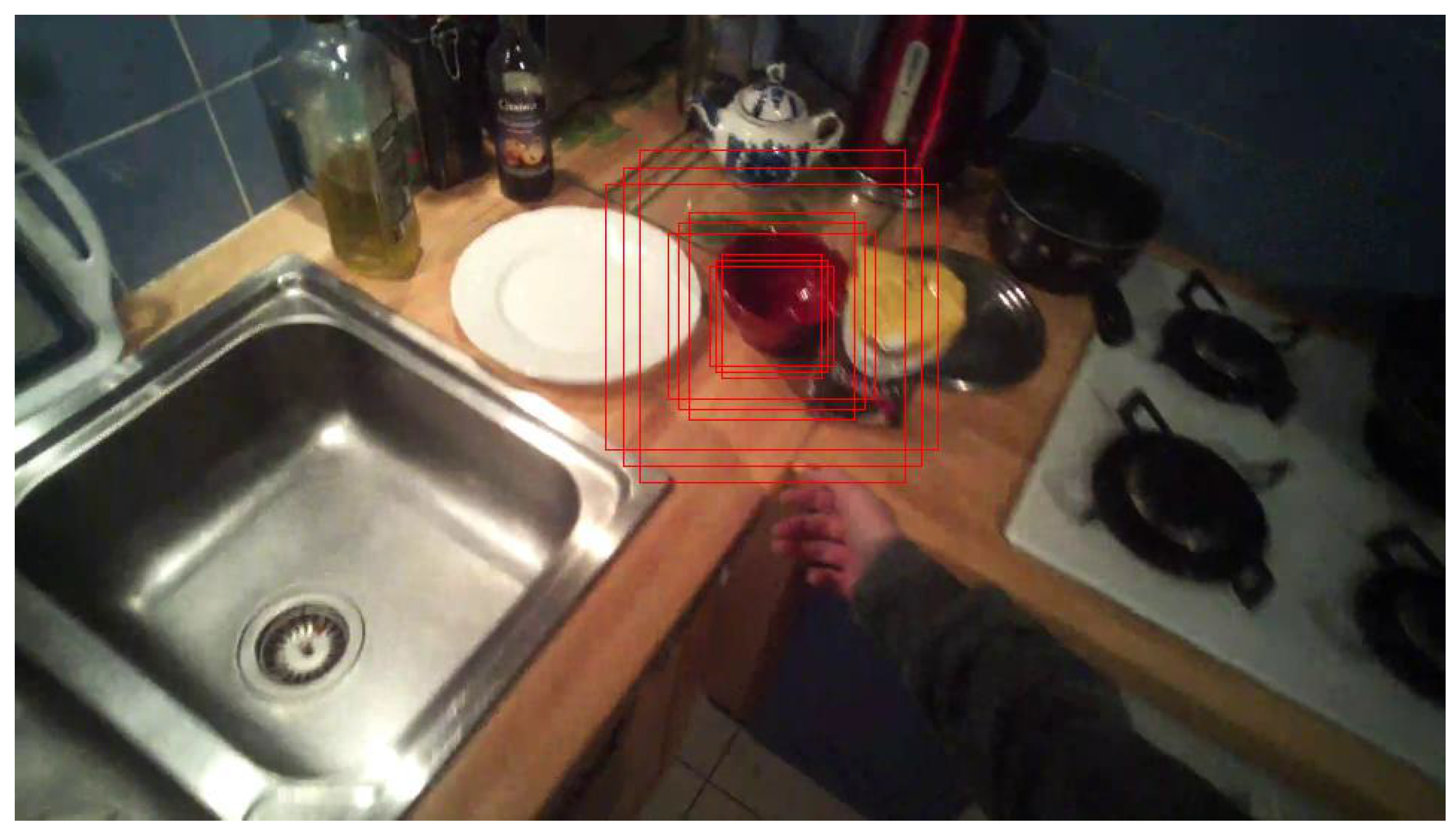
10] is a well-suited network. In our problem, we are interested in naturally cluttered home environments, where the subject intends to grasp an object, such as in kitchens. The vision analysis system we propose has to be designed to recognise objects to grasp in the video, similar to the gras**-in-the-wild (GITW) dataset [
18]. This dataset was recorded in natural environments by several healthy volunteers and we made it publicly available on the CNRS NAKALA platform. The objects here, seen from the glass-mounted camera, are quite small. Their surface merely represents
of the whole video frame. Hence, Faster R-CNN [
10] is a better choice than the SSD [
12] and YOLO [
11]. This is due to the fact that Faster R-CNN achieves higher mean average precision (mAP) than them, as reported by Huang et al. [
19] for small objects.
The original Faster R-CNN [
10] uses VGGnet [
14] as a feature extractor. However, the mAP is higher when Resnet [
13] is used as a backbone [
20]. When the object is small, the mAP of the backbone with Resnet [
13] is higher than the backbone with MobileNet [
16], as reported in [
19].
There are several possible ways to accelerate an algorithm [
21]. In our case, FPGA was chosen in the interest of develo** a lightweight and portable device [
22].
Neural network inference can be very efficiently accelerated on field-programmable gate arrays (FPGA). The most important frameworks and development environments are Vitis AI [
23], Apache TVM Versatile Tensor Accelerator (VTA) [
24], Brevitas [
25], and FINN [
26].
Due to the large computing and memory bandwidth requirements, deep learning neural networks are trained on high-performance workstations, computing clusters, or GPUs using floating-point numbers. The memory access pattern of the inference step of a trained network is different, offering more data reuse and requiring smaller memory bandwidth. It makes FPGAs a versatile platform for acceleration. Computing with floating-point numbers is a resource-intensive process for FPGA in terms of digital signal processing (DSP) slices and logic resource usage. Memory bandwidth, required to load 32 bit floating-point state values and weights, can be still high compared with the capabilities of low-power FPGA devices. Additionally, a significant amount of memory is required for buffering state values and partial results in the on-chip memory of the FPGA. One possible solution would consist of using the industry standard bfloat, 16-bit, floating-point representation, which can improve the inference speed of an FPGA. Observations show [
26] that the value of weights, state values, and partial results during the computation usually fall in a relatively small range and the 8-bit exponent range of the bfloat type is practically never used. If the range of the values during the computation is known in advance, then fixed-point numbers can be used. One of the major application areas of FPGAs is signal processing; therefore, the DSP slices are designed for fast, fixed-point multiply–accumulate (MAC) or multiply–add (MADD) operations, which can be utilized during neural network inference.
Converting a neural network model trained with floating-point numbers to a fixed-point FPGA-based implementation usually requires an additional step called quantization. Here, a small training set is used to determine the fixed-point weights and optimize the position of the radix point in each stage of the computation. The common bit width for quantization is 16 or 8 bits, where the accuracy of the network is slightly reduced. In some cases, even a binary representation is possible [
26], eliminating all multiplications from the computation, which makes FPGA implementation very efficient while the accuracy is decreased slightly.
For latency-sensitive applications, this fixed-point model can be implemented on a streaming architecture, such as FINN [
26], where layers of the network are connected directly on the FPGA. Using this structure, loading and storing state values can be avoided. In an ideal case, when the number of weights is small enough, they can be stored in the on-chip memories, further reducing the memory bandwidth requirements of the system. This also results in lower dissipated power due to the high energy requirement of off-chip data movement. Another approach used in Vitis AI [
23] and Apache TVM VTA [
24] is to divide the computation into a series of matrix–matrix multiplications and create a customized ISA (instruction set architecture) to execute these operations efficiently. The resulting system might have higher memory bandwidth requirements and longer latency, but can be easily reprogrammed to infer a different network during different steps of an image processing application.
Apache TVM VTA [
24] is an open, generic, and customizable deep learning accelerator with a complete TVM-based compiler stack. It is an end-to-end hardware–software deep learning system stack that combines TVM and VTA. It contains the hardware design drivers, a just-in-time (JIT) runtime, and an optimizing compiler stack based on TVM.
The main advantages of the quantization are reduced complexity of the circuit, efficient use of dedicated hardware resources, reduced on-chip memory requirements, reduced off-chip memory bandwidth, and smaller power dissipation. Thus, for a lightweight body-worn device, Vitis AI [
23] is a good choice, because it can accelerate the network with minimal accuracy loss.
The remainder of the paper is organized as follows. In
Section 2, we present the system overview for object detection in egocentric camera view, previously developed in [
4], which we further adapt. In
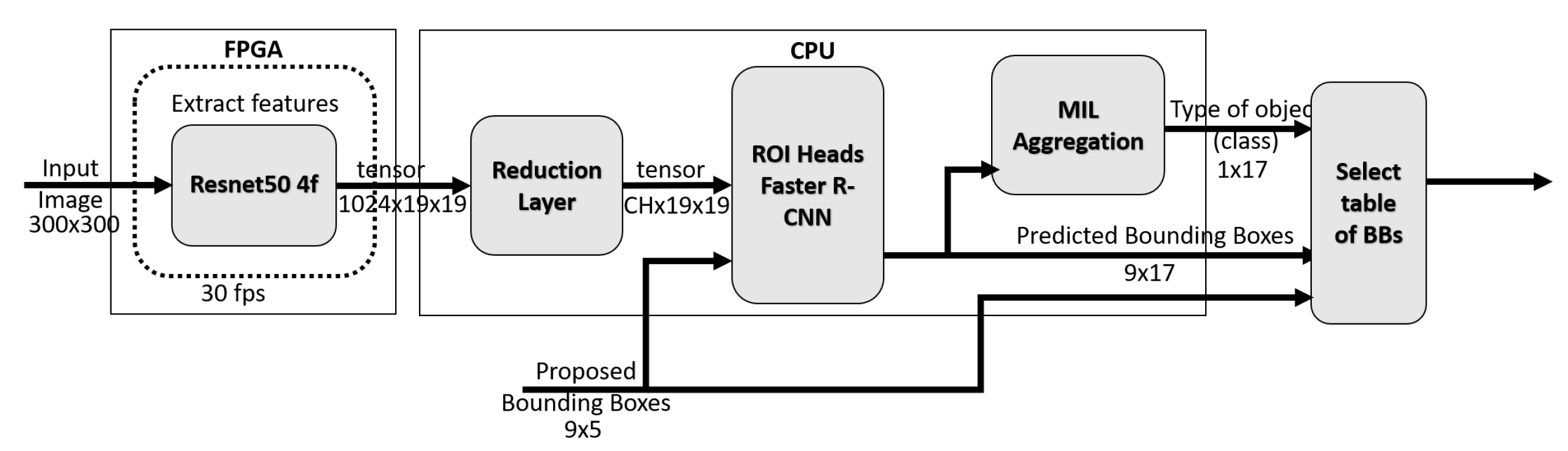
Section 3, we propose a hybridization of the solution for the FPGA–CPU board to be incorporated into a body-worn device for prosthetic control. In
Section 4, we present our results, measuring the execution time, while comparing it on different platforms.
Section 5 concludes our work and outlines its perspectives.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}