1. Introduction
Forests constitute the main body of the global terrestrial ecosystem and are often referred to as the “lungs of the Earth”. As an important natural resource in the global climate system, forests have contributed to the realization of “green carbon banks” [
1,
2,
3]. Forest resources have many ecological functions in the terrestrial ecosystem carbon cycle, such as regulating climate, conserving water resources, fixing carbon, releasing oxygen, and conserving biodiversity [
4,
5]. Forest structural parameters such as canopy cover, tree density, diameter at breast height, and tree height serve as important criteria characterizing the growth status of a forest, determining the rationality of the forest spatial structure, and evaluating the ecological functions of a forest. Tree height stands out as one of the most important forest structural parameters, and it is widely used to estimate terrestrial forest carbon reserves, as well as in biomass monitoring and forest health assessment [
6,
7,
8].
Currently, the measuring of forest tree height is mainly achieved using the following methods:
(1) The traditional method of measuring tree height in the field uses some instruments to measure tree height, including the Blume-LEISS, mirror relascope Spiegel relaskop, DQW-2, and laser height meter [
9]. Among them, the Blume-LEISS is widely used in forestry work around the world due to its ease of transport, simple operation, and high measurement accuracy [
10]. However, these instruments have limitations in tree height measurement; for example, it is difficult for Blume-LEISS to observe tree tops and tree bases in dense forests, and the accuracy of readings is easily affected by the observation distance; the laser beam of a laser altimeter is easily affected by environmental restrictions, thus affecting the measurement efficiency and accuracy of tree height.
(2) The tree height is extracted based on the canopy height model (CHM) [
11]. Tree height acquisition based on the CHM aims to directly estimate the tree height using the image target detection and recognition algorithms [
12,
13]. However, during the process of data collection using unmanned aerial vehicles (UAVs) owing to the mutual occlusion of the dense forest area, the data obtained for the canopy of the forest area are missing or redundant. Some holes are generated when the CHM is constructed. The height of these holes is lower than the surrounding pixels. As a result, the CHM produces leaky segmentation and over-segmentation during canopy segmentation leading to inaccurate tree height estimation using the CHM [
14,
15,
16]. Although Zhang et al. [
17] found that the pit-free CHM algorithm based on cloth simulation could effectively solve the problem of holes, the accuracy of extracting physical structure parameters of trees remains to be studied.
(3) Tree height inversion is also achieved based on light detection and ranging (LiDAR) [
18,
19,
20]. According to different carrying platforms, LiDAR can be divided into spaceborne LiDAR, airborne LiDAR, shipborne LiDAR, and ground-based LiDAR [
21]. Spaceborne LiDAR combines the advantages of LiDAR’s vertical information depiction and the characteristics of large-scale data acquisition. It has great advantages in the quantitative inversion of forest parameters at a large regional scale. It is one of the forest detection sensors focused on development by remote sensing agencies around the world. Wu [
22] et al. used GLAS data to calculate tree height and combined it with multi-angle optical remote sensing image MISR data and applied the random forest model to establish a tree height map, achieving the expansion of tree height extraction from point to surface scale. However, for complex terrain conditions, this method requires further in-depth research. Xu et al. [
23] explained the method of using GLAS data in forest canopy height inversion and found that terrain is one of the main factors affecting canopy height inversion. Although spaceborne LiDAR has made great progress in retrieving forest structure parameters, there are still many limitations, including under complex terrain conditions, the accuracy of forest structure parameters is easily affected, the data are discontinuous in spatial distribution, and the difficulty of obtaining forest level structure parameters. Yue et al. [
24] pointed out that spaceborne LiDAR faces the following problems in the inversion research of forest structure parameters: low data coverage; serious information interference within the light spot; and low efficiency in integration with other loads.
Airborne LiDAR, also known as airborne laser scanning (ALS), is a technique that carries LiDAR on drones and other aircrafts to obtain the three-dimensional (3D) spatial information of objects [
25]. Airborne LiDAR can be further divided into manned airborne LiDAR and unmanned aerial LiDAR. Li et al. [
26] used UAV-LiDAR data combined with ground plot data to model the stand height of artificial forests. The results showed that UAV-LiDAR can be used to estimate stand height, but this study is not suitable for complex stands and forest type. The model has not been tested. Liu et al. [
27] used UAV-LiDAR data to estimate the structural parameters of ginkgo, extracted parameters such as the tree height of ginkgo, and studied the impact of point clouds of different densities on ginkgo parameters. They found that point cloud density has little effect on tree height. Through the above research, it can be found that most of the current work focuses on parameter extraction and not much research has been conducted on point cloud data filtering. During LiDAR scanning, the instrument emits a laser beam and receives the reflected signal to measure the position and distance of the target object. These measurement results are organized as point clouds. After obtaining the UAV forest point cloud data, a series of processes such as denoising and filtering are performed on the point cloud data. After the processing is completed, the tree height is further extracted.
However, owing to the huge number of targets point clouds, several problems arise, including data redundancy, high requirements for computer hardware, a large segmentation operation load, slow processing speed, and difficulty develo** the corresponding algorithms [
28]. Discher et al. [
29] use processing methods based on external storage and GPU to improve the processing efficiency of 4D point cloud, but they still need to use external storage and parallel processing to accelerate tasks, and there is no substantial improvement in the redundancy of point cloud data. In conclusion, compared with the traditional measurement methods and tree height measurement based on the CHM, the development of LiDAR technology offers new solutions for the measurement of tree height [
30,
31,
32]. However, airborne LiDAR data redundancy is also one of the challenges faced in the tree height extraction process. How to ensure that the accuracy of tree height inversion is maintained at a high level with the smallest amount of data is an urgent problem that we need to solve.
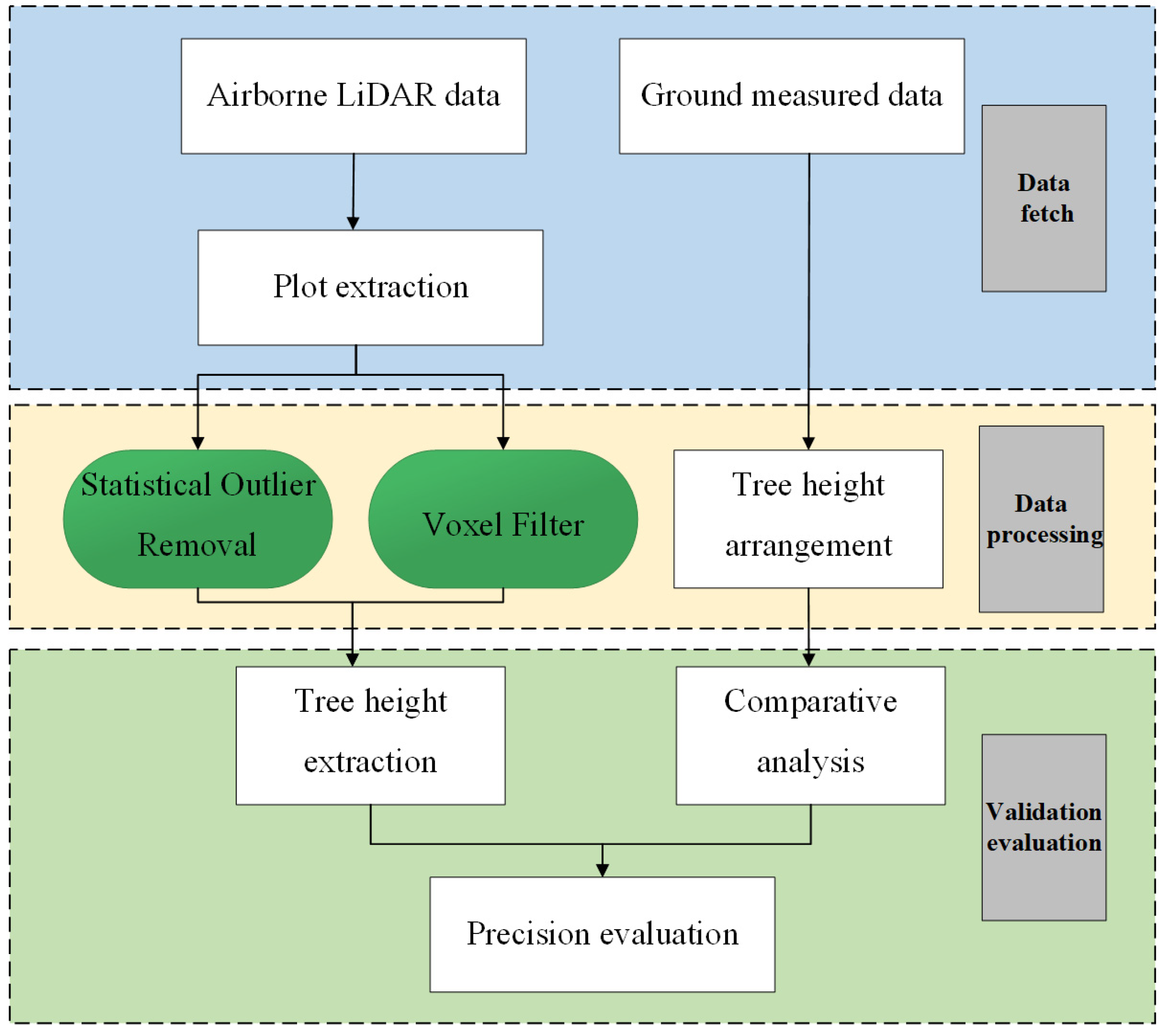
In view of the current data redundancy problem faced by tree height extraction based on LiDAR technology, in the present study, the voxel filtering (VF) method and statistical outlier removal (SOR) method were used to de-redundantly process the airborne LiDAR data during the data processing stage. Combining these methods with the top–down regional growth algorithm, research was conducted on tree height inversion in sample plots, and the advantages and disadvantages of VF and the statistical filtering method in improving the efficiency of tree height inversion were explored based on a comparative analysis with the measured tree height results. This study aimed to explore the use of filtering methods to eliminate redundant LiDAR data and reliably extract accurate forest tree heights. The results indicate that the tree height can be extracted quickly and accurately using the VF filtering method, which effectively improves the data processing efficiency.
3. Results
In this study, VF and SOR were used to process the UAV-LiDAR data and verify the influences of different filtering methods on tree height inversion by comparing the number of point clouds, scenes, computing efficiency, and height accuracy of the inversion trees.
3.1. Comparison of Point Cloud Number
Generally, the greater the density of the point cloud, the greater detail with which it can depict the features of ground objects and detect small targets, thereby reducing the dependence on interpolation algorithms and more accurately describing the features and laws of ground objects [
41,
42]. However, for tree height extraction, as long as the highest point and the lowest points of the tree are not filtered out, the accuracy of the tree height is generally unaffected. Processed through two filtering methods, we calculated the change in the number of processed point clouds relative to the original point clouds, and the percentage reduction in the number of point clouds can be calculated by Equation (7):
where,
P represents the percentage reduction in the number of filtered point clouds compared with the original point cloud number,
O represents the number of original point clouds, and
F represents the number of filtered point clouds. The UAV-LiDAR data were processed using VF and SOR, and the number of point cloud changes was clear (
Table 3).
Comparing the results shown in
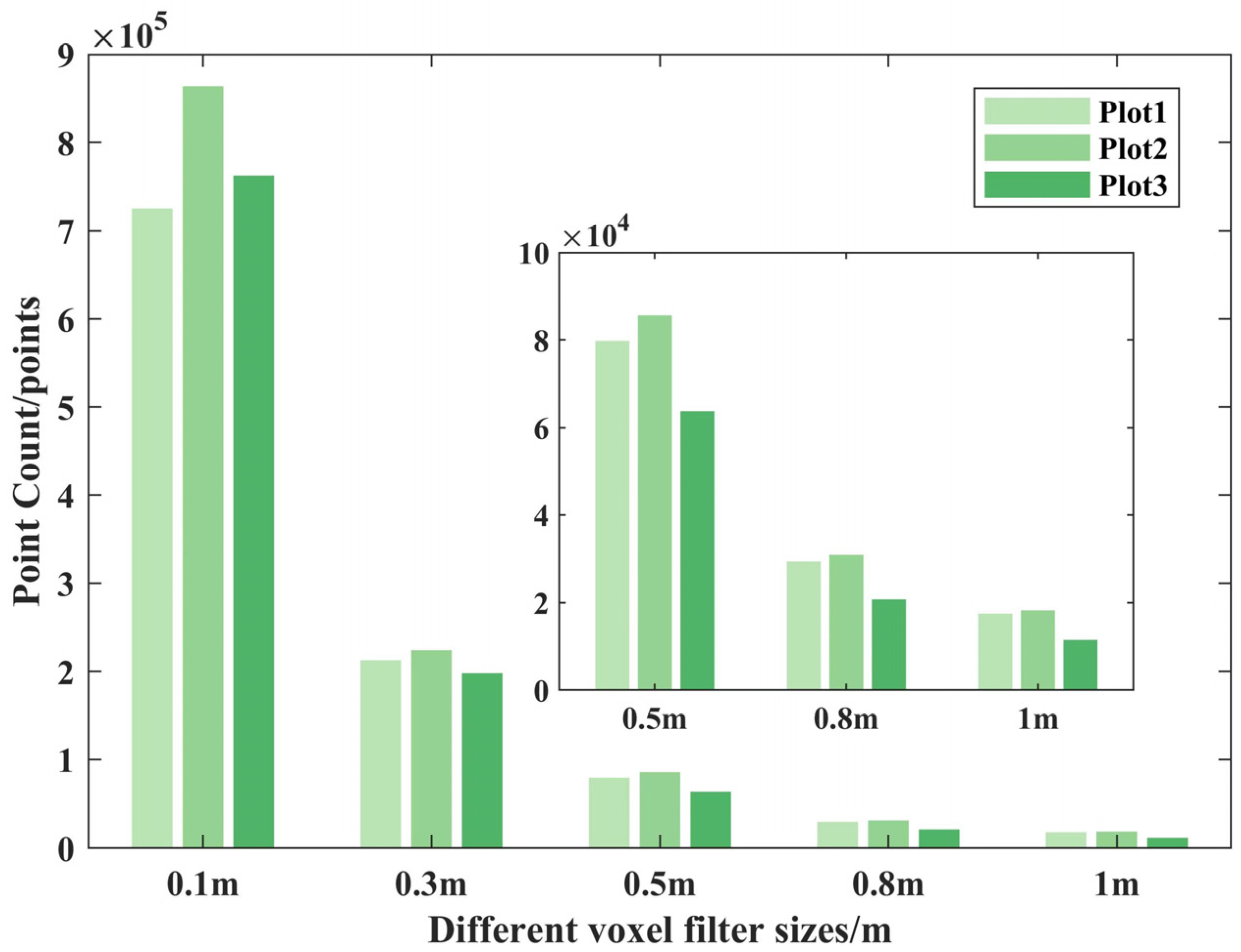
Table 3 revealed that in sample plots 1, 2, and 3, the number of point clouds after SOR processing decreased by 13.50%, 13.90%, and 12.18%, respectively, compared with the original point clouds, while the number of point clouds after VF processing decreased by 95.26%, 96.94%, and 98.52% compared with the original point clouds. This indicates that in terms of the number of point clouds, VF is better than SOR.
3.2. Impact of Tree Height Accuracy
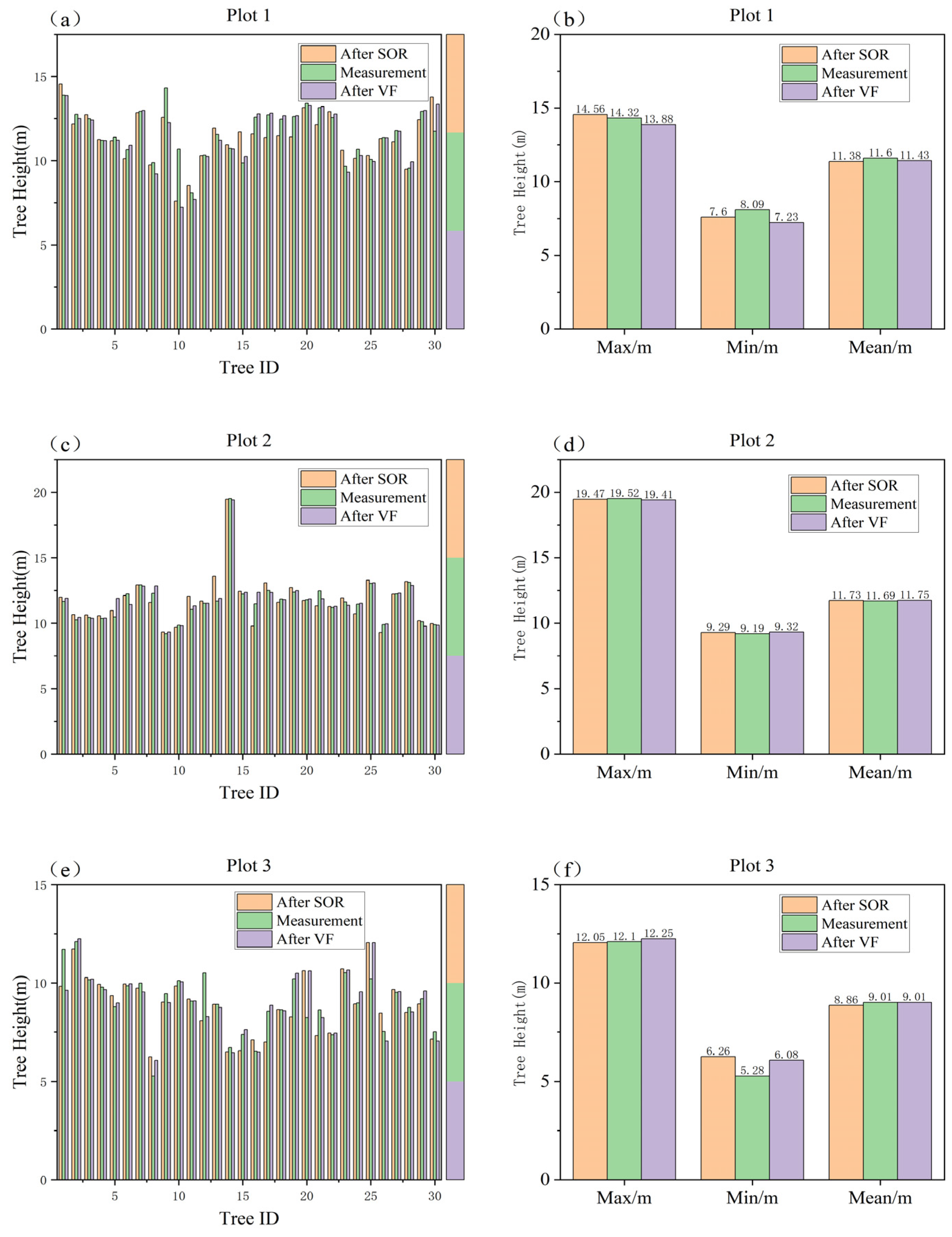
In sample plot 1, 84 trees were extracted after SOR, and 90 trees were extracted after VF, for a difference of six trees. For sample plot 2, 97 trees were extracted after SOR, and 102 trees were extracted after VF, for a difference of five trees. For sample plot 3, 89 trees were extracted after SOR, and 96 trees were extracted after VF, for a difference of seven trees. Each plot was separately matched to 30 measured trees through visual interpretation and compared with the measured tree heights of these 30 trees. Finally, the maximum, minimum, and mean values of the measured and extracted values were calculated, as shown in
Figure 6.
The results show that compared with the measured values, the inversion results after VF processing were better than those after SOR processing. In sample plot 1, the mean tree heights extracted from the data processed by the two filtering methods were 11.38 m (by SOR) and 11.43 m (by VF). In sample plot 2, the mean tree heights extracted from the data processed by the two filtering methods were 11.73 m (by SOR) and 11.75 m (by VF). In sample plot 3, the mean tree heights extracted from the data processed by the two filtering methods were 8.86 m (by SOR) and 9.01 m (by VF). The smallest difference between the mean inversion tree height and the measured value after VF processing was found in sample plot 3, and the mean inversion tree height was equal to the mean measured value. The largest difference was detected in sample plot 1, and the difference was 0.17 m. The smallest difference between the mean tree height inversion after SOR processing and the actual measured value was obtained in sample plot 2, with a difference of 0.04 m, while the largest difference was found in sample plot 1, with a difference of 0.22 m. Generally, the tree inversion accuracy after VF could be maintained in a range close to the measured values, and the tree inversion accuracy of the three plots was better than the tree inversion accuracy after SOR processing.
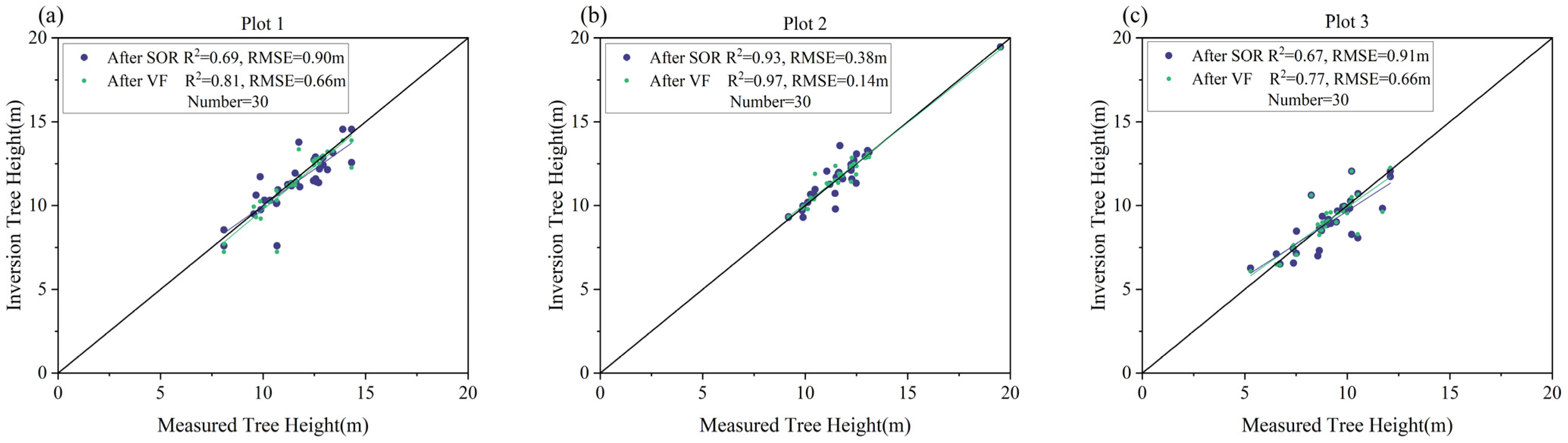
The accuracy of tree height extraction was evaluated by comparing the tree height of the inversion after VF and the tree height based on SOR filter inversion. The corresponding linear regression scatter plot was then created and can be seen in
Figure 7. The tree height of the three plots’ inversion using the VF method had a high fit, with R
2 values of 0.81, 0.97, and 0.77 (RMSE:0.66 m, 0.14 m, 0.66 m) for sample plots 1, 2 and 3, while the inversion tree height after SOR processing was consistent with the measured tree height, with R
2 values of 0.69, 0.93, and 0.67 (RMSE:0.90 m, 0.38 m, 0.91 m). The VF method greatly reduced the data redundancy and maintained the accuracy of the data, indicating that processing data using the VF method was feasible in tree height inversion.
The suitability of different filtering methods was also evaluated by calculating the height accuracy of each tree extracted from the data processed using the two filtering methods. The accuracy calculation formula is
In this formula, HA represents the height precision of the extraction tree, MH represents the measured tree height, and H represents the inversion tree height.
Equation (8) was used to find the accuracy values of the two methods for the three plots (
Table 4). The overall deviation between the tree estimation and the measured value, extracted based on the VF-processed data used in the study, was relatively small and more accurate than the SOR-processed data.
3.3. Scene Comparison
The UAV-LiDAR point cloud data were used to further calculate the average slope and forest stand density to analyze and discuss the applicability of the two filtering methods for forest scenes. The stand density can be calculated using Equation (9):
In this formula,
D represents the stand density (in plants/ha),
N represents the number of trees, and
A represents the forest area. The forest density of the three plots was calculated using the number of trees segmented from the point cloud data processed using the two filtering methods, as detailed in
Table 5.
As shown in
Table 5, sample plots 1 and 3 had similar slopes, while plot 2 had a relatively steep slope, and the altitudes of the three plots were relatively similar. Sample plot 2 was located in a
P. yunnanensis forest with an average slope of 22.22°, with the smallest difference in stand density of 55 plants/ha, and sample plot 3 was a
cypress forest with an average slope of 14.84°, with the largest difference of 77.67 plants/ha. Combined with the calculated tree height mean accuracy, it was found that the VF method had the best effect in scenes mainly collected from a
P. yunnanensis pure forest, followed by scenes from a mixed forest and other forest scenes.
3.4. Performance Comparison
In addition, the performance of the two filtering methods could also be evaluated by comparing the file size and running time after different filtering methods (
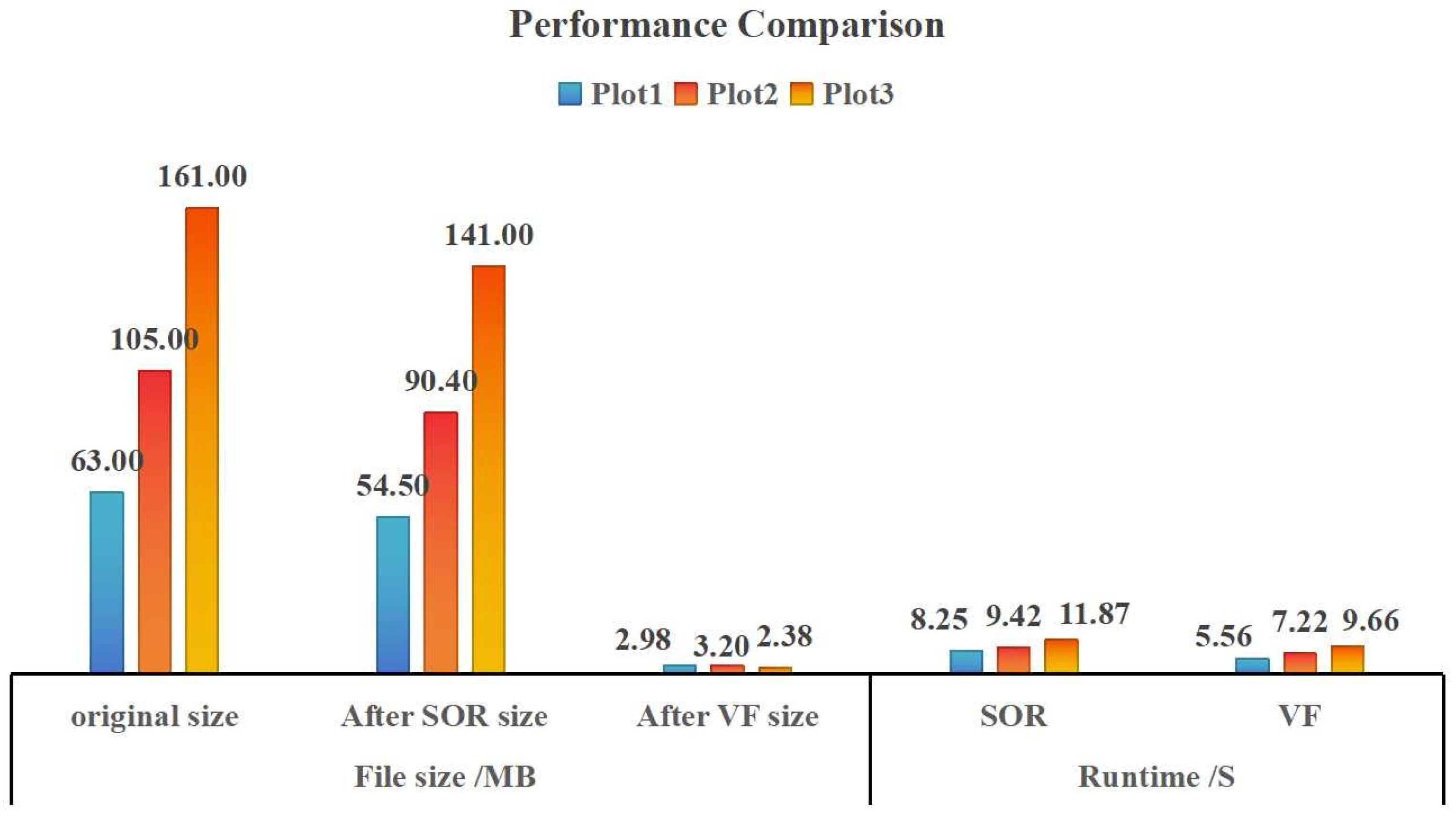
Figure 8). As shown in
Figure 8, the VF method performed the best in terms of file size and running time. The file sizes of sample plots 1, 2, and 3 were 95.27%, 96.95%, and 98.52% less than those of the original files, while the file sizes after SOR were 13.49%, 13.90%, and 12.42% less than those of the original files. VF was also significantly better than SOR in terms of running time. Thus, the VF method has good performance, which can reduce the pressure on the computer processing hardware and environment as well as the operating cost.
4. Discussion
(1) Filtering method principles: VF divides the space into cubes of equal volume (voxels) to process the data, while SOR processes the data based on statistical characteristics. The greatest difference between the two methods is the principle. In this study, VF was used to reverse the tree height after preprocessing. By comparing the data inversion tree height with the SOR method, it was found that both filtering methods could be used to accurately extract the tree height, but that the effect of VF was better. The reason for this finding is that VF can ensure that the features of the object are not destroyed and can greatly reduce the number of point clouds [
43], decrease the data redundancy, lessen the storage footprint, and improve the computing efficiency. The filter size used in this study was 0.5 m, which effectively removed excess points [
44] and retained key ground features, thus enabling the efficient inversion of tree height. VF outperformed statistical filtering in terms of the point cloud number, tree accuracy, and performance.
(2) Effects of different filtering methods: VF has been shown to effectively reduce data redundancy and improve computing efficiency, as demonstrated by **ng et al. [
45]. Aiming at the problem of redundant point cloud data, the present study found that the proposed feature extraction method was similar to VF and could improve the computing speed while effectively reducing the number of point clouds. The results of this study showed that VF could effectively improve point cloud processing efficiency while retaining key features to some extent, which is consistent with the results reported by He et al. [
46]. After VF processing, the point cloud density decreased; however, the tree high inversion accuracy remained unaffected, in accordance with the research results of You [
47] and Pang et al. [
48,
49].
(3) Error and accuracy: The data were measured using an altimeter. However, the laser point of the altimeter could not accurately illuminate the top of the tree crown, which resulted in a large deviation between some tree heights and the cloud extraction height of the airborne point. In regard to the coordinate problem, because the measured data and the airborne data adopted different measurement systems, there were systematic errors, resulting in a certain offset in the tree position. In regard to the difference in the tree segmentation, VF processing led to more data segmentation than SOR. The possible reason for this is through the VF after a sparse cloud density, the excessive segmentation phenomenon occurred; of course, we cannot rule out SOR after segmentation, because the measured data did not measure all the trees, so the problem needs to be verified. In the fine extraction of the stand parameters, this study only reversed the tree height. As for the extraction of other stand parameters, it remains unclear whether data processed using VF can still accurately extract the parameters.
(4) Method applicability: Theoretically, this research method is applicable to multiple forest situations. Considering the relatively small number of species and sampling plots examined, further exploration is needed to assess the algorithm’s applicability to a broader range of forest scenarios. In point cloud data forest parameter inversion research, no scholars have yet compared the height accuracy of data inversion trees after VF and SOR processing. This study conducted such research from the perspective of data processing. The experimental results validate the feasibility of the study method. However, the present research did not examine data under various experimental conditions, and the selected study areas were relatively concentrated. In the future, more areas and scenarios need to be tested to verify the reliability of this method and, thus, better serve the forestry industry by realizing the sustainable development of forests.
5. Conclusions
This study focused on typical natural forest plots for different tree species and different site conditions in Yuxi City, Yunnan Province, China. For the large volume of point cloud data and redundancy issues, the airborne LiDAR point cloud data were processed using VF and SOR, and the height parameters of a single tree were extracted in combination with the top–down regional growth algorithm. From the perspective of the number of point clouds, applicable scenarios, computing performance, and inversion accuracy, we explore the data de-redundancy effects of different filtering methods and their impact on tree height parameter inversion. It is believed that
(1) VF can reduce the number of point clouds at multiple levels and retain the key features of objects, enabling VF to not only reduced data redundancy but also ensure the accuracy of tree height inversion. This implies that VF has certain advantages in reducing data redundancy, and this method provides feasible ideas and solutions for point cloud data processing.
(2) Under the condition that the slope and forest stand density are not considerably different, combined with the comparison of the average accuracy of the inversion tree height, the plot effect in Yunnan pine pure forest was the best, followed by the mixed forest, and other pure forests. The overall accuracy of the three scenes in the study was high. VF was better than SOR in terms of both file size and running time, which improved the operating efficiency and reduced the cost to a certain extent.
(3) The high accuracy of data inversion using VF was better than that using SOR. VF ensures the stability and robustness of point cloud data and has great advantages and potential in point cloud data processing and feature extraction applications. In the future, tree height inversion can select a voxel filter size of 0.5 m for data processing.
The present study examined the problem of data redundancy during the inversion of the UAV-LiDAR tree height using SOR and VF. The results indicate that VF can effectively achieve reduced data redundancy and ensure tree height inversion accuracy, which provides a reference for the rapid processing of UAV-LiDAR data. However, the VF threshold needs to be set manually, and the number of inversion parameters is one. Future research will focus on the adaptive threshold of VF, the inversion of multiple parameters, and combining the two methods to process point cloud data.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}